




Entwicklung mit Milvus: KI-gestützte Nachrichtenempfehlung im mobilen Browser von Xiaomi
Von Social-Media-Feeds bis hin zu Playlist-Empfehlungen auf Spotify spielt künstliche Intelligenz bereits eine wichtige Rolle bei den Inhalten, die wir jeden Tag sehen und mit denen wir interagieren. Um ihren mobilen Webbrowser von anderen abzuheben, entwickelte der multinationale Elektronikhersteller Xiaomi eine KI-gestützte Nachrichten-Empfehlungsmaschine. Milvus, eine Open-Source-Vektordatenbank, die speziell für Ähnlichkeitssuche und künstliche Intelligenz entwickelt wurde, wurde als zentrale Datenmanagement-Plattform der Anwendung verwendet. Dieser Artikel erklärt, wie Xiaomi seine KI-gestützte Nachrichten-Empfehlungsmaschine entwickelt hat und wie Milvus und andere KI-Algorithmen eingesetzt wurden.
KI nutzen, um personalisierte Inhalte vorzuschlagen und das Nachrichtenrauschen zu durchdringen
Allein die New York Times veröffentlicht täglich über 230 Beiträge an Inhalten, und die schiere Menge der produzierten Artikel macht es Einzelpersonen unmöglich, einen umfassenden Überblick über alle Nachrichten zu erhalten. Um große Mengen an Inhalten zu durchsuchen und die relevantesten oder interessantesten Beiträge zu empfehlen, greifen wir zunehmend auf KI zurück. Obwohl Empfehlungen noch lange nicht perfekt sind, wird maschinelles Lernen immer notwendiger, um den ständigen Strom neuer Informationen zu durchdringen, der aus unserer zunehmend komplexen und vernetzten Welt hervorströmt.
Xiaomi produziert und investiert in Smartphones, mobile Apps, Laptops, Haushaltsgeräte und viele weitere Produkte. Um einen mobilen Browser von anderen abzuheben, der auf vielen der über 40 Millionen Smartphones vorinstalliert ist, die das Unternehmen jedes Quartal verkauft, integrierte Xiaomi ein Nachrichten-Empfehlungssystem in diesen Browser. Wenn Nutzer Xiaomis mobilen Browser starten, wird künstliche Intelligenz verwendet, um ähnliche Inhalte basierend auf dem Suchverlauf, den Interessen der Nutzer und mehr zu empfehlen. Milvus ist eine Open-Source-Datenbank für Vektor-Ähnlichkeitssuche, die verwendet wird, um den Abruf verwandter Artikel zu beschleunigen.
Wie funktioniert KI-gestützte Inhaltsempfehlung?
Im Kern geht es bei Nachrichtenempfehlungen (oder jeder anderen Art von Inhaltsempfehlungssystem) darum, Eingabedaten mit einer riesigen Datenbank zu vergleichen, um ähnliche Informationen zu finden. Erfolgreiche Inhaltsempfehlung erfordert ein Gleichgewicht zwischen Relevanz und Aktualität sowie die effiziente Einbindung enormer Mengen neuer Daten—oft in Echtzeit.
Um massive Datensätze zu bewältigen, werden Empfehlungssysteme typischerweise in zwei Phasen unterteilt:
- Abruf: Während des Abrufs werden Inhalte aus der größeren Bibliothek basierend auf Nutzerinteressen und -verhalten eingegrenzt. In Xiaomis mobilem Browser werden Tausende von Inhalten aus einem riesigen Datensatz ausgewählt, der Millionen von Nachrichtenartikeln enthält.
- Sortierung: Anschließend werden die während des Abrufs ausgewählten Inhalte nach bestimmten Indikatoren sortiert, bevor sie dem Nutzer angezeigt werden. Wenn Nutzer mit empfohlenen Inhalten interagieren, passt sich das System in Echtzeit an, um relevantere Vorschläge zu liefern.
Nachrichtenempfehlungen müssen in Echtzeit auf Grundlage des Nutzerverhaltens und kürzlich veröffentlichter Inhalte erstellt werden. Darüber hinaus müssen vorgeschlagene Inhalte den Nutzerinteressen und der Suchabsicht so weit wie möglich entsprechen.
Milvus + BERT = intelligente Inhaltsvorschläge
Milvus ist eine Open-Source-Datenbank für Vektor-Ähnlichkeitssuche, die mit Deep-Learning-Modellen integriert werden kann, um Anwendungen in Bereichen wie Verarbeitung natürlicher Sprache, Identitätsprüfung und vielem mehr zu ermöglichen. Milvus indiziert große Vektordatensätze, um die Suche effizienter zu gestalten, und unterstützt eine Vielzahl beliebter KI-Frameworks, um den Prozess der Entwicklung von Machine-Learning-Anwendungen zu vereinfachen. Diese Eigenschaften machen die Plattform ideal für das Speichern und Abfragen von Vektordaten, einem entscheidenden Bestandteil vieler Machine-Learning-Anwendungen.
Xiaomi entschied sich für Milvus, um Vektordaten für sein intelligentes Nachrichtenempfehlungssystem zu verwalten, da es schnell und zuverlässig ist und nur minimale Konfiguration und Wartung erfordert. Milvus muss jedoch mit einem KI-Algorithmus kombiniert werden, um einsetzbare Anwendungen zu erstellen. Xiaomi wählte BERT, kurz für Bidirectional Encoder Representation Transformers, als Sprachrepräsentationsmodell in seiner Empfehlungs-Engine. BERT kann als allgemeines NLU-Modell (Natural Language Understanding) verwendet werden, das eine Reihe verschiedener NLP-Aufgaben (Natural Language Processing) antreiben kann. Zu seinen wichtigsten Funktionen gehören:
- BERTs Transformer wird als Hauptrahmen des Algorithmus verwendet und ist in der Lage, explizite und implizite Beziehungen innerhalb von und zwischen Sätzen zu erfassen.
- Multi-Task-Lernziele, Masked Language Modeling (MLM) und Next Sentence Prediction (NSP).
- BERT erzielt bei größeren Datenmengen bessere Ergebnisse und kann andere Techniken der Verarbeitung natürlicher Sprache wie Word2Vec verbessern, indem es als Konvertierungsmatrix fungiert.
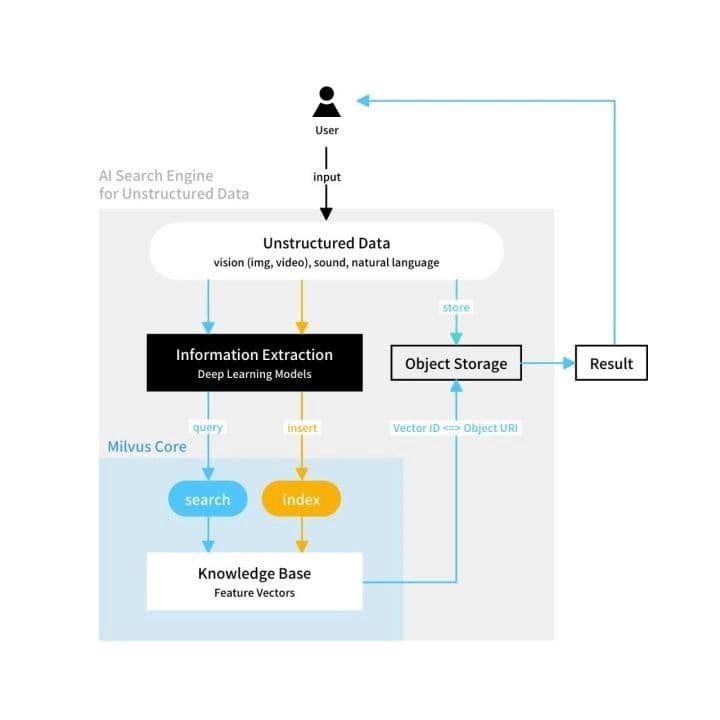 Milvus arbeitet mit BERT.
Milvus arbeitet mit BERT.
Die Netzwerkarchitektur von BERT verwendet eine mehrschichtige Transformer-Struktur, die die traditionellen neuronalen Netzwerke RNN und CNN aufgibt. Sie funktioniert, indem sie die Distanz zwischen zwei Wörtern an beliebigen Positionen durch ihren Attention-Mechanismus in eins umwandelt, und löst das Abhängigkeitsproblem, das in NLP seit einiger Zeit besteht.
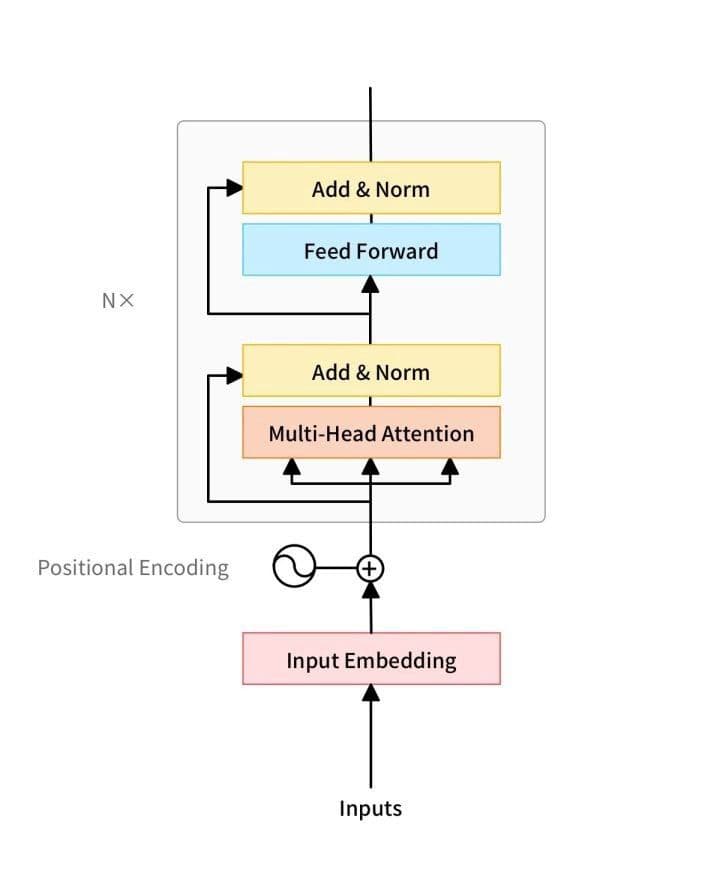 Die Netzwerkarchitektur eines Transformers in BERT.
Die Netzwerkarchitektur eines Transformers in BERT.
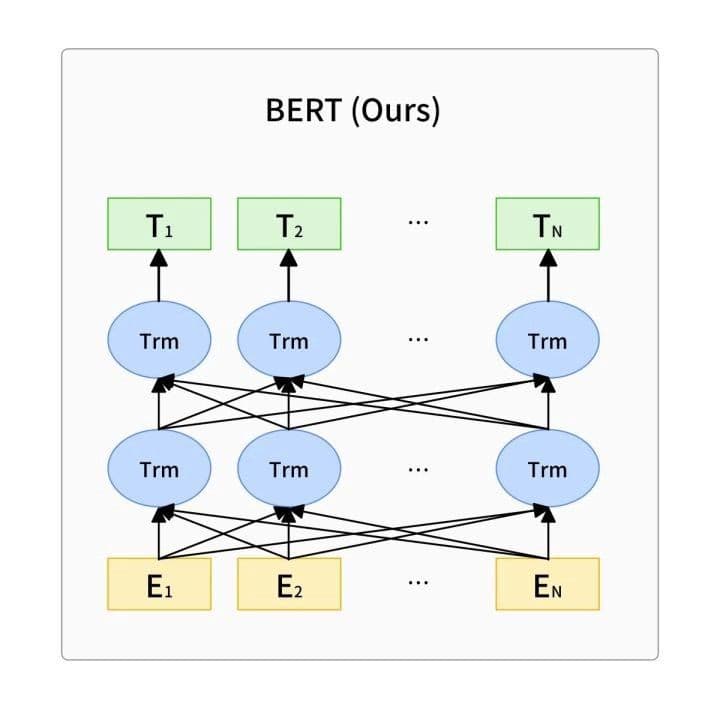 BERTs Netzwerkstruktur. „Trm“ stellt die oben dargestellte Transformer-Netzwerkarchitektur dar.
BERTs Netzwerkstruktur. „Trm“ stellt die oben dargestellte Transformer-Netzwerkarchitektur dar.
BERT bietet ein einfaches und ein komplexes Modell. Die entsprechenden Hyperparameter sind wie folgt: BERT BASE: L = 12, H = 768, A = 12, Gesamtparameter 110M; BERT LARGE: L = 24, H = 1024, A = 16, die Gesamtzahl der Parameter beträgt 340M.
In den obigen Hyperparametern steht L für die Anzahl der Schichten im Netzwerk (d. h. die Anzahl der Transformer-Blöcke), A steht für die Anzahl der Self-Attention in Multi-Head Attention, und die Filtergröße beträgt 4H.
Xiaomis Content-Empfehlungssystem
Das browserbasierte Nachrichtenempfehlungssystem von Xiaomi basiert auf drei Schlüsselkomponenten: Vektorisierung, ID-Mapping und Approximate-Nearest-Neighbor-(ANN)-Dienst.
Vektorisierung ist ein Prozess, bei dem Artikeltitel in allgemeine Satzvektoren umgewandelt werden. Das auf BERT basierende SimBert-Modell wird in Xiaomis Empfehlungssystem verwendet. SimBert ist ein 12-Schichten-Modell mit einer verborgenen Größe von 768. Simbert verwendet das Trainingsmodell Chinese L-12_H-768_A-12 für kontinuierliches Training (Trainingsaufgabe ist „metric learning +UniLM“) und hat 1,17 Millionen Schritte auf einer einzelnen TITAN RTX mit dem Adam-Optimierer trainiert (Lernrate 2e-6, Batch-Größe 128). Einfach ausgedrückt ist dies ein optimiertes BERT-Modell.
ANN-Algorithmen vergleichen vektorisierte Artikeltitel mit der gesamten in Milvus gespeicherten Nachrichtenbibliothek und geben dann ähnliche Inhalte für Nutzer zurück. ID-Mapping wird verwendet, um relevante Informationen wie Seitenaufrufe und Klicks für entsprechende Artikel zu erhalten.
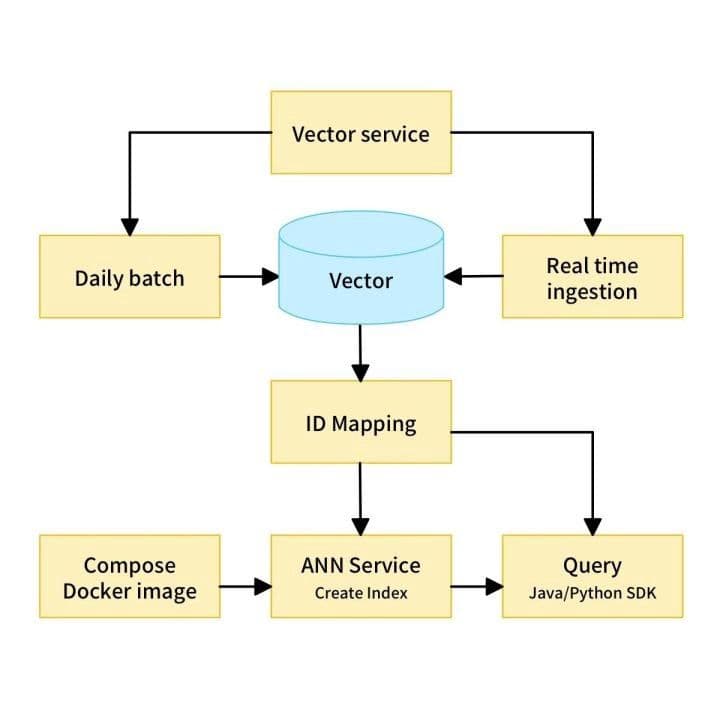 So funktioniert Content-Empfehlung.
So funktioniert Content-Empfehlung.
Die in Milvus gespeicherten Daten, die Xiaomis Nachrichtenempfehlungs-Engine antreiben, werden ständig aktualisiert, einschließlich zusätzlicher Artikel und Aktivitätsinformationen. Während das System neue Daten einbezieht, müssen alte Daten bereinigt werden. In diesem System werden vollständige Datenaktualisierungen für die ersten T-1 Tage durchgeführt und inkrementelle Aktualisierungen an den darauffolgenden T Tagen.
In definierten Intervallen werden alte Daten gelöscht und verarbeitete Daten der T-1-Tage in die Collection eingefügt. Hier werden neu generierte Daten in Echtzeit integriert. Sobald neue Daten eingefügt sind, wird in Milvus eine Ähnlichkeitssuche durchgeführt. Abgerufene Artikel werden erneut nach Klickrate und anderen Faktoren sortiert, und die besten Inhalte werden den Nutzern angezeigt. In einem Szenario wie diesem, in dem Daten häufig aktualisiert werden und Ergebnisse in Echtzeit bereitgestellt werden müssen, ermöglicht Milvus' Fähigkeit, neue Daten schnell zu integrieren und zu durchsuchen, die Empfehlung von Nachrichteninhalten im mobilen Browser von Xiaomi drastisch zu beschleunigen.
Milvus verbessert die Vektorähnlichkeitssuche
Daten zu vektorisieren und anschließend die Ähnlichkeit zwischen Vektoren zu berechnen, ist die am häufigsten verwendete Retrieval-Technologie. Der Aufstieg ANN-basierter Engines für Vektorähnlichkeitssuche hat die Effizienz von Vektorähnlichkeitsberechnungen erheblich verbessert. Im Vergleich zu ähnlichen Lösungen bietet Milvus optimierte Datenspeicherung, zahlreiche SDKs und eine verteilte Version, die den Aufwand für den Aufbau einer Retrieval-Schicht stark reduziert. Darüber hinaus ist Milvus' aktive Open-Source-Community eine leistungsstarke Ressource, die dabei helfen kann, Fragen zu beantworten und auftretende Probleme zu beheben.
Wenn Sie mehr über Vektorähnlichkeitssuche und Milvus erfahren möchten, sehen Sie sich die folgenden Ressourcen an:
- Sehen Sie sich Milvus auf Github an.
- Vector Similarity Search Hides in Plain View
- Accelerating Similarity Search on Really Big Data with Vector Indexing
Lesen Sie weitere User Stories, um mehr darüber zu erfahren, wie man Dinge mit Milvus erstellt.
Weiterlesen

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.