




Vektorähnlichkeitssuche für wissenschaftliche ArXiv-Papers mit Milvus 2.1
Einführung
Eine der besten Möglichkeiten, ein aktuelles Data-Science-Thema zu lernen, ist das Lesen von Open-Source-Forschungsarbeiten auf arxiv.org. Die enorme Anzahl an Forschungsarbeiten kann jedoch selbst für die erfahrensten Forscher überwältigend sein. Tools wie connected papers können helfen, aber sie messen Ähnlichkeit auf Grundlage der Zitationen und Bibliografie, die Arbeiten gemeinsam haben, nicht anhand der semantischen Bedeutung des Textes in diesen Dokumenten.
In diesem Beitrag mache ich mich daran, eine semantische Ähnlichkeitssuchmaschine zu bauen, die eine einzelne „Query“-Arbeit als Eingabe nimmt und modernstes NLP verwendet, um die Top-K der ähnlichsten Arbeiten aus dem arxiv-Korpus von ungefähr 640.000 Informatikarbeiten zu finden! Die Suche läuft mit <50ms Latenz auf einem einzelnen Laptop! Konkret behandle ich in diesem Beitrag
- Die Umgebung einrichten und die arXiv-Daten von Kaggle herunterladen
- Die Daten mit Dask in Python laden
- Implementierung einer Anwendung zur semantischen Ähnlichkeitssuche für wissenschaftliche Arbeiten mit der Milvus-Vektordatenbank
Die in diesem Beitrag verwendeten Techniken können als Vorlage dienen, um jede NLP-basierte semantische Ähnlichkeitssuchmaschine zu erstellen, nicht nur für wissenschaftliche Arbeiten. Der einzige Unterschied wäre das verwendete vortrainierte Modell.
Für diesen Beitrag verwenden wir den arXiv-Datensatz von Kaggle, den die Autoren unter der Lizenz CC0: Public Domain veröffentlicht haben.
Ich habe die Überlegungen zur Vektor-Ähnlichkeitssuche im Produktionsmaßstab in meinem vorherigen Beitrag skizziert. All diese Überlegungen gelten auch für dieses Projekt. Die Milvus-Vektordatenbank ist so gut konzipiert, dass viele der Schritte exakt gleich sind und hier nur der Vollständigkeit halber wiederholt werden.
Umgebung einrichten und die arxiv-Daten von Kaggle herunterladen.
Cornel University hat den gesamten arXiv-Korpus in einen Kaggle-Datensatz hochgeladen und ihn unter der Lizenz CC0: Public Domain lizenziert. Wir können den Datensatz direkt über die Kaggle API herunterladen. Falls Sie dies noch nicht getan haben, richten Sie bitte die Kaggle API auf Ihrem System ein, indem Sie diesen Anweisungen folgen.
Wir verwenden für diesen Beitrag eine conda-Umgebung namens semantic_similarity. Falls Sie conda auf Ihrem System noch nicht installiert haben, können Sie dies tun, indem Sie das Open-Source-Projekt mini forge aus seinem GitHub-Repository installieren. Die folgenden Schritte erstellen die notwendigen Verzeichnisse und die conda-Umgebung, installieren die erforderlichen Python-Bibliotheken und laden den arxiv-Datensatz von Kaggle herunter.
# Die notwendigen Verzeichnisse erstellen
mkdir -p semantic_similarity/notebooks semantic_similarity/data semantic_similarity/milvus
# In das Datenverzeichnis wechseln
cd semantic_similarity/data
# Eine conda-Umgebung erstellen und aktivieren
conda create -n semantic_similarity python=3.9
conda activate semantic_similarity
## Virtuelle Umgebung mit venv erstellen, falls conda nicht verwendet wird
# python -m venv semantic_similarity
# source semantic_similarity/bin/activate
# Die notwendigen Bibliotheken mit pip installieren
pip install jupyterlab kaggle matplotlib scikit-learn tqdm ipywidgets
pip install "dask[complete]" sentence-transformers
pip install pandas pyarrow pymilvus protobuf==3.20.0
# Daten mit der kaggle API herunterladen
kaggle datasets download -d Cornell-University/arxiv
# Die Daten in das lokale Verzeichnis entpacken
unzip arxiv.zip
# Die Zip-Datei löschen
rm arxiv.zip
Die Daten mit Dask in Python laden
Die Daten, die wir von Kaggle heruntergeladen haben, sind eine 3,3GB große JSON-Datei, die rund 2 Millionen Paper enthält! Um einen so großen Datensatz effizient zu verarbeiten, ist es keine gute Idee, den gesamten Datensatz mit pandas in den Arbeitsspeicher zu laden. Stattdessen können wir Dask verwenden, um die Daten in mehrere Partitionen aufzuteilen und zu jedem Zeitpunkt nur wenige Partitionen in den Arbeitsspeicher zu laden.
Dask
Dask ist eine Open-Source-Bibliothek, mit der wir paralleles Rechnen mit einer pandas-ähnlichen API einfach anwenden können. Die Einrichtung auf deinem lokalen Rechner ist unkompliziert, indem du, wie im Setup-Abschnitt gezeigt, pip install dask[complete] ausführst. Beginnen wir damit, zunächst die notwendigen Bibliotheken zu importieren.
import dask.bag as db
import json
from datetime import datetime
import time
data_path = '../data/arxiv-metadata-oai-snapshot.json'
Wir werden zwei Komponenten von Dask verwenden, um die große arxiv-JSON-Datei effizient zu verarbeiten.
- Dask Bag: Damit können wir die JSON-Datei in Blöcken fester Größe laden und einige Vorverarbeitungsfunktionen auf jede Datenzeile anwenden.
- Dask DataFrame: Wir können einen dask bag in ein dask dataframe umwandeln, um Zugriff auf pandas-ähnliche APIs zu erhalten
Schritt 1: Die JSON-Datei in einen Dask Bag laden
Laden wir die JSON-Datei in einen dask bag, bei dem jeder Block 10MB groß ist. Du kannst das Argument blocksize anpassen, um zu steuern, wie groß jeder Block sein soll. Anschließend wenden wir die Funktion json.loads mit der Funktion .map() auf jede Zeile des dask bag an, um den JSON-String in ein Python-Dictionary zu parsen.
# Read the file in blocks of 10MB and parse the JSON.
papers_db = db.read_text(data_path, blocksize="10MB").map(json.loads)
# Print the first row
papers_db.take(1)
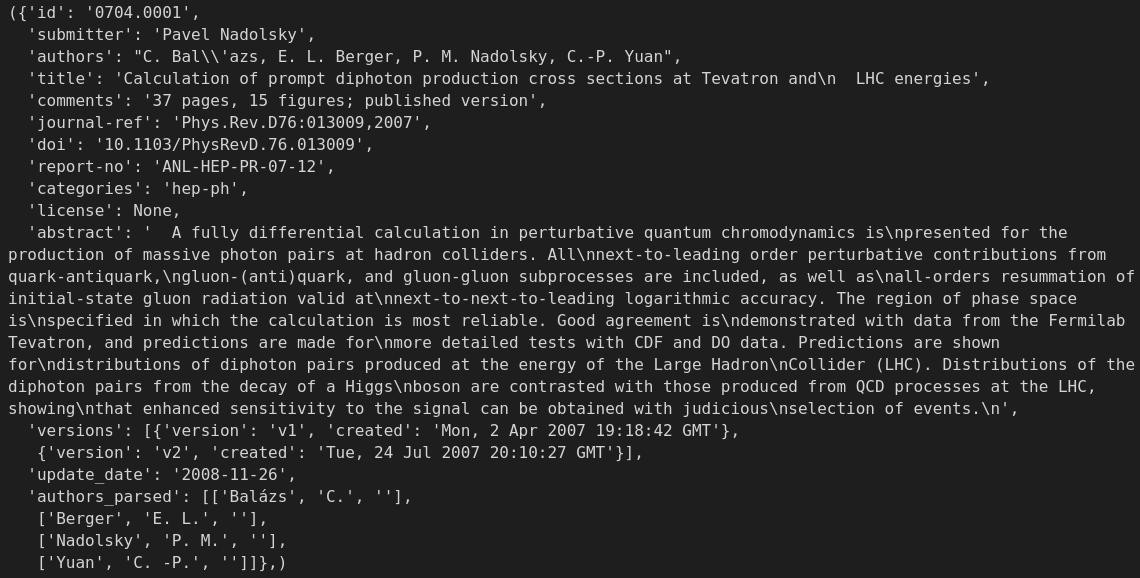 Bild vom Autor
Bild vom Autor
Schritt 2: Hilfsfunktionen für die Vorverarbeitung schreiben
Aus der Ausgabe sehen wir, dass jede Zeile mehrere Metadaten zu einem Paper enthält. Schreiben wir drei Hilfsfunktionen, die uns bei der Vorverarbeitung des Datensatzes helfen.
v1_date(): Diese Funktion dient dazu, das Datum zu extrahieren, an dem die Autoren die erste Version des Papers auf arXiv hochgeladen haben. Wir konvertieren das Datum in UNIX-Zeit und speichern es als neues Feld in dieser Zeile.text_col(): Diese Funktion dient dazu, die Felder „title“ und „abstract“ mithilfe eines „[SEP]“-Tokens zu kombinieren, damit wir diese Texte in das SPECTRE embedding model einspeisen können. Im nächsten Abschnitt werden wir mehr über SPECTRE sprechen.filters(): Diese Funktion behält nur Zeilen bei, die bestimmte Kriterien erfüllen, wie etwa maximale Textlänge in verschiedenen Spalten und Paper in der Kategorie Computer Science.
def v1_date(row):
"""
For each row in the dask bag,
find the date of the first version of the paper
and add it to the row as a new column
Args:
row: a row of the dask bag
Returns:
A row of the dask bag with added "unix_time" column
"""
versions = row["versions"]
date = None
for version in versions:
if version["version"] == "v1":
date = datetime.strptime(version["created"], "%a, %d %b %Y %H:%M:%S %Z")
date = int(time.mktime(date.timetuple()))
row["unix_time"] = date
return row
def text_col(row):
"""
It takes a row of a dataframe, adds a new column called 'text'
that is the concatenation of the 'title' and 'abstract' columns
Args:
row: the row of the dataframe
Returns:
A row with the text column added.
"""
row["text"] = row["title"] + "[SEP]" + row["abstract"]
return row
def filters(row):
"""
Für jede Zeile im Dask Bag die Zeile nur behalten, wenn sie die Filterkriterien erfüllt
Args:
row: die Zeile des DataFrames
Returns:
Boolesche Maske
"""
return ((len(row["id"])<16) and
(len(row["categories"])<200) and
(len(row["title"])<4096) and
(len(row["abstract"])<65535) and
("cs." in row["categories"]) # Nur CS-Papers behalten
)
Schritt 3: Die Vorverarbeitungs-Hilfsfunktionen auf dem Dask Bag ausführen
Wir können die Funktionen .map() und .filter() problemlos verwenden, um die Hilfsfunktionen auf jeder Zeile des Dask Bag auszuführen, wie unten gezeigt. Da Dask Method Chaining unterstützt, nutzen wir diese Gelegenheit, um nur einige wesentliche Spalten in unserem Dask Bag zu behalten und den Rest zu entfernen.
# Spalten angeben, die in der finalen Tabelle behalten werden sollen
cols_to_keep = ["id", "categories", "title", "abstract", "unix_time", "text"]
# Die Vorverarbeitung anwenden
papers_db = (
papers_db.map(lambda row: v1_date(row))
.map(lambda row: text_col(row))
.map(
lambda row: {
key: value
for key, value in row.items()
if key in cols_to_keep
}
)
.filter(filters)
)
# Die erste Zeile ausgeben
papers_db.take(1)
 Bild vom Autor
Bild vom Autor
Schritt 4: Das Dask Bag in ein Dask DataFrame konvertieren
Der letzte Schritt des Datenladens besteht darin, das Dask Bag in ein Dask Dataframe zu konvertieren, um pandas-ähnliche APIs auf jedem Block oder jeder Partition der Daten zu verwenden.
# Das Dask Bag in ein Dask Dataframe konvertieren
schema = {
"id": str,
"title": str,
"categories": str,
"abstract": str,
"unix_time": int,
"text": str,
}
papers_df = papers_db.to_dataframe(meta=schema)
# Die ersten 5 Zeilen anzeigen
papers_df.head()
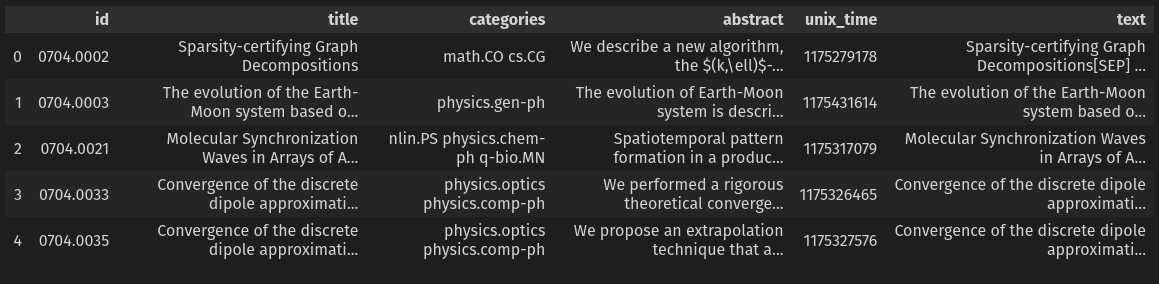 Bild vom Autor
Bild vom Autor
Implementierung einer Anwendung zur semantischen Ähnlichkeitssuche für wissenschaftliche Arbeiten mit der Milvus-Vektordatenbank
Milvus ist eine der beliebtesten Open-Source-Vektordatenbanken, die für hochskalierbare und blitzschnelle Ähnlichkeitssuche entwickelt wurde. Wir verwenden für diesen Beitrag Milvus Standalone, da wir Milvus nur auf unserem lokalen Rechner ausführen.
Schritt 1: Die Milvus-Vektordatenbank lokal installieren
Die Installation der Milvus-Vektordatenbank ist mit Docker kinderleicht, daher müssen wir zuerst Docker und Docker Compose installieren. Dann müssen wir nur noch eine docker-compose.yml herunterladen und die Docker-Container starten, wie im folgenden Code-Snippet gezeigt! Die milvus.io-Website bietet viele weitere Optionen zur Installation sowohl von Milvus Standalone als auch von Milvus Cluster; schauen Sie dort bitte nach, wenn Sie es auf einem Kubernetes-Cluster installieren oder offline installieren müssen.
# In das Milvus-Verzeichnis wechseln
cd semantic_similarity/milvus
# Die Standalone-Version von Milvus Docker Compose herunterladen
wget https://github.com/milvus-io/milvus/releases/download/v2.1.0/milvus-standalone-docker-compose.yml -O ./docker-compose.yml
# Den Milvus-Server-Docker-Container lokal ausführen
sudo docker-compose up -d
Schritt 2: Eine Milvus-Collection erstellen
Jetzt, da der Server der Milvus-Vektordatenbank auf unserem lokalen Rechner läuft, können wir mithilfe der Bibliothek pymilvus mit ihm interagieren. Lassen Sie uns zunächst die erforderlichen Module importieren und eine Verbindung zu dem auf localhost laufenden Milvus-Server herstellen. Sie können die Parameter alias und collection_name gerne ändern. Das Modell, das wir verwenden, um unseren Text in Embeddings umzuwandeln, bestimmt den Wert des Parameters emb_dim. Im Fall von SPECTRE sind die Embeddings 768-dimensional.
# Stellen Sie sicher, dass bereits ein Milvus-Server läuft
from pymilvus import connections, utility
from pymilvus import Collection, CollectionSchema, FieldSchema, DataType
# Mit dem Milvus-Server verbinden
connections.connect(alias="default", host="localhost", port="19530")
# Name der Collection
collection_name = "arxiv"
# Embedding-Größe
emb_dim = 768
# # Auf vorhandene Collection prüfen und löschen, falls vorhanden
# if utility.has_collection(collection_name):
# print(utility.list_collections())
# utility.drop_collection(collection_name)
Optional können Sie prüfen, ob die durch collection_name angegebene Collection bereits auf Ihrem Milvus-Server vorhanden ist. Für dieses Beispiel lösche ich sie, wenn die Collection bereits verfügbar ist. Auf einem Produktionsserver würden Sie dies jedoch nicht tun und stattdessen den untenstehenden Code zur Erstellung der Collection überspringen.
Eine Milvus-Collection ist analog zu einer Tabelle in einer traditionellen Datenbank. Um eine Collection zum Speichern von Daten zu erstellen, müssen wir zunächst das schema der Collection angeben. In diesem Beispiel nutzen wir die Fähigkeit von Milvus 2.1, String-Indizes und -Felder zu speichern, um alle notwendigen Metadaten zu speichern, die mit jedem Paper verbunden sind. Der Primärschlüssel idx und andere Felder categories, title, abstract haben den Datentyp VARCHAR mit angemessenen Maximallängen, während embedding ein FLOAT_VECTOR-Feld ist, das die Embeddings der Dimension emb_dim enthält. Milvus unterstützt eine große Vielfalt von Datentypen, wie auf unserer Dokumentationsseite gezeigt.
# Ein Schema für die Collection erstellen
idx = FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=16)
categories = FieldSchema(name="categories", dtype=DataType.VARCHAR, max_length=200)
title = FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=4096)
abstract = FieldSchema(name="abstract", dtype=DataType.VARCHAR, max_length=65535)
unix_time = FieldSchema(name="unix_time", dtype=DataType.INT64)
embedding = FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=emb_dim)
# Felder in der Collection
fields = [idx, categories, title, abstract, unix_time, embedding]
schema = CollectionSchema(
fields=fields, description="Semantic Similarity of Scientific Papers"
)
# Eine Collection mit dem Schema erstellen
collection = Collection(
name=collection_name, schema=schema, using="default", shards_num=10
)
Sobald eine Collection erstellt wurde, sind wir nun bereit, unsere Texte und Vektoren in sie hochzuladen.
Schritt 3: Über die Partitionen unseres Dask-Dataframes iterieren, die Texte mit SPECTER einbetten und sie in die Milvus-Vektordatenbank hochladen
Zunächst müssen wir die Texte im Dask-Dataframe in einen Embedding-Vektor umwandeln, um eine semantische Ähnlichkeitssuche auszuführen. Mein untenstehender Beitrag zeigt, wie wir Texte in Embeddings umwandeln können. Insbesondere verwenden wir ein SBERT-Bi-Encoder-Modell namens SPECTRE zur Umwandlung wissenschaftlicher Papers in Embeddings.
SPECTER [Paper] [Github]: Scientific Paper Embeddings using Citation-informed TransformERs ist ein Modell zur Umwandlung wissenschaftlicher Papers in Embeddings.
- Die Titel- und Abstract-Texte jedes Papers werden mit dem [SEP]-Token verkettet und mithilfe des [CLS]-Tokens eines vortrainierten Transformer-Modells (SciBERT) in Embeddings umgewandelt.
- Verwenden Sie Zitationen als Proxy-Signal für die Verwandtschaft zwischen Dokumenten. Wenn ein Paper ein anderes zitiert, können wir daraus schließen, dass beide verwandt sind.
- Trainingsziel mit Triplet Loss: Wir trainieren das Transformer-Modell so, dass Papers mit gemeinsamen Zitationen im Embedding-Raum näher beieinander liegen.
- Mit anderen Worten: Ein positives Paper ist ein Paper, das im Query-Paper zitiert wird, während ein negatives Paper ein Paper ist, das vom Query-Paper nicht zitiert wird. Zufällig ausgewählte Negative sind „einfache“ Negative.
- Um die Leistung zu verbessern, erstellen wir „schwierige“ Negative mithilfe von Papers, die vom Query-Paper NICHT zitiert werden, aber vom positiven Paper zitiert WERDEN.
- Während der Inferenz benötigen wir nur den Titel und das Abstract. Es sind keine Zitationen erforderlich, sodass SPECTER sogar für neue Papers Embeddings erzeugen kann, die noch keine Zitationen haben!
- SPECTER bietet eine hervorragende Leistung (besser als SciBERT) bei Themenklassifikation, Zitationsvorhersage und Empfehlung wissenschaftlicher Papers.
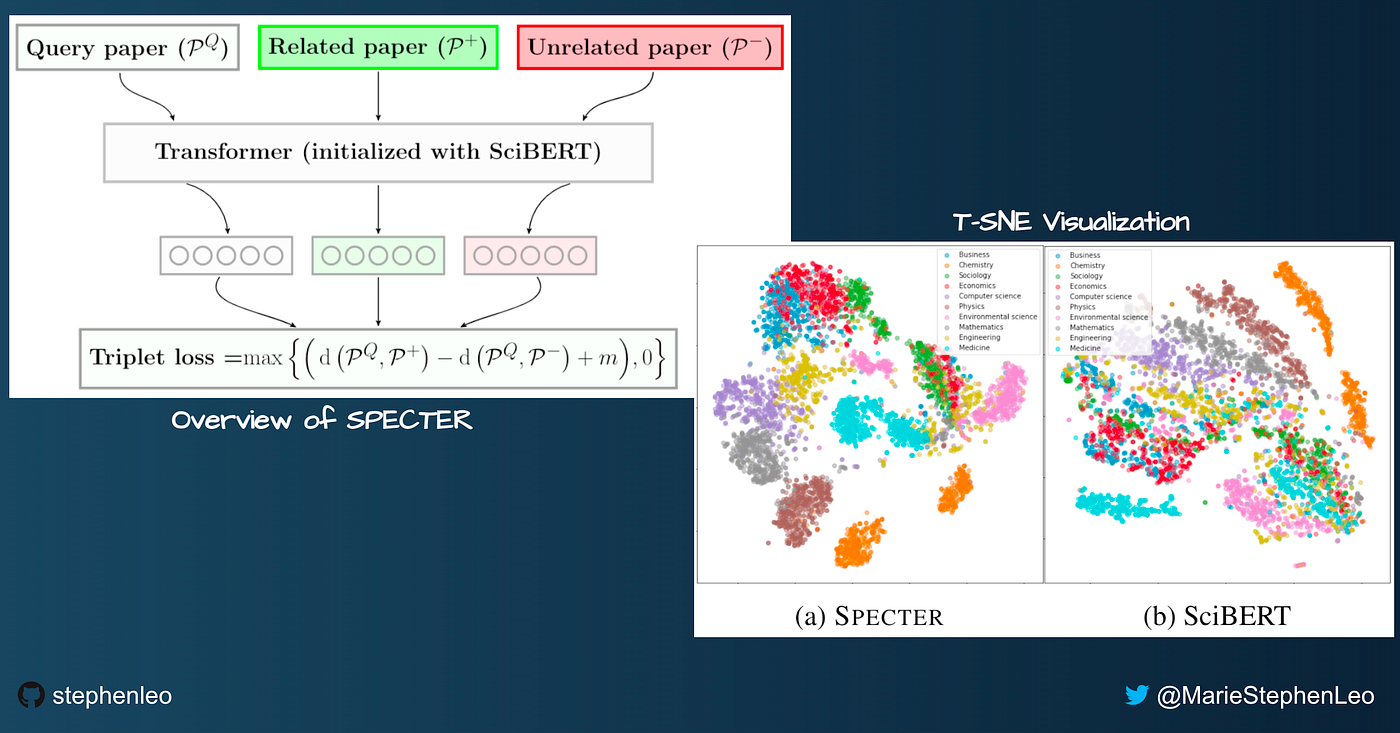 Bild vom Autor unter Verwendung von Screenshots aus dem quelloffenen SPECTER-Paper
Bild vom Autor unter Verwendung von Screenshots aus dem quelloffenen SPECTER-Paper
Die Verwendung des vortrainierten SPECTRE-Modells ist mit der Sentence Transformer-Bibliothek einfach. Wir können das vortrainierte Modell mit nur einer Codezeile herunterladen, wie unten gezeigt. Außerdem schreiben wir eine einfache Hilfsfunktion, um eine ganze Textspalte aus der Dask-Dataframe-Partition in Embeddings umzuwandeln.
from sentence_transformers import SentenceTransformer
from tqdm import tqdm
# Scientific Papers SBERT Model
model = SentenceTransformer('allenai-specter')
def emb_gen(partition):
return model.encode(partition['text']).tolist()
Wir müssen über die Partitionen des Dask-Dataframes iterieren, um die Daten in unsere Milvus-Collection hochzuladen. Bei jeder Iteration laden wir nur die Zeilen dieser Partition in den Speicher und fügen die Daten aus den Metadatenspalten einer Variablen data hinzu. Wir können die Dask-API .map_partitions() verwenden, um die Embedding-Erzeugung auf jede Zeile in der Partition anzuwenden und die Ergebnisse wieder an dieselbe Variable data anzuhängen. Schließlich können wir die Daten mit collection.insert nach Milvus hochladen.
# Initialize
collection = Collection(collection_name)
for partition in tqdm(range(papers_df.npartitions)):
# Get the dask dataframe for the partition
subset_df = papers_df.get_partition(partition)
# Check if dataframe is empty
if len(subset_df.index) != 0:
# Metadata
data = [
subset_df[col].values.compute().tolist()
for col in ["id", "categories", "title", "abstract", "unix_time"]
]
# Embeddings
data += [
subset_df
.map_partitions(emb_gen)
.compute()[0]
]
# Insert data
collection.insert(data)
Bitte beachten Sie, dass die Reihenfolge der Spalten, die der Variablen data hinzugefügt werden, derselben Reihenfolge entsprechen muss wie die Variable fields, die wir während der Schemaerstellung definiert haben!
Schritt 4: Erstellen eines Approximate-Nearest-Neighbors-(ANN)-Index für die hochgeladenen Daten
Nachdem wir alle Embeddings in die Milvus-Vektordatenbank eingefügt haben, müssen wir einen ANN-Index erstellen, um die Suche zu beschleunigen. In diesem Beispiel verwende ich den Indextyp HNSW, einen der schnellsten und genauesten ANN-Indizes. Weitere Informationen zum HNSW-Index und seinen Parametern finden Sie in der Milvus-Dokumentation.
# Add an ANN index to the collection
index_params = {
"metric_type": "L2",
"index_type": "HNSW",
"params": {"efConstruction": 128, "M": 8},
}
collection.create_index(field_name="embedding", index_params=index_params)
Schritt 5: Führen Sie Ihre Vector-Similarity-Search-Abfragen aus!
Schließlich sind die Daten in unserer Milvus-Collection bereit für Abfragen. Zuerst müssen wir die Collection in den Arbeitsspeicher laden, um Abfragen darauf auszuführen.
# Load the collection into memory
collection = Collection(collection_name)
collection.load()
Als Nächstes habe ich eine einfache Hilfsfunktion erstellt, die einen query_text entgegennimmt, ihn in das SPECTRE-Embedding umwandelt, eine ANN-Suche über die Milvus-Collection ausführt und die Ergebnisse ausgibt. Wir können die Suchqualität und -geschwindigkeit mithilfe der search_params steuern, die auf der HNSW-Dokumentationsseite beschrieben sind.
def query_and_display(query_text, collection, num_results=10):
# Embed the Query Text
query_emb = [model.encode(query_text)]
# Search Params
search_params = {"metric_type": "L2", "params": {"ef": 128}}
# Search
query_start = datetime.now()
results = collection.search(
data=query_emb,
anns_field="embedding",
param=search_params,
limit=num_results,
expr=None,
output_fields=["title", "abstract"],
)
query_end = datetime.now()
# Print Results
print(f"Query Speed: {(query_end - query_start).total_seconds():.2f} s")
print("Results:")
for res in results[0]:
title = res.entity.get("title").replace("\n ", "")
print(f"➡️ ID: {res.id}. L2 Distance: {res.distance:.2f}")
print(f"Title: {title}")
print(f"Abstract: {res.entity.get('abstract')}")
Wir können nun die Hilfsfunktion mit nur einer Codezeile verwenden, um eine semantische arXiv-Papersuche über die gesamten ~640K Computer-Science-Paper auszuführen, die in unserer Milvus-Collection gespeichert sind. Beispielsweise suche ich nach einigen Papers, die dem SimCSE-Paper ähneln, das ich in meinem vorherigen Beitrag ausführlich besprochen habe. Die Top-10-Ergebnisse sind für meine Suchanfrage ziemlich relevant, da sie größtenteils mit kontrastivem Lernen von Satz-Embeddings zusammenhängen! Noch beeindruckender ist, dass die gesamte Suche nur 30 ms dauerte und lediglich auf meinem Laptop ausgeführt wurde, was deutlich innerhalb der typischen Nutzungsanforderungen für die meisten Anwendungen liegt!
# Query for papers that are similar to the SimCSE paper
title = "SimCSE: Simple Contrastive Learning of Sentence Embeddings"
abstract = """This paper presents SimCSE, a simple contrastive learning framework that greatly advances state-of-the-art sentence embeddings. We first describe an unsupervised approach, which takes an input sentence and predicts itself in a contrastive objective, with only standard dropout used as noise. This simple method works surprisingly well, performing on par with previous supervised counterparts. We find that dropout acts as minimal data augmentation, and removing it leads to a representation collapse. Then, we propose a supervised approach, which incorporates annotated pairs from natural language inference datasets into our contrastive learning framework by using "entailment" pairs as positives and "contradiction" pairs as hard negatives. We evaluate SimCSE on standard semantic textual similarity (STS) tasks, and our unsupervised and supervised models using BERT base achieve an average of 76.3% and 81.6% Spearman's correlation respectively, a 4.2% and 2.2% improvement compared to the previous best results. We also show -- both theoretically and empirically -- that the contrastive learning objective regularizes pre-trained embeddings' anisotropic space to be more uniform, and it better aligns positive pairs when supervised signals are available."""
query_text = f"{title}[SEP]{abstract}"
query_and_display(query_text, collection, num_results=10)
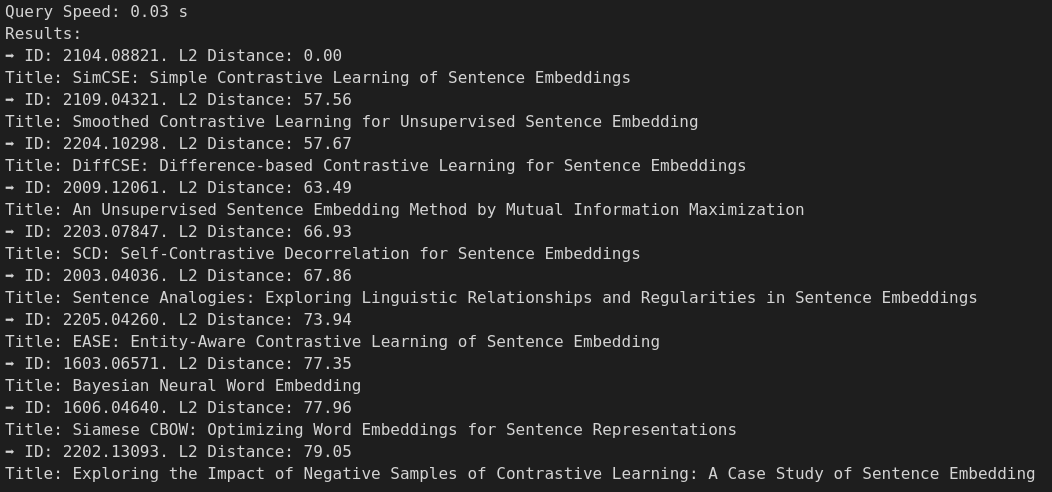 Bild vom Autor
Bild vom Autor
Wenn wir keine weiteren Abfragen ausführen müssen, können wir die Collection freigeben, um Arbeitsspeicher unserer Maschine freizugeben. Das Entfernen einer Collection aus dem Speicher verursacht keinen Datenverlust, da sie weiterhin auf unserer Festplatte gespeichert ist und bei Bedarf erneut geladen werden kann.
# Release the collection from memory when it's not needed anymore
collection.release()
Wenn Sie den Milvus-Server stoppen und alle Daten von der Festplatte löschen möchten, können Sie den Anweisungen zum Stoppen von Milvus folgen. Vorsicht! Dieser Vorgang ist irreversibel und löscht alle Daten in Ihrem Milvus-Cluster.
Fazit
In diesem Beitrag haben wir in wenigen einfachen Schritten einen extrem skalierbaren Dienst für die semantische Suche wissenschaftlicher Arbeiten mithilfe von SPECTRE-Embeddings und der Milvus-Vektordatenbank implementiert. Dieser Ansatz ist in der Produktion auf Hunderte Millionen oder sogar Milliarden von Vektoren skalierbar. Wir haben die Suche mit einer Beispielabfrage für eine wissenschaftliche Arbeit getestet, die die Top-10-Ergebnisse in nur 30 ms zurückgab! Milvus’ Ruf als hochskalierbare und blitzschnelle Datenbank für Vektorähnlichkeitssuche ist wohlverdient!
Weitere Inspirationen zu Milvus’ Anwendungen finden Sie in den Milvus Vektordatenbank-Demos und im Bootcamp.
Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.