




RAG Agêntico: Recuperação de IA Mais Inteligente com Agentes Autônomos
RAG Agêntico: Recuperação de IA Mais Inteligente com Agentes Autônomos
Imagine ter um assistente de pesquisa que não apenas pesquisa em um banco de dados quando você faz uma pergunta, mas decide inteligentemente quais fontes consultar, valida as informações que encontra e até reformula sua pergunta, se necessário, para obter melhores resultados. É exatamente isso que o RAG agêntico traz para os sistemas de inteligência artificial.
Embora os sistemas tradicionais de Geração Aumentada por Recuperação (RAG) tenham melhorado significativamente a forma como as aplicações de IA acessam conhecimento externo, eles operam como uma mente de via única, limitados a uma única fonte de conhecimento e a uma única tentativa de recuperação. O RAG agêntico transforma essa abordagem linear em um sistema inteligente e adaptável que pode pensar, planejar e agir em várias fontes de informação para fornecer respostas mais precisas e abrangentes.
O que é RAG Agêntico?
RAG agêntico é uma implementação aprimorada da Geração Aumentada por Recuperação que incorpora agentes de IA para orquestrar fluxos de trabalho complexos de recuperação e geração de informações. Diferentemente dos sistemas RAG tradicionais, que seguem uma sequência fixa de recuperação e geração, o RAG agêntico emprega agentes inteligentes capazes de raciocinar, planejar e tomar decisões sobre a melhor forma de responder às consultas dos usuários.
Em sua essência, o RAG agêntico utiliza agentes de IA para facilitar a geração aumentada por recuperação, aprimorando o pipeline de RAG com adaptabilidade e precisão, ao mesmo tempo em que permite que grandes modelos de linguagem realizem recuperação de informações de múltiplas fontes e lidem com fluxos de trabalho mais complexos.
Esses sistemas convertem LLMs em agentes de IA, capacitando-os a utilizar ferramentas, funções e fontes externas de conhecimento, criando assim uma abordagem mais sofisticada para o processamento de informações do que as implementações padrão de RAG.
Principais Recursos do RAG Agêntico
Inteligência Multifuente: O sistema pode se conectar a vários bancos de dados, incluindo bancos de dados vetoriais como Milvus e Zilliz Cloud, bem como bancos de dados SQL tradicionais. Os agentes podem acessar simultaneamente documentos internos, APIs externas, pesquisas na web e bancos de dados especializados com base nos requisitos da consulta.
Processamento Adaptativo de Consultas: Agentes de IA podem iterar sobre processos anteriores para otimizar resultados ao longo do tempo. Quando os resultados iniciais são insuficientes, os agentes podem reformular consultas, tentar fontes diferentes ou dividir perguntas complexas em subconsultas gerenciáveis.
Planejamento e Orquestração Inteligentes: Agentes nessa abordagem podem planejar e raciocinar por meio de tarefas que exigem múltiplas etapas e raciocínio lógico. Um agente coordenador pode atribuir tarefas especializadas a diferentes agentes de recuperação, cada um otimizado para tipos de dados ou domínios específicos.
Validação de Qualidade: Diferentemente dos sistemas tradicionais, o RAG agêntico inclui mecanismos integrados para avaliar o conteúdo recuperado. Agentes de IA podem iterar sobre processos anteriores para otimizar resultados ao longo do tempo. Essa camada de validação reduz significativamente alucinações e melhora a precisão das respostas.
Integração de Ferramentas: Agentes de recuperação com acesso a diferentes ferramentas de recuperação, como: mecanismo de busca vetorial (também chamado de mecanismo de consulta) que realiza busca vetorial em um índice vetorial (como em pipelines RAG típicos), pesquisa na web, calculadora, qualquer API para acessar software programaticamente, como programas de e-mail ou chat, permitem a coleta abrangente de informações além da simples recuperação de documentos.
Como Funciona o RAG Agêntico
O RAG agêntico opera por meio de uma arquitetura sofisticada que combina múltiplos agentes de IA com capacidades avançadas de raciocínio. Veja como o sistema processa consultas do início ao fim:
Fluxo de Trabalho Passo a Passo
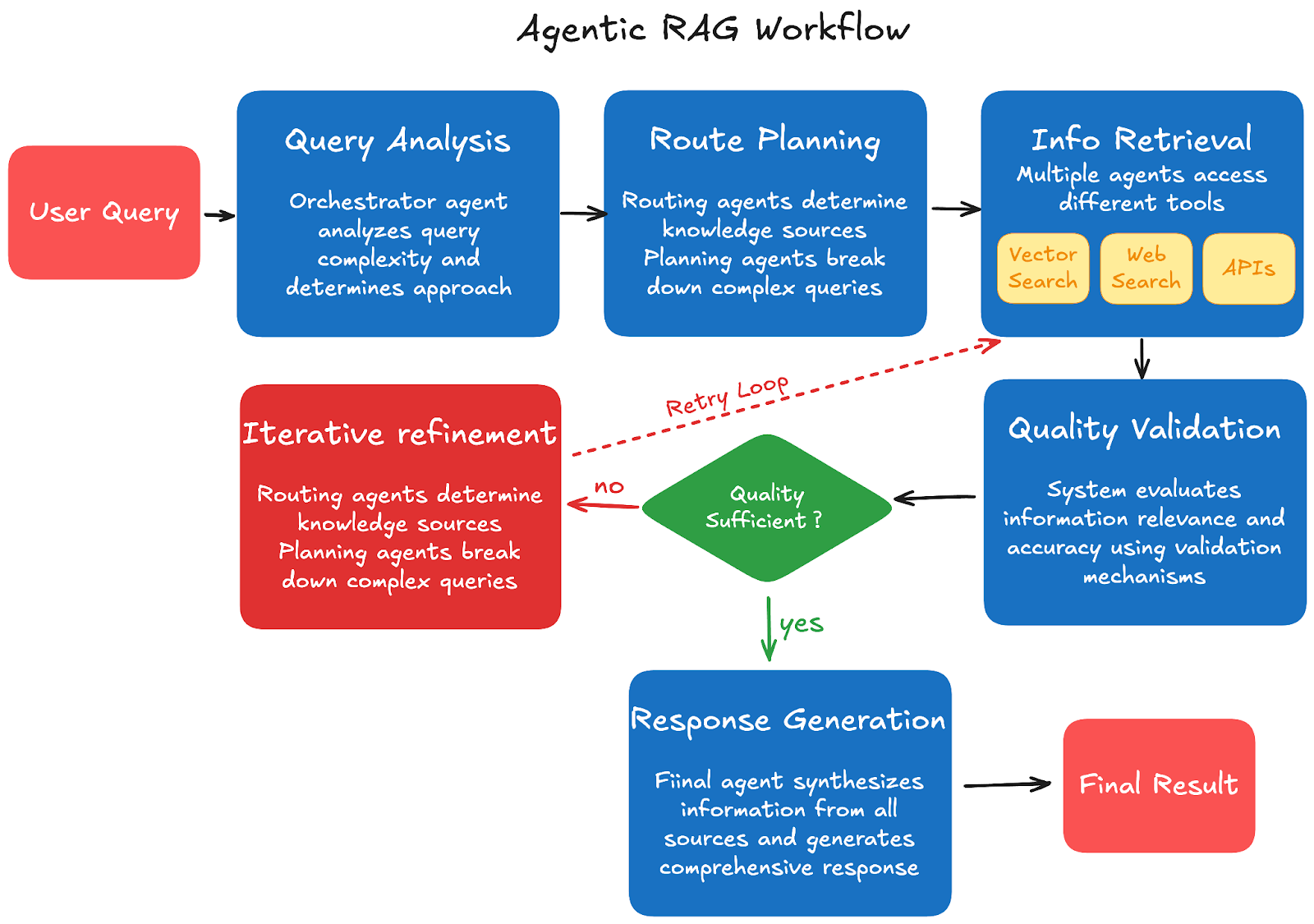
Etapa 1: Análise da Consulta: O usuário envia uma consulta ao agente orquestrador principal, que analisa a complexidade da consulta e determina a abordagem necessária. O sistema decide se são necessárias etapas de recuperação únicas ou múltiplas com base no escopo e na complexidade da consulta.
Etapa 2: Planejamento de Rotas: Agentes de roteamento determinam quais fontes externas de conhecimento e ferramentas usar, enquanto agentes de planejamento de consultas dividem consultas complexas em subtarefas gerenciáveis. O sistema cria um plano de execução com base nos recursos disponíveis e no caminho mais eficiente para coletar informações abrangentes.
Etapa 3: Recuperação de Informações: Agentes de recuperação acessam diferentes ferramentas com base no plano de execução, incluindo mecanismos de busca vetorial para bancos de dados de documentos, busca na web para informações atuais, APIs para dados específicos de software ou serviços e calculadoras para tarefas computacionais. Vários agentes podem trabalhar simultaneamente em diferentes fontes para maximizar a eficiência e a cobertura.
Etapa 4: Validação de Qualidade: O sistema avalia as informações recuperadas quanto à relevância e precisão usando mecanismos de validação integrados. Se o conteúdo for insuficiente ou irrelevante, os agentes reformulam as consultas, e os mecanismos de validação verificam a consistência entre várias fontes para garantir uma qualidade de informação confiável.
Etapa 5: Refinamento Iterativo: O sistema determina se é necessária recuperação adicional com base na qualidade e completude das informações coletadas. Os agentes podem consultar novamente com termos de busca refinados, e esse processo se repete até que informações de qualidade suficiente sejam coletadas para fornecer uma resposta abrangente.
Etapa 6: Geração de Resposta: O agente final sintetiza informações de todas as fontes em uma resposta coerente. Ele gera respostas abrangentes usando contexto validado e fornece citações e atribuição de fontes quando aplicável para manter transparência e credibilidade.
Tipos de Agentes e Funções
Agentes de Roteamento: Determinam quais fontes externas de conhecimento e ferramentas são usadas para responder às consultas dos usuários
Agentes de Planejamento de Consultas: Processam consultas complexas e as dividem em processos passo a passo
Agentes ReAct: Combinam capacidades de raciocínio e ação para adaptação dinâmica do fluxo de trabalho
Agentes Plan-and-Execute: Lidam com fluxos de trabalho de várias etapas de forma independente, sem coordenação constante
 Fluxo de trabalho Agentic RAG.png
Fluxo de trabalho Agentic RAG.png
Benefícios e Desafios do Agentic RAG
Agentic RAG oferece vantagens significativas em relação às abordagens tradicionais, ao mesmo tempo em que introduz algumas considerações operacionais.
Benefícios
Precisão Aprimorada: A validação e a referência cruzada de múltiplas fontes reduzem significativamente as alucinações e melhoram a confiabilidade das respostas. A capacidade do sistema de verificar informações em várias bases de conhecimento cria um mecanismo robusto de checagem de fatos que o RAG tradicional não consegue igualar.
Integração de Múltiplas Fontes: O acesso a diversas bases de conhecimento, APIs e ferramentas externas permite a coleta abrangente de informações de bancos de dados estruturados, buscas na web, calculadoras e software especializado. Essa versatilidade permite que o sistema lide com consultas complexas que exigem informações de vários domínios.
Refinamento Iterativo: A melhoria contínua da qualidade das respostas por meio de múltiplos ciclos de recuperação e validação garante que resultados iniciais abaixo do ideal possam ser aprimorados. O sistema aprende com cada iteração, reformulando consultas e melhorando estratégias de busca até que uma qualidade satisfatória das informações seja alcançada.
Resolução Adaptativa de Problemas: Abordagem proativa para consultas complexas com roteamento inteligente e ajuste dinâmico do fluxo de trabalho. O sistema pode determinar autonomamente a melhor estratégia de recuperação, adaptar-se a contextos em mudança e lidar com cenários inesperados sem exigir intervenção manual ou extensa engenharia de prompts.
Desafios
Custos Mais Altos: Mais agentes e processos iterativos exigem maiores recursos computacionais e uso de tokens, aumentando potencialmente as despesas operacionais em 2-3x em comparação com o RAG tradicional. A arquitetura multiagente exige mais chamadas de API, tempos de processamento mais longos e infraestrutura adicional para dar suporte a fluxos de trabalho complexos.
Maior latência: Múltiplas interações entre agentes, etapas de validação e possíveis ciclos de iteração podem desacelerar significativamente os tempos de resposta. Consultas complexas podem exigir várias rodadas de recuperação e refinamento, tornando o sistema menos adequado para aplicações em tempo real que demandam respostas imediatas.
Problemas de confiabilidade: Agentes podem ter dificuldade ou falhar ao concluir tarefas complexas, criando pontos de falha no fluxo de trabalho. A coordenação entre múltiplos agentes pode se tornar instável, levando a respostas incompletas, loops infinitos ou decisões conflitantes que exigem mecanismos sofisticados de tratamento de erros.
Complexidade de integração: Conectar diversas ferramentas, fontes de conhecimento e gerenciar a coordenação multiagente requer orquestração sofisticada e testes extensivos. A arquitetura do sistema torna-se significativamente mais complexa do que o RAG tradicional, exigindo conhecimento especializado para implantação, manutenção e solução de problemas.
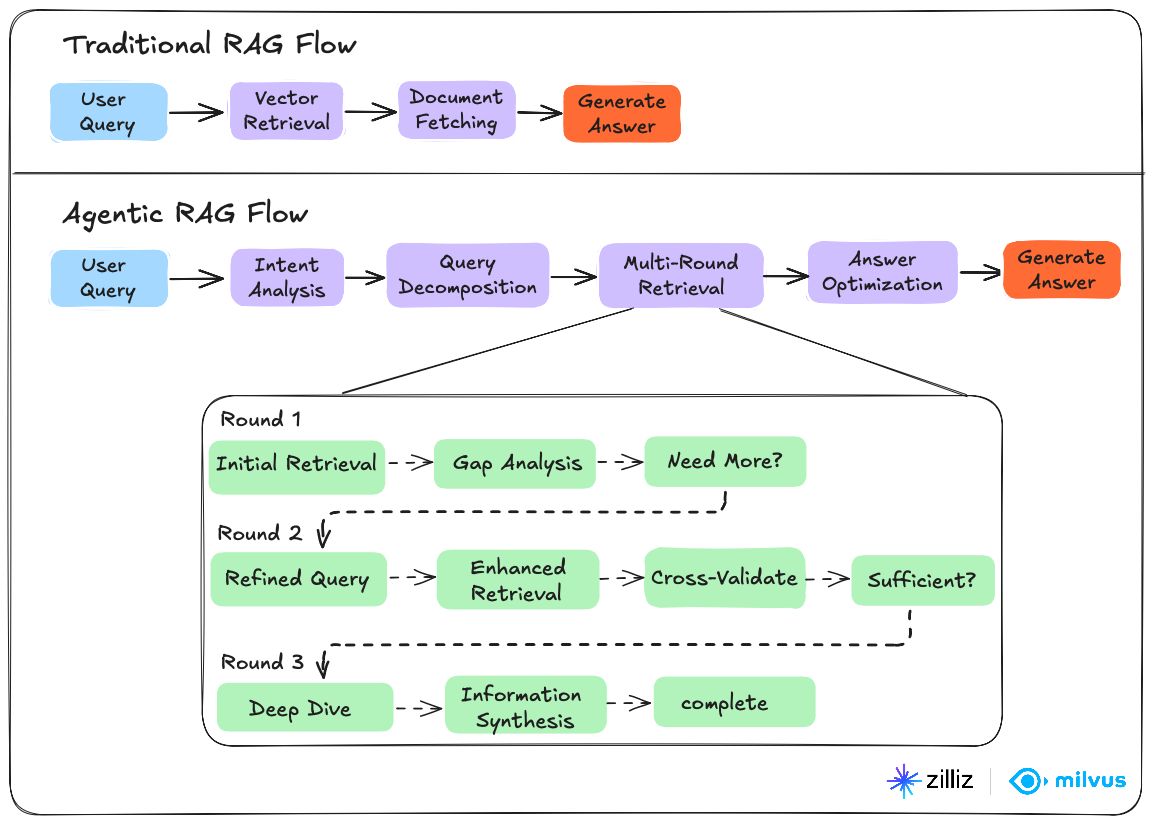
Comparação do Agentic RAG com o RAG tradicional
 Agentic RAG vs Traditional RAG.jpg
Agentic RAG vs Traditional RAG.jpg
| Recurso | RAG tradicional | Agentic RAG |
|---|---|---|
| Fontes de dados | Base de conhecimento única | Múltiplas fontes e ferramentas externas |
| Processamento de consultas | Recuperação única | Abordagem iterativa em múltiplas etapas |
| Validação | Sem validação integrada | Avaliação automatizada de qualidade |
| Adaptabilidade | Estática, baseada em regras | Tomada de decisão dinâmica e inteligente |
| Acesso a ferramentas | Limitado ao banco de dados vetorial | APIs, pesquisa na web, calculadoras, serviços externos |
| Capacidade de planejamento | Recuperação e geração simples | Raciocínio complexo e decomposição de tarefas |
| Tratamento de erros | Intervenção manual necessária | Mecanismos de autocorreção e nova tentativa |
| Escalabilidade | Limitada por uma única fonte | Escala com agentes e fontes adicionais |
| Custo | Menor uso de tokens | Maior sobrecarga computacional |
| Velocidade de resposta | Resposta inicial mais rápida | Variável, dependendo da complexidade |
Casos de uso do Agentic RAG
Gestão do conhecimento empresarial: Sistemas RAG alimentados por agentes são excelentes para analisar e recuperar informações de dados empresariais heterogêneos. Empresas podem implantar sistemas que pesquisam automaticamente em documentos internos, bancos de dados, e-mails e inteligência de mercado externa para responder a perguntas de negócios complexas.
Automação do suporte ao cliente: Empresas que desejam otimizar os serviços de suporte ao cliente podem usar sistemas RAG automatizados para lidar com consultas mais simples de clientes. O sistema agentic RAG pode escalar solicitações de suporte mais exigentes para profissionais humanos. O sistema pode acessar manuais de produtos, bancos de dados de FAQ, histórico do cliente e informações de status em tempo real para fornecer suporte abrangente.
Sistemas de informação em saúde: Profissionais médicos podem usar o agentic RAG para acessar registros de pacientes, literatura médica, bancos de dados de medicamentos e diretrizes clínicas simultaneamente, permitindo uma tomada de decisão mais informada enquanto mantêm a privacidade dos dados e os padrões de conformidade.
Suporte à decisão financeira: Múltiplos agentes RAG podem realizar cálculos, encontrar informações meteorológicas, recomendar tendências de ações e mercado, analisar dados e muito mais. Analistas financeiros podem consultar sistemas que combinam dados internos de portfólio com informações de mercado externas, registros regulatórios e indicadores econômicos.
FAQs
P: O agentic RAG pode acessar múltiplos documentos simultaneamente?
A: Um agente RAG pode acessar, recuperar e comparar dados em vários documentos fornecidos. O sistema se destaca na síntese de informações de diversas fontes em uma única resposta.
P: Como o RAG agêntico difere do RAG padrão?
A: Um RAG clássico pode recuperar informações de uma única fonte, enquanto um RAG agêntico usa vários agentes para acessar e orquestrar dados de diversas fontes. O RAG tradicional é reativo, enquanto o RAG agêntico é proativo e inteligente.
P: Quais frameworks podem ser usados para criar aplicações de RAG agêntico?
A: Vários frameworks Python estão disponíveis com componentes e ferramentas prontos para uso para análise e monitoramento de agentes RAG. Esses frameworks incluem Phidata, LangGraph, Swarm, Microsoft Autogen, etc.
P: O RAG agêntico é sempre melhor do que o RAG tradicional?
A: Não necessariamente. Embora o RAG agêntico otimize os resultados com chamada de funções, raciocínio em várias etapas e sistemas multiagente, ele nem sempre é a melhor escolha. Para consultas simples, de fonte única, o RAG tradicional pode ser mais eficiente e econômico.
P: O RAG agêntico pode trabalhar com diferentes tipos de dados?
A: Sim, os sistemas modernos de RAG agêntico oferecem suporte a processamento multimodal, lidando com texto, imagens, áudio e outros formatos de dados estruturados e não estruturados.
- O que é RAG Agêntico?
- Principais Recursos do RAG Agêntico
- Como Funciona o RAG Agêntico
- Benefícios e Desafios do Agentic RAG
- Comparação do Agentic RAG com o RAG tradicional
- Casos de uso do Agentic RAG
- FAQs
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis