




Como a Tokopedia conseguiu uma experiência de pesquisa 10 vezes mais inteligente com a Milvus
10x mais inteligente
experiência de pesquisa
Melhorado
experiência do utilizador
Melhorado
escalabilidade e fiabilidade
Our search system has been much more intelligent, stable, and reliable using Milvus.
Rahul Yadav
Sobre a Tokopedia
A [Tokopedia] (https://www.tokopedia.com/) é a maior plataforma de comércio eletrónico da Indonésia, com uns impressionantes 90 milhões de utilizadores activos mensais e uma impressionante rede de 8,6 milhões de comerciantes. Com um alcance que se estende a 98% das regiões administrativas da Indonésia, a Tokopedia tornou-se o destino preferido do país para compras online.
A Tokopedia reconhece que o valor do seu extenso catálogo de produtos reside no facto de os compradores poderem descobrir sem esforço produtos adaptados às suas preferências. No seu compromisso inabalável de melhorar a relevância dos resultados de pesquisa, introduziram uma [pesquisa por semelhança] (https://zilliz.com/learn/vetor-similarity-search) na Tokopedia.
Quando o utilizador navega para a página de resultados da pesquisa no seu dispositivo móvel, notará um discreto botão "...". Ao clicar neste botão, o utilizador pode aceder a um menu que lhe oferece a interessante oportunidade de explorar produtos que coincidem com o que o utilizador está a ver.
Desafios da pesquisa baseada em palavras-chave
No passado, a Tokopedia Search utilizava o Elasticsearch como seu principal mecanismo de pesquisa e classificação de produtos. Cada pedido de pesquisa iniciava uma consulta ao Elasticsearch, que classificava os produtos com base na palavra-chave de pesquisa do utilizador. O Elasticsearch armazena as palavras-chave como sequências de valores numéricos, representando códigos ASCII ou UTF para letras individuais. Constrói um índice invertido para a identificação rápida de documentos que contenham palavras da consulta do utilizador e, subsequentemente, determina as melhores correspondências utilizando uma série de algoritmos de pontuação.
No entanto, estes algoritmos de pontuação não têm normalmente em conta a semântica das palavras-chave pesquisadas. Em vez disso, concentram-se em factores como a frequência com que as palavras aparecem nos documentos, a proximidade entre elas e outras informações estatísticas. Embora os humanos possam compreender o significado subjacente à representação ASCII das palavras, os computadores necessitam de um algoritmo fiável para comparar a semântica das palavras codificadas em ASCII.
Representação vetorial
Uma das soluções para o problema que a equipa da Tokopedia encontrou foi criar uma nova forma de representar as palavras-chave, que mostra as letras de uma palavra e dá informações sobre o seu significado. Por exemplo, podiam codificar as palavras normalmente utilizadas com a palavra-chave de pesquisa para fornecer um contexto provável. A partir daí, podem assumir que contextos semelhantes indicam conceitos semelhantes e compará-los utilizando técnicas matemáticas. É até possível codificar frases inteiras com base no seu significado.
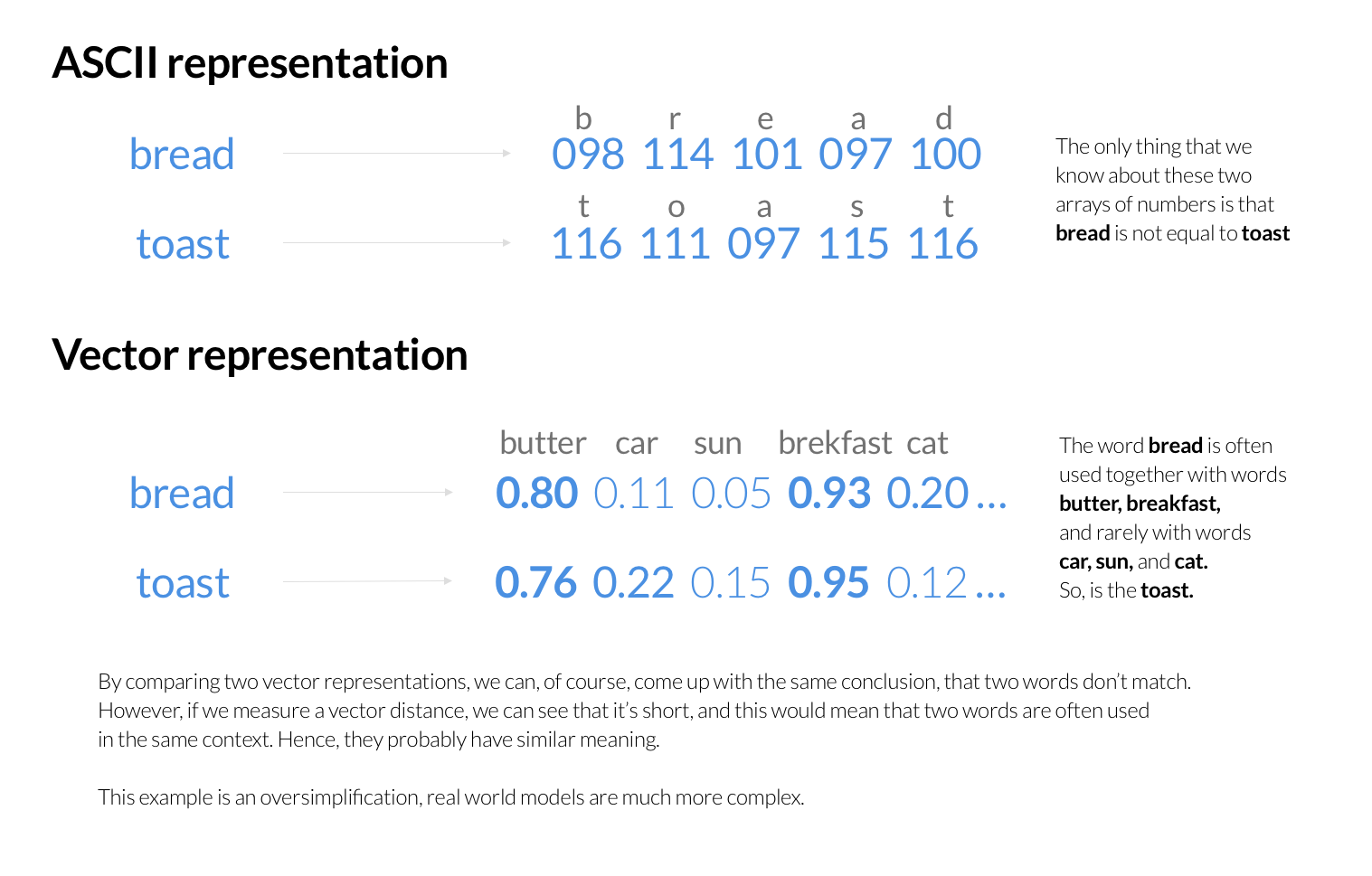
Selecionar o Milvus como motor de pesquisa de semelhanças vectoriais
Agora que a Tokopedia possui vectores de caraterísticas, o desafio restante reside na recuperação eficiente de vectores a partir do extenso conjunto de dados que coincidem com o vetor alvo. Ao explorar os motores de pesquisa de vectores, realizámos avaliações de prova de conceito (POC) em várias pilhas de pesquisa de vectores disponíveis no GitHub, incluindo FAISS, Vearch e Milvus.
A nossa preferência inclina-se para o Milvus com base nos resultados dos nossos testes de carga. Comparado com o Milvus, o FAISS funciona mais como uma biblioteca subjacente e, consequentemente, é menos fácil de utilizar. À medida que nos aprofundámos no Milvus, adoptámo-lo pelas seguintes razões:
- O Milvus revelou-se extremamente fácil de utilizar**. Descobriram que só é necessário puxar a sua imagem Docker e ajustar os parâmetros para se adequarem aos seus casos de utilização específicos.
- O Milvus oferece uma gama mais ampla de índices suportados**. Além de FAISS, HSNW, DISK_ANN e ScaNN, há 11 índices para escolher.
- O Milvus fornece documentação completa para ajudar os utilizadores na sua implementação**.
Em suma, o Milvus é de fácil utilização, com documentação clara e apoio fiável da comunidade para quaisquer problemas que possam surgir.
Milvus em produção
Depois de implementarem o Milvus como o seu motor de pesquisa de vectores de caraterísticas, utilizaram-no no seu serviço de anúncios para fazer corresponder palavras-chave de baixa taxa de preenchimento com palavras-chave de alta taxa de preenchimento. Configuraram e executaram um nó autónomo num ambiente de desenvolvimento (DEV), que funcionou sem problemas e proporcionou uma impressionante taxa de cliques (CTR) e uma taxa de conversão (CVR) 10 vezes superior.
No entanto, surgiu uma preocupação potencial. Se um nó autónomo falhasse, tornaria todo o serviço inacessível. Por isso, a equipa da Tokopedia mudou para uma implementação HA do Milvus.
Milvus oferece duas ferramentas: Mishards, um middleware de fragmentação de cluster, e Milvus-Helm para configuração simplificada. Na Tokopedia, eles usam playbooks Ansible para a configuração da infraestrutura, o que os leva a criar um playbook para orquestrar a infraestrutura. O diagrama abaixo mostra como o Mishards funciona.
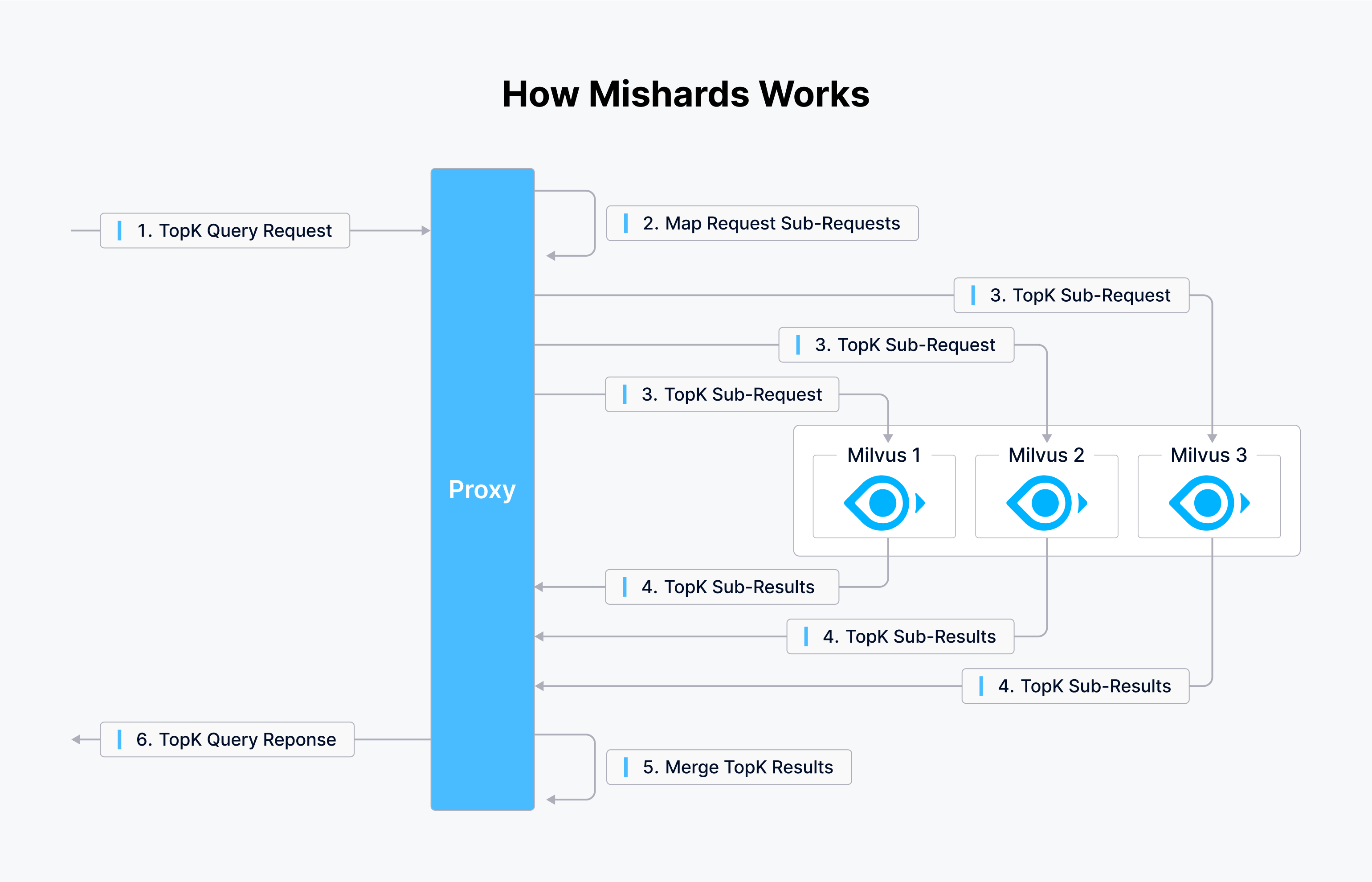
Mishards facilita o fluxo contínuo de pedidos de upstream para downstream, dividindo os pedidos de upstream em sub-módulos, reunindo resultados de sub-serviços e, subsequentemente, entregando esses resultados de volta à fonte de upstream.
A arquitetura da solução de cluster baseada em Mishards é apresentada abaixo.
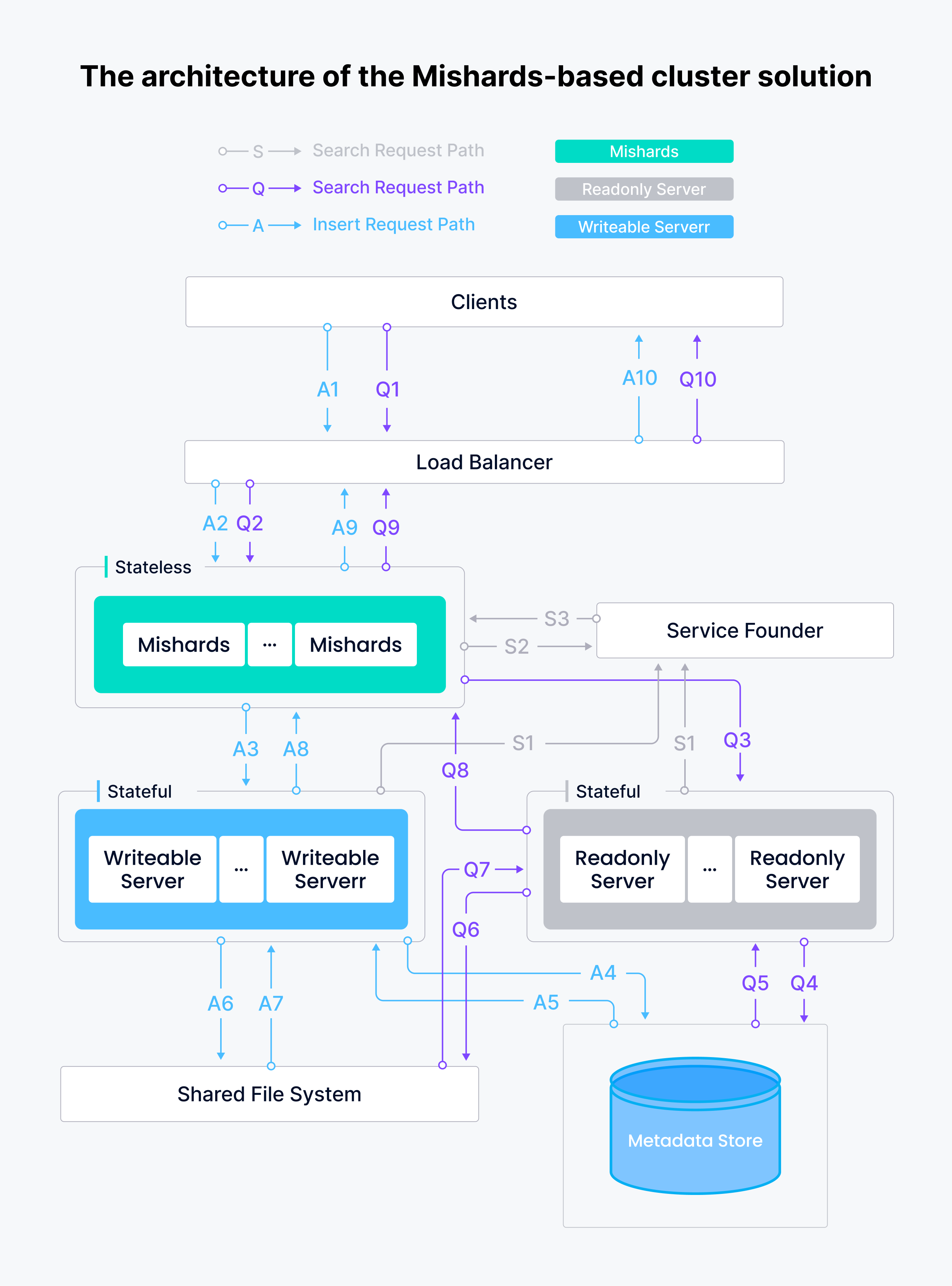
O sistema de serviço de pesquisa semântica da Tokopedia inclui um nó gravável, dois nós apenas de leitura e uma instância de middleware Mishards, todos implementados no GCP utilizando o Milvus Ansible. O sistema tem sido consideravelmente mais inteligente, estável e fiável.
Como é que a indexação vetorial acelera a pesquisa de semelhanças?
A consulta eficiente de grandes conjuntos de dados vetoriais em mecanismos de pesquisa de similaridade requer uma indexação adequada. Esse processo organiza os dados e acelera o processo de pesquisa, tornando-o essencial para lidar com conjuntos de dados com milhões, bilhões ou até trilhões de vetores. Uma vez indexado um conjunto de dados vectoriais maciço, é possível direcionar as consultas para clusters ou subconjuntos de dados com maior probabilidade de conterem vectores semelhantes à consulta de entrada. No entanto, esta abordagem pode sacrificar a precisão para obter consultas mais rápidas em grandes dados vectoriais.
Para compreender melhor, pense na indexação como a ordenação alfabética de palavras num dicionário. Ao procurar uma palavra-chave, pode navegar rapidamente para uma secção que contenha apenas palavras com a mesma letra inicial, acelerando drasticamente a procura da definição da palavra de entrada.
Resumo
A busca da Tokopedia por uma funcionalidade de pesquisa superior levou-os ao Milvus, um divisor de águas na pesquisa semântica. Com o Milvus, desbloquearam o poder da representação vetorial e criaram um sistema de pesquisa 10 vezes mais inteligente que melhorou drasticamente a experiência do utilizador. O seu serviço de pesquisa está também altamente disponível, garantindo operações sem falhas. Esta viagem com Milvus transformou a pesquisa da Tokopedia, prometendo um futuro de resultados de pesquisa personalizados e significativos. Com a Milvus, estão a revolucionar o comércio eletrónico na Indonésia e não só.
*Este post foi escrito por Rahul Yadav, um engenheiro de software da Tokopedia. Ele foi editado e republicado aqui com permissão. *