




Como uma plataforma global líder em GPU e IA usa o Milvus para escalar a mineração de dados multimodais para seu sistema de direção autônoma

-30% de custo
Menor consumo de memória e armazenamento por meio de chaves primárias baseadas em disco e layout de segmento otimizado no Milvus 2.5.
Escala 10×
Margem comprovada para escalar mais uma ordem de grandeza sem redesenho ou surpresas de custo.y sem alterações arquitetônicas ou custos inesperados.
Confiabilidade Empresarial
Produção contínua em escala massiva sem incidentes graves.
Pesquisa híbrida
Pesquisa vetorial unificada e filtragem de metadados para oferecer suporte a consultas complexas.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
Sobre a Empresa
O cliente é líder global em computação acelerada e inteligência artificial, com décadas de experiência na criação de GPUs e plataformas de software usadas em jogos, robótica, data centers e aplicações automotivas. Uma de suas principais iniciativas é uma plataforma de ponta a ponta para assistência avançada ao motorista e direção autônoma. Essa plataforma oferece suporte a todo o ciclo de vida do desenvolvimento de direção autônoma — desde a coleta de dados em larga escala e o treinamento de modelos de IA até a inferência no veículo e a tomada de decisões em tempo real.
Por trás dessa plataforma está a organização de Engenharia de Dados de Veículos Autônomos (AV) da empresa, responsável pela infraestrutura de dados que impulsiona sua tecnologia de direção autônoma. Cada hora de condução no mundo real produz terabytes de dados de sensores multimodais, incluindo fluxos de câmeras sincronizados, nuvens de pontos LiDAR, medições de radar, dados de localização de alta precisão e metadados detalhados do estado do veículo. A missão da equipe é tornar esse conjunto de dados massivo e em constante crescimento pesquisável, detectável e operacionalmente utilizável por centenas de engenheiros que precisam revelar cenários de cauda longa, identificar casos de borda raros e validar o comportamento dos modelos em condições do mundo real.
Para atender a esses requisitos, a equipe criou um sistema de mineração de dados multimodal capaz de pesquisar dezenas de bilhões de pontos de dados de sensores indexados coletados de frotas de teste. O sistema converte dados brutos de sensores em embeddings vetoriais para que os engenheiros possam executar consultas profundas e sensíveis ao contexto — por exemplo: “veículos entrando pela direita sob chuva forte”, “pedestres atravessando ao anoitecer em cruzamentos sem sinalização” ou “rotatórias de duas faixas com visibilidade ocluída.”
Inicialmente, o sistema era executado no FAISS, mas, à medida que o volume de dados e as demandas operacionais cresceram, a equipe migrou para o Milvus para obter maior escalabilidade, menor esforço de manutenção e confiabilidade mais robusta em produção. O Milvus forneceu um caminho claro para oferecer suporte a uma ordem de grandeza a mais de dados, reduzir a sobrecarga operacional e melhorar a eficiência de clustering, indexação e armazenamento à medida que a frota de direção autônoma continuava a se expandir.
O Desafio: o FAISS Não Conseguia Escalar
O Gargalo da Gestão de Dados
O design inicial desse sistema de mineração de dados era intencionalmente simples. Cada sessão de direção autônoma — normalmente uma viagem de uma hora — era processada em frames, transformada em embeddings vetoriais por meio dos modelos proprietários da empresa e agrupada em arquivos de índice FAISS, geralmente um por dia.
Embora essa estrutura funcionasse bem inicialmente, ela não escalava. À medida que o conjunto de dados crescia rapidamente, o número de arquivos de índice também aumentava — chegando, eventualmente, a centenas de milhares. Cada um representava um pequeno bolsão isolado de informações. Pesquisar entre eles introduzia uma complexidade significativa: os índices diários frequentemente continham dados sobrepostos, exigindo uma lógica intrincada para filtrar e mesclar metadados. Na prática, isso significava que, embora pesquisar dentro de um único dia funcionasse bem, a maioria dos usuários queria consultar condições mais amplas — como cenários específicos de direção abrangendo vários dias ou regiões. Essas pesquisas precisavam acessar muitos arquivos de índice separados ao mesmo tempo, o que era computacionalmente caro. Os engenheiros frequentemente tinham que restringir manualmente seu escopo, adivinhando quais arquivos poderiam conter os dados relevantes antes de executar uma consulta. Esse processo de tentativa tornava a pesquisa lenta e pouco confiável.
A Lacuna de Flexibilidade
O FAISS não é um banco de dados — é uma biblioteca. Ele é adequado para encontrar os vizinhos mais próximos de um determinado vetor, mas sistemas de pesquisa de nível de produção exigem muito mais do que apenas correspondência rápida por similaridade.
Na prática, os engenheiros não queriam pesquisar em todo o corpus de uma só vez. Eles precisavam de filtragem contextual — para encontrar, por exemplo, “quadros de câmera frontal capturados sob chuva leve em vias urbanas” ou “percursos noturnos em rodovias da Califórnia”. Alcançar esse nível de precisão exigia combinar busca vetorial com filtros de metadados, como tipo de câmera, horário, localização, clima e versão do modelo. Mas o FAISS não oferecia esses recursos nativamente. Para preencher essa lacuna, a equipe teve que construir uma pilha complexa de lógica personalizada: bancos de dados de metadados separados, planejadores de consulta sob medida para decidir quais índices FAISS varrer e pós-filtragem manual dos resultados após a recuperação.
Com o tempo, essas customizações criaram um grande problema de escalabilidade. Diferentes ângulos de câmera, múltiplos modelos de embedding e pipelines de pré-processamento versionados exigiam estratégias de gerenciamento distintas. Não havia um conceito integrado de coleções, partições ou agrupamento lógico de dados — apenas arquivos de índice. Cada camada de organização, do versionamento de dados à filtragem de consultas, precisava ser escrita e mantida em código personalizado. O sistema funcionava — mas ao custo de flexibilidade, manutenibilidade e escalabilidade de longo prazo.
O Problema de Escalabilidade
O sistema já estava sobrecarregado com bilhões de vetores, e os veículos de teste da empresa geravam novos dados todos os dias. Enquanto isso, as equipes de pesquisa estavam introduzindo novos modelos de embedding, cada um exigindo reindexação em larga escala de dados históricos. Era apenas uma questão de tempo até que as cargas de trabalho crescessem dez vezes, mas a configuração do FAISS baseada em arquivos não tinha uma forma prática de escalar para esse nível.
Pior ainda, cada novo conjunto de dados significava mais arquivos de índice e mais atualizações manuais no armazenamento de metadados. Não havia sharding automático, nem balanceamento de carga integrado, nem uma forma de adicionar capacidade sob demanda. A arquitetura havia se tornado antiquada — estática, trabalhosa e resistente ao crescimento.
Os Custos Ocultos de Engenharia
Além dos custos de nuvem, o maior desafio era a sobrecarga oculta de engenharia para manter o FAISS. Os engenheiros precisavam gerenciar sistemas complexos de metadados, projetar lógica personalizada para distribuir dados e atualizar manualmente milhões de arquivos de índice. Com o tempo, essa sobrecarga desacelerou a inovação: o desempenho da busca se degradou, os ciclos de desenvolvimento ficaram mais longos e novas ideias nunca passaram do quadro branco. À medida que os volumes de dados continuavam a crescer, o sistema se tornava cada vez mais rígido e frágil. Ficou claro que tentar atualizar a configuração legada já não era mais sustentável.
A Solução: Rearquitetando para Escala com Milvus
Para superar esses desafios, a equipe de Dados de AV precisava de um sistema capaz de lidar com dezenas de bilhões de vetores hoje, com um caminho claro para crescimento de 10× e além. Ele precisava oferecer filtragem robusta, simplicidade operacional e — acima de tudo — confiabilidade em produção com manutenção mínima.
O Processo de Avaliação
Em vez de realizar uma comparação ampla entre todos os bancos de dados vetoriais emergentes, a equipe se concentrou no popular Milvus Vector Database, executando uma prova de conceito com 400–500 milhões de vetores — grande o suficiente para expor gargalos do mundo real. Durante os testes, os engenheiros replicaram todo o fluxo de trabalho de dados: indexando conjuntos de dados com diferentes tipos de índice para comparar trade-offs, medindo o tempo de indexação para estimar atualizações diárias em lote e fazendo benchmarking de latência sob combinações de filtros e padrões de consulta realistas. Eles levaram deliberadamente o Milvus ao limite, executando buscas complexas com múltiplas condições e escalando volumes de dados para testar a estabilidade.
Por que Milvus?
Os resultados da prova de conceito fizeram do Milvus a escolha clara para a equipe de Dados de AV.
Desempenho de consulta aceitável: O Milvus entregou consistentemente latências de consulta na casa dos segundos, mesmo para as buscas mais complexas e intensivas em filtros — bem dentro dos requisitos para cargas de trabalho internas de mineração de dados.
Filtragem nativa e flexibilidade de consulta: Os engenheiros agora podiam combinar busca por similaridade vetorial com filtros de metadados em uma única consulta—capacidades que antes exigiam extenso código personalizado no FAISS.
Estrutura de dados organizada: Embeddings vetoriais de diferentes modelos eram armazenados em coleções separadas, cada uma particionada por atributos como data de captura ou região. O Milvus gerenciava automaticamente a distribuição de dados entre segmentos, eliminando o peso do gerenciamento manual de arquivos.
Escalabilidade contínua: À medida que os dados cresciam, a equipe adicionava mais nós para expandir a capacidade. A arquitetura distribuída do Milvus escalava linearmente sem exigir redesenhos do sistema.
Comunidade open-source ativa: Durante os testes, os engenheiros de Dados de AV receberam suporte rápido e prático da equipe do Milvus e de colaboradores da comunidade, construindo uma forte confiança no Milvus como um ecossistema confiável e pronto para produção.
Implementando a Nova Arquitetura com o Milvus
Em sua essência, a arquitetura deste sistema de mineração de dados multimodal é simples—mas executá-la em escala massiva exige engenharia cuidadosa e precisão. Dados brutos de vídeo de trajetos de veículos autônomos—horas de filmagem contínua de múltiplas câmeras—fluem para um pipeline de processamento que extrai quadros individuais ou clipes curtos, geralmente com alguns segundos de duração.
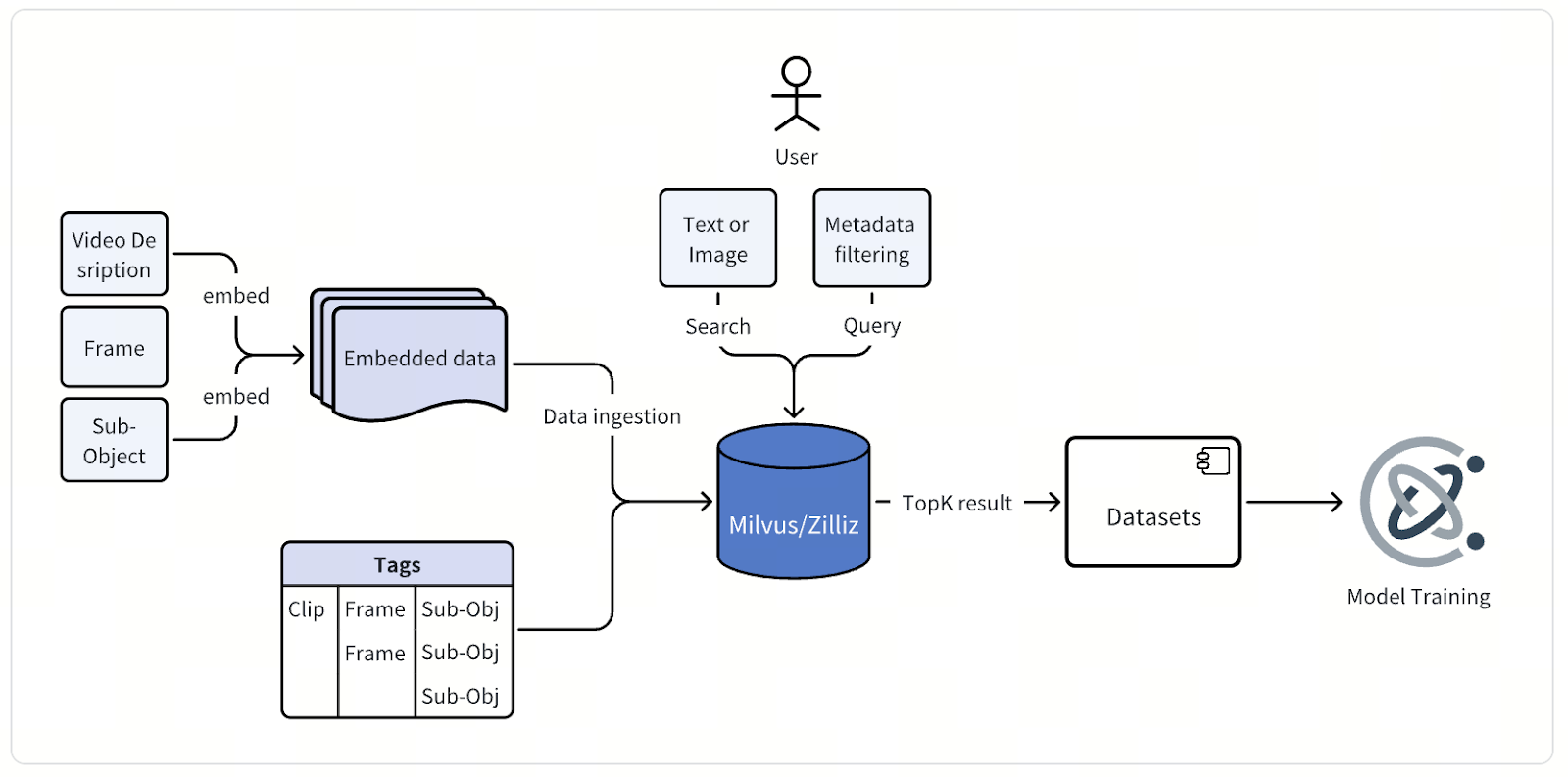
Cada quadro ou clipe então passa pelos modelos de embedding proprietários da empresa, criados especificamente para direção autônoma. Para dados de imagem, a equipe usa modelos derivados da arquitetura CLIP, personalizados e ajustados para capturar semânticas específicas de vias. Para dados de vídeo, eles contam com seus próprios modelos internos, uma família de modelos fundamentais para aplicações de IA física. Juntos, esses modelos convertem dados visuais em embeddings vetoriais de alta dimensionalidade que codificam um rico significado contextual.
Uma vez gerados, esses embeddings vetoriais—junto com metadados detalhados—são armazenados e indexados no Milvus Vector Database. Cada ponto de dados carrega atributos que descrevem a sessão de condução, posição da câmera, timestamp, estado do veículo, localização e condições climáticas, entre outros. Esses metadados também são indexados para permitir buscas filtradas rápidas e precisas em conjuntos de dados massivos.
Por meio de uma interface de consulta unificada, os engenheiros podem pesquisar os dados de várias maneiras. Eles podem digitar uma descrição em texto, fazer upload de uma imagem ou vídeo de referência, ou combinar busca vetorial com filtros de metadados para identificar exatamente o que precisam. Uma única consulta poderia pedir, por exemplo, “cruzamentos urbanos à noite com pedestres atravessando”, e o Milvus retorna os quadros ou clipes mais relevantes para revisão, análise e aprimoramento do modelo.
Os Benefícios: Eficiência de Custos, Estabilidade e Escala
Após mais de um ano em operação contínua, o Milvus provou ser não apenas tecnicamente sólido, mas operacionalmente transformador. Os resultados a seguir mostram como sua arquitetura e seu ecossistema se traduziram em eficiência real em escala.
Operações Mais Simples, Menos Dores de Cabeça e Desenvolvimento Mais Rápido
Migrar de centenas de milhares de arquivos FAISS para o Milvus removeu uma camada inteira de sobrecarga operacional. Não há mais gerenciamento manual de arquivos de índice, scripts ad-hoc nem lógica de consulta personalizada. A distribuição de dados, o gerenciamento de segmentos e o roteamento de consultas agora acontecem automaticamente. As atualizações são diretas, o monitoramento é unificado, e as métricas contam uma história clara. O resultado é menos tempo gasto na manutenção de sistemas e mais tempo minerando dados em busca de insights.
Menor Sobrecarga de Engenharia Mais 30% de Redução Adicional de Custos Após a Atualização para o Milvus 2.5
A implantação do Milvus reduziu imediatamente tanto os custos de infraestrutura quanto os de engenharia. A migração do sistema baseado em arquivos do FAISS eliminou o gerenciamento manual de arquivos e o rastreamento complexo de metadados, economizando tempo significativo dos desenvolvedores e esforço operacional. A atualização do Milvus 2.4 para o Milvus 2.5 então proporcionou uma redução adicional de 30% nos custos de infraestrutura, graças ao mapeamento de memória mais inteligente, ao armazenamento de chaves primárias baseado em disco e ao gerenciamento de segmentos mais eficiente.
Juntas, essas melhorias permitem que a equipe de AV Data execute as mesmas cargas de trabalho em instâncias AWS menores — ou indexe muito mais dados — sem aumentar os gastos ou a sobrecarga de manutenção. Encorajada por esses resultados, a equipe planeja testar o Milvus 2.6, que introduz novos tipos de índice como RaBitQ e outras otimizações que devem impulsionar ainda mais tanto o desempenho quanto a eficiência de custos. Para grandes cargas de trabalho em lote offline, a velocidade de construção de índices continua sendo um desafio central. Graças às contribuições da equipe NVIDIA cuVS, o Milvus agora oferece suporte a construções de índice aceleradas por GPU com serving baseado em CPU (GPU-build, CPU-serve). Essa abordagem acelera significativamente a construção de índices, mantendo a eficiência de custos — e espera-se que aumente ainda mais a vantagem de preço-desempenho do Milvus em cargas de trabalho de direção autônoma.
Escalabilidade Integrada, Comprovada na Prática
A plataforma agora indexa dezenas de bilhões de vetores e ingere novos dados diariamente sem atritos. A modelagem interna confirma que ela pode escalar mais 10× sem redesign ou surpresas de custo — transformando o que antes era uma restrição de capacidade em uma vantagem estratégica de longo prazo. Com essa folga, a equipe pode expandir de indexar dois anos de dados recentes de condução para cobrir todo o arquivo histórico, permitindo buscas em todas as sessões de direção já registradas. Eles também podem executar múltiplos modelos de embedding em paralelo para otimizar a recuperação para diferentes tipos de consulta e até mesmo reter dados indefinidamente em vez de removê-los com o tempo. Escalabilidade aqui significa não apenas lidar com mais dados, mas permitir aprendizado contínuo e progresso mais rápido rumo a uma direção autônoma mais segura.
Confiabilidade Empresarial em Escala Massiva
Em mais de um ano de produção ininterrupta, o Milvus lidou discretamente com dezenas de bilhões de vetores, com ingestão e consultas diárias — sem um único incidente grave. O sistema roda de forma estável em segundo plano, exigindo supervisão mínima. Sem interrupções no fim de semana, sem patches emergenciais — apenas desempenho consistente e previsível. Esse tipo de confiabilidade nessa escala se traduz em menos riscos operacionais, menos combate a incêndios e mais foco em criar valor em vez de gerenciar infraestrutura.
Busca Mais Rica, Fluxos de Trabalho Mais Inteligentes
O Milvus combina busca vetorial com filtragem por metadados, oferecendo aos engenheiros da empresa novas maneiras de analisar dados complexos de direção. Eles podem, por exemplo, encontrar todas as imagens de zonas de construção capturadas por câmeras frontais à luz do dia ou filtrar por horário e localização para comparar o comportamento do modelo entre atualizações e regiões. Diferentes coleções armazenam embeddings de diferentes modelos, permitindo que as equipes testem novas arquiteturas sem impactar a produção. Esses recursos aceleram a experimentação e revelam insights que antes exigiam extensa engenharia personalizada.
Uma Comunidade Forte Que Multiplica o Impacto
Além da tecnologia, a comunidade open-source do Milvus tem sido uma parte fundamental do sucesso da empresa. Durante os testes e a implantação, os engenheiros receberam suporte rápido diretamente de colaboradores e mantenedores do Milvus. Essa responsividade reduziu o tempo de inatividade, acelerou a depuração e manteve o progresso no rumo certo. Com o tempo, a comunidade ativa continuou a agregar valor ajudando a validar novas ideias, suavizar atualizações e compartilhar melhores práticas. Para esse cliente, o Milvus não é apenas um software confiável — é um ecossistema colaborativo que fortalece a plataforma e entrega eficiência de longo prazo.
Lições da Produção
Escolhendo o Índice Certo: Equilibrando Escala, Custo e Precisão
Escolher um índice é uma das decisões práticas mais importantes ao criar um sistema de busca vetorial. O Milvus oferece suporte a muitos tipos de índice, cada um com seus próprios trade-offs em velocidade, uso de memória e precisão. Para a equipe de AV Data, o objetivo era encontrar um equilíbrio entre escala de dados, custo de infraestrutura e precisão da busca — não apenas escolher a opção mais rápida.
Depois de testar várias configurações, eles selecionaram o IVF_FLAT, que agrupa vetores em clusters e realiza uma busca exata dentro dos relevantes. Ele não é a opção mais rápida nem a mais compacta, mas, para dezenas de bilhões de vetores e necessidades moderadas de latência, entregou a combinação certa de desempenho e precisão, mantendo a eficiência.
A equipe descobriu que, quando um índice se ajusta bem à carga de trabalho, raramente há necessidade de mudar para algo mais novo. Na prática, um índice bem alinhado economiza mais tempo e recursos do que perseguir pequenos ganhos de desempenho. Para sistemas de grande escala, um desempenho estável e previsível é o que mantém as operações fluindo sem problemas.
Mapeamento de Memória: Trocando Latência por Custo em Escala
Uma das escolhas técnicas mais eficazes da equipe foi usar mapeamento de memória (Mmap) para controlar os custos de infraestrutura. Em configurações tradicionais, manter todos os dados vetoriais na RAM exigiria instâncias enormes e de alto custo. Com o mapeamento de memória no Milvus, a maior parte dos dados permanece em disco enquanto o sistema operacional mantém automaticamente na memória as partes acessadas com frequência. Esse design introduz alguma latência — leituras em disco são mais lentas do que na RAM —, mas mantém um desempenho previsível e um uso eficiente de recursos. Para a carga de trabalho da empresa, esse trade-off fazia todo sentido. Seus usuários são engenheiros executando consultas analíticas, não usuários finais esperando respostas instantâneas, e a concorrência permanece baixa.
Operações de Exclusão: Quando Pequenas Suposições Quebram em Escala
Uma das maiores lições da equipe veio de algo que parecia simples: excluir dados. Na arquitetura append-only do Milvus, os vetores excluídos não são removidos imediatamente — eles são marcados para exclusão e limpos posteriormente por meio de compactação em segundo plano. Durante os testes, excluir milhões de vetores inesperadamente acionou a reindexação de bilhões, pois os filtros de Bloom produziram falsos positivos em milhares de segmentos. O que parecia ser uma limpeza rotineira acabou sobrecarregando os nós de dados e travando jobs.
A correção veio de entender como o Milvus gerencia os dados e ajustar o fluxo de trabalho — ajustando filtros de Bloom, usando chaves de partição para direcionar exclusões com precisão e mudando para carregamento em massa apenas por inserção. A conclusão: em escala, até operações simples podem se comportar de maneira diferente, e entender os detalhes internos do sistema é essencial para manter o desempenho previsível.
Olhando para o Futuro
A equipe está se preparando para adotar o Milvus 2.6 pouco depois do lançamento, confiante de que novos tipos de índice e otimizações arquiteturais trarão outro salto em eficiência. As discussões iniciais com a equipe de engenharia do Milvus apontam para reduções contínuas de custo e melhor utilização de recursos, que a empresa planeja validar por meio de benchmarks em escala completa.
Olhando mais adiante, a equipe vê oportunidades empolgantes para expandir a funcionalidade e a escala. Recursos como a busca híbrida, que combina consultas de texto e vetoriais, podem abrir novas formas de explorar dados multimodais, enquanto filtros aprimorados no estilo de banco de dados simplificarão fluxos de trabalho complexos. O próximo lançamento do Milvus 3.0 também promete arquiteturas em camadas, permitindo que a empresa mantenha acesso rápido a dados recentes enquanto armazena seu arquivo histórico completo de forma eficiente. Juntos, esses avanços darão à empresa uma plataforma de dados que escala sem esforço, oferece suporte a capacidades de busca mais profundas e cresce com mais eficiência.
Além disso, espera-se que a introdução e o amadurecimento das construções de índices aceleradas por GPU com NVIDIA cuVS e atendimento baseado em CPU (GPU-build, CPU-serve) no Milvus entreguem uma melhoria transformadora no desempenho de indexação offline. Ao aproveitar GPUs NVIDIA e as bibliotecas cuVS altamente otimizadas, o Milvus pode construir índices vetoriais em larga escala de forma dramaticamente mais rápida do que pipelines baseados apenas em CPU, enquanto continua a atender consultas de forma econômica em CPU. Isso reduz significativamente o tempo entre dados e consulta, permite ciclos de atualização de índices mais frequentes e amplifica ainda mais a vantagem de custo-benefício do Milvus para direção autônoma e outras cargas de trabalho multimodais em larga escala, nas quais iteração rápida e dados atualizados são críticos.
Conclusão
A equipe de Dados AV do cliente construiu uma poderosa plataforma de mineração de dados que acelera o desenvolvimento de direção autônoma ao tornar volumes massivos de dados multimodais pesquisáveis e acionáveis. A migração do FAISS para o Milvus resolveu desafios críticos de escalabilidade, flexibilidade e complexidade operacional—ao mesmo tempo em que entregou economias de custo mensuráveis e notável estabilidade em produção.
Depois de mais de um ano de operação contínua e dezenas de bilhões de vetores indexados, a plataforma provou que o Milvus pode servir como uma base de nível de produção para busca vetorial em larga escala e específica de domínio. O sistema ingere novos dados diariamente, oferece suporte a engenheiros em todos os programas de direção autônoma da empresa e oferece um caminho claro para escalar 10× mais sem rearquitetura.
Para organizações que estão construindo sistemas de busca vetorial com escala massiva de dados, a eficiência de custos importa, e a estabilidade supera a latência abaixo de milissegundos. A experiência da empresa é instrutiva. O Milvus demonstra que um banco de dados vetorial de código aberto pode não apenas atender às demandas de produção, mas continuar a melhorar ao longo do tempo—entregando uma espinha dorsal confiável, escalável e preparada para o futuro para infraestrutura de IA no mundo real.