




Otimização da IA de conversação na FARFETCH

15x
tempo de indexação mais rápido
5x
tempo de consulta mais rápido
Aumento da conversão
através de recomendações de produtos mais relevantes
Vários tipos de métricas
para suportar vários casos de utilização
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
Sobre a FARFETCH
A FARFETCH, uma força líder no retalho de moda online, está a ultrapassar os limites das compras digitais com a sua mais recente inovação, a iFetch. Este sistema de IA conversacional foi concebido para trazer o serviço personalizado e de alta qualidade, tipicamente encontrado em lojas físicas de luxo, para o domínio digital. A FARFETCH Chat R&D está a desenvolver um sistema de recomendação conversacional especializado como parte desta iniciativa. Este chatbot, integrado no iFetch, permite aos utilizadores interagir com o catálogo de produtos FARFETCH através de linguagem natural e imagens. Por exemplo, um utilizador pode carregar uma fotografia de um casaco de que gosta e o chatbot responderá com uma seleção de casacos semelhantes. Ao combinar perfeitamente tecnologias avançadas de IA com um foco na experiência do utilizador, a FARFETCH pretende redefinir o que os clientes podem esperar das compras online.
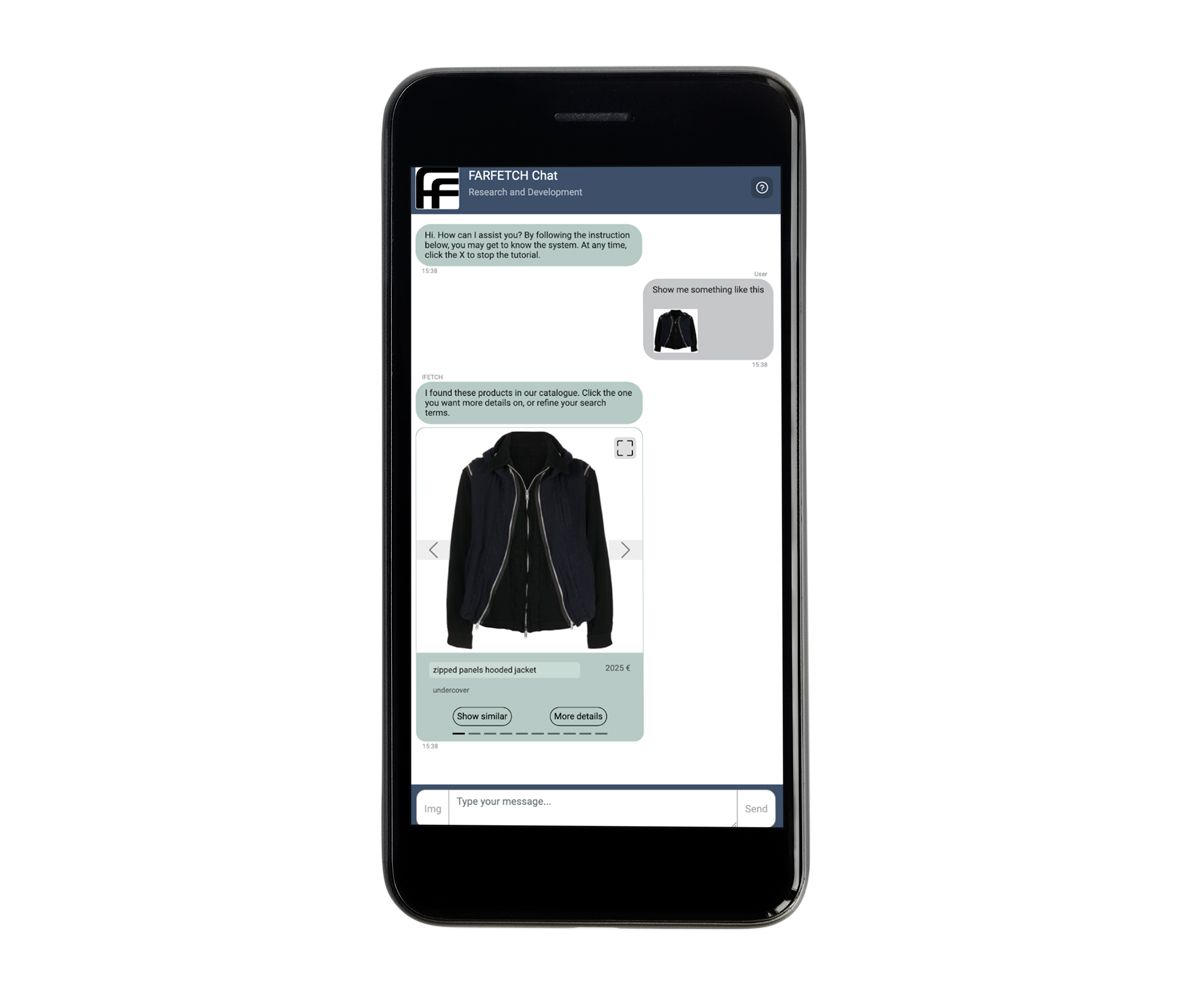 O FARFETCH Chat mostra uma montra semelhante
O FARFETCH Chat mostra uma montra semelhante
No entanto, depararam-se com um desafio significativo: com os seus metadados limitados, os catálogos de produtos tradicionais tinham dificuldade em captar as relações intrincadas e os atributos matizados da sua extensa gama de produtos. Para resolver este problema, utilizaram algoritmos de aprendizagem automática para desenvolver "product embeddings" - pontos de dados de alta dimensão que servem como uma linguagem robusta para o seu sistema de IA. Isto permite que o chatbot compreenda e recomende produtos com uma precisão sem precedentes. No entanto, o armazenamento e a recuperação dessas incorporações em tempo real representaram outro obstáculo, exigindo uma solução de armazenamento especializada capaz de lidar eficientemente com dados de alta dimensão.
A importância das bases de dados vectoriais
As bases de dados de vectores, também conhecidas como motores de semelhança de vectores (VSE), são bases de dados especializadas concebidas para lidar com dados complexos e de elevada dimensão designados por embeddings de vectores. Estas bases de dados utilizam algoritmos de Vizinhos Mais Próximos Aproximados (ANN), que são indispensáveis para uma recuperação de dados rápida e precisa. Esta caraterística é particularmente vital para o iFetch, que exige interações em tempo real com os clientes para fornecer recomendações instantâneas de produtos e responder às suas perguntas. A escolha de uma base de dados vetorial não é uma mera questão técnica; é uma decisão estratégica que afecta diretamente o desempenho, a robustez e a eficiência do iFetch. Realizaram um estudo de benchmarking abrangente para garantir que seleccionavam o VSE mais adequado. Este estudo de referência envolveu a avaliação de várias bases de dados, incluindo Vespa, Milvus, Qdrant, Weaviate, Vald e Pinecone, com base em diversos critérios, como a velocidade de indexação, a velocidade de consulta e a escalabilidade. A avaliação comparativa também incluiu testes de stress para avaliar o desempenho de cada VSE sob picos de carga e cenários de recuperação e ativação pós-falha para avaliar a resiliência.
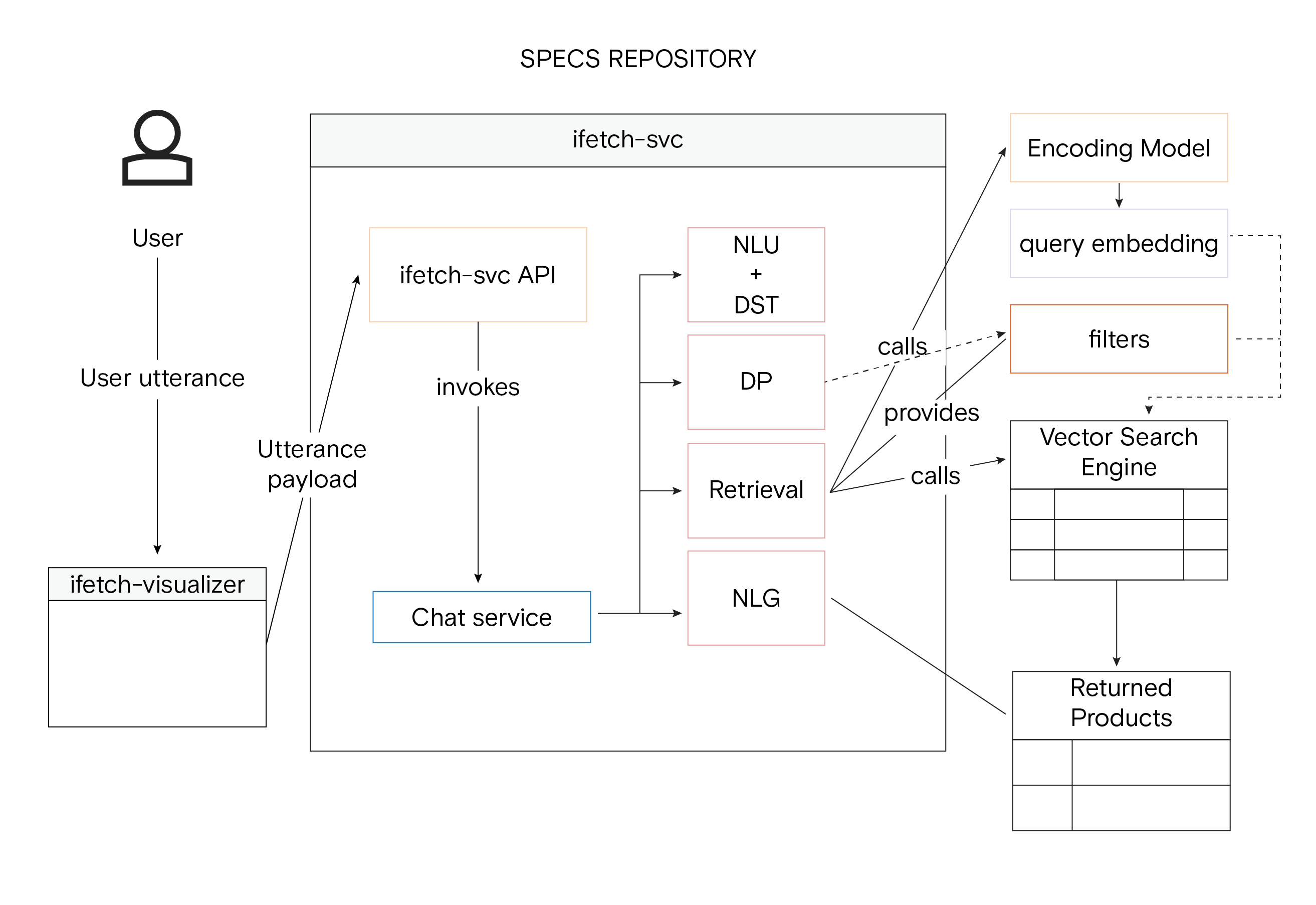 Representação holística da arquitetura do sistema iFetch com Vetor Similarity Searc
Representação holística da arquitetura do sistema iFetch com Vetor Similarity Searc
Critérios de referência e seleção
O processo de benchmarking conduzido pela equipa da Farfetch foi exaustivo e metódico, abrangendo uma vasta gama de factores cruciais para o sucesso a longo prazo do iFetch. Estes incluíam a diversidade de tipos de índices, tipos de métricas, capacidades de serviço de modelos e adoção pela comunidade. Também consideraram a qualidade da documentação e a disponibilidade de apoio, uma vez que estes factores teriam impacto na facilidade de implementação e na manutenção contínua.
| Feature | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone | |||
|---|---|---|---|---|---|---|---|---|---|
| Modelo de Consistência | N/D | Consistência Forte | Consistência Eventual | Consistência Eventual | N/D | Consistência Eventual | N/D | Consistência Eventual | |
| Suporte para GraphQL | N/A | N/A | Sim | N/A | N/A | N/A | N/A | ||
| Sharding | Não (A ser abordado data desconhecida) | Sim | Sim | Sim | Sim | N/A | N/A | N/A | |
| Paginação | N/A | Não (Esperado na versão 2.2 em 2022.3) | Sim | Sim | N/A | N/A | |||
| Tipos de métricas | Produto interno Similaridade de cosseno Euclidiana (L2) | L2 Produto interno Hamming Jaccard Tanimoto Superestrutura Subestrutura | Cosseno | Euclidiana Angular Produto Interno Geo graus Hamming | L1 L2 Ângulo Hamming Cosine Ângulo Normailizado Cosine Normalizado Jaccard | Euclidean Cosine Produto Interno | |||
| Dimensão máxima do vetor | N/A | N/A | 32 768 | N/A | max.MaxInt64 | N/A | |||
| Tamanho máximo do índice | N/D | N/D | N/D | Ilimitado | N/D | N/D | N/D | N/D | N/D |
| Tipos de índice | HNSW | ANNOY HNSW IVF_PQ IVF_SQ8 IVF_FLAT FLAT IVF_SQ8_H RNSG | NHSW | HNSW BM25 | N/A | Proprietário | |||
| Model Serving | N/A | N/A | text2vec-contextionary Vectorizador de linguagem próprio da Weaviate; módulo de vectorização Weighted Mean of Word Embeddings (WMOWE) que funciona com modelos populares como fastText e GloVe. O mais recente text2vec - contextionary é treinado usando fastText em dados Wiki e CommonCrawl. text2vec- transformers Os modelos Transfomer diferem do Contextionary, pois permitem que você conecte um módulo NLP pré-treinado específico para o seu caso de uso. Isso significa que modelos como BERT, DilstBERT, RoBERTa, DilstilROBERTa, etc. podem ser usados fora da caixa com o Weaviate. Modelos personalizados | N/A | N/A | N/A | N/A |
Após uma análise rigorosa, foram selecionados dois VSEs - Milvus e Weaviate - para uma análise comparativa aprofundada. Estas plataformas estavam estreitamente alinhadas com os seus rigorosos requisitos de robustez, eficiência e escalabilidade. Os roteiros das plataformas também influenciaram a seleção final, uma vez que precisavam de uma solução que continuasse a evoluir e a adaptar-se às suas necessidades crescentes.
Configuração experimental
A empresa utilizou uma configuração padronizada de hardware e software para garantir uma avaliação justa e abrangente.
- Hardware: CPU Intel Xeon E5-2690 v4, 112 GB de RAM, 1024 GB de HDD
- Software: Linux 16.04-LTS, Anaconda 4.8.3 com Python 3.8.12
- Conjunto de dados: A equipa da Farfetch utilizou um conjunto de dados públicos da startups-list.com, composto por 40.474 registos. O conjunto de dados incluía embeddings pré-computados para descrições de empresas.
Cenários e algoritmo de indexação
A equipa concebeu vários cenários de teste para avaliar o desempenho destes VSEs em diferentes condições. Estes cenários variaram o número de registos e o número de codificações por entidade. Utilizaram o algoritmo Hierarchical Navigable Small World (HNSW) para a indexação, conhecido pela sua eficiência em espaços de dados de elevada dimensão.
A lista final de cenários é apresentada a seguir.
| Cenário | Número de entidades | Número de codificações por entidade |
|---|---|---|
| Cenário #1 (S1) | 1.000 | 1 |
| Cenário #2 (S2) | 10.000 | 1 |
| Cenário #3 (S3) | 40.474 | 1 |
| Cenário #4 (S4) | 1.000 | 2 |
| Cenário #5 (S5) | 10.000 | 2 |
| Cenário #6 (S6) | 40,474 | 2 |
| Cenário #7 (S7) | 1.000 | 5 |
| Cenário #8 (S8) | 10.000 | 5 |
| Cenário #9 (S9) | 40,474 | 5 |
Análise de desempenho
Indexação
Weaviate: Permite a declaração explícita de parâmetros de índice durante a criação do esquema de classe. No entanto, restringe a nomeação de classes, como não permitir números ou caracteres especiais.
Milvus: Oferece uma gama mais ampla de algoritmos de indexação e tipos de métricas. Também permite definir tamanhos de ficheiros de índice, o que pode otimizar as operações em lote.
Resultado: O Milvus teve a vantagem em relação aos tempos médios de indexação em todos os cenários. Foi notavelmente mais rápido no cenário com maior consumo de recursos, o S9.
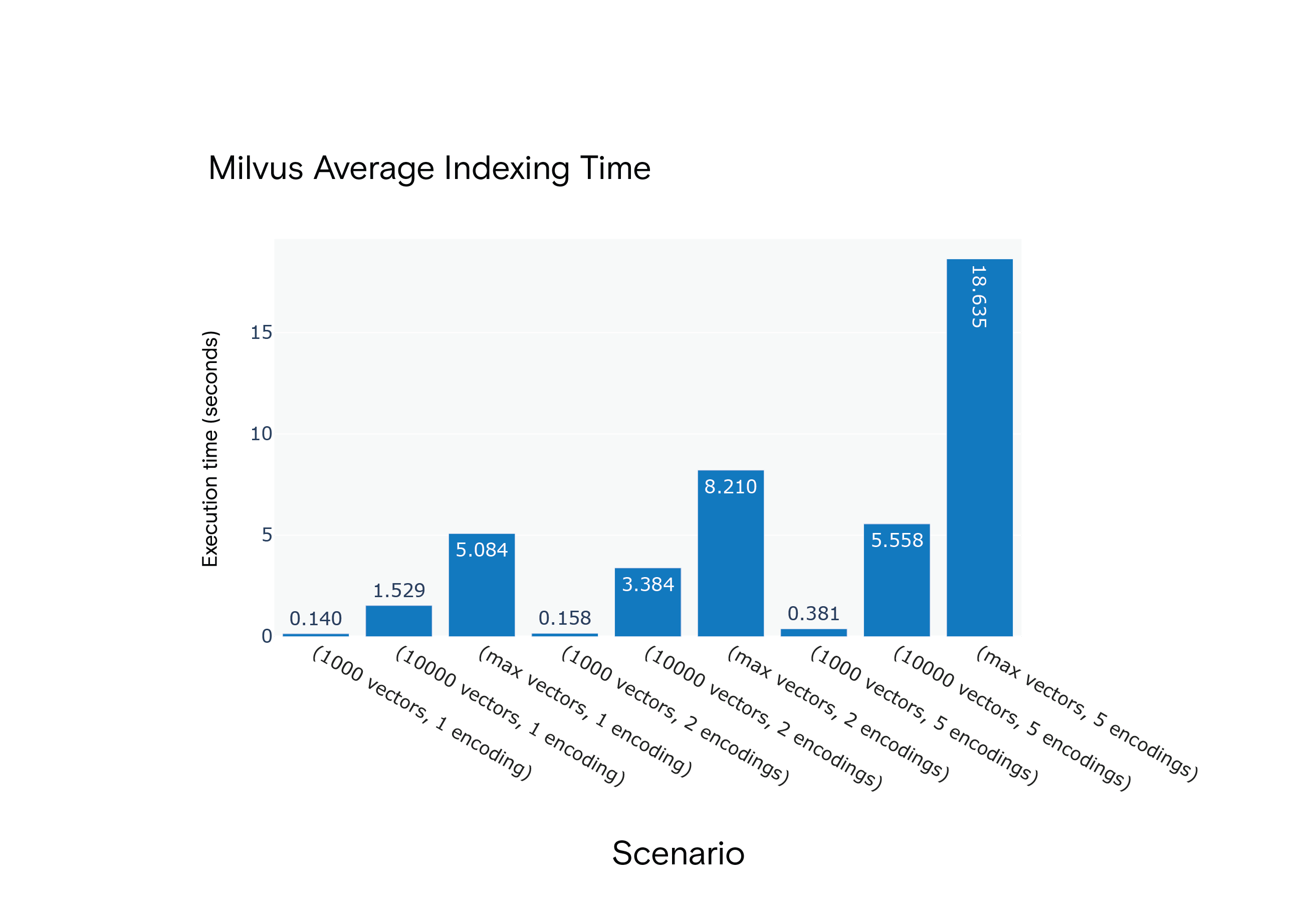 Tempo médio de indexação do Milvus 1.1.1 para os cenários S1 a S9
Tempo médio de indexação do Milvus 1.1.1 para os cenários S1 a S9
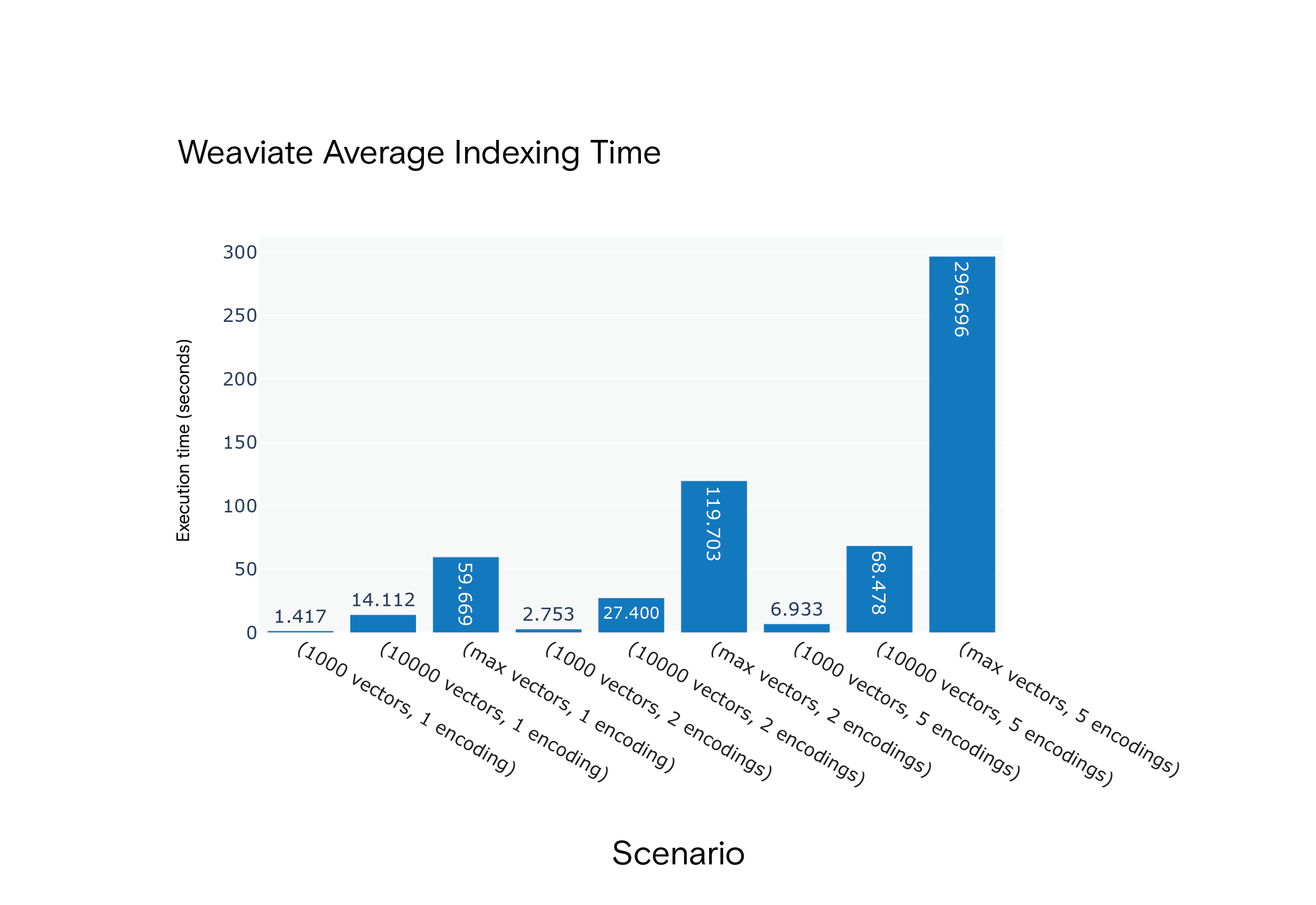 Tempo médio de indexação do Weaviate para os cenários S1 a S9
Tempo médio de indexação do Weaviate para os cenários S1 a S9
Consulta
Weaviate: O seu cliente Python suporta a pesquisa vetorial, mas apenas para um único vetor de cada vez.
Milvus: Oferece um método de pesquisa mais flexível que pode lidar com uma lista de vectores, facilitando a consulta multi-vetorial.
Resultado: O Milvus apresentou tempos médios de consulta mais curtos em todos os cenários, embora tenha sido necessária uma fase de "aquecimento" para atingir o desempenho ótimo.
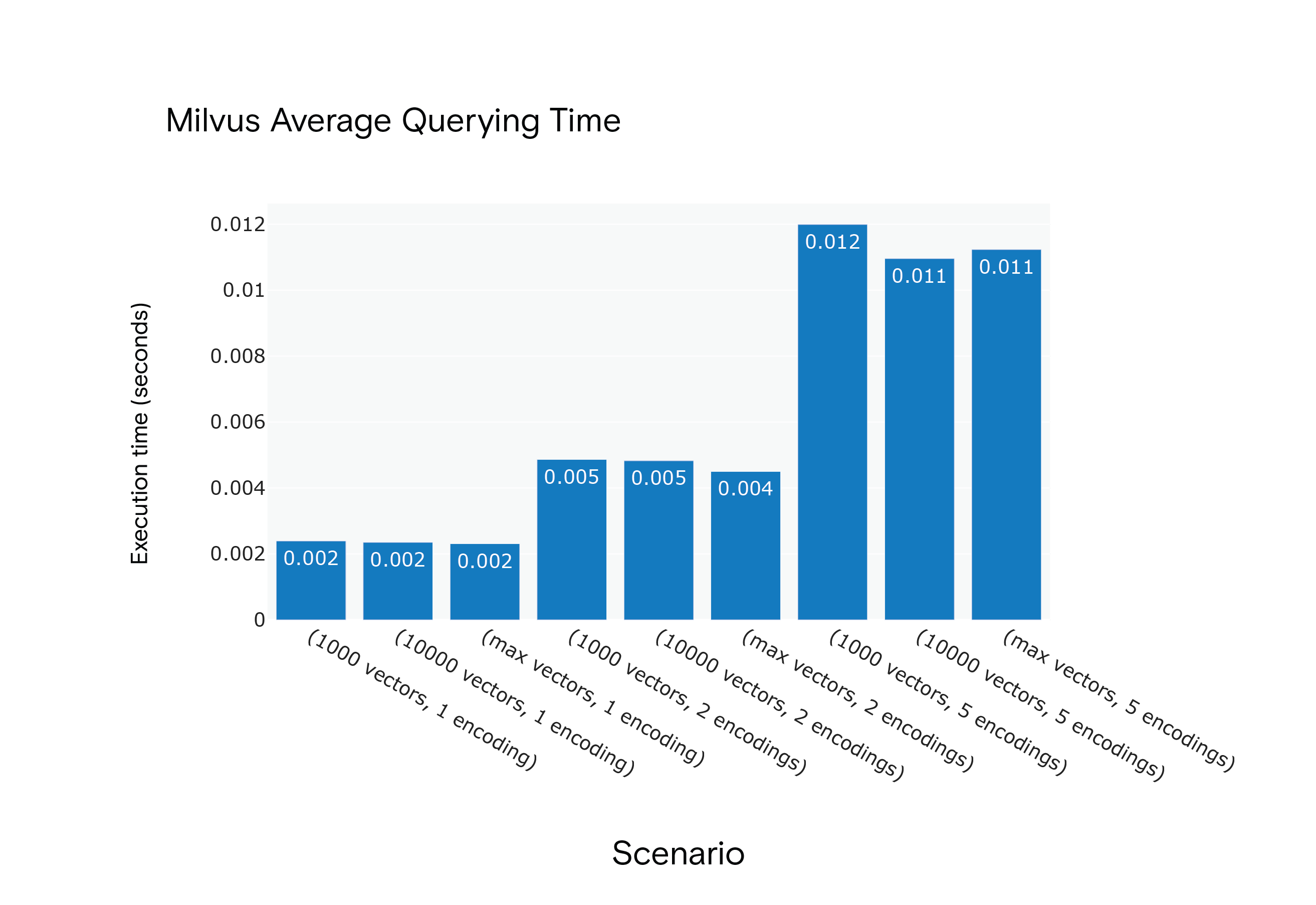 Tempo médio de consulta do Milvus 1.1.1 para os cenários S1 a S9
Tempo médio de consulta do Milvus 1.1.1 para os cenários S1 a S9
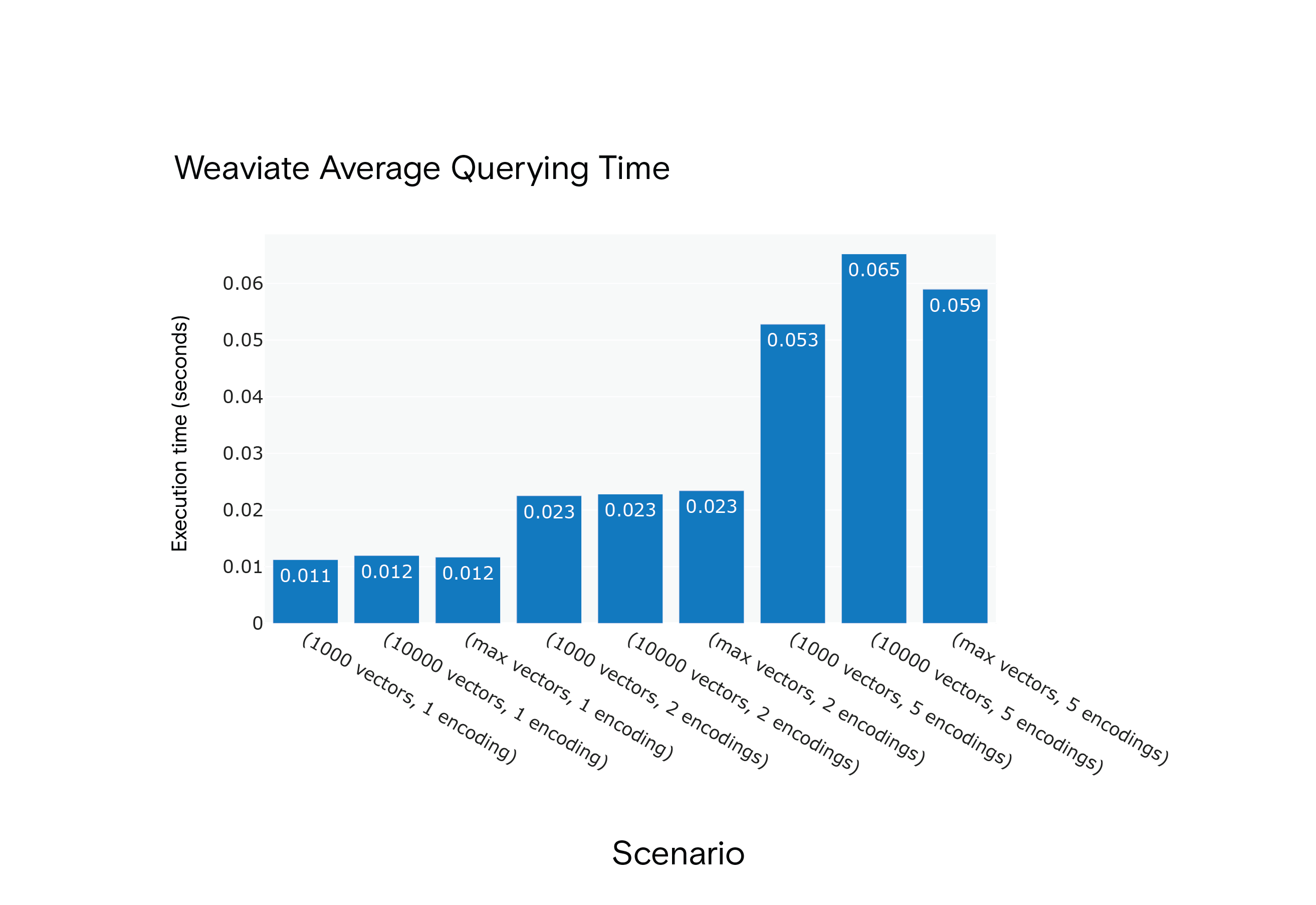 Tempo médio de consulta do Weaviate para os cenários S1 a S9
Tempo médio de consulta do Weaviate para os cenários S1 a S9
A equipa da Farfetch considerou que o Milvus e o Weaviate são promissores, mas ainda estão a evoluir. Caraterísticas como escalonamento horizontal, sharding e suporte a GPU estão no roteiro. Para a FARFETCH, que tem como objetivo lidar com um catálogo de produtos que varia entre 300 mil e 5 milhões de produtos, o VSE ideal deve oferecer:
- Resultados precisos e de alta qualidade
- Capacidades de indexação eficientes
- Execução rápida de consultas
- Recursos de escalabilidade, como balanceamento de carga e replicação de dados
As suas experiências revelaram que o Milvus superou consistentemente o Weaviate em termos de tempos de indexação e consulta. No entanto, vale a pena notar que ambas as plataformas têm certas limitações, como a falta de suporte para várias codificações. O seu trabalho futuro irá monitorizar de perto o desenvolvimento destas plataformas e potencialmente reavaliá-las à medida que introduzem novas funcionalidades.
Este estudo de caso é uma versão condensada de um blogue aprofundado de análise comparativa de bases de dados vectoriais publicado originalmente por PEDRO MOREIRA COSTA da Farfetch. Para uma análise mais pormenorizada e conhecimentos, consulte as publicações originais do blogue: POTENCIALIZAR A IA COM BASES DE DADOS VECTORIAIS: UM BENCHMARK - PARTE I e POTENCIALIZAR A IA COM BASES DE DADOS VECTORIAIS: UM BENCHMARK - PARTE II.