




Como o DiDi Food transformou a busca de supermercados em toda a América Latina com Milvus

Redução de 19%
em consultas sem resultados alcançadas por meio da busca vetorial semântica do Milvus
Aumento de 4%
conversões no carrinho a partir da correspondência semântica de produtos com tecnologia Milvus
15% das consultas
agora se beneficiam da pesquisa vetorial, complementando a pesquisa de texto tradicional
Recuperação de Vetores em Menos de um Segundo
com indexação IVF_FLAT do Milvus e similaridade por produto interno
Sobre a DiDi Food
DiDi, líder global em transporte por aplicativo com mais de 800 milhões de usuários em todo o mundo, lançou a DiDi Food—seu serviço de entrega de supermercado—em 12 grandes cidades da América Latina, incluindo México, Colômbia e Costa Rica. Aproveitando sua rede logística existente e seus recursos de otimização em tempo real, alcançaram um crescimento notável: 2 milhões de usuários ativos mensais, 500.000 pedidos diários e mais de US$ 120 milhões em GMV no 1º trimestre de 2025—tudo isso em apenas seis meses.
A plataforma entrega produtos frescos e itens essenciais para o lar em 30 a 45 minutos, com lojas parceiras oferecendo até 30 milhões de SKUs cada. Operando em mercados diversos com interações multilíngues, preços dinâmicos e gerenciamento de estoque em tempo real, a DiDi Food construiu uma base de negócios impressionante. Mas, à medida que sua escala cresceu, também aumentou a complexidade de ajudar milhões de clientes a encontrar exatamente o que precisavam em catálogos de produtos massivos. Foi aí que o banco de dados vetorial Milvus transformou suas capacidades de busca, possibilitando uma compreensão semântica que funciona entre idiomas e lida com a bagunça do mundo real de como as pessoas realmente pesquisam.
O desafio da busca: quando o Elasticsearch baseado em palavras-chave deixa de funcionar
A equipe de engenharia da DiDi enfrentou as limitações que afetam seu banco de dados Elasticsearch baseado em palavras-chave. Erros simples de digitação, alternância de idiomas ou descrições não convencionais muitas vezes levavam a páginas sem resultados, criando atrito na experiência de compra.
Altas taxas de "sem resultados": a perda de receita oculta
A DiDi Food enfrentou um problema crítico: muitas buscas de clientes retornavam zero resultados, levando ao abandono de sessões de compra e à perda de receita. Exemplos reais dos dados de busca da DiDi revelaram três causas principais por trás dessas falhas.
Erros de digitação e ortografia eram os culpados mais comuns. Usuários digitavam "Genjibr" ao procurar por "Jengibre" (gengibre), "hedaho" em vez de "HELADO" (sorvete) ou "Kellongs" para "Kelloggs." Seus sistemas de busca por palavras-chave existentes, alimentados pelo Elasticsearch, não conseguiam preencher essas pequenas, mas críticas, lacunas de ortografia.
Artefatos de métodos de entrada criavam outra barreira. Teclados móveis e diferentes sistemas de entrada geravam variações Unicode incomuns como "𝑤𝑖𝑛𝑒" em vez de "wine," "𝑏𝑎𝑛𝑎𝑛𝑎" para "banana," ou "𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠" para "chocolates." Esses problemas técnicos de codificação impediam os clientes de encontrar produtos que claramente estavam em estoque.
Consultas em idiomas mistos representavam o maior desafio nos mercados latino-americanos. Os clientes pesquisavam naturalmente por "apple juice orgánico" ou "leche sin lactosa," combinando termos em inglês e espanhol. As variações regionais pioravam isso—o mesmo produto podia receber nomes diferentes no México, na Colômbia e na Costa Rica.
Cada busca malsucedida representava um cliente frustrado e perda direta de receita. Para uma plataforma que processa 500.000 pedidos diários, até mesmo uma pequena porcentagem de consultas sem resultados pode se traduzir em um impacto significativo nos negócios.
Escalabilidade e complexidade multilíngue
Além das falhas de busca individuais, a DiDi enfrentava desafios sistêmicos que ameaçavam sua capacidade de escalar. Indexar textualmente dezenas de milhões de nomes distintos de SKUs inflava os custos de armazenamento e degradava o desempenho das consultas à medida que seu catálogo de produtos se expandia por vários países.
A complexidade multilíngue ia além das consultas em idiomas mistos. Operar no México, na Colômbia, na Costa Rica e em outros mercados latino-americanos significava que o mesmo produto podia ter nomes completamente diferentes em cada região. "Palta" em alguns países, "aguacate" em outros—ambos se referindo ao abacate. Sistemas tradicionais de palavras-chave alimentados pelo Elasticsearch exigiam a manutenção de índices separados para cada variação regional, o que multiplicava os requisitos de armazenamento e complicava a manutenção.
Nuances culturais e linguísticas criaram barreiras adicionais. Gírias locais, variações de nomes de marcas e até diferentes sistemas de medição (métrico vs. imperial) contribuíram para falhas de busca. Uma abordagem baseada em palavras-chave exigiria mapear manualmente milhares de variações regionais — uma tarefa impossível na escala da DiDi.
A equipe de engenharia da DiDi precisava urgentemente de uma solução que pudesse superar esses desafios e entender a intenção por trás das consultas dos usuários, independentemente do idioma, da região ou de como os clientes escolhessem expressar suas necessidades.
A Solução: Construindo um Mecanismo de Busca Semântica com Milvus
O sistema baseado em Elasticsearch enfrenta dificuldades com a diversidade linguística e a variabilidade de entrada dos usuários porque trata palavras como tokens discretos, em vez de conceitos significativos. Bancos de dados vetoriais, no entanto, conseguem entender o significado semântico e a intenção das consultas dos usuários por meio de embeddings vetoriais e retornar resultados mais precisos e relevantes, independentemente do idioma ou de erros de digitação.
A equipe de engenharia da DiDi decidiu construir um mecanismo de busca semântica aproveitando modelos de embeddings multilíngues e um banco de dados vetorial. O modelo de embeddings converte tanto nomes e descrições de produtos quanto consultas de usuários em embeddings vetoriais que representam seu significado semântico em um espaço de alta dimensionalidade, enquanto o banco de dados vetorial armazena esses embeddings e realiza busca semântica calculando as distâncias entre vetores de consulta e vetores de produtos.
Após uma avaliação cuidadosa, eles escolheram jina-embeddings-v3 como seu principal modelo de embeddings porque ele mapeia textos de diferentes idiomas no mesmo espaço matemático de alta dimensionalidade. Isso significa que consultas por "苹果" (chinês), "apple" (inglês) ou "manzana" (espanhol) geram vetores quase idênticos, permitindo correspondência multilíngue precisa sem a necessidade de sistemas complexos de tradução. Mesmo entradas com erros de digitação ou foneticamente semelhantes produzem vetores próximos aos termos corretos.
A DiDi selecionou Milvus como seu banco de dados vetorial devido à sua maturidade open-source, capacidade de escalar horizontalmente para bilhões de vetores, latência em milissegundos, arquitetura comprovada de alta taxa de transferência e rico conjunto de recursos.
Arquitetura de Dados e Estratégia de Otimização
Para oferecer suporte à recuperação vetorial de baixa latência em 30 milhões de SKUs enquanto preservavam associações em nível de loja, os engenheiros da DiDi implementaram várias otimizações importantes.
Em vez de armazenar vetores individuais para cada combinação SKU-loja, eles mesclaram nomes de itens idênticos em entradas vetoriais únicas, com os IDs de loja correspondentes armazenados em arrays. Essa abordagem reduziu sua biblioteca vetorial de 30 milhões de entradas para 200.000 vetores únicos, diminuindo drasticamente o uso de memória enquanto mantinha a cobertura completa de produtos.
A equipe escolheu uma configuração de índice
IVF_FLATno Milvus, priorizando a precisão da busca em vez da complexidade de compressão. Quando os usuários consultam o sistema, o Milvus retorna os top-k vetores mais semelhantes do índice agregado, seguido por um filtro rápido de IDs de loja para isolar itens disponíveis na localização atual do comprador.Para manter os dados atualizados, a DiDi adotou um ciclo de atualização noturna T+1. SKUs novos e atualizados são agrupados diariamente, re-embeddados usando clusters de GPU e enviados para atualizar a coleção do Milvus. Essa estratégia equilibra atualidade dos dados com eficiência computacional em seu enorme catálogo de produtos.
Design do Esquema do Milvus
O esquema da coleção reflete os requisitos específicos da DiDi para busca de mercado, equilibrando flexibilidade com desempenho:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
Geração de Embeddings Acelerada por GPU
A geração inicial de embeddings baseada em CPU com o modelo jina-embeddings-v3 resultou em uma latência inaceitável de 5 segundos por registro. Para alcançar desempenho em tempo real, a DiDi implantou instâncias de GPU em sua plataforma Luban, reduzindo o tempo de embedding para aproximadamente 50 milissegundos por consulta:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Arquitetura do Pipeline de Busca Híbrida
Em vez de substituir totalmente sua infraestrutura existente, a DiDi implementou o Milvus como um complemento inteligente ao seu sistema Elasticsearch estabelecido. O design de pipeline duplo permite que o Elasticsearch lide com consultas padrão por palavras-chave, enquanto o Milvus fornece compreensão semântica para casos complexos.
O fluxo de busca opera nas seguintes etapas:
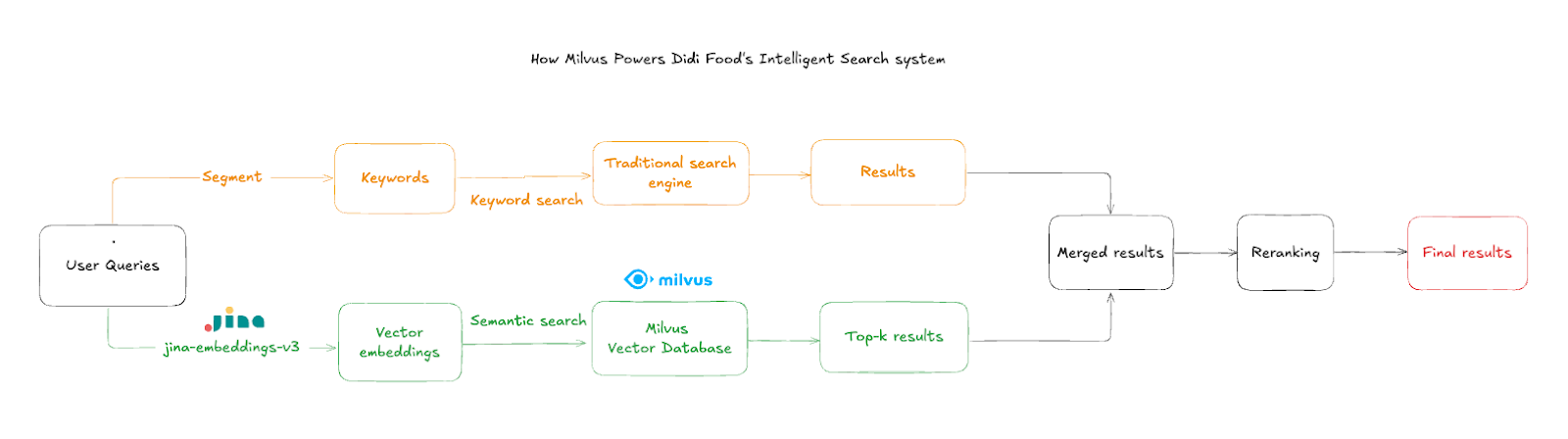
Entrada da Consulta do Usuário: Os clientes digitam nomes ou descrições de produtos, frequentemente com erros de digitação ou idiomas misturados
Embedding de Texto: O sistema usa
jina-embeddings-v3para converter a entrada em vetores semânticos de alta dimensionalidade em ~50 msBusca por Similaridade: O Milvus consulta os vetores de produtos agregados para encontrar as correspondências semânticas mais próximas
Filtragem por Loja: Os resultados são filtrados pelo ID da loja para garantir que apenas itens em estoque na loja atual sejam exibidos
Mesclagem de Resultados: Os resultados vetoriais são combinados com os resultados do Elasticsearch quando a busca tradicional produz resultados insatisfatórios, proporcionando uma experiência de busca mais rica e completa
Crítica para a experiência do usuário é a filtragem em nível de loja, que garante que os resultados pertençam ao contexto da localização atual do comprador. O sistema emprega agregação inteligente de resultados—quando o Elasticsearch produz resultados insatisfatórios, os itens semanticamente relevantes do Milvus complementam a resposta.
Resultados de Desempenho e Impacto no Mundo Real
A implementação do Milvus pela DiDi trouxe melhorias concretas em métricas críticas de negócios.
O sistema alcançou uma redução de 19% em consultas sem resultado, o que significa que quase uma em cada cinco buscas anteriormente malsucedidas agora retorna produtos relevantes, recuperando diretamente oportunidades de receita perdidas. Para uma plataforma que processa 500.000 pedidos diários, essa taxa de recuperação representa um valor de negócio significativo.
A busca vetorial é acionada em 15% do total de consultas, complementando a busca textual tradicional precisamente quando a compreensão semântica agrega valor sem sobrecarregar o pipeline central de consultas. Mais significativamente, usuários expostos a itens recuperados por vetores mostram um aumento de 4% nas conversões de adição ao carrinho, demonstrando que a relevância aprimorada da busca se traduz em comportamento de compra mensurável.
O sistema agora lida com consultas em vários idiomas, incluindo inglês, espanhol, chinês, coreano e japonês, com melhorias de precisão particularmente notáveis para o espanhol, crucial para a presença da DiDi no mercado latino-americano. Os testes de desempenho multilíngue revelaram o poder da compreensão semântica: buscas por "Liquid Foundation" funcionam igualmente bem, quer os usuários digitem o termo em inglês, o chinês "液体妆前乳" ou o espanhol "Base de maquillaje líquida." O sistema supera lacunas linguísticas que confundiriam completamente abordagens tradicionais baseadas em palavras-chave.
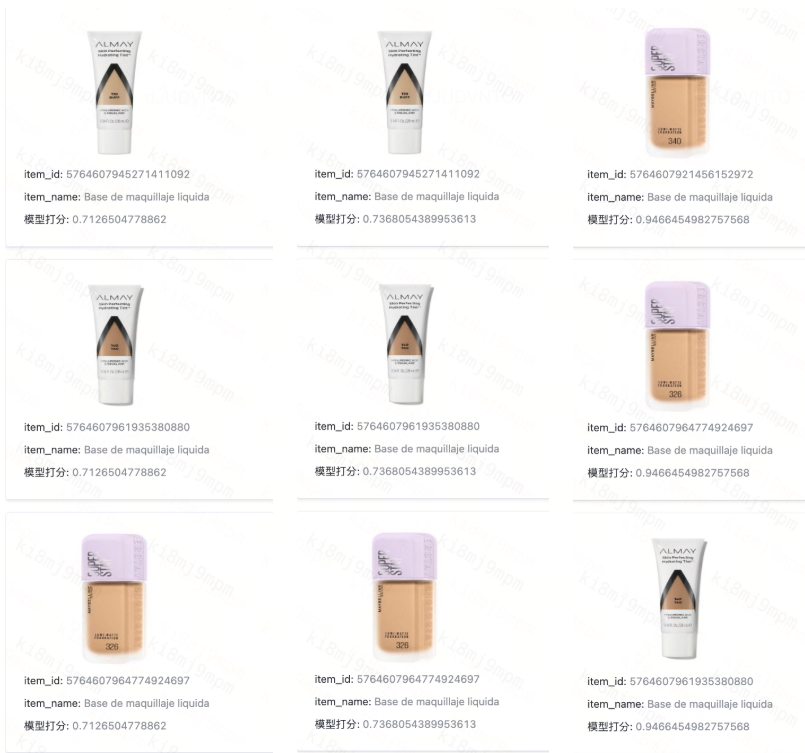
Figura: Buscas por "Liquid Foundation" funcionam igualmente bem, quer os usuários digitem o termo em inglês, o chinês "液体妆前乳" ou o espanhol "Base de maquillaje líquida."
Consultas complexas de produtos demonstram a compreensão contextual da busca vetorial. Quando os usuários pesquisam por "Redac PalancaPara WC Blanca" (uma alavanca branca de descarga para vaso sanitário), o sistema vetorial corresponde com precisão à consulta apesar da terminologia técnica composta, enquanto a busca tradicional falha ao analisar a descrição do produto com várias palavras.
Esses ganhos se traduzem em uma experiência de compra mais fluida, maior satisfação do cliente e uma vantagem competitiva definitiva no mercado de e-commerce de hortifruti e mercearia frescos.
Roadmap Futuro: Recursos de Busca de Próxima Geração
Com base nessa fundação sólida, a DiDi e o Milvus estão colaborando em vários recursos avançados para a próxima fase de desenvolvimento.
A sincronização de catálogo em tempo real reduzirá a latência entre mudanças de inventário e dados pesquisáveis por meio de atualizações por streaming, garantindo que os usuários nunca vejam produtos que não estejam realmente disponíveis. A integração de sinais comportamentais combinará similaridade vetorial com histórico do usuário, preferências e sinais contextuais para entregar recomendações hiperpersonalizadas que melhoram com o tempo.
A busca híbrida avançada e o reranking representam talvez o desenvolvimento mais empolgante. Esse sistema combinará métricas de negócios, incluindo preço, avaliações, promoções e níveis de estoque, com relevância semântica para destacar recomendações verdadeiramente ideais para cada comprador individual.
O suporte multilíngue aprimorado expandirá a cobertura de idiomas e melhorará o tratamento de dialetos regionais à medida que a DiDi entrar em novos mercados. A otimização dinâmica de embeddings implementará mecanismos de aprendizado contínuo para melhorar a qualidade dos embeddings com base em padrões reais de interação dos usuários, criando assim um sistema de busca que se torna cada vez mais inteligente com o uso.
Ao inovar continuamente, a DiDi está redefinindo a experiência de busca em mercearia, garantindo que cada comprador encontre exatamente o que precisa, todas as vezes.
Conclusão
A jornada da DiDi Food com o Milvus demonstra que a busca semântica representa mais do que uma atualização técnica — é uma reimaginação fundamental de como os usuários interagem com grandes catálogos de produtos. Ao combinar uma arquitetura de dados bem pensada, escolhas tecnológicas adequadas e foco inabalável na experiência do usuário, eles criaram um sistema de busca que realmente entende a intenção entre idiomas e culturas.
Os resultados validam essa abordagem: menos usuários frustrados, mais compras bem-sucedidas e uma experiência de compra que funciona independentemente de como os clientes escolhem expressar suas necessidades. Para os 2 milhões de usuários mensais da DiDi, isso significa encontrar consistentemente o que precisam, quando precisam, no idioma que lhes parecer mais natural.
Esta história de sucesso ilustra o que se torna possível quando empresas inovadoras adotam a compreensão semântica em escala. À medida que a DiDi continua se expandindo pela América Latina, sua arquitetura de busca baseada no Milvus oferece uma base robusta para inovação contínua e satisfação dos usuários. A tecnologia funciona, os resultados de negócios são claros e a melhoria na experiência do usuário é tangível — exatamente o que a excelente engenharia deve entregar.