




RAG multimodal localmente com CLIP e Llama3
Com o recente lançamento do GPT-4o e do Gemini, o multimodal tem sido um tema quente ultimamente. Outro que tem estado no topo do ponto de luz é o Retrieval Augmented Generation (RAG) no ano passado, mas foi principalmente focado em texto. Este tutorial vai mostrar-lhe como construir um sistema RAG multimodal.
Ao utilizar o RAG Multimodal, não tem de utilizar apenas texto; pode utilizar diferentes tipos de dados, como imagens, áudio, vídeos e texto, claro. Também é possível devolver diferentes tipos de dados; só porque utiliza texto como entrada para o seu sistema RAG, não significa que tenha de devolver texto como saída. Iremos mostrar isso durante este tutorial.
Pré-requisitos
Antes de começar a configurar os diferentes componentes do nosso tutorial, certifique-se de que o seu sistema tem o seguinte:
Docker & Docker-Compose - Certifique-se de que o Docker e o Docker-Compose estejam instalados no seu sistema.
Milvus Standalone**-Para nossos propósitos, utilizaremos o eficiente Milvus Standalone, que é facilmente gerenciado via Docker Compose; explore nossa documentação para instalação orientação
Ollama-Instale o Ollama no seu sistema. Isto permitir-nos-á utilizar o Llama3 no nosso portátil. Visite o [sítio Web] (https://ollama.com/) para obter o guia de instalação mais recente.
OpenAI CLIP
A ideia central do modelo CLIP (Contrastive Language-Image Pretraining) é compreender a ligação entre uma imagem e um texto. É um modelo de IA fundamental treinado em pares texto-imagem. Em seguida, aprende a criar um ponto no espaço vetorial para texto e imagens. Neste espaço, as descrições de texto semelhantes estarão próximas de imagens relevantes e vice-versa.
O CLIP pode ser utilizado para diferentes aplicações, incluindo:
Recuperação de imagens: Imagine procurar imagens utilizando uma descrição de texto ou encontrar a legenda perfeita para uma imagem.
Aprendizagem multimodal:** A capacidade do CLIP para ligar texto e imagens torna-o um elemento de base perfeito para sistemas como o RAG multimodal, que lida com informações em diferentes formatos.
Isto permite que o nosso sistema RAG compreenda e responda a consultas que podem envolver tanto texto como imagens.
Fig. 1: Arquitetura do OpenAI CLIP] (https://assets.zilliz.com/Architecture_of_Open_AI_CLIP_765f6f1fc0.png)
Embeddings Multimodais
O que são embeddings? Em termos mais simples, embeddings são representações comprimidas de dados. O CLIP pega numa imagem ou texto como entrada e transforma-o num código numérico que capta as suas principais caraterísticas.
A vantagem do CLIP é que funciona tanto para texto como para imagens. Pode fornecer-lhe uma imagem e ela gerará uma incorporação que capta o conteúdo visual. No entanto, também pode fornecer texto, e o CLIP gerará uma incorporação que reflecte o significado do texto.
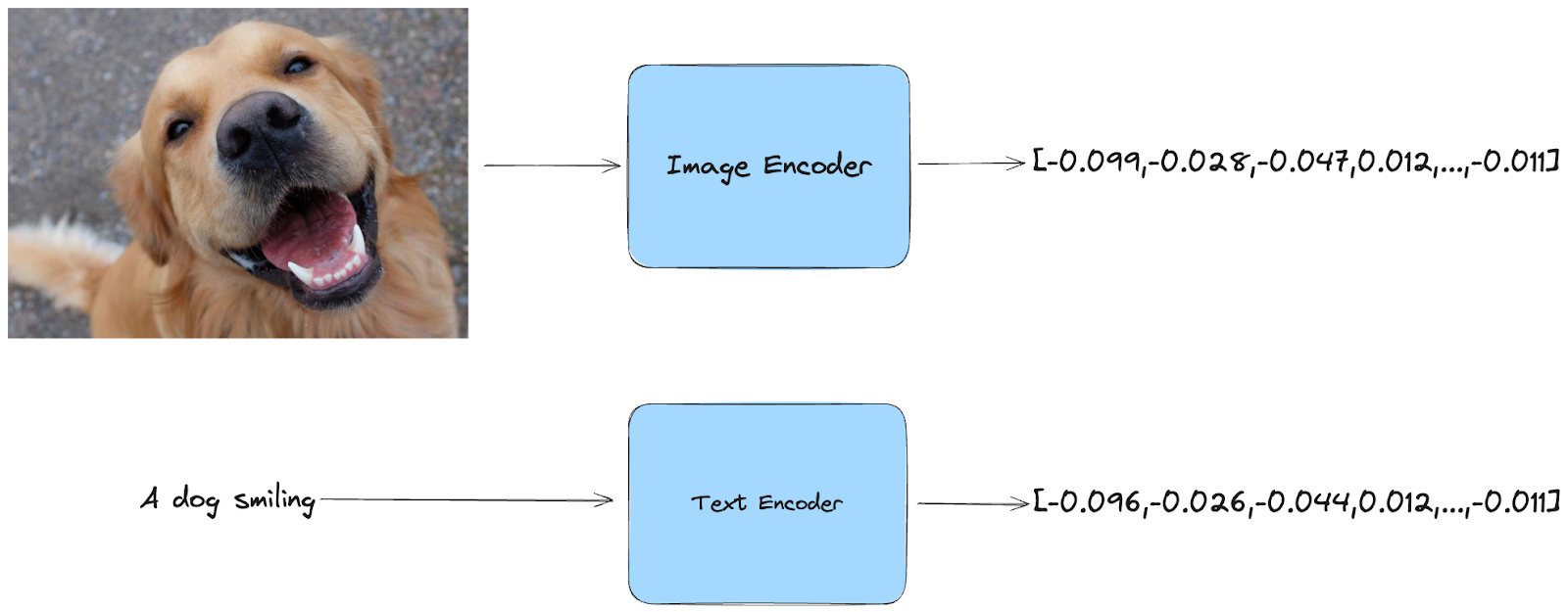 Multimodal Embeddings
Multimodal Embeddings
Se imaginássemos uma projeção no espaço vetorial, teríamos embeddings com significados semelhantes próximos uns dos outros. Por exemplo, o texto "Um cão com um sorriso" e a imagem de um cão que parece estar a sorrir estão próximos uns dos outros.
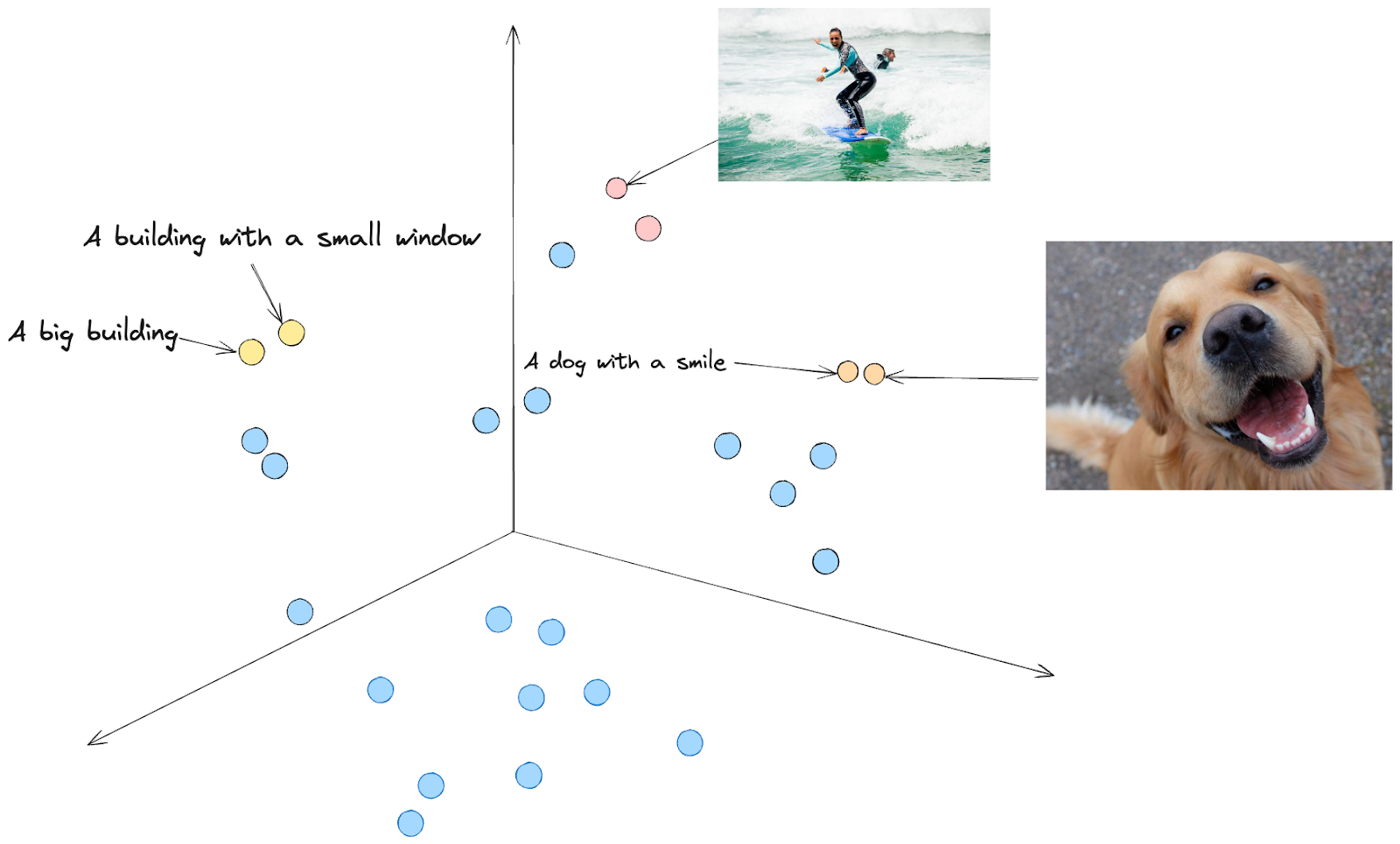 Fig2. Representação num espaço vetorial
Fig2. Representação num espaço vetorial
Construir um RAG multimodal
Vamos usar os dados da Wikipédia, descarregar os dados de texto associados ao que queremos aprender mais sobre e fazer o mesmo com as imagens.
Vamos gerar Embeddings com o modelo CLIP ViT-B/32 e usar o Llama3 como LLM.
Armazenamos os embeddings no Milvus, que foi concebido para gerir embeddings em grande escala, de modo a podermos efetuar uma pesquisa rápida e eficiente.
O LlamaIndex é utilizado como motor de pesquisa em combinação com o Milvus como armazenamento de vectores.
Todo o código é bastante longo, pois precisamos de navegar na Wikipédia, processar o texto e as imagens e depois criar uma aplicação RAG. No entanto, está totalmente disponível no Github, pelo que deve mesmo dar uma vista de olhos!
Quando estiver a funcionar, deve ser possível executar consultas semelhantes às seguintes:
# https://en.wikipedia.org/wiki/Helsinki
query2 = "Quais são algumas das atracções turísticas populares em Helsínquia?"
# gerar resultados de recuperação de imagens
consulta_imagem(consulta2)
# gerar resultados de recuperação de texto
resultados_de_recuperação_de_texto = motor_de_consulta_de_texto.consulta(consulta2)
print("Resultados da recuperação de texto: \n" + str(resultados_recuperação_texto))
O que deve produzir algo semelhante a
Algumas atracções turísticas populares em Helsínquia incluem Suomenlinna (Sveaborg), uma ilha-fortaleza com uma história rica, e o Jardim Zoológico de Korkeasaari, localizado numa das principais ilhas de Helsínquia. Além disso, a cidade tem muitas reservas naturais, incluindo Vanhankaupunginselkä, que é a maior reserva natural de Helsínquia.

E com isso, terá uma aplicação RAG multimodal que é capaz de processar imagens ou texto e pode também devolver imagens ou texto.
Pode aceder ao código no Github, fazer perguntas no nosso Discord e dar-nos uma estrela no Github.

Continue lendo

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.