




Milvus em GPUs com NVIDIA RAPIDS cuVS
Introdução
**O desempenho na produção é um fator crítico para o sucesso da nossa aplicação de IA. Quanto mais rápido pudermos devolver os resultados ao utilizador, melhor. Esta urgência leva à necessidade de otimização.
Consideremos um exemplo do mundo real - uma aplicação Retrieval Augmented Generation (RAG). Num sistema RAG, a pesquisa vetorial é o motor que alimenta a experiência do utilizador, fornecendo resultados relevantes com base nas suas consultas. No entanto, todos sabemos que a pesquisa vetorial é uma tarefa que consome muitos recursos. Quanto mais dados armazenamos, mais dispendiosa e demorada se torna a computação.
É necessário encontrar uma solução para otimizar o desempenho das nossas aplicações de IA nestes casos. Em uma palestra recente no Unstructured Data Meetup hospedado por Zilliz, Corey Nolet, Engenheiro Principal da NVIDIA, discutiu os últimos avanços da NVIDIA para resolver esse problema, que exploraremos neste artigo. Também pode ver a palestra de Corey no YouTube.
Especificamente, vamos focar-nos na cuVS, uma biblioteca desenvolvida pela NVIDIA que contém vários algoritmos relacionados com a pesquisa vetorial e aproveita o poder de aceleração das GPUs. Veremos como esta biblioteca pode melhorar o desempenho das operações de pesquisa vetorial e otimizar os custos operacionais gerais. Então, sem mais delongas, vamos mergulhar no assunto!
A pesquisa vetorial e o papel do banco de dados vetorial nela
A pesquisa vetorial é um método de [recuperação de informação] (https://zilliz.com/learn/what-is-information-retrieval) em que tanto a consulta do usuário quanto os documentos que estão sendo pesquisados são representados como vetores. Para efetuar uma pesquisa vetorial, temos de transformar a nossa consulta e os documentos (que podem ser imagens, textos, etc.) em vectores.
Um vetor tem uma dimensão específica, que depende do método utilizado para o gerar. Por exemplo, se utilizarmos um modelo HuggingFace chamado all-MiniLM-L6-v2 para transformar a nossa consulta num vetor, obteremos um vetor com uma dimensão de 384. Os vectores transportam o significado semântico dos dados ou documentos que representam. Assim, se dois dados forem semelhantes entre si, os seus vectores correspondentes são posicionados próximos um do outro no espaço vetorial.
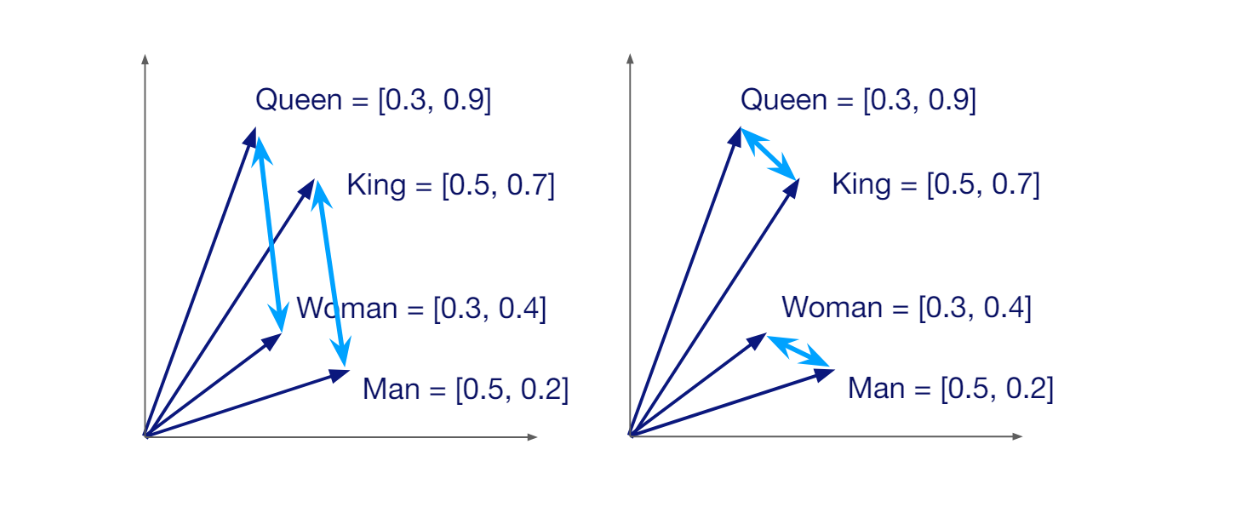 Semelhança semântica entre vectores num espaço vetorial..png
Semelhança semântica entre vectores num espaço vetorial..png
Semelhança semântica entre vectores num espaço vetorial.
O facto de cada vetor conter o significado semântico dos dados que representa permite-nos calcular a semelhança entre qualquer par aleatório de vectores. Se forem semelhantes, a pontuação de semelhança será elevada e vice-versa. O principal objetivo da pesquisa vetorial é encontrar os vectores mais semelhantes ao vetor da nossa consulta.
A implementação da pesquisa vetorial é relativamente simples quando se trata de poucos documentos. No entanto, a complexidade aumenta à medida que temos mais documentos e precisamos de armazenar mais vectores. Quanto mais vectores tivermos, mais tempo será necessário para efetuar uma pesquisa vetorial. Além disso, o custo operacional aumenta significativamente à medida que armazenamos mais vectores na memória local. Assim, precisamos de uma solução escalável, que é onde as [bases de dados vectoriais] (https://zilliz.com/learn/what-is-vetor-database) entram em jogo.
As bases de dados vectoriais oferecem uma solução eficiente, rápida e escalável para armazenar uma enorme coleção de vectores. Fornecem métodos de indexação avançados para uma recuperação mais rápida durante as operações de pesquisa de vectores, bem como fácil integração com estruturas de IA populares para simplificar o processo de desenvolvimento das nossas aplicações de IA. Em bases de dados de vectores como Milvus e Zilliz Cloud (o Milvus gerido), também podemos armazenar os metadados dos vectores e realizar processos de filtragem avançados durante as operações de pesquisa.
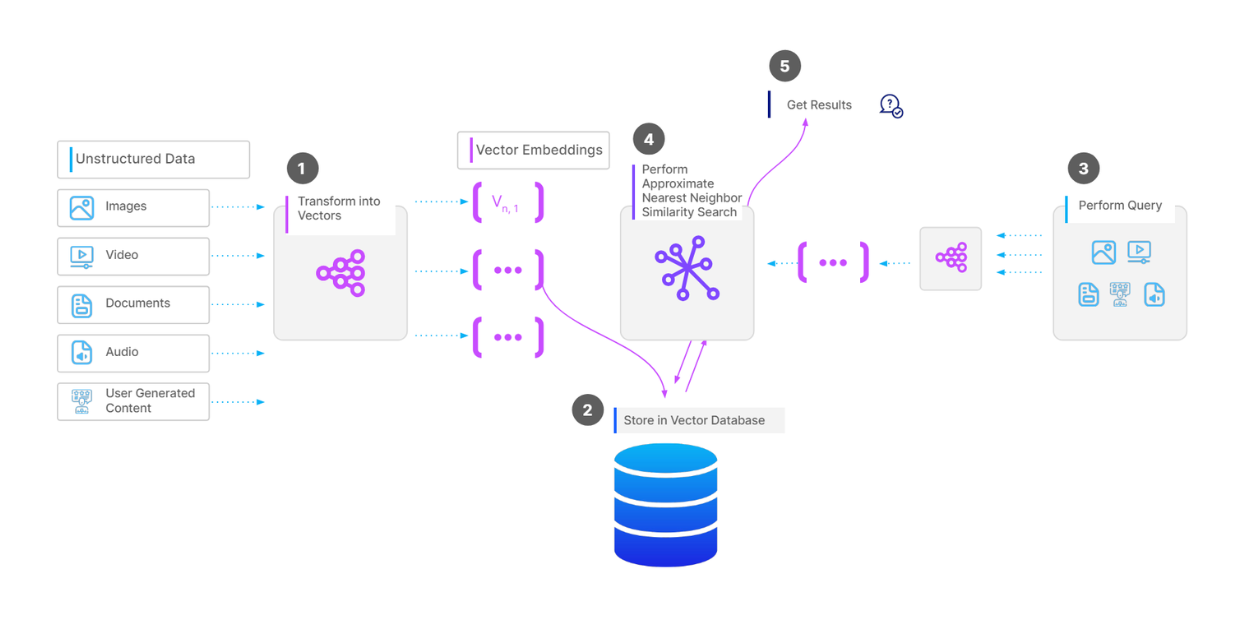 Fluxo de trabalho completo de uma operação de pesquisa de vectores..png
Fluxo de trabalho completo de uma operação de pesquisa de vectores..png
Fluxo de trabalho completo de uma operação de pesquisa vetorial.
Para armazenar uma coleção de vectores numa base de dados vetorial como o Milvus, o primeiro passo é efetuar o pré-processamento dos dados, dependendo do tipo de dados. Por exemplo, se os nossos dados forem uma coleção de documentos, podemos dividir o texto de cada documento em partes. Em seguida, transformamos cada pedaço num vetor utilizando [um modelo de incorporação] (https://zilliz.com/ai-models) à nossa escolha. Depois, introduzimos todos os vectores na nossa base de dados de vectores e criamos um índice sobre eles para uma recuperação mais rápida durante as operações de pesquisa de vectores.
Quando temos uma consulta e queremos efetuar uma operação de pesquisa vetorial, transformamos a consulta num vetor utilizando o mesmo modelo de incorporação utilizado anteriormente e, em seguida, calculamos a sua semelhança com os vectores da base de dados. Por fim, são-nos devolvidos os vectores mais semelhantes.
Operação de pesquisa vetorial na CPU
As operações de pesquisa vetorial requerem uma computação intensiva, e o custo de computação aumenta à medida que armazenamos mais vectores numa base de dados vetorial. Vários factores afectam diretamente o custo de computação, como a construção do índice, o número total de vectores, a dimensionalidade do vetor e a qualidade do resultado de pesquisa pretendido.
As CPUs são as unidades de processamento mais comuns para as operações de pesquisa vetorial devido à sua relação custo-eficácia e fácil integração com outros componentes em aplicações de IA. Muitos algoritmos de pesquisa vetorial estão totalmente optimizados para CPUs, sendo o Hierarchical Navigable Small World (HNSW) o mais popular.
Na sua essência, o HNSW combina os conceitos de skip lists e Navigable Small World (NSW). Num algoritmo NSW, o gráfico é construído começando por baralhar aleatoriamente os nossos pontos de dados. De seguida, os pontos de dados são inseridos um a um, com cada ponto ligado através de um número predefinido de arestas aos seus vizinhos mais próximos.
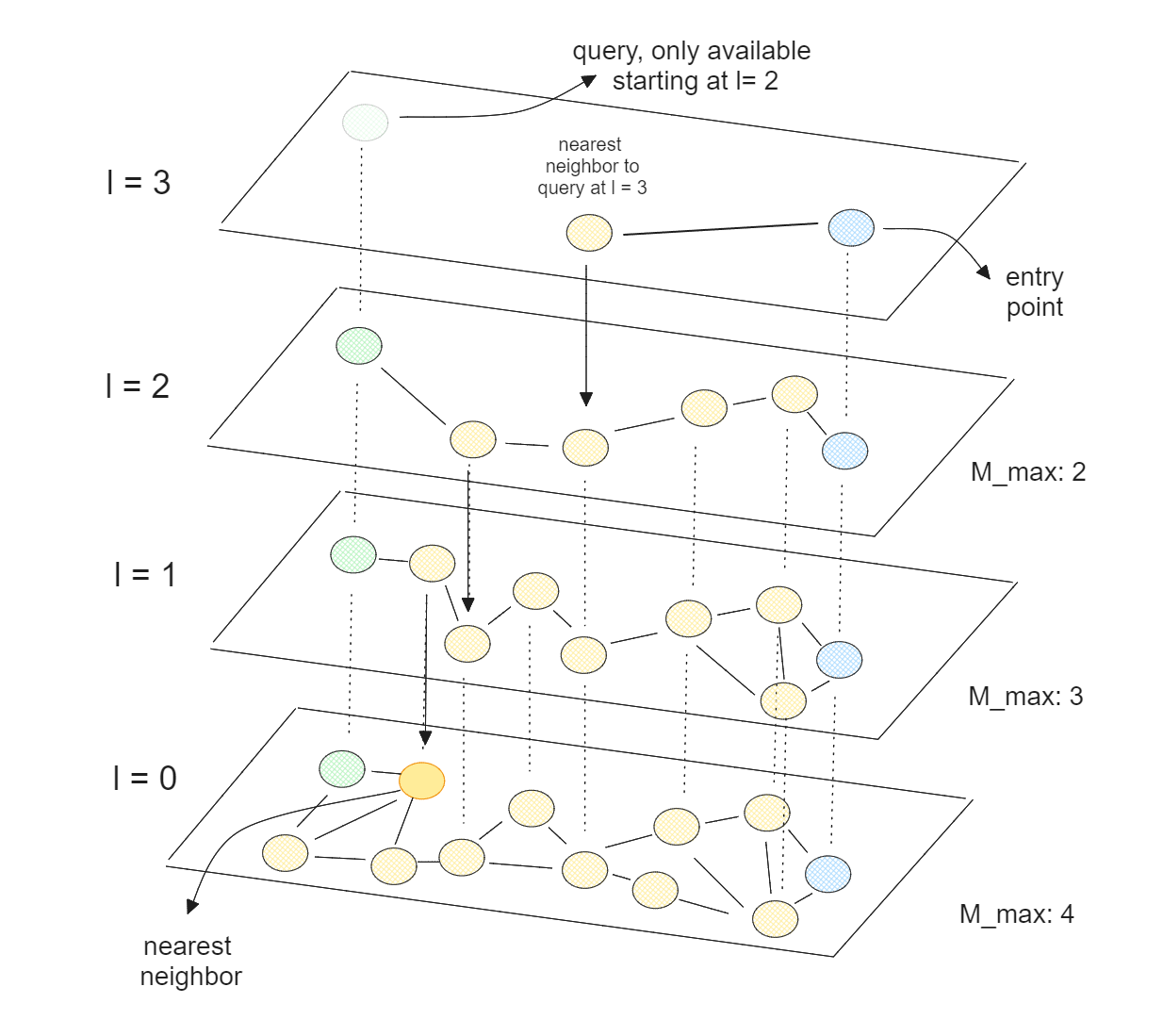 Pesquisa vetorial utilizando HNSW..png
Pesquisa vetorial utilizando HNSW..png
Pesquisa de vectores utilizando HNSW.
O HNSW é um NSW de várias camadas, em que a camada mais baixa contém todos os pontos de dados e a camada mais alta contém apenas um pequeno subconjunto dos nossos pontos de dados. Isto significa que quanto mais alta a camada, mais pontos de dados saltamos, o que corresponde à teoria das listas de saltos.
Com o HNSW, temos um gráfico em que a maioria dos nós pode ser alcançada a partir de qualquer outro nó através de um pequeno número de iterações. Esta propriedade permite que o HNSW navegue eficientemente pelo grafo para encontrar rapidamente os vizinhos mais próximos. Como o HNSW é otimizado para CPUs, também podemos paralelizar sua execução em vários núcleos de CPU para acelerar ainda mais o processo de pesquisa vetorial.
No entanto, o tempo de computação do HNSW continua a sofrer à medida que armazenamos mais dados na base de dados vetorial. A situação pode agravar-se ainda mais se a dimensionalidade dos nossos vectores for muito elevada. Por conseguinte, precisamos de outra solução para os casos em que temos um grande número de vectores com elevada dimensionalidade.
Operação de pesquisa de vetor na GPU
Uma solução para melhorar o desempenho da pesquisa vetorial ao lidar com um grande número de vetores de alta dimensionalidade é operar em uma GPU. **Para facilitar isso, podemos utilizar o RAPIDS cuVS da NVIDIA, uma biblioteca que contém várias implementações de pesquisa vetorial otimizadas para GPU. Ela simplifica o uso de GPUs para operações de pesquisa vetorial e construção de índices.
O cuVS oferece vários algoritmos de vizinho mais próximo para escolher, incluindo:
Brute-force: Uma pesquisa exaustiva de vizinhos mais próximos em que a consulta é comparada a cada vetor na base de dados.
IVF-Flat**: Um algoritmo de vizinho mais próximo aproximado (ANN) que divide os vectores da base de dados em várias partições que não se intersectam. A consulta é então comparada apenas com vectores nas mesmas partições (e, opcionalmente, nas partições vizinhas).
IVF-PQ**: Uma versão quantizada do IVF-Flat que reduz o espaço de memória dos vectores armazenados na base de dados.
CAGRA: Um algoritmo nativo da GPU semelhante ao HNSW.
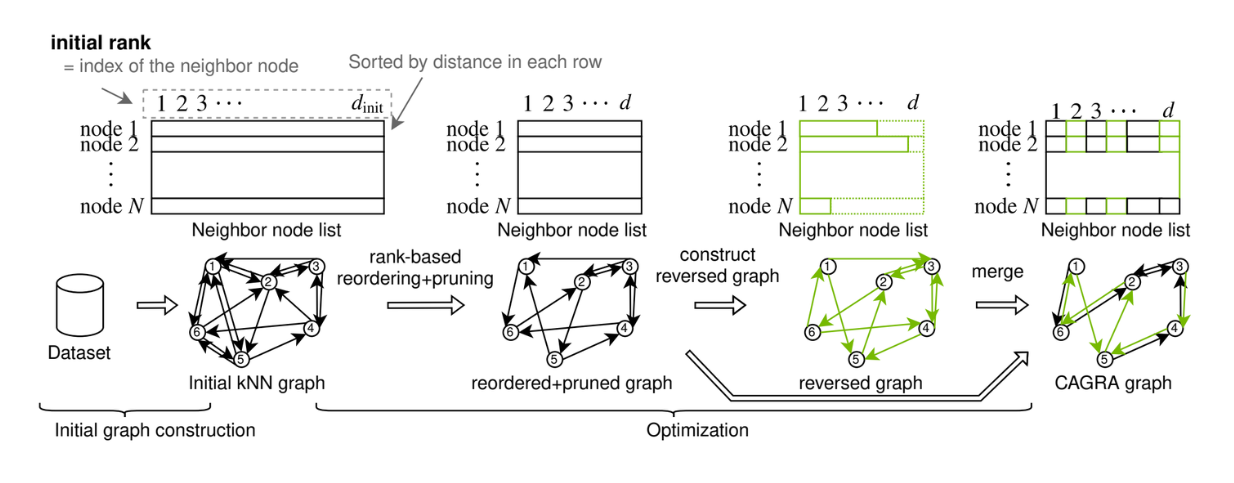 CAGRA graph construction. .png
CAGRA graph construction. .png
CAGRA graph construction. Source.
Entre estes algoritmos de vizinho mais próximo, vamos concentrar-nos no CAGRA.
O CAGRA é um algoritmo baseado em grafos introduzido pela NVIDIA para pesquisa rápida e eficiente do vizinho mais próximo aproximado, aproveitando o poder de processamento paralelo das GPUs.
O grafo no CAGRA pode ser construído usando o método IVF-PQ ou o método NN-DESCENT:
Método IVF-PQ**: Utiliza um índice para criar um grafo inicial eficiente em termos de memória, conectando cada ponto a muitos vizinhos.
Método NN-DESCENT**: Usa um processo iterativo para construir um gráfico expandindo e refinando as conexões entre os pontos.
Em comparação com o HNSW, os métodos de construção de gráficos do CAGRA são mais fáceis de paralelizar e contêm menos interação de dados entre tarefas, o que melhora significativamente o tempo de construção de gráficos ou índices. Se quiser saber mais pormenores sobre o CAGRA, consulte o seu documento oficial ou o artigo CAGRA.
O CAGRA estabeleceu um desempenho topo de gama nas operações de pesquisa vetorial. Para o demonstrar, comparamos o seu desempenho com o do HNSW na próxima secção.
Comparação do desempenho do CAGRA e do HNSW
Existem duas operações críticas na pesquisa vetorial em que o desempenho é crucial: a construção do índice e a própria pesquisa. Vamos comparar o desempenho do CAGRA e do HNSW nessas duas operações.
Vamos começar com a construção do índice.
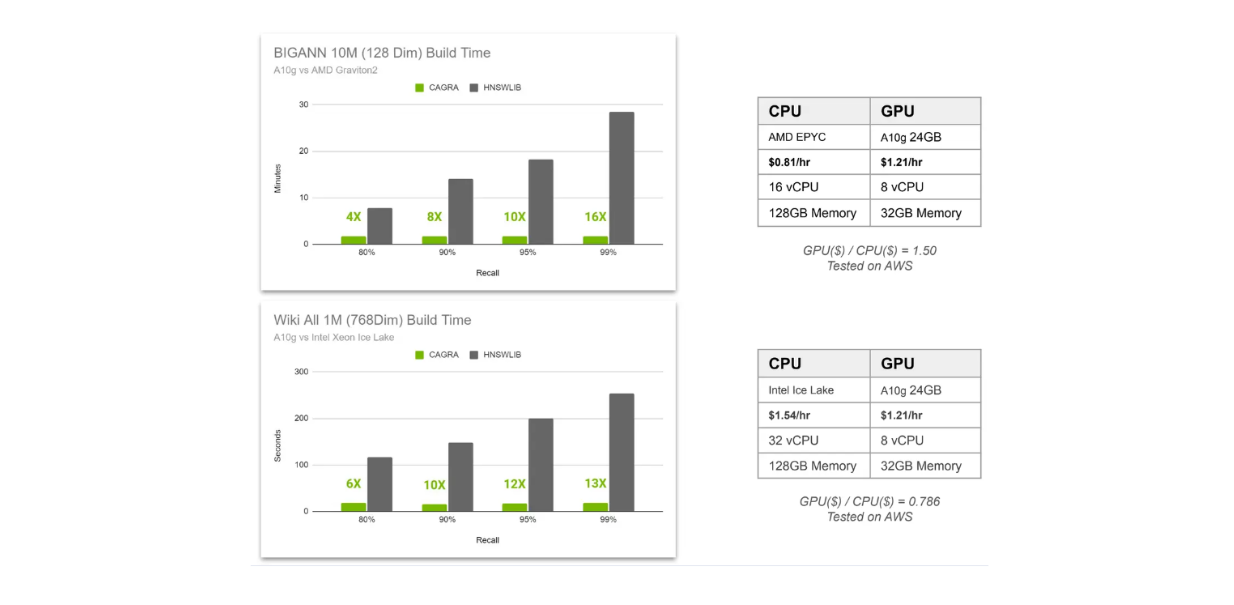 Comparação do tempo de construção de índice CAGRA vs HNSW..png
Comparação do tempo de construção de índice CAGRA vs HNSW..png
Comparação do tempo de construção do índice CAGRA vs HNSW.
Na visualização acima, comparamos o tempo de construção de índices de CAGRA e HNSW em dois cenários diferentes. Primeiro, temos 10 milhões de vectores de 128 dimensões armazenados numa base de dados de vectores e, segundo, temos 1 milhão de vectores de 768 dimensões. O primeiro cenário usa AMD Graviton2 como CPU para HNSW e GPU A10G para CAGRA, enquanto o segundo cenário usa Intel Xeon Ice Lake como CPU para HNSW e GPU A10G para CAGRA.
Comparamos o tempo de criação do índice em quatro valores de recuperação diferentes, variando de 80% a 99%. Como já deve saber, quanto maior for a recuperação, mais intensiva será a computação necessária.
Isto deve-se ao facto de, numa pesquisa vetorial baseada em grafos, podermos afinar dois factores: o número de vizinhos considerados para encontrar o vizinho mais próximo em cada camada e o número de vizinhos mais próximos a considerar como ponto de entrada em cada camada. Quanto maior for a recuperação, mais vizinhos serão considerados, o que resulta numa maior precisão de recuperação, mas também num custo computacional mais elevado.
A partir da visualização acima, vemos mais valor na utilização da GPU quando queremos resultados com elevada recuperação. Além disso, a aceleração da utilização da GPU aumenta à medida que aumentamos o número de vectores de elevada dimensão armazenados na nossa base de dados de vectores.
Em seguida, vamos comparar o desempenho do HNSW e do CAGRA usando duas métricas comuns na pesquisa de vetores:
Throughput: o número de consultas que podem ser concluídas num intervalo de tempo específico.
Latência**: o tempo que o algoritmo necessita para completar uma consulta.
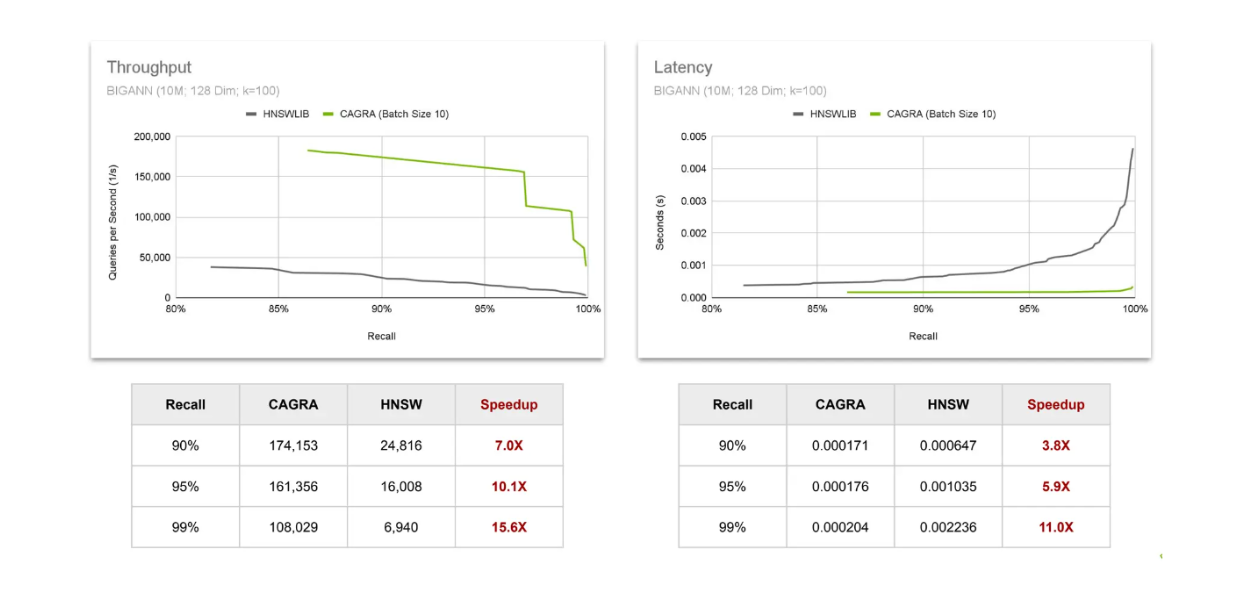 Comparações de taxa de transferência e latência CAGRA vs HNSW..png
Comparações de taxa de transferência e latência CAGRA vs HNSW..png
Comparações de rendimento e latência CAGRA vs HNSW.
Para avaliar a taxa de transferência, observamos o número de consultas que podem ser concluídas em um segundo. Os resultados mostram que o aumento de velocidade da utilização do CAGRA na GPU aumenta à medida que exigimos resultados com valores de recuperação mais elevados. A mesma tendência é observada para a latência, em que a aceleração aumenta à medida que o valor de recuperação aumenta. Isto confirma que o valor da utilização da GPU aumenta à medida que procuramos resultados mais precisos da pesquisa vetorial.
No entanto, por vezes, continuamos a querer utilizar a CPU durante a pesquisa de vectores devido à sua simplicidade e fácil integração com outros componentes da nossa aplicação de IA. Neste caso, a implementação de algoritmos de vizinhos mais próximos com o CAGRA continua a ser útil porque podemos efetuar a pesquisa vetorial tanto na GPU como na CPU.
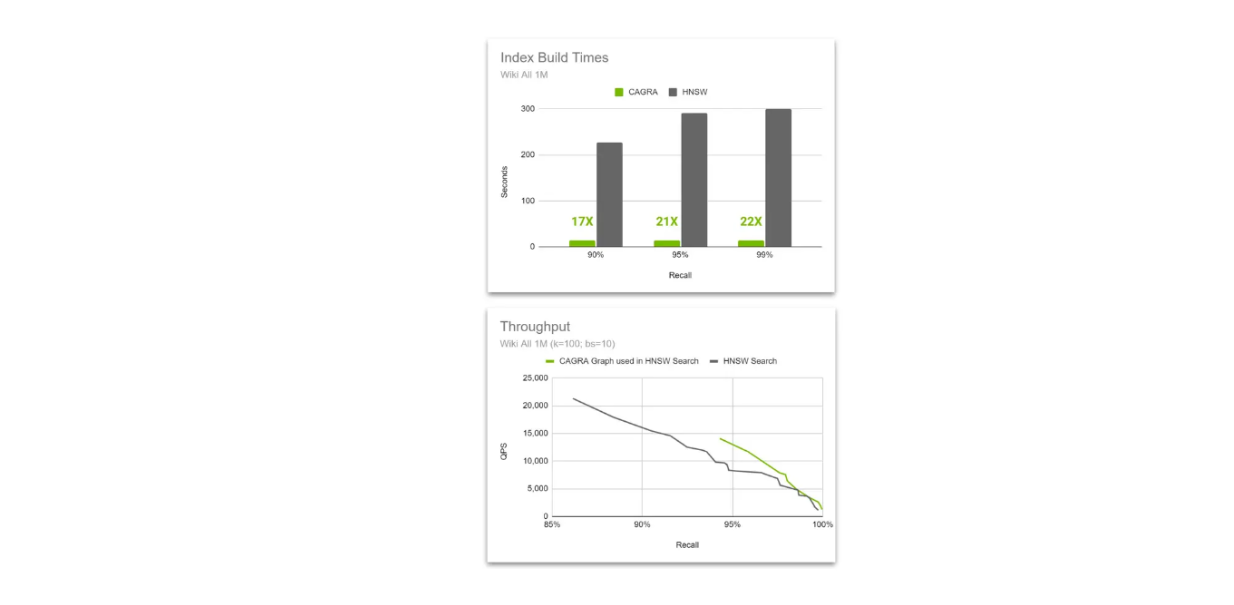 Comparação da taxa de transferência entre o gráfico HNSW nativo e o gráfico CAGRA utilizado na pesquisa HNSW..png
Comparação da taxa de transferência entre o gráfico HNSW nativo e o gráfico CAGRA utilizado na pesquisa HNSW..png
Comparação do rendimento entre o gráfico HNSW nativo e o gráfico CAGRA utilizado na pesquisa HNSW.
A ideia é utilizar o poder de aceleração do CAGRA e da GPU durante a construção do índice, mas depois mudar para o HNSW durante a pesquisa vetorial. Este método é possível porque o algoritmo HNSW pode efetuar uma pesquisa utilizando um grafo construído pelo CAGRA, e o seu desempenho é ainda melhor do que o do grafo construído com o HNSW à medida que a dimensão do vetor aumenta.
O CAGRA também oferece um método de quantização chamado CAGRA-Q para comprimir ainda mais a memória dos vectores armazenados. Isto é particularmente útil para tornar a atribuição de memória mais eficiente e permite-nos armazenar vectores quantizados em dispositivos de memória mais pequenos para uma recuperação mais rápida.
Digamos que temos uma memória de dispositivo que tem um tamanho de memória menor em comparação com a memória do host. Os testes de desempenho iniciais da NVIDIA mostraram que os vectores quantizados armazenados na memória do dispositivo com o gráfico armazenado na memória do anfitrião terão um desempenho semelhante ao dos vectores originais não quantizados e do gráfico armazenado na memória do dispositivo a taxas de recuperação mais elevadas.
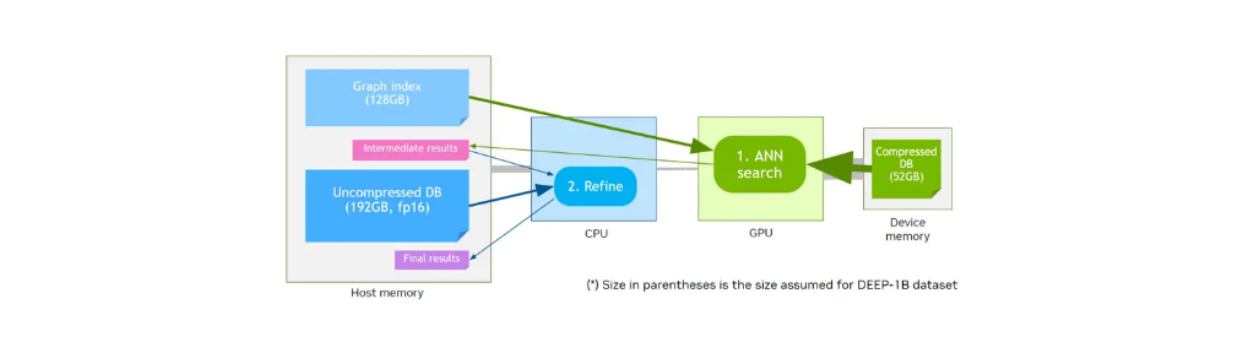 Fluxo de trabalho de pesquisa de vectores utilizando a memória do dispositivo e o CAGRA-Q..png
Fluxo de trabalho de pesquisa de vectores utilizando a memória do dispositivo e o CAGRA-Q..png
Fluxo de pesquisa de vectores utilizando a memória do dispositivo e o CAGRA-Q.
Milvus na GPU com CuVS
Milvus suporta a integração com a biblioteca cuVS, permitindo-nos combinar o Milvus com o CAGRA para criar aplicações de IA. A arquitetura do Milvus consiste em vários nós, tais como nós de índice, nós de consulta e nós de dados. O cuVS optimiza o desempenho do Milvus acelerando os processos nos nós de consulta e nos nós de índice.
O cuVS suporta os nós de consulta e de índice da arquitetura Milvus..png](https://assets.zilliz.com/cu_VS_supports_both_query_and_index_nodes_of_Milvus_architecture_811a8ae3e3.png)
cuVS suporta nós de consulta e de índice da arquitetura Milvus.
Como já deve saber, os nós de índice são responsáveis pela construção do índice, enquanto os nós de consulta processam as consultas do utilizador, efectuam pesquisas vectoriais e devolvem os resultados ao utilizador. Vimos como o CAGRA melhora todos estes aspectos em comparação com algoritmos nativos da CPU, como o HNSW, na secção anterior.
Agora, vamos examinar o desempenho da criação de índices com o cuVS e o Milvus local. Especificamente, vamos analisar o tempo de construção do índice utilizando o CAGRA e o IVF-PQ em diferentes números de vectores: 10, 20, 40 e 80 milhões.
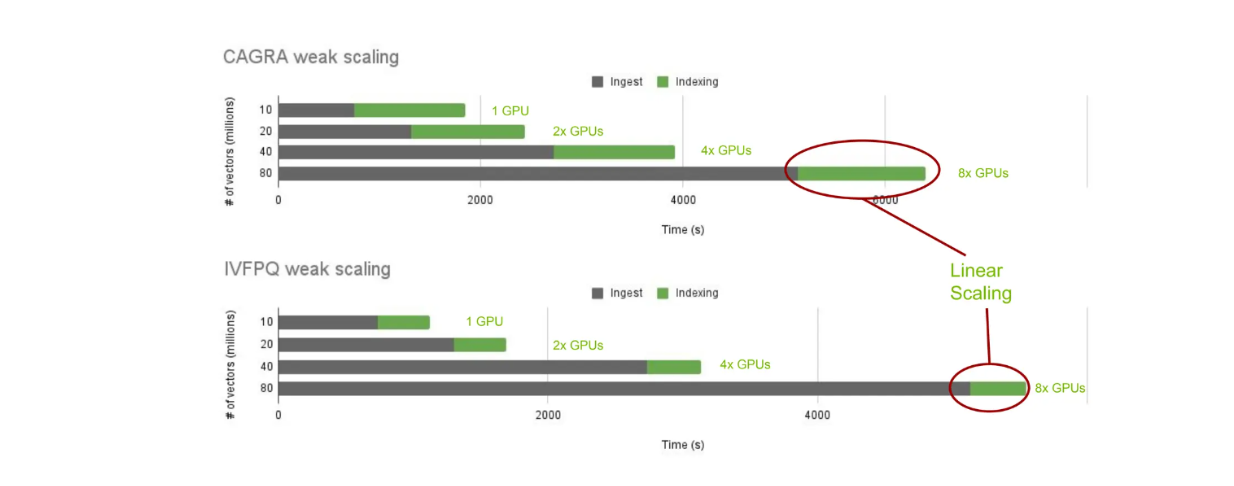 Escala cuVS do tempo de criação de índices em diferentes algoritmos de vizinhos mais próximos..png
Escala cuVS do tempo de criação de índices em diferentes algoritmos de vizinhos mais próximos..png
escala cuVS do tempo de construção do índice em diferentes algoritmos de vizinhos mais próximos.
Como esperado, o tempo de ingestão aumenta à medida que o número de vectores armazenados aumenta. No entanto, o tempo de construção do índice permanece constante à medida que adicionamos linearmente mais GPUs, dependendo do número de vectores armazenados. Isto permite-nos escalar e comparar o tempo de construção do índice entre diferentes algoritmos de vizinhança mais próxima com o cuVS.
Sabemos que as GPUs oferecem operações computacionais mais rápidas em comparação com as CPUs. No entanto, o custo operacional da utilização de GPUs também é mais elevado. Portanto, precisamos comparar a relação custo-desempenho do uso de GPUs e CPUs com o Milvus, conforme visualizado abaixo.
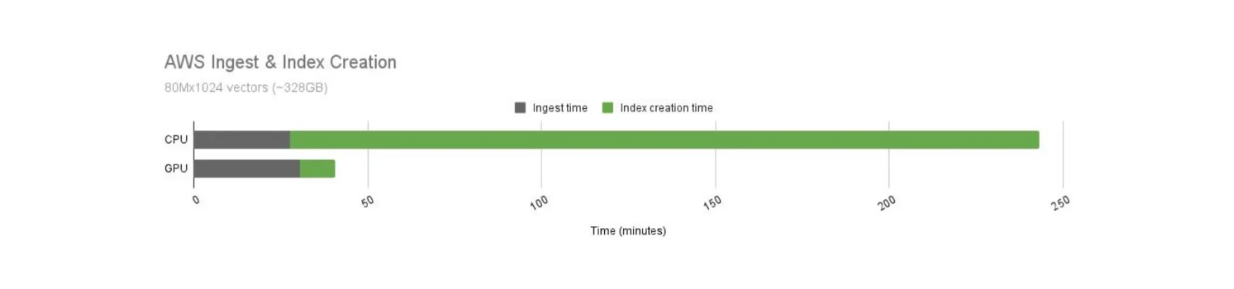 Comparação do tempo de construção do índice Milvus entre GPU e CPU..png
Comparação do tempo de construção do índice Milvus entre GPU e CPU..png
Comparação do tempo de construção do índice Milvus entre GPU e CPU.
O tempo de construção do índice usando GPUs é significativamente mais rápido do que CPUs. Neste caso de uso, o Milvus acelerado por GPU oferece um aumento de velocidade de 21x em comparação com sua contraparte de CPU. No entanto, o custo operacional das GPUs também é mais caro do que o das CPUs. A GPU custa 9,68 por hora.
Quando normalizamos a relação custo-desempenho de GPUs e CPUs, o uso de GPUs para a criação de índices ainda produz melhores resultados. Com o mesmo custo, o tempo de criação do índice é 12,5x mais rápido usando GPUs.
Em outro teste de benchmark, criamos um índice para 635M vetores de 1024 dimensões. Usando 8 GPUs DGX H100, o tempo de construção do índice com o método IVF-PQ leva cerca de 56 minutos. Em contraste, usar uma CPU para executar a mesma tarefa levaria aproximadamente 6,22 dias para ser concluída.
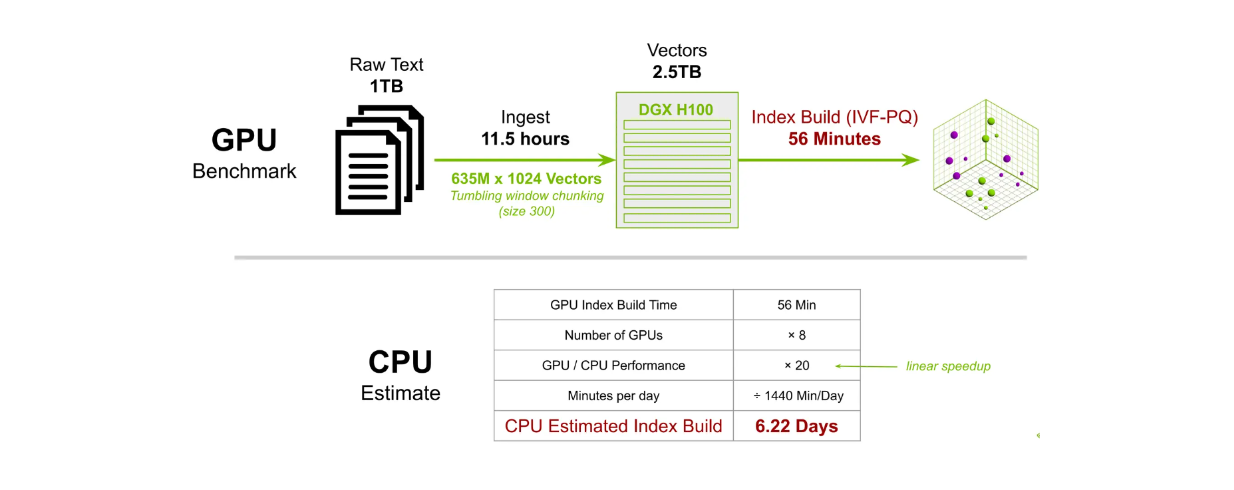 Comparação do tempo de construção do índice Milvus em grande escala entre GPU e CPU..png
Comparação do tempo de construção do índice Milvus em grande escala entre GPU e CPU..png
Comparação do tempo de construção do índice Milvus em grande escala entre GPU e CPU.
Conclusão
Os avanços na pesquisa vetorial acelerada por GPU por meio da biblioteca cuVS da NVIDIA e do algoritmo CAGRA são altamente benéficos para otimizar o desempenho de aplicativos de IA em produção. Especificamente, as GPUs oferecem melhorias significativas em relação às CPUs em casos que envolvem altos valores de recall, alta dimensionalidade de vetor e um grande número de vetores.
Graças às capacidades de integração do Milvus, podemos agora incorporar facilmente o cuVS na nossa base de dados de vectores Milvus. Embora as GPUs tenham custos operacionais mais altos do que as CPUs, a relação desempenho-custo muitas vezes ainda favorece as GPUs em aplicações de grande escala, como demonstrado nos benchmarks acima. Se quiser saber mais sobre o cuVS, pode consultar a[ documentação abrangente] (https://rapids.ai/cuvs/) fornecida pela equipa da NVIDIA.
Outros recursos
O que é RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
O que são bases de dados vectoriais e como funcionam?](https://zilliz.com/learn/what-is-vetor-database)
Pesquisa vetorial eficiente no RecSys com Milvus e NVIDIA Merlin
Continue lendo

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Announcing the General Availability of Single Sign-On (SSO) on Zilliz Cloud
SSO is GA on Zilliz Cloud, delivering the enterprise-grade identity management capabilities your teams need to deploy vectorDB with confidence.