




Milvus 2.4 revela CAGRA: Elevando a pesquisa vetorial com indexação de GPU de última geração
O que é um índice baseado em GPU?
A pesquisa vetorial é inerentemente intensiva em termos de computação. Sendo a base de dados vetorial com melhor desempenho, a Milvus atribui mais de 80% dos seus recursos de computação às suas bases de dados vectoriais e ao seu motor de pesquisa, Knowhere. Dadas as exigências computacionais da computação de alto desempenho, as GPU surgem como um elemento essencial da nossa plataforma de bases de dados vectoriais, especialmente no domínio da pesquisa vetorial.
A Milvus abriu um precedente ao tornar-se a primeira base de dados vetorial a tirar partido da aceleração da GPU com a sua Milvus versão 1.1 em 2021. Na versão 2.3, ao aproveitar a biblioteca RAFT da NVIDIA para pesquisa vetorial, Milvus introduziu índices acelerados por GPU e integração com a estrutura de recomendação NVIDIA Merlin (usada para construir sistemas de recomendação). A introdução dos índices IVFFLAT e IVFPQ nesta versão mostrou notáveis melhorias de desempenho.
Apesar destes avanços, persistem desafios como a otimização do desempenho para consultas em pequenos lotes e a melhoria da relação custo-eficácia dos índices baseados em GPU, o que leva a uma exploração contínua de soluções inovadoras. A mudança da indústria para os [algoritmos de pesquisa vetorial] baseados em grafos (https://zilliz.com/learn/popular-machine-learning-algorithms-behind-vetor-search), reconhecidos pelo seu desempenho superior aos métodos baseados em FIV, representa uma evolução fundamental. No entanto, a adaptação destes algoritmos aos GPU não é simples devido aos seus padrões de execução sequencial e de acesso aleatório à memória, o que torna a implementação eficiente dos GPU um desafio para algoritmos como o GGNN e o SONG
Ao abordar estes desafios, a mais recente inovação da NVIDIA, o índice gráfico baseado em GPU CAGRA, representa um marco significativo. Com a ajuda da NVIDIA, o Milvus integrou o suporte para o CAGRA na sua versão 2.4, marcando um passo significativo para ultrapassar os obstáculos da implementação eficiente da GPU na pesquisa vetorial.
O que é o CAGRA?
Construir o CAGRA
O CAGRA (CUDA Anns GRAph-based) apresenta uma nova abordagem para a construção de grafos, divergindo do método iterativo de inserção e atualização usado por grafos hierárquicos navegáveis de mundos pequenos (HNSW) em CPUs. Esta alteração responde ao desafio de aproveitar plenamente as capacidades de construção de grafos altamente paralelos das GPUs, que o processo de construção de HNSW baseado em CPU não capitaliza. O CAGRA começa por criar um grafo inicial usando IVFPQ ou NN-DESCENT, onde cada nó está ligado a vários vizinhos. Os passos seguintes envolvem a ordenação destas ligações por importância, a poda de arestas menos críticas e a fusão de grafos direcionados para finalizar a estrutura e construir um grafo inicial. No grafo inicial, cada nó tem um grande número de nós vizinhos. Em seguida, o CAGRA ordena todas as arestas adjacentes de acordo com a sua importância, com base no grafo inicial, e elimina as arestas sem importância.
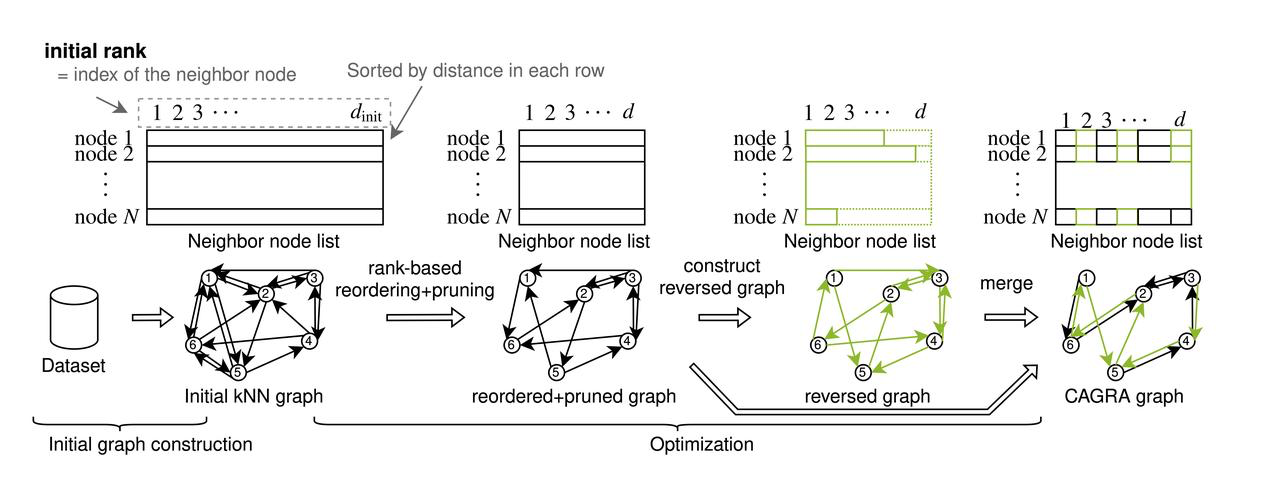 O processo de construção do CAGRA
O processo de construção do CAGRA
Construção inicial do gráfico
IVFPQ
No modo IVFPQ, o CAGRA aproveita o conjunto de dados para construir um índice IVFPQ, utilizando o recurso de quantização do índice Product Quantization (PQ) para minimizar o uso da memória de vídeo. Após a criação deste índice, o CAGRA efectua uma pesquisa para cada ponto no conjunto de dados, utilizando os vizinhos mais próximos aproximados identificados pelo índice IVFPQ como pesquisa de vizinhos mais próximos de pontos adjacentes. Esse processo forma a base para a construção do gráfico inicial, garantindo uma configuração eficiente sem ocupar muita memória.
NN-DESCENT
O CAGRA utiliza o algoritmo NN-DESCENT para outra abordagem à construção do grafo inicial, que envolve os seguintes passos detalhados:
Inicialização: Selecionar aleatoriamente k pontos do conjunto de dados v para criar a lista de adjacência inicial B[v].
Reversão e Fusão: Tomar o inverso de B[v] para gerar a lista de adjacência invertida R[v], e depois fundir B e R para formar H[v].
Expansão dos vizinhos: Para qualquer nó v no conjunto de dados, identificar todos os vizinhos dos vizinhos com base em H[v], selecionando os nós topk mais próximos como seus novos vizinhos.
Iteração: Repetir o processo de Reversão e fusão e Expansão de vizinhos até B estabilizar e não mudar mais ou até que um limite de iteração predefinido seja atingido.
Em comparação com o HNSW, o NN-Descent oferece uma paralelização mais fácil e menos interação de dados entre tarefas, aumentando significativamente o tempo de construção do gráfico e a eficiência do gráfico de adjacência CAGRA em GPUs. No entanto, é de notar que a qualidade inicial do grafo em NN-DESCENT pode ficar ligeiramente aquém da obtida com o modo IVFPQ.
Otimização do CAGRA
A estratégia de otimização de grafos do CAGRA baseia-se em dois pressupostos principais:
Ordenação por importância: É dada preferência à ordenação baseada em caminhos em vez da tradicional ordenação baseada em distâncias para determinar a importância das arestas. Este método argumenta que a conetividade do grafo pode não beneficiar necessariamente da ordenação de importância baseada na distância.
Fusão de grafos inversos: O princípio de que um nó considerado importante para um pode também ser importante para o outro está na base da estratégia de fusão de grafos inversos.
O processo de otimização inclui duas etapas principais:
- Inicialmente, são atribuídos vários pesos ('w')** às arestas adjacentes de cada nó, com base na distância. O CAGRA emprega uma estratégia de poda em que as arestas são cortadas se conectarem nós que são mais 'desfavoráveis', com base na condição 'max(w_{x to z},w_{z to y}) < w_{x to y}'. Isto centra-se na eliminação de ligações menos críticas para simplificar o gráfico.
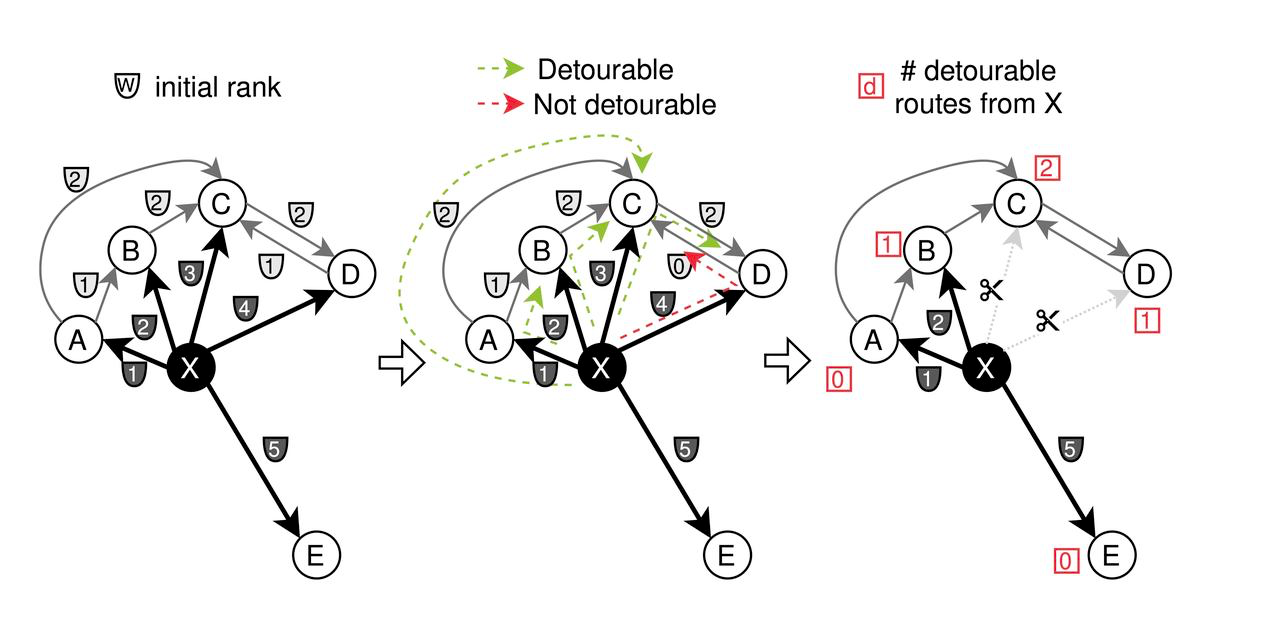 Processo de poda para otimização CAGRA
Processo de poda para otimização CAGRA
- Fusão: Após a poda do grafo avançado com base na significância do caminho, as arestas são invertidas e fundidas. Especificamente, metade das arestas são selecionadas dos gráficos direto e inverso para criar o gráfico CAGRA optimizado final.
Esta abordagem detalhada à construção e otimização do grafo garante a eficiência e eficácia do CAGRA em operações de pesquisa vetorial, tirando partido das capacidades únicas das GPUs e enfrentando os desafios inerentes aos algoritmos de pesquisa baseados em grafos.
Pesquisando com o CAGRA
O mecanismo de pesquisa do CAGRA emprega uma abordagem metódica usando uma fila de prioridade ordenada de tamanho fixo para navegação eficiente no gráfico. Este processo detalhado é delineado através de uma série de etapas dentro de um quadro estruturado:
Estrutura de pesquisa CAGRA
O CAGRA funciona com um buffer de memória sequencial que inclui uma lista interna de topo-M e uma lista de candidatos. A lista interna top-M actua como uma fila de prioridades, com o seu comprimento definido para M (onde M ≥ k), garantindo que pode armazenar os resultados mais relevantes até ao número desejado de vizinhos mais próximos, k. O tamanho da lista de candidatos é determinado por p × d, com p a representar o número de nós de origem explorados em cada iteração e d a indicar o grau do grafo. Cada elemento destas listas emparelha um índice de nó com a distância à consulta, permitindo uma gestão eficiente da pesquisa.
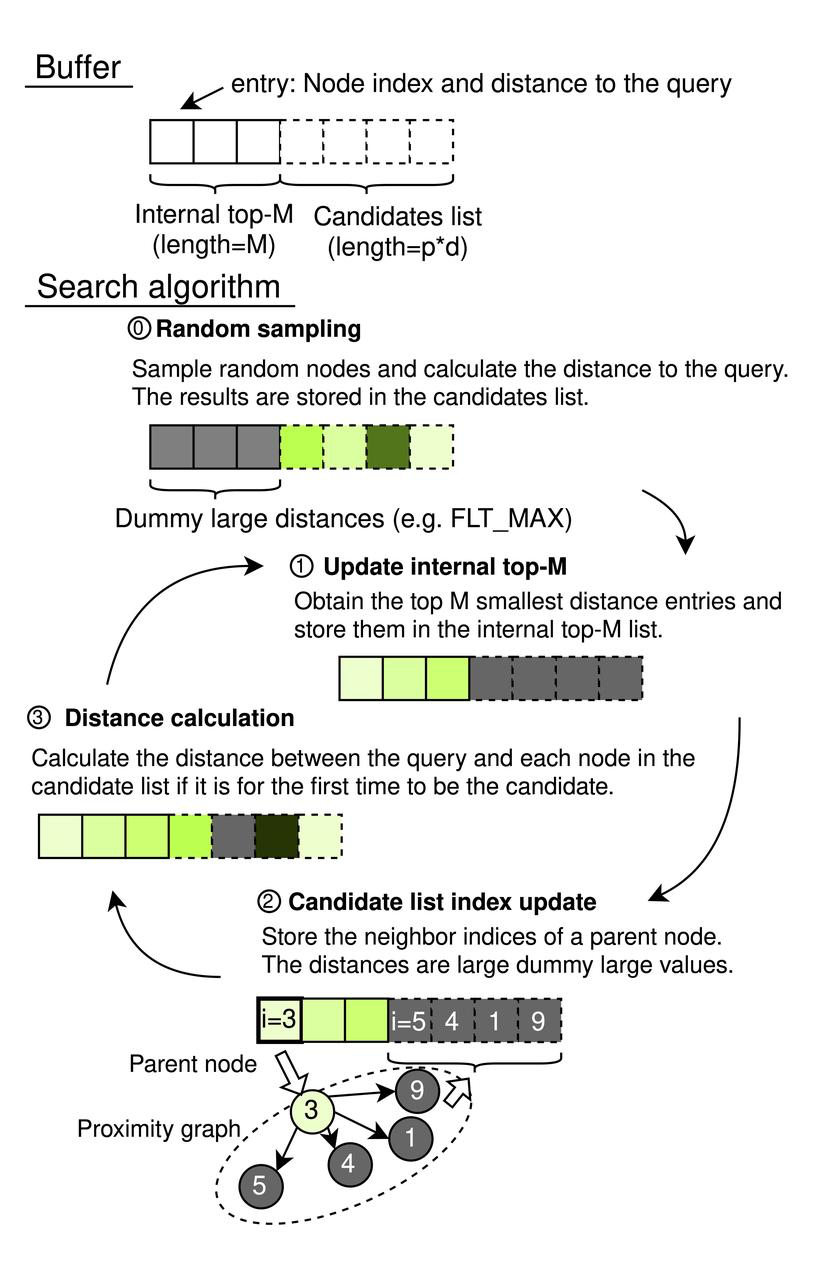 Processo de pesquisa CAGRA
Processo de pesquisa CAGRA
Etapas do processo de pesquisa
- Amostragem aleatória (Inicialização)
- Utiliza um gerador pseudo-aleatório para selecionar p × d índices de nós aleatórios, calculando a distância entre cada nó e a consulta.
- Os resultados preenchem a lista de candidatos, enquanto a lista interna top-M é inicializada com entradas virtuais (definidas para FLT_MAX) para evitar influenciar os resultados da ordenação inicial.
Atualização da lista interna Top-M: Selecionar os nós Top-M com base nas distâncias mais pequenas em toda a memória intermédia para inclusão na lista interna Top-M.
Atualização do índice da lista de candidatos (Graph Traversal):
- Identifica todos os nós vizinhos dos p nós do topo da lista interna top-M, excluindo os nós usados anteriormente através de um filtro de tabela de hash.
- Adiciona estes vizinhos à lista de candidatos sem recalcular as distâncias nesta fase.
- **Cálculo da distância
- Efectua cálculos de distância para os nós que aparecem recentemente na lista de candidatos, evitando cálculos redundantes para nós avaliados em iterações anteriores.
- Assegura que os nós só são adicionados à lista Top-M se as suas distâncias justificarem a sua relevância, com base no facto de serem suficientemente pequenos para pertencerem ou demasiado grandes para serem considerados.
O algoritmo processa estes passos de forma iterativa, percorrendo todos os nós da lista interna de top-M até que todos tenham servido como pontos de partida para a pesquisa. A pesquisa termina com a extração das k entradas de topo da lista interna de topo-M, apresentando os resultados da pesquisa Approximate Nearest Neighbor (ANNS).
Desempenho
A decisão de aproveitar os índices GPU foi motivada principalmente por considerações de desempenho. Realizámos uma avaliação exaustiva do desempenho do Milvus utilizando uma ferramenta de benchmark [open-source vetor database] (https://zilliz.com/product/open-source-vetor-database), concentrando-nos em comparações entre os índices HNSW, IVFFLAT baseado em GPU e CAGRA.
Configuração de benchmarking
Para uma avaliação realista, os nossos testes de referência foram realizados em máquinas alojadas na AWS equipadas com GPUs NVIDIA T4 e A10G, garantindo que os ambientes de teste reflectem os recursos normalmente disponíveis. As máquinas selecionadas tinham preços comparáveis, proporcionando condições equitativas para a avaliação do desempenho. Todos os testes tinham como objetivo alcançar top100@98% de recordação, utilizando uma instância AWS m6i.4xlarge (16C64G) como cliente.
 Informações básicas da máquina selecionada
Informações básicas da máquina selecionada
Insights de desempenho
Desempenho de pequenos lotes:
Em situações com pequenos lotes de pesquisa (tamanho de lote de 1), onde as GPUs são geralmente subutilizadas, o CAGRA superou significativamente suas contrapartes. Nossos testes revelaram que o CAGRA pode oferecer quase 10 vezes o desempenho dos métodos tradicionais nessas condições.
![Comparação de desempenho para conjunto de dados de lote pequeno] (https://assets.zilliz.com/Performance_Comparison_for_Small_Batch_Data_Set_b9bcc9f26e.png)
Desempenho de grandes lotes:
Ao examinar lotes de pesquisa maiores (tamanhos de 10 e 100), a vantagem do CAGRA tornou-se ainda mais pronunciada. Contra o HNSW, o CAGRA apresentou um aumento dramático de desempenho, melhorando a eficiência da pesquisa em dezenas de vezes.
![Comparação de desempenho para conjunto de dados de lote grande] (https://assets.zilliz.com/Performance_Comparison_for_Large_Batch_Data_Set_ef371476c6.png)
Índice de Eficiência de Edifícios:
Além dos recursos de pesquisa, a proficiência do CAGRA se estende à construção de índices. Com a aceleração de GPU, o CAGRA demonstrou a capacidade de construir índices aproximadamente 10 vezes mais rápido do que métodos alternativos.
![Comparação de desempenho para construção de índices] (https://assets.zilliz.com/Performance_Comparison_for_Index_Building_2368e7a64e.png)
Os resultados de benchmark destacam os benefícios substanciais de desempenho da adoção de índices acelerados por GPU, como o CAGRA, no Milvus. Não só se destaca na aceleração de tarefas de pesquisa em tamanhos de lote, como também melhora significativamente a velocidade de construção do índice, afirmando o valor das GPUs na otimização do desempenho da base de dados vetorial.
O que vem a seguir?
O CAGRA marca um salto significativo em nossa busca para redefinir os limites da pesquisa vetorial, mostrando o potencial da pesquisa baseada em GPU para enfrentar os desafios de produção mais exigentes. À medida que avançamos, a Milvus está determinada a explorar mais profundamente os aspectos de [high recall] (https://zilliz.com/blog/diskann-a-disk-based-anns-solution-with-high-recall-and-high-qps-on-billion-scale-dataset), baixa latência, eficiência de custos e escalabilidade na pesquisa vetorial. O nosso compromisso vai além das realizações actuais, abrangendo uma gestão de dados mais flexível, capacidades de pesquisa enriquecidas e optimizações de desempenho revolucionárias.
Esta visão leva-nos a inovar continuamente, assegurando que a Milvus lidera e é pioneira no futuro da pesquisa acelerada para [dados não estruturados] (https://zilliz.com/glossary/unstructured-data). Ao ultrapassar os limites do que é possível hoje, pretendemos desbloquear novas possibilidades para o futuro, tornando a pesquisa vetorial mais poderosa, eficiente e acessível.
 Dicas e truques práticos para desenvolvedores que usam bancos de dados vetoriais.png
Não tem certeza de qual índice escolher para sua solução? Temos um blogue que o ajuda a fazer a escolha certa!*
Dicas e truques práticos para desenvolvedores que usam bancos de dados vetoriais.png
Não tem certeza de qual índice escolher para sua solução? Temos um blogue que o ajuda a fazer a escolha certa!*

Continue lendo

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.