




WhyHow
Build more controlled retrieval workflows within your RAG pipeline with WhyHow and Milvus or Zilliz Cloud
Utilizzate questa integrazione gratuitamenteChe cos'è il WhyHow?
WhyHow è una piattaforma che fornisce agli sviluppatori gli elementi di base per organizzare, contestualizzare e recuperare in modo affidabile i dati non strutturati per eseguire complesse operazioni di Retrieval Augmented Generation (RAG). Il Rule-based Retrieval Package è un pacchetto Python sviluppato da WhyHow che aiuta gli sviluppatori a creare flussi di lavoro di recupero più accurati all'interno di RAG, aggiungendo funzionalità di filtraggio avanzate. Questo pacchetto si integra con OpenAI per la generazione del testo e con Milvus e Zilliz Cloud (Milvus completamente gestito) per un'efficiente archiviazione vettoriale e la ricerca di similarità.
Perché integrare WhyHow e Milvus/Zilliz?
La Retrieval Augmented Generation (RAG) è una tecnologia avanzata che migliora i modelli linguistici di grandi dimensioni (LLMs fornendo informazioni contestuali alla query per ottenere risposte più accurate. Tuttavia, una semplice pipeline RAG può talvolta non riuscire a recuperare in modo coerente i dati corretti. Questo problema può essere dovuto alla natura "black-box" del reperimento e della generazione di risposte LLM, a richieste dell'utente mal formulate che producono risultati non ottimali da un database vettoriale o alla necessità di includere nelle risposte dati contestualmente rilevanti ma semanticamente dissimili.
Per superare queste sfide, dobbiamo avere un maggiore controllo sul recupero dei dati grezzi. Integrando WhyHow e Milvus/Zilliz, possiamo costruire una soluzione di recupero basata su regole. Questo approccio consente di definire e mappare regole specifiche per i pezzi di dati rilevanti prima di eseguire una similarity search, migliorando il controllo sul flusso di lavoro di recupero. L'implementazione di queste regole restringe l'ambito delle query a un insieme più mirato di pezzi, aumentando le possibilità di recuperare dati pertinenti per generare risposte accurate. Con ulteriori modifiche e messe a punto delle query, la qualità dei risultati può essere continuamente migliorata.
Come funziona l'integrazione WhyHow e Milvus/Zilliz
La soluzione di reperimento basata su regole costruita con WhyHow e Milvus/Zilliz svolge i seguenti compiti:
Questa integrazione crea una collezione Milvus per memorizzare gli embeddings dei chunk.
Splitting, Chunking e Embedding: Quando si caricano i documenti, l'integrazione divide, suddivide e crea automaticamente le incorporazioni dei documenti prima di inserirli in Milvus o Zilliz Cloud. Questo pacchetto di recupero basato su regole supporta attualmente PyPDFLoader e RecursiveCharacterTextSplitter di LangChain per l'elaborazione dei PDF, l'estrazione dei metadati e il chunking. Per l'incorporamento, supporta il modello OpenAI text-embedding-3-small.
Inserimento dei dati:** Carica le incorporazioni e i metadati su Milvus o Zilliz Cloud.
Filtrazione automatica:** Utilizzando regole definite dall'utente, l'integrazione costruisce automaticamente un filtro di metadati per restringere la query rispetto all'archivio vettoriale.
Il flusso di lavoro di questa integrazione è il seguente:
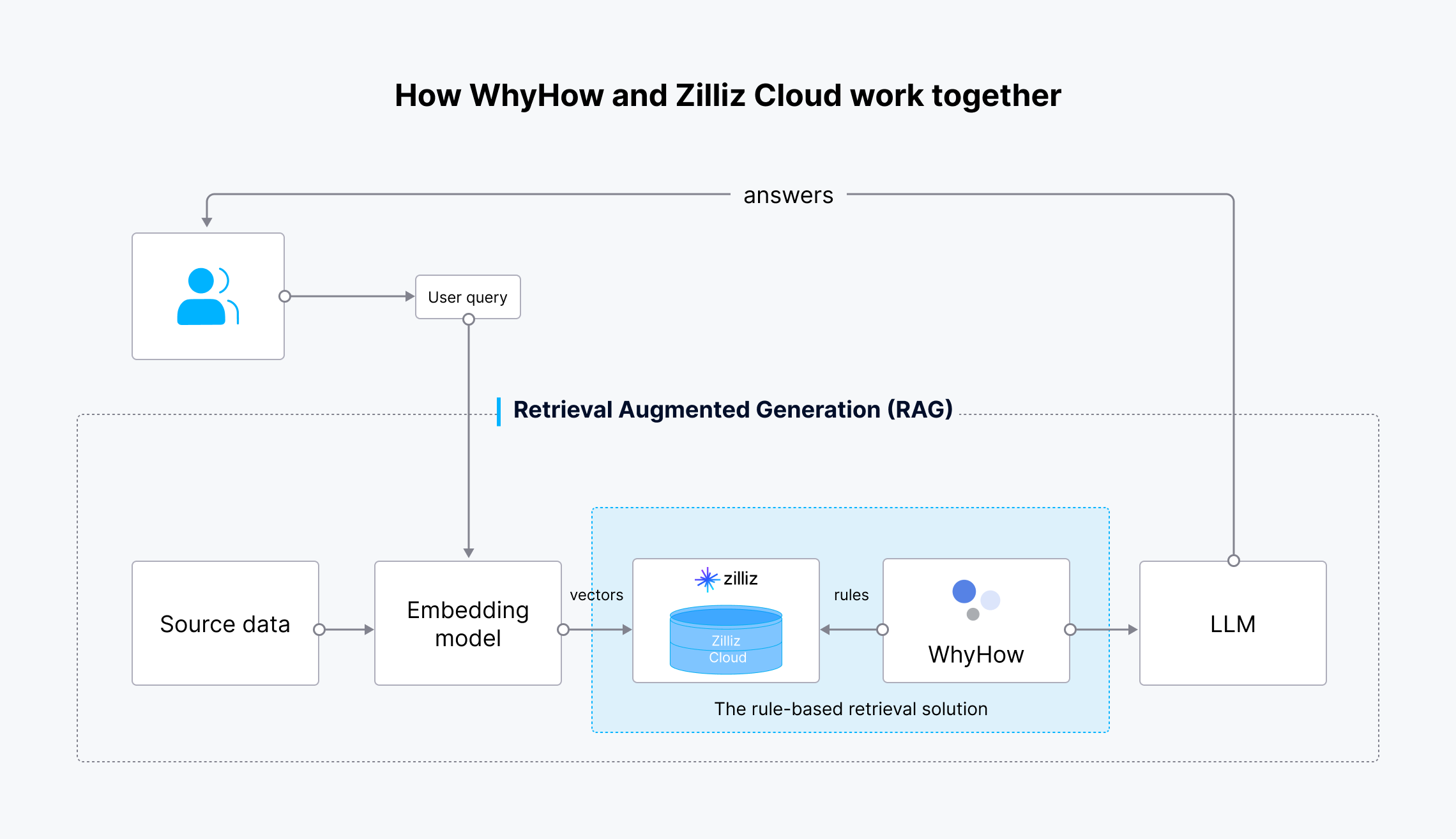 Come lavorano insieme WhyHow e Zilliz Cloud.png
Come lavorano insieme WhyHow e Zilliz Cloud.png
- I dati di partenza vengono trasformati in embeddings vettoriali utilizzando il modello di embedding di OpenAI.
- Gli embeddings vettoriali vengono inseriti in Milvus o Zilliz Cloud per essere archiviati e recuperati.
- Anche la domanda dell'utente viene trasformata in embeddings vettoriali e inviata a Milvus o Zilliz Cloud per la ricerca dei risultati più rilevanti.
- WhyHow imposta regole e aggiunge filtri alla ricerca vettoriale.
- I risultati recuperati e la domanda originale dell'utente vengono inviati al LLM.
- L'LLM genera risultati più accurati e li invia all'utente.
Come utilizzare WhyHow e Milvus/Zilliz Cloud