




Che cos'è una rete neurale? Guida per gli sviluppatori
Che cos'è una rete neurale? Guida per gli sviluppatori
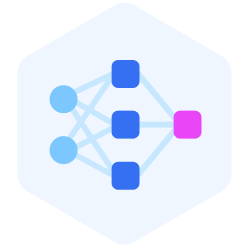
Cosa sono le reti neurali?
Le reti neurali sono modelli computazionali ispirati alla struttura del cervello umano. Sono costituite da neuroni disposti in strati. I neuroni sono funzioni di dati di ingresso, x, e di variabili tensoriali apprendibili (pesi e bias). Pensate a una rete neurale come a un grande modello F(x). Vale a dire, una funzione complessa e non lineare addestrata per adattarsi ai dati di ingresso. Questa tecnologia che cambia il paradigma consente alle macchine di comprendere modelli e risolvere problemi complessi.

Architettura della rete neurale
Una rete neurale è organizzata in strati: ingresso, nascosto e uscita.
- Strato di ingresso: È il punto in cui i dati vengono immessi nella rete.
- Strati nascosti: Questi strati intermedi elaborano i dati attraverso molteplici trasformazioni sequenziali. Ogni strato nascosto estrae caratteristiche sempre più astratte e complesse dai dati in ingresso.
- Strato di uscita: Lo strato finale produce il risultato sulla base delle informazioni elaborate dagli strati nascosti.
Importanza delle reti neurali
Le reti neurali sono fondamentali per diversi motivi.
- Riconoscimento dei modelli: Le reti neurali eccellono nel riconoscimento di schemi intricati nei dati, rendendole molto efficaci in compiti come il riconoscimento di immagini e del parlato.
- Adattabilità: Allenandosi su grandi insiemi di dati, le reti neurali possono adattarsi e migliorare le loro prestazioni nel tempo. Non linearità: Le reti neurali possono modellare relazioni complesse tra ingressi e uscite, comprese quelle non lineari.
- Elaborazione in parallelo: Le reti neurali possono elaborare i dati in parallelo, accelerando il calcolo per compiti su larga scala.
Principio di funzionamento delle reti neurali
Le reti neurali possono essere utilizzate in due modalità: addestramento e inferenza. Durante l'addestramento, la rete regola i suoi pesi di connessione elaborando i dati di ingresso e confrontando le sue previsioni con i risultati attesi. Questo processo minimizza le differenze tra le previsioni e i risultati effettivi utilizzando algoritmi di ottimizzazione come la discesa del gradiente. Una volta addestrata, la rete è pronta a fare previsioni utilizzando nuovi dati non visti. L'utilizzo di una rete neurale addestrata in questo modo si chiama inferenza.
Tipi di reti neurali
Reti neurali artificiali (RNA)
[Le reti neurali artificiali (https://zilliz.com/blog/ANN-machine-learning) (RNA), note anche come reti neurali feedforward, sono un tipo fondamentale di tecnologia delle reti neurali. Sono costituite da neuroni di ingresso, nascosti e di uscita, che rispecchiano la struttura interconnessa del cervello umano. Le RNA eccellono nel riconoscimento dei modelli regolando i pesi tra i neuroni.
Quando una RNA incorpora più strati nascosti, viene definita DNN (deep neural network). Queste reti eccellono nell'apprendimento di complesse gerarchie di caratteristiche da ampie serie di dati.
Come funzionano le reti neurali artificiali
Le RNA utilizzano l'elaborazione feedforward e la retropropagazione. Sono costituite da neuroni interconnessi con pesi e bias inizializzati, utilizzando metodi come inizializzazione zero o costante, inizializzazione casuale, inizializzazione Xavier o Glorot. I dati in ingresso vengono immessi nello strato di input e passati agli strati nascosti attraverso i bordi. I neuroni negli strati nascosti applicano funzioni di attivazione, introducendo una non linearità, e lo strato di uscita genera previsioni o risultati basati sui dati elaborati.
Queste previsioni vengono confrontate con i risultati effettivi per il [calcolo dell'errore] (https://saturncloud.io/blog/how-to-calculate-error-for-a-neural-network/). Durante l'addestramento, i segnali di errore vengono propagati all'indietro, regolando i pesi attraverso algoritmi di ottimizzazione per minimizzare le differenze tra le previsioni e i risultati effettivi.
Per saperne di più, potete consultare questo blog sulle RNA.
Applicazioni
Le RNA svolgono un ruolo significativo in una serie di compiti di regressione e classificazione che includono l'analisi del sentiment, la previsione dei prezzi delle azioni, la valutazione del rischio di credito, il rilevamento delle frodi, il trading algoritmico, il rilevamento delle anomalie, la manutenzione predittiva, ecc. Oltre a queste, le RNA sono anche alla base di una serie di altre reti neurali come le CNN e le RNN.
Reti neurali convoluzionali (CNN)
Le RNA tradizionali hanno strati completamente connessi che trattano ogni unità di ingresso in modo indipendente. Questa architettura non è adatta a gestire dati di tipo reticolare come le immagini. Le reti neurali convoluzionali (CNN) sono specializzate nell'elaborazione di dati di tipo reticolare, soprattutto immagini e video, poiché sono progettate per sfruttare la struttura spaziale delle immagini. Utilizzano la connettività locale, la condivisione dei parametri, l'apprendimento gerarchico delle caratteristiche, gli strati convoluzionali e gli strati di pooling per estrarre automaticamente le caratteristiche gerarchiche dai dati di input.
Architettura e funzionamento
- Strato di ingresso: L'ingresso per i dati delle immagini.
- Strati convoluzionali**: Questi livelli rilevano le caratteristiche spaziali, creando modelli strutturati all'interno delle immagini. Per identificare le diverse caratteristiche, alle immagini in ingresso viene applicata una serie di filtri apprendibili (kernel). Una CNN è tipicamente composta da diversi strati convoluzionali sovrapposti. Gli strati più profondi apprendono aspetti più astratti e complicati, mentre gli strati precedenti catturano informazioni semplici come bordi e texture. I risultati prodotti dagli strati di convoluzione sono chiamati mappe di caratteristiche.
- Livelli di pooling: Questi livelli eseguono fasi di riduzione in cui le dimensioni dei dati vengono diminuite mantenendo le informazioni essenziali. Anche se è possibile ridurre le dimensioni dei dati controllando lo stride della convoluzione, un modo efficiente per farlo è usare i livelli di pooling. Le operazioni di pooling più comuni sono il pooling massimo e il pooling medio.
- Livelli completamente connessi: Una volta ottenute le caratteristiche essenziali delle immagini, gli strati completamente connessi sono responsabili della predizione finale. Ogni strato FC è densamente connesso con lo strato precedente e con quello immediato e viene spesso utilizzato per produrre i punteggi e le probabilità per il compito di classificazione.
Per saperne di più, è possibile consultare questa guida completa su [CNN] (https://saturncloud.io/blog/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way/).

Applicazioni
Le CNN hanno rivoluzionato la classificazione delle immagini, il riconoscimento delle immagini, il rilevamento degli oggetti, la segmentazione delle immagini, l'analisi delle immagini mediche, il riconoscimento della scrittura, ecc. Tutti questi compiti coinvolgono dati di immagine in cui le CNN eccellono. Ma non è tutto. Grazie alla loro capacità di elaborare dati di tipo reticolare, le CNN vengono applicate anche in molti compiti legati al parlato, come il riconoscimento vocale, la traduzione, ecc.
Reti neurali ricorrenti (RNN)
Sebbene le RNA e le CNN siano adatte a molti compiti, non sono in grado di gestire le dipendenze temporali e le sequenze di dati. Le reti neurali ricorrenti (RNN) eccellono nell'analisi dei dati sequenziali, che è fondamentale per le attività che coinvolgono i dati delle serie temporali e l'elaborazione del linguaggio. Le RNN mantengono la memoria attraverso cicli di feedback. Le RNN lavorano su uno schema di memoria intrinseco, che consente loro di elaborare l'input corrente ricordando quello precedente. Questa memoria è ottenuta attraverso uno stato nascosto che si evolve man mano che la rete elabora ogni elemento della sequenza.
A volte, le RNN possono soffrire di un problema chiamato [vanishing gradient] (https://www.engati.com/glossary/vanishing-gradient-problem), che limita la loro capacità di catturare le dipendenze a lungo raggio. Per questo motivo, sono state proposte alcune variazioni all'architettura delle RNN che hanno portato alle architetture LSTM e GRU, le quali, conservando e aggiornando selettivamente le informazioni in contesti estesi, forniscono capacità migliori per modellare sequenze complicate.
Architettura e funzionamento
- Livello di ingresso: Questo livello riceve in ingresso dati sequenziali, che possono essere una sequenza di parole in una frase, dati di serie temporali, ecc. Ogni punto di questi dati sequenziali è rappresentato da un vettore, spesso noto come vettore di input.
- Strato ricorrente: Questo livello elabora e memorizza i dati sequenziali. A ogni passo temporale (t), questo strato elabora il vettore di input corrente e lo stato nascosto precedente (output) del passo temporale precedente (t-1) per produrre un nuovo stato o l'output per lo stato corrente.
- Strato di uscita: Questo livello produce i risultati dell'analisi sequenziale. L'architettura di questo livello di output dipende dal compito specifico. Ad esempio, nei compiti di sequenza-sequenza (ad esempio, la traduzione di una lingua), per lo strato di uscita si può utilizzare un'altra RNN o una rete neurale feedforward.
Per saperne di più, si può consultare questo blog sulle [RNN] (https://zilliz.com/blog/ANN-machine-learning).
Applicazioni
Le RNN sono utili per compiti in cui la sequenza o la dipendenza temporale sono importanti, come la traduzione linguistica, la generazione del parlato, il riconoscimento vocale, la generazione di musica, le previsioni del tempo, la previsione delle tendenze finanziarie, ecc.
Trasformatori
Le RNN sono soggette al problema del gradiente che svanisce, che limita la loro capacità di apprendere e propagare informazioni su lunghe sequenze. Inoltre, non sono in grado di comprendere l'ordine della sequenza. È qui che un'architettura a trasformatori può essere d'aiuto. I trasformatori utilizzano meccanismi di autoattenzione che consentono loro di pesare l'importanza delle diverse parti della sequenza in ingresso.
Questo meccanismo è in grado di catturare le dipendenze tra gli elementi di una sequenza, indipendentemente dalla loro posizione, rendendolo molto efficace per compiti come la traduzione linguistica, l'analisi del sentiment e la generazione di testi. Inoltre, fornisce capacità di elaborazione parallela, il che significa che può elaborare i dati in parallelo per gestire in modo efficiente sequenze lunghe e grandi insiemi di dati.
![]()
Architettura e funzionamento
Incorporazione dell'input: La sequenza di ingresso, ad esempio una sequenza di testo, viene convertita in embeddings. Questi embeddings sono la rappresentazione vettoriale numerica del testo, che può essere generata utilizzando un modello pre-addestrato come Word2vec o GloVe.
- Codifica posizionale: I modelli di trasformazione non comprendono intrinsecamente l'ordine degli elementi in una sequenza. Per questo motivo, alle incorporazioni in ingresso viene aggiunta una codifica posizionale che fornisce informazioni sulla posizione di ciascun elemento nella sequenza, ottenuta con l'aiuto di una combinazione di funzioni trigonometriche.
- Strati di codifica e decodifica del trasformatore: Gli strati di codifica e decodifica sono gli elementi costitutivi dei trasformatori, ripetuti più volte nella rete. Ciascuno di essi è composto da tre componenti principali:
- Attenzione a più teste: Calcola i punteggi di attenzione per ogni coppia di posizioni nella sequenza di ingresso. Cattura le dipendenze tra gli elementi, indipendentemente dalla loro posizione. L'output dell'autoattenzione multitesta è un insieme di rappresentazioni consapevoli del contesto per ogni posizione in ingresso.
- Rete di alimentazione: Le rappresentazioni ottenute dall'attenzione multitesta vengono passate a una rete feedforward che applica una serie di trasformazioni lineari e funzioni di attivazione non lineari a ogni posizione in modo indipendente.
- Connessioni residue e normalizzazione degli strati: Le connessioni residue (connessioni saltate) vengono aggiunte sia agli strati di autoattenzione multitesta che a quelli di feedforward, seguite dalla [normalizzazione degli strati] (https://zilliz.com/learn/layer-vs-batch-normalization-unlocking-efficiency-in-neural-networks). Questi componenti aiutano a stabilizzare l'addestramento e permettono al gradiente di fluire in modo più efficace.
- Strato di uscita: La parte superiore del decodificatore è un livello di uscita che genera previsioni o classificazioni.
Per saperne di più, consultate questo blog su Transformer Model.
Applicazioni
Le reti neurali, in particolare i trasformatori, hanno migliorato drasticamente l'elaborazione del linguaggio, consentendo traduzioni accurate, riassunti e analisi del sentiment.
Conclusione
Dopo aver letto questo articolo, ora conoscete le reti neurali, la loro architettura e il loro funzionamento. Avete visto diversi tipi di reti neurali e perché sono la scelta giusta per un caso d'uso specifico. Questo articolo era solo un punto di partenza, quindi sentitevi liberi di esplorare ogni tipo in dettaglio per una migliore comprensione.
- Cosa sono le reti neurali?
- Architettura della rete neurale
- Importanza delle reti neurali
- Principio di funzionamento delle reti neurali
- Tipi di reti neurali
- Reti neurali convoluzionali (CNN)
- Reti neurali ricorrenti (RNN)
- Conclusione
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente