




Agentic RAG: retrieval AI più intelligente con agenti autonomi
Agentic RAG: retrieval AI più intelligente con agenti autonomi
Immagina di avere un assistente di ricerca che non si limita a cercare in un solo database quando fai una domanda, ma decide in modo intelligente quali fonti consultare, convalida le informazioni che trova e persino riformula la tua domanda se necessario per ottenere risultati migliori. Questo è esattamente ciò che l'agentic RAG porta ai sistemi di intelligenza artificiale.
Mentre i sistemi tradizionali di Retrieval-Augmented Generation (RAG) hanno migliorato in modo significativo il modo in cui le applicazioni AI accedono alla conoscenza esterna, operano come una mente a binario unico, limitati a una sola fonte di conoscenza e a un singolo tentativo di recupero. L'agentic RAG trasforma questo approccio lineare in un sistema intelligente e adattivo che può pensare, pianificare e agire su più fonti di informazione per fornire risposte più accurate e complete.
Cos'è l'Agentic RAG?
L'agentic RAG è un'implementazione potenziata della Retrieval-Augmented Generation che incorpora agenti AI per orchestrare flussi di lavoro complessi di recupero e generazione di informazioni. A differenza dei sistemi RAG tradizionali che seguono una sequenza fissa di recupero e generazione, l'agentic RAG impiega agenti intelligenti capaci di ragionare, pianificare e prendere decisioni su come rispondere al meglio alle query degli utenti.
Al suo centro, l'agentic RAG utilizza agenti AI per facilitare la generazione aumentata dal recupero, migliorando la pipeline RAG con adattabilità e accuratezza e consentendo al contempo ai large language model di condurre il recupero di informazioni da più fonti e gestire flussi di lavoro più complessi.
Questi sistemi convertono gli LLM in agenti AI, consentendo loro di utilizzare strumenti, funzioni e fonti di conoscenza esterne, creando così un approccio più sofisticato all'elaborazione delle informazioni rispetto alle implementazioni RAG standard.
Funzionalità principali dell'Agentic RAG
Intelligenza multi-fonte: Il sistema può connettersi a più database, inclusi database vettoriali come Milvus e Zilliz Cloud, nonché database SQL tradizionali. Gli agenti possono accedere simultaneamente a documenti interni, API esterne, ricerche web e database specializzati in base ai requisiti della query.
Elaborazione adattiva delle query: Gli agenti AI possono iterare sui processi precedenti per ottimizzare i risultati nel tempo. Quando i risultati iniziali sono insufficienti, gli agenti possono riformulare le query, provare fonti diverse o suddividere domande complesse in sotto-query gestibili.
Pianificazione e orchestrazione intelligenti: Gli agenti in questo approccio possono pianificare e ragionare attraverso attività che richiedono più passaggi e ragionamento logico. Un agente coordinatore può assegnare attività specializzate a diversi agenti di recupero, ciascuno ottimizzato per tipi di dati o domini specifici.
Convalida della qualità: A differenza dei sistemi tradizionali, l'agentic RAG include meccanismi integrati per valutare i contenuti recuperati. Gli agenti AI possono iterare sui processi precedenti per ottimizzare i risultati nel tempo. Questo livello di convalida riduce significativamente le allucinazioni e migliora l'accuratezza delle risposte.
Integrazione degli strumenti: Agenti di recupero con accesso a diversi strumenti di recupero, come: motore di ricerca vettoriale (chiamato anche motore di query) che esegue la ricerca vettoriale su un indice vettoriale (come nelle tipiche pipeline RAG), ricerca web, calcolatrice, qualsiasi API per accedere a software in modo programmatico, come programmi di email o chat, consentono una raccolta completa di informazioni oltre il semplice recupero di documenti.
Come funziona l'Agentic RAG
L'agentic RAG opera attraverso un'architettura sofisticata che combina più agenti AI con capacità di ragionamento avanzate. Ecco come il sistema elabora le query dall'inizio alla fine:
Flusso di lavoro passo passo
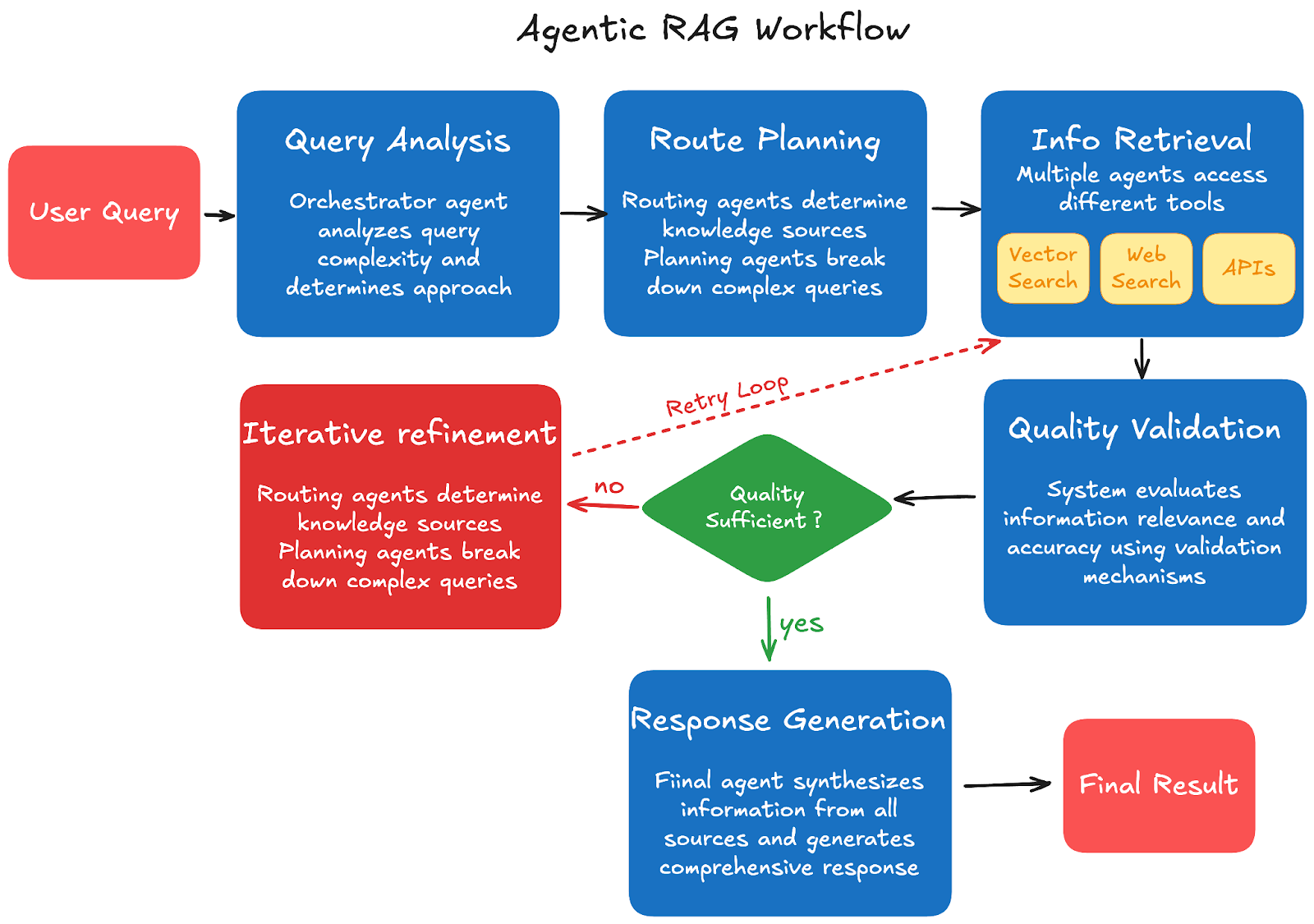
Passaggio 1: Analisi della query: L'utente invia una query all'agente orchestratore principale, che analizza la complessità della query e determina l'approccio richiesto. Il sistema decide se sono necessari uno o più passaggi di recupero in base all'ambito e alla complessità della query.
Passaggio 2: Pianificazione del percorso: Gli agenti di routing determinano quali fonti di conoscenza esterne e strumenti utilizzare, mentre gli agenti di pianificazione delle query scompongono le query complesse in sotto-attività gestibili. Il sistema crea un piano di esecuzione basato sulle risorse disponibili e sul percorso più efficiente per raccogliere informazioni complete.
Passaggio 3: Recupero delle informazioni: Gli agenti di recupero accedono a diversi strumenti in base al piano di esecuzione, inclusi motori di ricerca vettoriale per database documentali, ricerca web per informazioni aggiornate, API per dati di software o servizi specifici e calcolatrici per attività computazionali. Più agenti possono lavorare simultaneamente su diverse fonti per massimizzare efficienza e copertura.
Passaggio 4: Validazione della qualità: Il sistema valuta le informazioni recuperate in termini di pertinenza e accuratezza utilizzando meccanismi di validazione integrati. Se il contenuto è insufficiente o irrilevante, gli agenti riformulano le query e i meccanismi di validazione verificano la coerenza tra più fonti per garantire una qualità affidabile delle informazioni.
Passaggio 5: Perfezionamento iterativo: Il sistema determina se è necessario un ulteriore recupero in base alla qualità e alla completezza delle informazioni raccolte. Gli agenti possono eseguire nuovamente query con termini di ricerca perfezionati, e questo processo si ripete finché non vengono raccolte informazioni di qualità sufficiente per fornire una risposta completa.
Passaggio 6: Generazione della risposta: L’agente finale sintetizza le informazioni provenienti da tutte le fonti in una risposta coerente. Genera risposte complete utilizzando un contesto validato e fornisce citazioni e attribuzione delle fonti quando applicabile per mantenere trasparenza e credibilità.
Tipi di agenti e ruoli
Agenti di routing: Determinano quali fonti di conoscenza esterne e strumenti vengono utilizzati per rispondere alle query degli utenti
Agenti di pianificazione delle query: Elaborano query complesse e le scompongono in processi passo dopo passo
Agenti ReAct: Combinano capacità di ragionamento e azione per l’adattamento dinamico del flusso di lavoro
Agenti Plan-and-Execute: Gestiscono flussi di lavoro multi-step in modo indipendente senza coordinamento costante
 Agentic RAG workflow.png
Agentic RAG workflow.png
Vantaggi e sfide di Agentic RAG
Agentic RAG offre vantaggi significativi rispetto agli approcci tradizionali, introducendo al contempo alcune considerazioni operative.
Vantaggi
Accuratezza migliorata: La validazione multi-fonte e il confronto incrociato riducono significativamente le allucinazioni e migliorano l’affidabilità delle risposte. La capacità del sistema di verificare le informazioni su più basi di conoscenza crea un solido meccanismo di fact-checking che il RAG tradizionale non può eguagliare.
Integrazione multi-fonte: L’accesso a basi di conoscenza, API e strumenti esterni diversificati consente la raccolta completa di informazioni da database strutturati, ricerche web, calcolatrici e software specializzati. Questa versatilità permette al sistema di gestire query complesse che richiedono informazioni da più domini.
Perfezionamento iterativo: Il miglioramento continuo della qualità delle risposte attraverso più cicli di recupero e validazione garantisce che i risultati iniziali subottimali possano essere migliorati. Il sistema apprende da ogni iterazione, riformulando le query e migliorando le strategie di ricerca finché non viene raggiunta una qualità soddisfacente delle informazioni.
Risoluzione adattiva dei problemi: Approccio proattivo alle query complesse con routing intelligente e regolazione dinamica del flusso di lavoro. Il sistema può determinare autonomamente la migliore strategia di recupero, adattarsi a contesti mutevoli e gestire scenari imprevisti senza richiedere intervento manuale o un’estesa prompt engineering.
Sfide
Costi più elevati: Un maggior numero di agenti e processi iterativi richiede maggiori risorse computazionali e utilizzo di token, aumentando potenzialmente le spese operative di 2-3 volte rispetto al RAG tradizionale. L’architettura multi-agente richiede più chiamate API, tempi di elaborazione più lunghi e infrastruttura aggiuntiva per supportare flussi di lavoro complessi.
Latenza aumentata: Molteplici interazioni tra agenti, passaggi di validazione e potenziali cicli di iterazione possono rallentare significativamente i tempi di risposta. Le query complesse possono richiedere diversi cicli di recupero e perfezionamento, rendendo il sistema meno adatto alle applicazioni in tempo reale che richiedono risposte immediate.
Problemi di affidabilità: Gli agenti possono avere difficoltà o non riuscire a completare attività complesse, creando punti di errore nel flusso di lavoro. Il coordinamento tra più agenti può diventare instabile, portando a risposte incomplete, loop infiniti o decisioni contrastanti che richiedono meccanismi sofisticati di gestione degli errori.
Complessità di integrazione: Collegare strumenti diversi, fonti di conoscenza e gestire il coordinamento multi-agente richiede un’orchestrazione sofisticata e test estesi. L’architettura del sistema diventa significativamente più complessa rispetto al RAG tradizionale, richiedendo competenze specialistiche per distribuzione, manutenzione e risoluzione dei problemi.
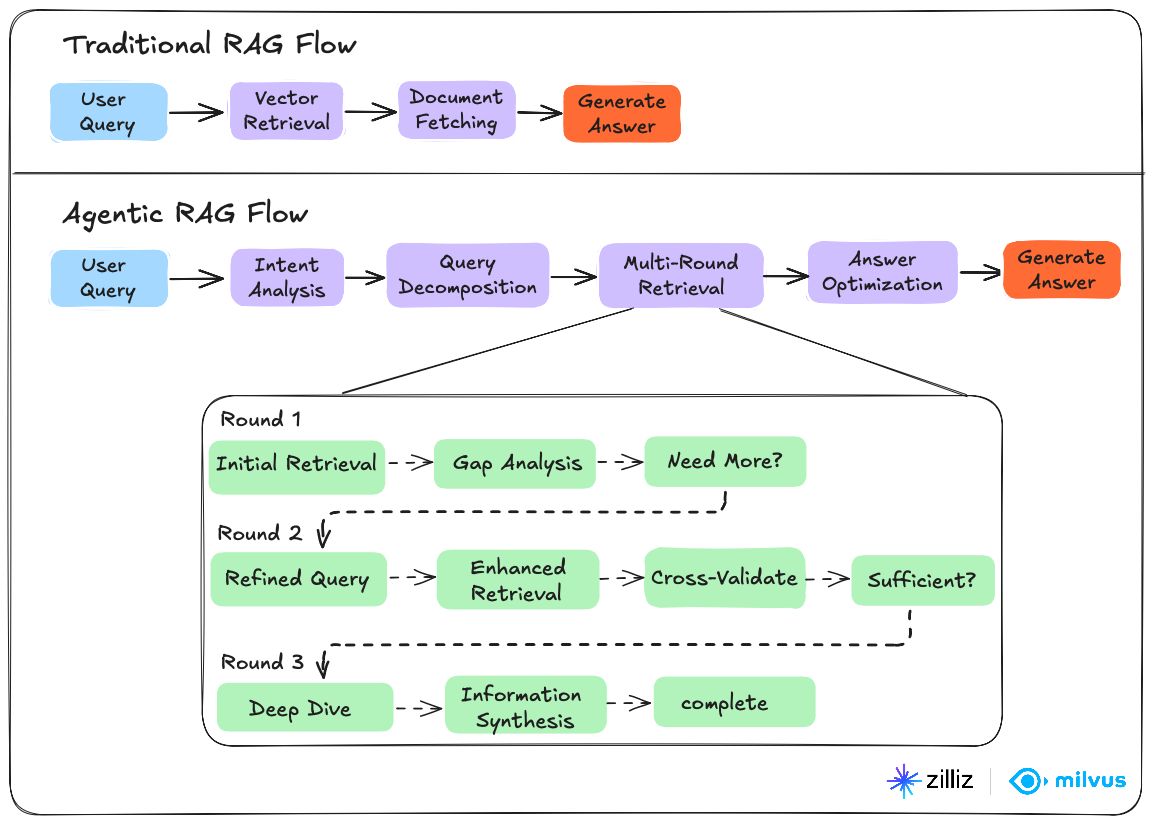
Confronto tra Agentic RAG e RAG tradizionale
 Agentic RAG vs Traditional RAG.jpg
Agentic RAG vs Traditional RAG.jpg
| Funzionalità | RAG tradizionale | Agentic RAG |
|---|---|---|
| Fonti di dati | Singola base di conoscenza | Più fonti e strumenti esterni |
| Elaborazione delle query | Recupero in un solo passaggio | Approccio iterativo, multi-step |
| Validazione | Nessuna validazione integrata | Valutazione automatizzata della qualità |
| Adattabilità | Statica, basata su regole | Decision-making dinamico e intelligente |
| Accesso agli strumenti | Limitato al database vettoriale | API, ricerca web, calcolatrici, servizi esterni |
| Capacità di pianificazione | Semplice recupero-e-generazione | Ragionamento complesso e scomposizione delle attività |
| Gestione degli errori | Richiede intervento manuale | Meccanismi di autocorrezione e nuovo tentativo |
| Scalabilità | Limitata da una singola fonte | Scala con agenti e fonti aggiuntivi |
| Costo | Minore utilizzo di token | Maggiore overhead computazionale |
| Velocità di risposta | Risposta iniziale più rapida | Variabile, a seconda della complessità |
Casi d’uso di Agentic RAG
Gestione della conoscenza aziendale: I sistemi RAG basati su agenti sono eccellenti nell’esaminare e recuperare informazioni da dati aziendali eterogenei. Le aziende possono distribuire sistemi che cercano automaticamente tra documenti interni, database, email e intelligence di mercato esterna per rispondere a domande aziendali complesse.
Automazione dell’assistenza clienti: Le aziende che desiderano ottimizzare i servizi di assistenza clienti possono utilizzare sistemi RAG automatizzati per gestire richieste dei clienti più semplici. Il sistema agentic RAG può inoltrare le richieste di supporto più impegnative al personale umano. Il sistema può accedere a manuali di prodotto, database di FAQ, cronologia dei clienti e informazioni sullo stato in tempo reale per fornire un supporto completo.
Sistemi informativi sanitari: I professionisti medici possono utilizzare agentic RAG per accedere simultaneamente a cartelle cliniche dei pazienti, letteratura medica, database di farmaci e linee guida cliniche, consentendo un processo decisionale più informato mantenendo al contempo la privacy dei dati e gli standard di conformità.
Supporto alle decisioni finanziarie: Più agenti RAG possono eseguire calcoli, trovare informazioni meteorologiche, consigliare tendenze azionarie e di mercato, analizzare dati e altro ancora. Gli analisti finanziari possono interrogare sistemi che combinano dati di portafoglio interni con informazioni di mercato esterne, documenti normativi e indicatori economici.
Domande frequenti
D: Agentic RAG può accedere a più documenti contemporaneamente?
A: Un agente RAG può accedere, recuperare e confrontare dati in più documenti forniti. Il sistema eccelle nella sintesi di informazioni da fonti diverse in un'unica risposta.
D: In che modo agentic RAG differisce da RAG standard?
R: Un RAG classico può recuperare informazioni da una singola fonte, mentre un agentic RAG utilizza più agenti per accedere ai dati da fonti diverse e orchestrarli. Il RAG tradizionale è reattivo, mentre l'agentic RAG è proattivo e intelligente.
D: Quali framework possono essere utilizzati per creare applicazioni agentic RAG?
R: Sono disponibili diversi framework Python con componenti e strumenti pronti all'uso per l'analisi e il monitoraggio degli agenti RAG. Questi framework includono Phidata, LangGraph, Swarm, Microsoft Autogen, ecc.
D: Agentic RAG è sempre migliore del RAG tradizionale?
R: Non necessariamente. Sebbene l'agentic RAG ottimizzi i risultati con chiamate di funzione, ragionamento multistep e sistemi multiagente, non è sempre la scelta migliore. Per query semplici, con un'unica fonte, il RAG tradizionale può essere più efficiente e conveniente.
D: Agentic RAG può funzionare con diversi tipi di dati?
R: Sì, i moderni sistemi agentic RAG supportano l'elaborazione multimodale, gestendo testo, immagini, audio e altri formati di dati strutturati e non strutturati.
- Cos'è l'Agentic RAG?
- Funzionalità principali dell'Agentic RAG
- Come funziona l'Agentic RAG
- Vantaggi e sfide di Agentic RAG
- Confronto tra Agentic RAG e RAG tradizionale
- Casi d’uso di Agentic RAG
- Domande frequenti
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente