




Exa crea un motore di ricerca di entità per agenti IA con Zilliz Cloud
<200ms di latenza di ricerca
La latenza della ricerca neurale di Exa è stata ridotta da secondi a meno di 200 ms con la ricerca ibrida di Zilliz
Elevata affidabilità
Incidenti operativi quasi azzerati, liberando tempo di engineering per il lavoro sul prodotto
Zero downtime per le modifiche allo schema
È possibile aggiungere nuovi campi filtrabili e metadati senza ricostruire gli indici o mettere offline le raccolte
We believe AI agents will become a fundamental interface for how people work, learn, and make decisions, and that only happens if those systems can access real-world information with speed, precision, and trust. That’s what we’re building at Exa. Aside from web search, Exa also operates entity search, and Zilliz Cloud has been an important part of that journey, giving us the retrieval performance and operational simplicity we need to scale our entity search product quickly and confidently.
Jeffrey Wang
La ricerca per agenti di IA sembra un’estensione naturale della ricerca web, ma in pratica richiede uno standard di prodotto diverso. Gli agenti non hanno solo bisogno di link; hanno bisogno di informazioni fondate, aggiornate e strutturate, fornite abbastanza rapidamente da supportare flussi di lavoro reali, dalle interazioni vocali alle attività di ricerca approfondita.
Exa sta costruendo esattamente questo tipo di motore di ricerca per l’IA. La sua Search API offre agli sviluppatori accesso a una ricerca web di alta qualità e a bassa latenza su un’ampia gamma di compute-latency, dalla ricerca istantanea per agenti vocali alla ricerca più approfondita con output strutturati e arricchimenti. Exa serve clienti che vanno da startup AI-native come Cursor e Lovable a imprese enterprise come AWS, tutte accomunate dalla necessità di un contesto concreto e reale per flussi di lavoro guidati da agenti.
Man mano che Exa si espande nella ricerca di entità per aziende, persone e codice, ha dovuto affrontare una sfida infrastrutturale più specializzata: come supportare il recupero ibrido, un ricco filtraggio dei metadati, aggiornamenti frequenti e una latenza a livello di millisecondi senza distogliere l’attenzione ingegneristica dal motore di ricerca principale. Questo è il ruolo specifico che Zilliz Cloud (Milvus completamente gestito) svolge nella storia seguente.
| 200ms Bassa latenza di ricerca | Ricerca ibrida che combina vettori densi, vettori sparsi, reranking RRF e filtri sui metadati in una singola chiamata API. Exa Instant ha ridotto la latenza della ricerca neurale da secondi a meno di 200ms |
| Alta affidabilità | Il servizio gestito ha fornito incidenti operativi prossimi allo zero, liberando tempo ingegneristico per il lavoro sul prodotto |
| Zero downtime per modifiche allo schema | Nuovi campi filtrabili e metadati possono essere aggiunti senza ricostruire gli indici o portare offline le collection |
Di seguito è riportato lo script di una conversazione con Exa sulla sua missione di prodotto, sul passaggio dalla ricerca web generale alla ricerca di entità e su come Zilliz Cloud si inserisce in questa evoluzione.
1. La promessa di prodotto di Exa: ricerca fondata per agenti di IA
Abbiamo iniziato chiedendo a Exa di descrivere il prodotto che sta costruendo e i clienti che serve, perché questo contesto spiega perché la qualità del recupero e la latenza non siano aspetti secondari per l’azienda.
Q: Quale prodotto o servizio offre Exa e chi sono i vostri clienti principali?
Exa: Exa sta costruendo il motore di ricerca per l’IA. Abbiamo creato una search API che consente agli sviluppatori di accedere a una ricerca web di alta qualità e a bassa latenza attraverso i loro agenti. La nostra API offre ricerca lungo tutto lo spettro della compute latency, dalle ricerche istantanee (<200ms) per agenti vocali alla deep research con output strutturati e arricchimenti. Siamo specializzati in code search, bassa latenza e ricerca di persone/aziende, con highlight che garantiscono efficienza dei token.
Abbiamo costruito il nostro motore di ricerca da zero utilizzando nuove architetture neurali, invece di affidarci a motori di ricerca legacy. Costruire il proprio motore di ricerca richiede tutto, dall’addestramento di modelli di embedding e reranker al crawling e all’indicizzazione di miliardi di pagine web. Questa proprietà end-to-end ci consente di ottimizzare ogni livello dello stack per qualità e velocità. Nel recente lancio di Exa Instant, per esempio, abbiamo raggiunto una latenza di ricerca <200ms: un miglioramento significativo che rende la ricerca neurale utilizzabile come primitiva in tempo reale per agenti di IA. La combinazione di qualità, velocità e personalizzabilità è un elemento differenziante chiave.
I nostri clienti vanno da aziende AI-native come Cursor e Lovable a grandi imprese. Qualsiasi azienda che utilizzi agenti per guidare il lavoro della conoscenza ha bisogno di un contesto fondato per rispondere al mondo reale, quindi, indipendentemente dalle dimensioni dell’azienda, lavoriamo con team che danno priorità ai flussi di lavoro guidati da agenti.
2. Il punto di svolta: dalla ricerca web alla ricerca di entità
Questo contesto di prodotto chiarisce anche perché la decisione di Exa sul database non riguardasse la sostituzione del suo stack di ricerca principale. La ricerca vettoriale era già fondamentale per l’azienda. Il vero cambiamento è arrivato quando la ricerca di entità ha introdotto nuovi vincoli.
D: In quale momento del vostro percorso di prodotto vi siete resi conto di aver bisogno di un database vettoriale?
Exa: Dato che il nostro motore di ricerca è stato costruito su embedding e similarità vettoriale, la ricerca vettoriale è stata una parte integrante dello stack tecnologico di Exa. Con la nostra espansione nella ricerca di entità, abbiamo dovuto aggiornare la nostra infrastruttura di database vettoriale per supportare gli output strutturati e gli arricchimenti che ora offrivamo.
La ricerca di entità richiede schemi di metadati ricchi, aggiornamenti frequenti dei dati e scalabilità gestita. Il nostro database interno era ottimizzato per questi vincoli aggiornati, ma volevamo migliorare ulteriormente la velocità di iterazione su questo livello di ricerca di entità, il che ci ha spinto a utilizzare Zilliz Cloud. Il nostro indice web principale rimane sulla nostra infrastruttura interna, e Zilliz Cloud è stato introdotto specificamente per alimentare questo livello di ricerca di entità.
D: Quali sfide o requisiti avete affrontato con la vostra soluzione precedente?
Exa: Quando abbiamo iniziato a costruire la ricerca di entità, i requisiti erano molto diversi: ricerca ibrida che combina vettori densi e sparsi, schemi di metadati ricchi e in frequente cambiamento, e il sovraccarico operativo legato alla gestione di più raccolte specializzate. Cercavamo una soluzione gestita che consentisse ai nostri ingegneri di iterare rapidamente e supportare risposte veloci su larga scala.
D: Quali casi d’uso specifici state risolvendo con la ricerca vettoriale/database vettoriale?
Exa: Oggi, Zilliz Cloud alimenta il nostro livello di ricerca di entità, fungendo sia da indice primario sia da cache di aggiornamento per le raccolte di entità, mentre il nostro indice web principale gira su un’infrastruttura interna separata. Ogni verticale richiede una ricerca filtrata a bassa latenza su dati aggiornati frequentemente, in cui le capacità gestite di retrieval ibrido e hot-upsert di Zilliz mantengono i risultati aggiornati senza ricostruire gli indici. Queste verticali alimentano direttamente la nostra Search API, quindi velocità e recall sono critici per il business.
3. Che cosa serviva a Exa da un livello gestito di retrieval vettoriale
Una volta che la ricerca di entità è diventata un livello distinto, la valutazione riguardava davvero l’adeguatezza: un sistema gestito poteva supportare lo standard di qualità di ricerca di Exa senza rallentare il team o imporre compromessi architetturali?
D: Quali database vettoriali avete valutato prima di scegliere Zilliz Cloud? Quali erano i criteri chiave nella vostra valutazione?
Exa: Quando abbiamo iniziato a costruire la ricerca di entità, i requisiti erano molto diversi: ricerca ibrida che combina vettori densi e sparsi, schemi di metadati ricchi e in frequente cambiamento, e il sovraccarico operativo legato alla gestione di più raccolte specializzate. Cercavamo una soluzione gestita che consentisse ai nostri ingegneri di iterare rapidamente e supportare risposte veloci su larga scala.
Abbiamo esaminato tutte le principali opzioni di database vettoriali disponibili sul mercato. I nostri criteri chiave erano:
Supporto alla ricerca ibrida: capacità nativa di combinare vettori semantici densi con vettori sparsi di parole chiave in una singola query, con reranking integrato
Latenza delle query: risposte costantemente rapide su raccolte con decine di milioni di vettori
Filtraggio avanzato dei metadati: filtri complessi su campi strutturati senza degradare le prestazioni di ricerca
Scalabilità: scalabilità fluida man mano che aggiungiamo nuove verticali e fonti di dati
Zilliz Cloud soddisfaceva ogni requisito, e le sue prestazioni nei benchmark di ricerca ibrida erano chiaramente superiori alla concorrenza.
D: Come avete sentito parlare per la prima volta di Zilliz Cloud / Milvus?
Exa: Conoscevamo Milvus da molto tempo, poiché è uno dei database vettoriali open-source più maturi, e per un team che vive e respira ricerca vettoriale è difficile non notarlo. Quando abbiamo iniziato a definire la nostra infrastruttura di ricerca di entità, Zilliz Cloud si è distinto come la naturale offerta gestita basata su Milvus, con miglioramenti delle prestazioni di livello enterprise.
D: Che cosa vi ha colpito di Zilliz Cloud durante la valutazione? Quali sono state le ragioni principali che vi hanno portato a scegliere Zilliz Cloud?
Exa: Alcuni aspetti si sono distinti subito.
Ricerca ibrida nativa: Zilliz Cloud supporta la ricerca vettoriale densa e sparsa in un’unica chiamata API, con strategie di reranking integrate (RRF, ponderata). Questo era un requisito imprescindibile per diversi concorrenti, e noi non lo supportavamo nativamente.
Prestazioni su larga scala: il loro motore di indicizzazione Cardinal offre tempi di query costantemente rapidi anche quando le nostre collection crescono fino a centinaia di milioni di vettori.
Filtri maturi: la capacità di combinare la ricerca vettoriale con filtri di metadati complessi in un’unica richiesta, senza un calo significativo delle prestazioni.
In termini di fattori decisivi per l’adozione:
Velocità: la latenza delle query di Zilliz Cloud ha soddisfatto i nostri requisiti stringenti per la ricerca in produzione. I nostri utenti si aspettano risultati in millisecondi, e Zilliz è in grado di supportarlo.
Funzionalità di ricerca ibrida: la capacità di fondere la ricerca semantica densa con il matching di parole chiave sparse BM25 e applicare il reranking Reciprocal Rank Fusion (RRF) in un’unica chiamata API è stata importante per la qualità della ricerca.
Semplicità operativa: in quanto servizio completamente gestito, Zilliz Cloud consente al nostro team di concentrarsi sulla creazione di esperienze di ricerca migliori e di iterare rapidamente sui miglioramenti all’infrastruttura di database vettoriali su larga scala.
4. Come l’architettura di Zilliz ed Exa si integra
Q: In che modo Zilliz Cloud si inserisce nella vostra architettura?
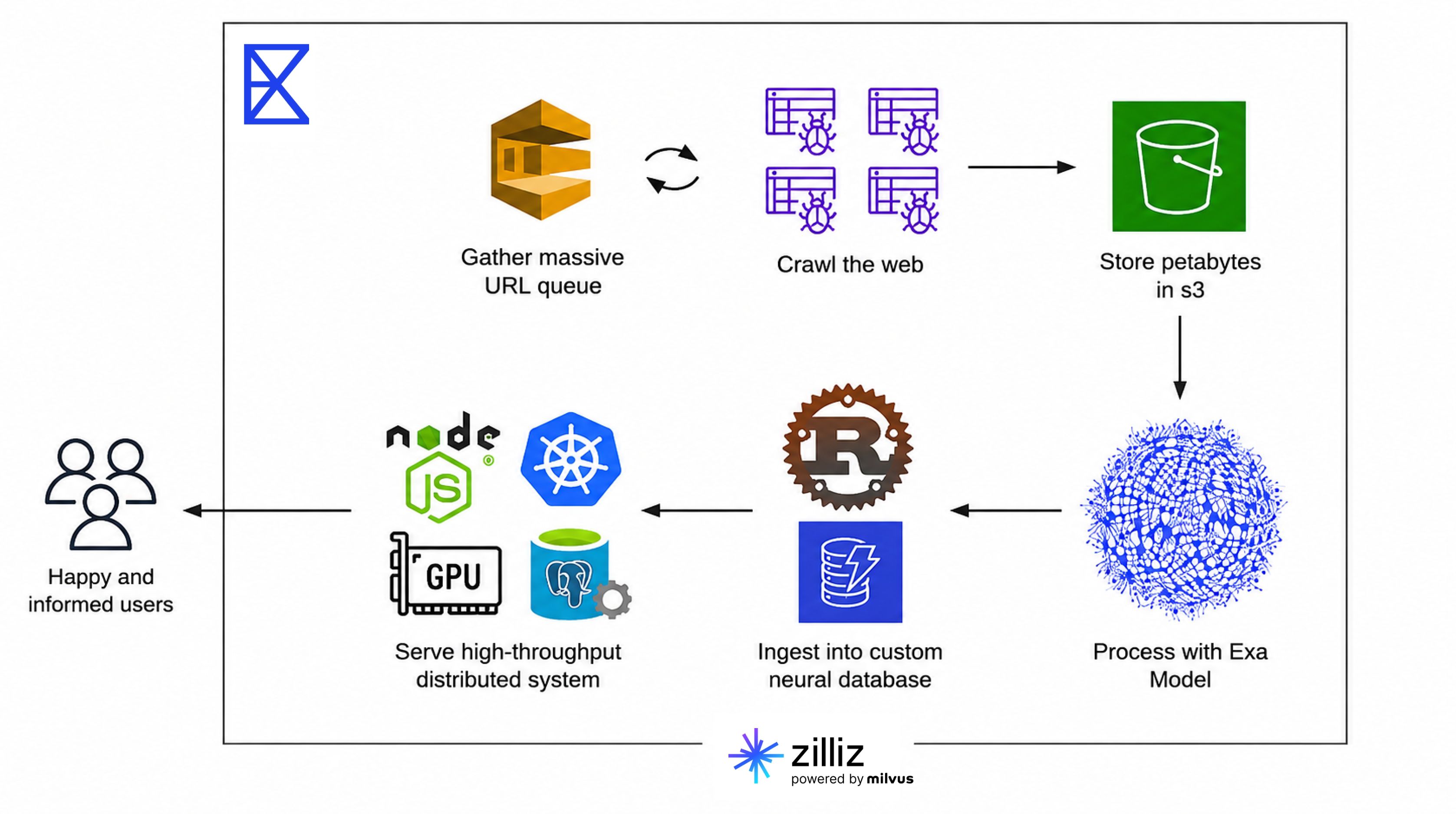
Exa: La nostra architettura di ricerca delle entità comprende tre livelli: ingestione, ricerca e API.
Nell’ingestione, arricchiamo e trasformiamo in embedding i dati delle entità utilizzando le nostre pipeline ML, quindi eseguiamo l’upsert di vettori densi e sparsi in Zilliz Cloud.
Nella ricerca, il nostro backend genera embedding dalle query degli utenti e invia richieste di ricerca ibrida a Zilliz Cloud, combinando matching semantico e per parole chiave con reranking RRF.
Nel livello API, i risultati vengono arricchiti con metadati strutturati e forniti tramite la nostra Search API e il prodotto Websets. Zilliz Cloud si trova al centro del retrieval per questo workflow: archivia tutti i vettori e i metadati delle entità e gestisce la ricerca a bassa latenza. Il nostro indice web primario è creato e gestito su un’infrastruttura interna separata.
Q: Com’è stata l’esperienza del vostro team nell’utilizzo di Zilliz Cloud o Milvus?
Exa: L’API è intuitiva, la documentazione è solida e il sistema è stato affidabile in produzione. La curva di apprendimento è stata minima perché i concetti di Milvus: collection, indici, parametri di ricerca, si adattano bene al modo in cui già pensiamo alla ricerca vettoriale. La natura gestita di Zilliz Cloud significa che abbiamo avuto pochissimi incidenti operativi da gestire.
Q: Com’è stata l’esperienza di integrazione di Zilliz Cloud con AWS o altri servizi cloud?
Exa: Fluida. Eseguiamo la nostra infrastruttura principalmente su AWS, e Zilliz Cloud si integra in modo pulito in quello stack nativo AWS. Poiché viene eseguito su AWS, la latenza di rete tra i nostri servizi EKS e Zilliz Cloud è minima.
5. Cosa è cambiato dopo l’adozione
Q: Quali sono i 3 principali vantaggi che avete riscontrato? Potete condividere metriche o miglioramenti misurabili?
Exa: Il primo vantaggio è stato la velocità degli sviluppatori: il servizio gestito e l’API pulita hanno permesso al nostro team di rilasciare rapidamente nuove verticali di ricerca entità senza creare o gestire infrastrutture aggiuntive.
Oltre a questo, la flessibilità e l’adattabilità dello schema sono state molto importanti man mano che questi dataset verticali evolvono, e anche la qualità della ricerca tramite autoindex si è rivelata preziosa nella pratica.
Q: Quali funzionalità di Zilliz Cloud trovate più preziose?
Exa: Due aspetti si distinguono maggiormente nell’uso quotidiano.
Filtraggio senza cali di prestazioni: Filtri di metadati complessi sovrapposti alla ricerca vettoriale con un impatto trascurabile sulla latenza.
Lanci rapidi di verticali: La scalabilità gestita ci consente di rilasciare rapidamente nuove verticali di ricerca senza dover predisporre ogni volta una nuova infrastruttura.
Inizia con Zilliz Cloud
Zilliz è il creatore di Milvus, il database vettoriale open-source più popolare al mondo, e di Zilliz Cloud, il servizio di database vettoriale completamente gestito basato su Milvus. Zilliz Cloud consente alle organizzazioni di creare applicazioni di IA pronte per la produzione con ricerca vettoriale ad alte prestazioni, recupero ibrido e sicurezza e conformità di livello enterprise.
- Inizia gratuitamente con Zilliz Cloud con $100 di crediti al momento della registrazione con un’email aziendale
- 1. La promessa di prodotto di Exa: ricerca fondata per agenti di IA
- 2. Il punto di svolta: dalla ricerca web alla ricerca di entità
- 3. Che cosa serviva a Exa da un livello gestito di retrieval vettoriale
- 4. Come l’architettura di Zilliz ed Exa si integra
- 5. Cosa è cambiato dopo l’adozione
- Inizia con Zilliz Cloud
Contenuto
Caso d'Uso
Settore
Infrastruttura AI