




Come Biomap trasforma la scoperta nelle scienze della vita su larga scala con la ricerca vettoriale basata sull'IA usando Milvus
22× più veloce
Ricerche di proteine con tempi di query ridotti da 10–20 minuti a meno di un minuto.
50 mld+
Sequence Scale è passato da centinaia di milioni a decine di miliardi di sequenze biologiche.
Scoperta in tempo reale
Risposte in meno di un secondo per query biologiche complesse nei flussi di lavoro RAG.
Integrazione cross-modale
Ha unificato proteine, DNA, RNA, testo e dati cellulari in un unico framework ricercabile.
Milvus has become the bridge that connects our multi-modal foundation models with real-world applications. It's not just about performance – it's about enabling entirely new approaches to biological discovery that were previously impossible.
Xiaoming Zhang
Informazioni su Biomap
Biomap è un'azienda leader nell'IA per le scienze della vita, focalizzata sulla creazione di modelli di IA che accelerano la scoperta nello sviluppo di farmaci, nella biologia sintetica e nella ricerca medica. Al centro della sua piattaforma c'è xTrimo, una famiglia di modelli fondazionali su larga scala progettati specificamente per la biologia. Scalando fino a 210 miliardi di parametri, xTrimo unifica proteine, DNA, RNA, cellule, molecole e testo scientifico in un unico framework, fornendo previsioni e insight che i metodi tradizionali non possono eguagliare.
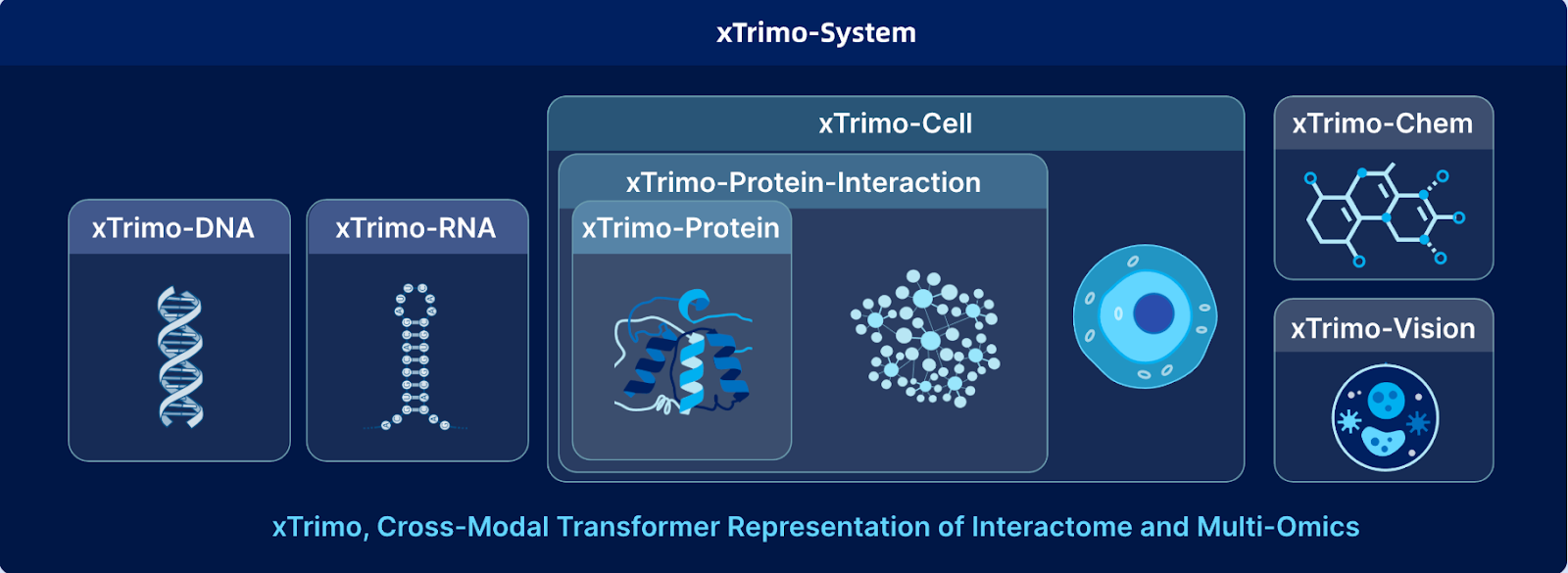
Raggiungere questa capacità ha richiesto il superamento di barriere tecniche, tra cui dati biologici rumorosi, formati estremamente diversi e la necessità di effettuare ricerche in tempo reale su miliardi di sequenze. Biomap ha affrontato queste sfide sviluppando modelli di embedding personalizzati per entità biologiche e implementando infrastrutture dati avanzate, come Milvus Vector Database, per consentire un recupero rapido e accurato su larga scala. Con questa base, i ricercatori possono ora accelerare scoperte rivoluzionarie in vari campi, tra cui immunologia, neurologia, oncologia e trattamento delle malattie rare.
Barriere tecniche alla scalabilità dell'IA biologica
Man mano che Biomap ampliava le sue capacità di IA, il team si è imbattuto in diversi colli di bottiglia che gli strumenti tradizionali non potevano superare.
1. Ricerca lenta delle proteine
La pipeline di previsione della struttura delle proteine di Biomap in precedenza si basava sull'Allineamento di Sequenze Multiple (MSA), che richiedeva 10–20 minuti per restituire un singolo risultato. Sebbene accettabile per la ricerca su piccola scala, questo ritardo era impraticabile per i carichi di lavoro di produzione, soprattutto quando si scalava a centinaia di milioni—o persino miliardi—di sequenze.
2. Complessità dei dati multimodali
I dati biologici si presentano intrinsecamente in molte forme—proteine, DNA, RNA, imaging cellulare e persino testo. I metodi di ricerca tradizionali non erano in grado di collegare efficacemente queste modalità, perdendo così il tipo di insight cross-modali che sono cruciali per comprendere sistemi biologici complessi.
3. Dilemma tra velocità e accuratezza
Nella ricerca biomedica, errori minori possono avere conseguenze importanti. L'assistente di scoperta basato su RAG di Biomap aveva bisogno sia di risposte alle query in meno di un secondo per l'interattività, sia di accuratezza di livello scientifico per l'affidabilità della ricerca. Tuttavia, la maggior parte delle soluzioni imponeva un compromesso tra velocità e precisione.
4. Requisiti dei dati specializzati
I dati biologici hanno caratteristiche uniche che richiedono strategie di indicizzazione personalizzate, modelli di embedding specifici del dominio e ottimizzazione calibrata per carichi di lavoro scientifici—capacità che le soluzioni pronte all'uso non potevano fornire.
5. Esigenze prestazionali diverse
I diversi casi d'uso di Biomap avevano esigenze molto differenti: gli assistenti conversazionali richiedevano risposte istantanee, la previsione delle proteine poteva tollerare minuti per query ma richiedeva un'elaborazione batch efficiente, e l'addestramento di modelli fondazionali richiedeva pipeline di dati ad alta produttività. Gestire questi requisiti eterogenei all'interno di un'unica infrastruttura unificata si è rivelato particolarmente impegnativo.
Perché Biomap ha scelto Milvus per alimentare l'IA biologica su larga scala
Biomap ha capito rapidamente che scalare i suoi carichi di lavoro di IA avrebbe richiesto una piattaforma di ricerca vettoriale progettata appositamente. Il team si è inizialmente rivolto a Faiss, una popolare libreria di ricerca vettoriale, per prove di concetto su piccola scala. Sebbene Faiss abbia ottenuto buoni risultati nei primi esperimenti, ha fallito quando è stato messo alla prova con carichi di lavoro di produzione, non riuscendo a soddisfare i requisiti di scala, affidabilità e flessibilità delle applicazioni reali nelle scienze della vita. Dopo aver testato diverse alternative, il team ha scoperto che Milvus era l'unica soluzione che soddisfaceva ogni requisito grazie ai seguenti fattori:
Flessibilità Open Source: I dati delle scienze della vita sono altamente specializzati e spesso richiedono indicizzazione e algoritmi personalizzati, adattati ai casi d’uso biologici. Il design open-source di Milvus ha dato a Biomap la libertà di adattare ed estendere il sistema senza vincoli. Come ha spiegato Xiaoming Zhang, VP of Technology di Biomap, “Se non è open source, probabilmente non c’è spazio per tali personalizzazioni, il che non si adatta ai nostri scenari.”
Stabilità Pronta per la Produzione: Per le implementazioni in produzione, Biomap aveva bisogno di una piattaforma matura, supportata da una base utenti attiva, in particolare tra le aziende biotech enterprise. Con una comprovata esperienza in diversi settori e una forte adozione da parte della community tra le aziende biotech, Milvus offriva l’affidabilità e il supporto dell’ecosistema richiesti da Biomap.
Set di Funzionalità Completo: Milvus supporta un’ampia gamma di tipi di indice e funzionalità di ricerca ibrida, consentendo l’ottimizzazione delle ricerche su proteine, DNA, RNA, testo e altre modalità, il tutto all’interno di un unico sistema.
Prestazioni su Larga Scala: Dagli assistenti interattivi alle ricerche proteiche su larga scala, Biomap aveva bisogno di un’infrastruttura in grado di gestire sia query in meno di un secondo sia enormi job batch. L’architettura scalabile orizzontalmente di Milvus ha garantito prestazioni costanti tra i diversi workload, indipendentemente dalle loro dimensioni e scala.
Community e Partnership: Il team di Biomap ha inoltre apprezzato la community open-source attiva di Milvus e il potenziale di partnership a lungo termine con Zilliz, l’azienda dietro Milvus.
Questa combinazione di profondità tecnica, maturità dell’ecosistema e supporto orientato al futuro ha reso Milvus la scelta evidente per l’infrastruttura di produzione di Biomap.
Come Biomap utilizza Milvus per alimentare i suoi servizi di IA biologica
Biomap ha implementato Milvus in tre casi d’uso critici, ciascuno dei quali affronta una sfida scientifica unica e, insieme, costituiscono la spina dorsale della loro piattaforma di IA biologica.
AI Discovery Assistant (RAG)
Al centro dei workflow di ricerca di Biomap c’è un assistente di discovery basato su Retrieval-Augmented Generation (RAG) avanzata. Costruito su LangGraph per l’orchestrazione, l’assistente estrae dati da vaste raccolte di letteratura scientifica, brevetti e database biologici specializzati. Tali dati, ricchi di formule, strutture proteiche e notazione specifica del dominio, vengono quindi convertiti in embedding vettoriali e archiviati in Milvus.
Milvus esegue ricerca vettoriale ibrida e full-text per fornire i risultati più accurati per le query in meno di un secondo. Ciò consente ai ricercatori di effettuare ricerche nella conoscenza biologica specializzata e ricevere risposte precise in tempo reale, invece di passare ore a scandagliare la letteratura.
Predizione della Struttura Proteica su Larga Scala
Biomap ha anche reinventato la pipeline tradizionale di ricerca proteica sostituendo i lenti metodi di Multiple Sequence Alignment (MSA) con la ricerca vettoriale. I loro modelli fondazionali proteici proprietari generano embedding ad alta dimensionalità, che vengono archiviati e interrogati in Milvus. Questa nuova architettura ha ampliato la scala di ricerca da centinaia di milioni a oltre 5 miliardi di sequenze proteiche, consentendo scoperte che in precedenza erano fuori portata. Anche le prestazioni sono migliorate drasticamente: query che un tempo richiedevano 10–20 minuti ora vengono completate in meno di un minuto, con maggiore accuratezza grazie a metriche di similarità guidate dall’IA.
Generazione di Campioni Cross-Modale per l’Addestramento dei Modelli
Per far progredire lo sviluppo di modelli fondazionali multi-modali, Biomap si affida a Milvus per collegare i dati tra modalità biologiche. I ricercatori possono, ad esempio, recuperare immagini cellulari collegate a specifiche sequenze proteiche o allineare dati a livello molecolare e a livello cellulare in uno spazio vettoriale unificato. Questa capacità supporta una sofisticata data augmentation e la scoperta di associazioni cross-modali, accelerando l’addestramento di modelli che collegano dati testuali, sequenziali e di immagine.
Nel loro insieme, queste applicazioni mostrano come Milvus consenta a Biomap di combinare scalabilità, accuratezza e velocità in diversi ambiti: dalla scoperta quotidiana all’addestramento di modelli biologici all’avanguardia.
Impatto di Milvus sulla piattaforma di Biomap
Adottando Milvus, Biomap ha ottenuto risultati che l’infrastruttura tradizionale non poteva offrire, trasformando sia la velocità sia la portata della propria ricerca.
Ricerche più rapide su scala miliardaria
Il motore di indicizzazione ad alte prestazioni di Milvus ha alimentato un’accelerazione di 22× nelle ricerche di sequenze proteiche. Le query che un tempo richiedevano 10–20 minuti ora restituiscono risultati in meno di un minuto, anche su scale di 50 miliardi di sequenze. Questo rappresenta un aumento di scala di oltre 10 volte—da centinaia di milioni a decine di miliardi di sequenze biologiche—senza sacrificare accuratezza o affidabilità.
Scoperta biologica più intelligente
Milvus ha anche cambiato il modo in cui Biomap affronta la scoperta stessa. Poiché la qualità della ricerca è direttamente legata alle prestazioni dei loro modelli fondazionali, i miglioramenti nell’accuratezza del modello si traducono immediatamente in risultati di recupero migliori. Questo crea un circolo virtuoso: man mano che i modelli evolvono, il motore di ricerca alimentato da Milvus diventa più preciso, sbloccando intuizioni scientifiche che i metodi statici basati sull’allineamento non potrebbero mai raggiungere.
Progressi cross-modali
Con Milvus, Biomap può ora collegare dati a livello molecolare e cellulare all’interno dello stesso spazio vettoriale. Questo “appiattimento” delle differenze di scala consente ricerche cross-modali fluide, supportando l’addestramento dei loro modelli fondazionali multimodali di nuova generazione. È un passo fondamentale verso la loro visione a lungo termine di costruire un simulatore AI completo per la biologia.
Una piattaforma scalabile per le scienze della vita
In definitiva, Milvus fornisce a Biomap l’infrastruttura per espandersi oltre la ricerca interna verso applicazioni più ampie nelle scienze della vita. La stessa piattaforma ora supporta basi di conoscenza personalizzate e agenti intelligenti per aziende farmaceutiche, ospedali e società di biologia sintetica—estendendo i benefici di un’AI biologica rapida e scalabile a tutto l’ecosistema.
Guardando al futuro
Il successo di Biomap con Milvus ha posto le basi per l’espansione in tutto l’ecosistema delle scienze della vita. Il team sta ora ampliando la propria piattaforma per servire una gamma di stakeholder, tra cui aziende farmaceutiche che accelerano la scoperta di farmaci, istituzioni mediche che promuovono la ricerca clinica, società di biologia sintetica che ottimizzano la progettazione degli organismi e aziende di biotecnologie agricole che guidano i miglioramenti genetici nelle colture. Ogni nuovo caso d’uso si basa sulla stessa infrastruttura centrale—la ricerca vettoriale con Milvus—che rende i dati biologici complessi accessibili e utilizzabili su larga scala.
Come ha osservato Xiaoming, “Milvus è diventata l’unica scelta tecnica per i database vettoriali nella nostra prossima espansione commerciale nel settore delle scienze della vita.”
Questa partnership va oltre l’integrazione tecnica. Sta creando una base per il modo in cui la scoperta biologica sarà condotta in futuro: più rapida, più precisa e capace di attraversare modalità che un tempo erano isolate. Mentre Biomap continua a perseguire la sua visione di un “simulatore AI per la vita,” Zilliz fornisce l’infrastruttura di database vettoriale che trasforma questa ambizione in realtà, consentendo progressi che potrebbero trasformare sia la scienza sia l’industria.
- Informazioni su Biomap
- Barriere tecniche alla scalabilità dell'IA biologica
- Perché Biomap ha scelto Milvus per alimentare l'IA biologica su larga scala
- Come Biomap utilizza Milvus per alimentare i suoi servizi di IA biologica
- Impatto di Milvus sulla piattaforma di Biomap
- Guardando al futuro
Contenuto
Settore
Scienze della vita
Milvus has become the only technical choice for vector databases in our upcoming business expansion across the life sciences industry.
Xiaoming Zhang