




Come Airtable ha costruito e scalato l’infrastruttura vettoriale con Milvus

Query a bassa latenza
prestazioni prevedibili sono fondamentali per la fiducia degli utenti
Scritture ad alta velocità
le basi cambiano costantemente e gli embedding devono rimanere sincronizzati
Scalabilità orizzontale
il sistema deve supportare milioni di basi indipendenti
Questo post è stato originariamente pubblicato sul canale Airtable Medium ed è ripubblicato qui con autorizzazione.
Man mano che la ricerca semantica in Airtable si è evoluta da concetto a funzionalità di prodotto fondamentale, il team Data Infrastructure ha affrontato la sfida di scalarla. Come descritto nel nostro post precedente sulla creazione dell’Embedding System, avevamo già progettato un livello applicativo robusto ed eventualmente consistente per gestire il ciclo di vita degli embedding. Ma nel nostro diagramma dell’architettura mancava ancora un elemento critico: il database vettoriale stesso.
Avevamo bisogno di un motore di archiviazione capace di indicizzare e servire miliardi di embedding, supportare una multi-tenancy massiva e mantenere obiettivi di prestazioni e disponibilità in un ambiente cloud distribuito. Questa è la storia di come abbiamo progettato, rafforzato ed evoluto la nostra piattaforma di ricerca vettoriale fino a farla diventare un pilastro fondamentale dello stack infrastrutturale di Airtable.
Contesto
In Airtable, il nostro obiettivo è aiutare i clienti a lavorare con i propri dati in modi potenti e intuitivi. Con l’emergere di LLM sempre più potenti e accurati, le funzionalità che sfruttano il significato semantico dei tuoi dati sono diventate centrali per il nostro prodotto.
Come usiamo la ricerca semantica
Omni (la chat AI di Airtable) risponde a domande reali da grandi dataset
Immagina di porre una domanda in linguaggio naturale alla tua base (database) con mezzo milione di righe e di ottenere una risposta corretta e ricca di contesto. Per esempio:
“Cosa stanno dicendo ultimamente i clienti sulla durata della batteria?”
Su dataset piccoli, è possibile inviare tutte le righe direttamente a un LLM. Su larga scala, questo diventa rapidamente impraticabile. Avevamo invece bisogno di un sistema capace di:
- Comprendere l’intento semantico di una query
- Recuperare le righe più rilevanti tramite ricerca per similarità vettoriale
- Fornire quelle righe come contesto a un LLM
Questo requisito ha plasmato quasi ogni decisione progettuale successiva: Omni doveva risultare istantaneo e intelligente, anche su basi molto grandi.
Raccomandazioni di record collegati: significato invece di corrispondenze esatte
La ricerca semantica migliora anche una funzionalità centrale di Airtable: i record collegati. Gli utenti hanno bisogno di suggerimenti di relazione basati sul contesto anziché su corrispondenze testuali esatte. Per esempio, la descrizione di un progetto potrebbe implicare una relazione con “Team Infrastructure” senza mai usare quella frase specifica.
Fornire questi suggerimenti on-demand richiede un recupero semantico di alta qualità con latenza coerente e prevedibile.
Le nostre priorità progettuali
Per supportare queste funzionalità e altro ancora, abbiamo ancorato il sistema attorno a 4 obiettivi:
- Query a bassa latenza (500ms p99): prestazioni prevedibili sono fondamentali per la fiducia degli utenti
- Scritture ad alto throughput: le basi cambiano costantemente e gli embedding devono rimanere sincronizzati
- Scalabilità orizzontale: il sistema deve supportare milioni di basi indipendenti
- Self-hosting: tutti i dati dei clienti devono rimanere all’interno dell’infrastruttura controllata da Airtable
Questi obiettivi hanno plasmato ogni decisione architetturale successiva.
Valutazione dei fornitori di database vettoriali
Alla fine del 2024, abbiamo valutato diverse opzioni di database vettoriali e alla fine abbiamo scelto Milvus sulla base di tre requisiti chiave.
- Innanzitutto, abbiamo dato priorità a una soluzione self-hosted per garantire la privacy dei dati e mantenere un controllo granulare della nostra infrastruttura.
- In secondo luogo, il nostro workload con molte scritture e pattern di query a picchi richiedeva un sistema che potesse scalare elasticamente mantenendo una latenza bassa e prevedibile.
- Infine, la nostra architettura richiedeva un forte isolamento tra milioni di tenant dei clienti.
Milvus è emerso come la scelta migliore: la sua natura distribuita supporta una multi-tenancy massiva e ci consente di scalare ingestione, indicizzazione ed esecuzione delle query in modo indipendente, offrendo prestazioni mantenendo al contempo costi prevedibili.
Progettazione dell’architettura
Dopo aver scelto una tecnologia, abbiamo poi dovuto determinare un’architettura per rappresentare la forma dei dati unica di Airtable: milioni di “base” distinte appartenenti a clienti diversi.
La sfida del partizionamento
Abbiamo valutato due principali strategie di partizionamento dei dati:
Opzione 1: Partizioni condivise
Più base condividono una partizione e le query sono limitate filtrando su un base id. Questo migliora l’utilizzo delle risorse, ma introduce un overhead di filtraggio aggiuntivo e rende più complessa l’eliminazione delle base.
Opzione 2: Una base per partizione
Ogni base Airtable viene mappata alla propria partizione fisica in Milvus. Questo garantisce un forte isolamento, consente un’eliminazione rapida e semplice delle base ed evita l’impatto sulle prestazioni del filtraggio post-query.
Strategia finale
Abbiamo scelto l’opzione 2 per la sua semplicità e il forte isolamento. Tuttavia, i primi test hanno mostrato che la creazione di 100k partizioni in una singola collection Milvus causava un significativo degrado delle prestazioni:
- La latenza di creazione delle partizioni è aumentata da ~20 ms a ~250 ms
- I tempi di caricamento delle partizioni hanno superato i 30 secondi
Per risolvere questo problema, abbiamo limitato il numero di partizioni per collection. Per ogni cluster Milvus, creiamo 400 collection, ciascuna con al massimo 1.000 partizioni. Questo limita il numero totale di base per cluster a 400k, e nuovi cluster vengono predisposti man mano che vengono acquisiti nuovi clienti.
Indicizzazione e recall
La scelta dell’indice si è rivelata uno dei compromessi più importanti nel nostro sistema. Quando una partizione viene caricata, il suo indice viene memorizzato nella cache in memoria o su disco. Per trovare un equilibrio tra tasso di recall, dimensione dell’indice e prestazioni, abbiamo eseguito benchmark su diversi tipi di indice.
- IVF-SQ8: Ha offerto un footprint di memoria ridotto ma un recall inferiore.
- HNSW: Offre il miglior recall (99%-100%) ma richiede molta memoria.
- DiskANN: Offre un recall simile a HNSW ma con una latenza delle query più elevata
Alla fine, abbiamo selezionato HNSW per il suo recall superiore e le sue caratteristiche prestazionali.
Il livello applicativo
A un livello generale, la pipeline di ricerca semantica di Airtable comprende due flussi principali:
- Flusso di ingestion: Convertire le righe di Airtable in embedding e archiviarle in Milvus
- Flusso di query: Creare embedding delle query degli utenti, recuperare gli ID delle righe rilevanti e fornire contesto all’LLM
Entrambi i flussi devono operare continuamente e in modo affidabile su larga scala, e li esaminiamo di seguito. Li esaminiamo di seguito.
Flusso di ingestion: mantenere Milvus sincronizzato con Airtable
Quando un utente apre Omni, Airtable inizia a sincronizzare la sua base con Milvus. Creiamo una partizione, quindi elaboriamo le righe in blocchi, generando embedding ed eseguendo upsert in Milvus. Da quel momento in poi, catturiamo qualsiasi modifica apportata alla base, quindi rigeneriamo gli embedding ed eseguiamo l’upsert di quelle righe per mantenere i dati coerenti.
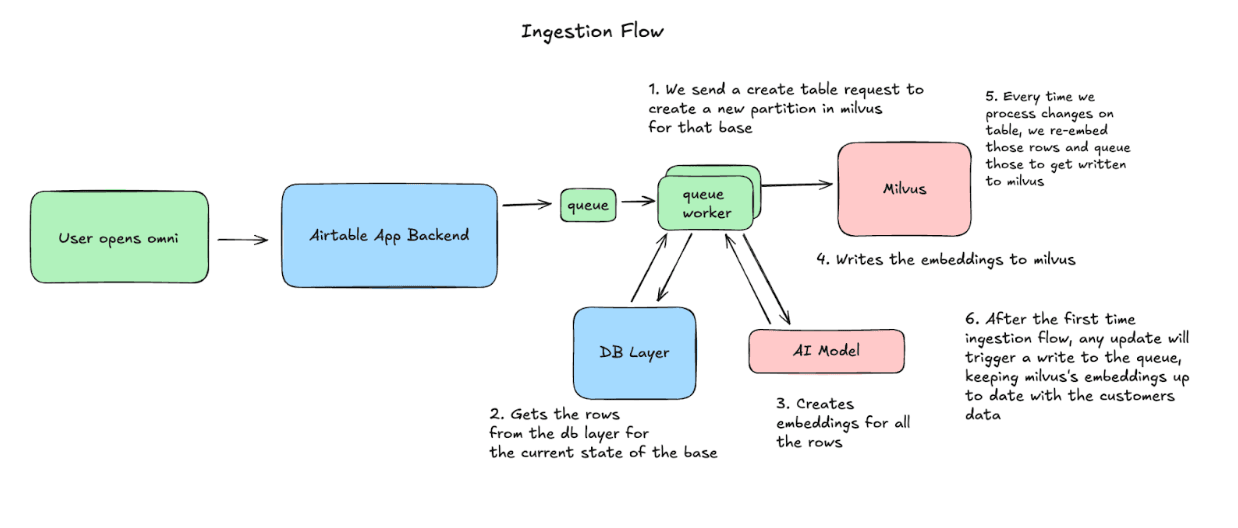
Flusso di query: come utilizziamo i dati
Sul lato delle query, creiamo l’embedding della richiesta dell’utente e la inviamo a Milvus per recuperare gli ID delle righe più rilevanti. Quindi recuperiamo le versioni più recenti di quelle righe e le includiamo come contesto nella richiesta all’LLM.
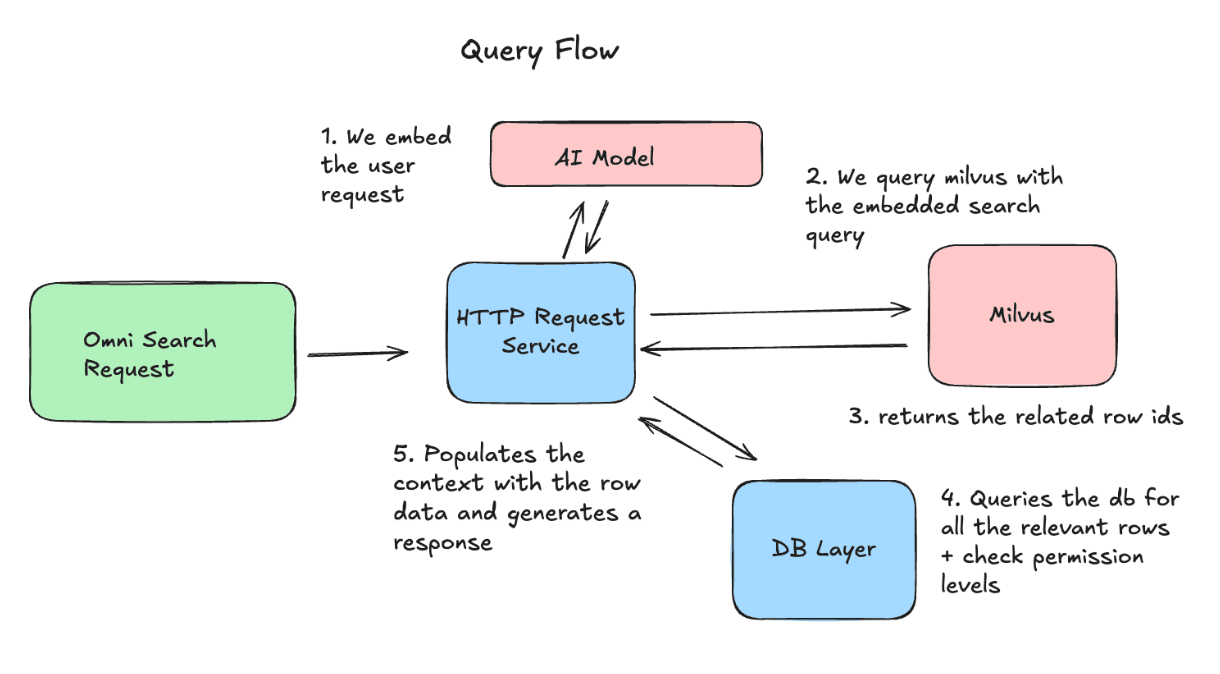
Sfide operative e come le abbiamo risolte
Costruire un’architettura di ricerca semantica è una sfida; eseguirla in modo affidabile per centinaia di migliaia di base è un’altra. Di seguito sono riportate alcune lezioni operative chiave che abbiamo appreso lungo il percorso.
Deployment
Distribuiamo Milvus tramite la sua CRD Kubernetes con il Milvus operator, consentendoci di definire e gestire i cluster in modo dichiarativo. Ogni modifica, che si tratti di un aggiornamento della configurazione, di un miglioramento del client o di un upgrade di Milvus, passa attraverso unit test e un test di carico on-demand che simula il traffico di produzione prima del rollout agli utenti.
Nella versione 2.5, il cluster Milvus è composto da questi componenti principali:
- I nodi di query mantengono gli indici vettoriali in memoria ed eseguono le ricerche vettoriali
- I nodi dati gestiscono l’ingestione e la compattazione, e persistono i nuovi dati nello storage
- I nodi indice creano e mantengono gli indici vettoriali per mantenere la ricerca veloce man mano che i dati crescono
- Il nodo coordinatore orchestra tutte le attività del cluster e l’assegnazione degli shard
- I nodi proxy instradano il traffico API e bilanciano il carico tra i nodi
- Kafka fornisce la dorsale di log/streaming per la messaggistica interna e il flusso di dati
- Etcd archivia i metadati del cluster e lo stato di coordinamento
Con l’automazione guidata da CRD e una pipeline di testing rigorosa, possiamo distribuire aggiornamenti rapidamente e in sicurezza.
Osservabilità: comprendere lo stato del sistema end-to-end
Monitoriamo il sistema su due livelli per garantire che la ricerca semantica rimanga veloce e prevedibile.
A livello di infrastruttura, monitoriamo CPU, utilizzo della memoria e stato dei pod su tutti i componenti Milvus. Questi segnali ci indicano se il cluster sta operando entro limiti sicuri e ci aiutano a individuare problemi come la saturazione delle risorse o nodi non integri prima che influiscano sugli utenti.
A livello di servizio, ci concentriamo su quanto bene ogni base riesca a tenere il passo con i nostri carichi di lavoro di ingestione e query. Metriche come il throughput di compattazione e indicizzazione ci danno visibilità su quanto efficientemente i dati vengono ingeriti. I tassi di successo delle query e la latenza ci danno una comprensione dell’esperienza utente nell’interrogare i dati, e la crescita delle partizioni ci permette di sapere come stanno crescendo i nostri dati, così veniamo avvisati se dobbiamo scalare.
Rotazione dei nodi
Per ragioni di sicurezza e conformità, ruotiamo regolarmente i nodi Kubernetes. In un cluster di ricerca vettoriale, questo non è banale:
- Man mano che i nodi di query vengono ruotati, il coordinatore ribilancerà i dati in memoria tra i nodi di query
- Kafka ed Etcd archiviano informazioni stateful e richiedono quorum e disponibilità continua
Affrontiamo questo con disruption budget rigorosi e una politica di rotazione di un nodo alla volta. Al coordinatore Milvus viene dato il tempo di ribilanciare prima che il nodo successivo venga sostituito. Questa attenta orchestrazione preserva l’affidabilità senza rallentare la nostra velocità.
Offloading delle partizioni fredde
Uno dei nostri maggiori successi operativi è stato riconoscere che i nostri dati hanno chiari pattern di accesso hot/cold. Analizzando l’utilizzo, abbiamo scoperto che solo circa il 25% dei dati in Milvus viene scritto o letto in una determinata settimana. Milvus ci consente di scaricare intere partizioni, liberando memoria sui nodi di query. Se quei dati servono in seguito, possiamo ricaricarli in pochi secondi. Questo ci permette di mantenere i dati hot in memoria e scaricare il resto, riducendo i costi e consentendoci di scalare in modo più efficiente nel tempo.
Recupero dei dati
Prima di distribuire Milvus su larga scala, avevamo bisogno della certezza di poterci riprendere rapidamente da qualsiasi scenario di errore. Sebbene la maggior parte dei problemi sia coperta dalla tolleranza ai guasti integrata del cluster, abbiamo anche pianificato casi rari in cui i dati potrebbero corrompersi o il sistema potrebbe entrare in uno stato irrecuperabile.
In queste situazioni, il nostro percorso di recupero è semplice. Prima avviamo un nuovo cluster Milvus pulito, così possiamo riprendere a servire traffico quasi immediatamente. Una volta che il nuovo cluster è live, rieseguiamo proattivamente l’embedding delle basi più comunemente utilizzate, poi elaboriamo pigramente il resto man mano che viene acceduto. Questo minimizza il downtime per i dati più consultati mentre il sistema ricostruisce gradualmente un indice semantico coerente.
Cosa c’è dopo
Il nostro lavoro con Milvus ha posto solide fondamenta per la ricerca semantica in Airtable: alimentando esperienze AI veloci e significative su larga scala. Con questo sistema in funzione, stiamo ora esplorando pipeline di retrieval più ricche e integrazioni AI più profonde in tutto il prodotto. C’è molto lavoro entusiasmante davanti a noi, e siamo solo all’inizio.
Grazie a tutti gli Airtablet passati e presenti di Data Infrastructure e di tutta l’organizzazione che hanno contribuito a questo progetto: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
Informazioni su Airtable
Airtable è una piattaforma leader per le operazioni digitali che consente alle organizzazioni di creare app personalizzate, automatizzare i flussi di lavoro e gestire dati condivisi su scala enterprise. Progettata per supportare processi complessi e interfunzionali, Airtable aiuta i team a creare sistemi flessibili per la pianificazione, il coordinamento e l’esecuzione basati su un’unica fonte di verità condivisa. Man mano che Airtable amplia la sua piattaforma basata sull’AI, tecnologie come Milvus svolgono un ruolo importante nel rafforzare l’infrastruttura di retrieval necessaria per offrire esperienze di prodotto più rapide e intelligenti.
- Contesto
- Come usiamo la ricerca semantica
- Le nostre priorità progettuali
- Valutazione dei fornitori di database vettoriali
- Progettazione dell’architettura
- La sfida del partizionamento
- Indicizzazione e recall
- Il livello applicativo
- Flusso di ingestion: mantenere Milvus sincronizzato con Airtable
- Flusso di query: come utilizziamo i dati
- Sfide operative e come le abbiamo risolte
- Osservabilità: comprendere lo stato del sistema end-to-end
- Rotazione dei nodi
- Offloading delle partizioni fredde
- Recupero dei dati
- Cosa c’è dopo
- Informazioni su Airtable
Contenuto
Caso d'Uso
Settore
SaaS di IA