




Vector Lakebase: elimina il silo di dati dell'IA
Ogni team di IA incontra lo stesso ostacolo — la gravità dei dati
Ogni moderno team di dati ha costruito una qualche versione della stessa architettura. Una lakehouse — tabelle Iceberg su S3, una pipeline Spark e Delta Lake per la governance — è al centro. Funziona bene. Poi arrivano i requisiti dell’IA.
La tua pipeline RAG deve rispondere a domande su 10 anni di documenti aziendali, quindi copi tutto in un database vettoriale. I tuoi agenti IA hanno bisogno di accesso a bassa latenza agli embedding del catalogo prodotti — un’altra pipeline, un altro job di sincronizzazione. L’addestramento del tuo modello multimodale richiede la deduplicazione quotidiana su un miliardo di embedding di immagini — un job Spark che non può vedere l’indice.
Sei mesi dopo, hai cinque sistemi invece di due. Il tuo team di data engineering dedica più tempo a mantenere le pipeline di sincronizzazione che a creare funzionalità IA. Hai tre copie dello stesso dataset senza alcuna garanzia che siano coerenti. Ogni modifica dello schema si propaga in quattro posti diversi.
Questo non è un fallimento di esecuzione. È un fallimento di architettura — nello specifico, un’architettura che continua a lottare contro una proprietà fondamentale dei dati: la gravità. Ogni sistema che ti richiede prima di copiare i dati ti sta imponendo una tassa di gravità. Più workload di IA aggiungi — pipeline RAG, memoria degli agenti, addestramento di modelli, raccomandazioni in tempo reale — più alta diventa quella tassa.
La soluzione giusta non è una pipeline migliore. Dovrebbe essere un nuovo paradigma architetturale: Vector Lakebase.
Tre generazioni di soluzioni architetturali, due vicoli ciechi
Prima di entrare nei dettagli di Vector Lakebase, vale la pena esaminare come l’architettura della ricerca vettoriale si sia evoluta per affrontare il problema della gravità dei dati. In generale, ci sono state tre generazioni di soluzioni.
Generazione 1: database vettoriali dedicati
I database vettoriali dedicati come Milvus hanno risolto un problema reale per i sistemi IA in produzione: ricerca semantica con latenza nell’ordine dei millisecondi, con recall e prestazioni che i database general-purpose non potevano eguagliare. In quanto creatori del database vettoriale open-source Milvus, Zilliz si è concentrata da tempo sulla costruzione di un sistema affidabile e ad alte prestazioni per archiviare embedding, costruire indici e servire retrieval a bassa latenza per RAG, agenti, sistemi di raccomandazione, ricerca semantica e applicazioni multimodali. Quella base è ancora importante. I sistemi IA in produzione hanno ancora bisogno di retrieval alla velocità di un database, e i database vettoriali restano il livello di serving giusto per molti workload sensibili alla latenza.
Tuttavia, man mano che i workload di IA maturano, la sfida si estende sempre più oltre il serving online. Gran parte dei dati sorgente di un’organizzazione vive già in object storage, data lake, lakehouse e sistemi analitici downstream. Per usare quei dati in un database vettoriale dedicato, i team in genere li copiano in un sistema di serving separato, costruiscono pipeline di ingestion, mantengono job di sincronizzazione e gestiscono la coerenza tra i dati sorgente e l’indice vettoriale. Quando i modelli di embedding cambiano, come inevitabilmente accade, i team devono rigenerare gli embedding, ricostruire gli indici e mantenere allineati più sistemi.
Questa non è una limitazione delle prestazioni dei database vettoriali. È un confine architetturale creato dallo spostamento dei dati. Man mano che più team vogliono usare gli stessi dati per retrieval in produzione, esperimenti di embedding, valutazione offline, governance, lineage e analytics, la superficie operativa cresce. I database vettoriali dedicati hanno risolto estremamente bene il problema del retrieval online, ma da soli non eliminano il problema della gravità dei dati.
Generazione 2: Vector Lake
La successiva risposta naturale è stata avvicinare la ricerca vettoriale al lake: interrogare i vettori direttamente da file Iceberg, Delta Lake o Parquet senza prima spostarli in un sistema di serving dedicato. La motivazione era corretta. Se i dati vivono già in object storage o in una lakehouse, perché duplicarli altrove solo per renderli ricercabili?
Ma in pratica, le architetture vector lake rimangono incomplete per i workload di AI in produzione per tre motivi.
Primo, non sono progettate per il serving a bassa latenza. La maggior parte degli approcci vector lake carica dati o indici dall'object storage on demand ed è ottimizzata più per la flessibilità che per la gestione di richieste concorrenti e sensibili alla latenza. Questo può essere accettabile per l'esplorazione offline, ma non è sufficiente per applicazioni RAG, agenti, raccomandazione o ricerca rivolte agli utenti. Quando una pipeline di retrieval si trova nel percorso critico di una chiamata LLM, i team hanno bisogno di una latenza prevedibile sotto i 100 ms con alta concorrenza. Se la latenza p99 deriva regolarmente nell'intervallo dei secondi, il sistema può essere ancora utile per l'analisi, ma non può fungere da layer di retrieval in produzione.
Secondo, i sistemi vector lake in genere si fermano alla fase di search. Consentono ai team di interrogare dati vettoriali nel lake, ma non forniscono un ambiente di esecuzione più ampio per i workflow di dati AI. I moderni sistemi di AI hanno bisogno di più della ricerca nearest-neighbor. Devono rigenerare embedding, valutare la qualità del retrieval, comprimere la memoria degli agenti, estrarre frame dai video, elaborare dati multimodali, gestire metadati e preparare dati per il fine-tuning o per pipeline downstream. Un sistema che aggiunge solo search sopra i file del lake non affronta l'intero ciclo di vita dei dati vettoriali e multimodali.
Terzo, il layer di storage sottostante non è stato costruito per questo workload. Iceberg e Delta Lake sono stati progettati per dati analitici strutturati — nessun tipo vettoriale nativo, nessuna struttura di indice, ogni query è una scansione completa. I workload di AI richiedono lookup puntuali veloci (non scansioni sequenziali dei row group di Parquet — formati come Vortex e Lance esistono per questo motivo), indici integrati co-gestiti con i dati e gestione di dati non strutturati basata su riferimenti in cui immagini, audio e video sono collegati tramite riferimento anziché incorporati inline come blob. Nulla di tutto questo esiste oggi nel lake. Un Vector Lake costruito su Iceberg combatte contro il layer di storage a ogni livello.
Generazione 3: Vector Lakebase
Vector Lakebase è ciò che si ottiene quando si smette di trattare il lake e il vector database come sistemi separati che devono essere sincronizzati e si inizia a costruirli come due modalità operative di un singolo layer unificato. Per essere più specifici:
Un vector lakebase è una nuova architettura AI-native e lake-native evoluta dai sistemi di vector database. Combina le capacità di serving ad alto QPS e bassa latenza dei vector database con l'apertura, la scalabilità e l'efficienza dei costi dei data lake multimodali, mantenendo al contempo tutti i workload sulla stessa source of truth senza migrazione dei dati. Separando il compute dallo storage, un vector lakebase memorizza dati multimodali, vettori, attributi, indici e metadati direttamente in object storage a basso costo usando formati aperti. I workload di serving, discovery e analytics possono quindi essere eseguiti indipendentemente sopra gli stessi dati.
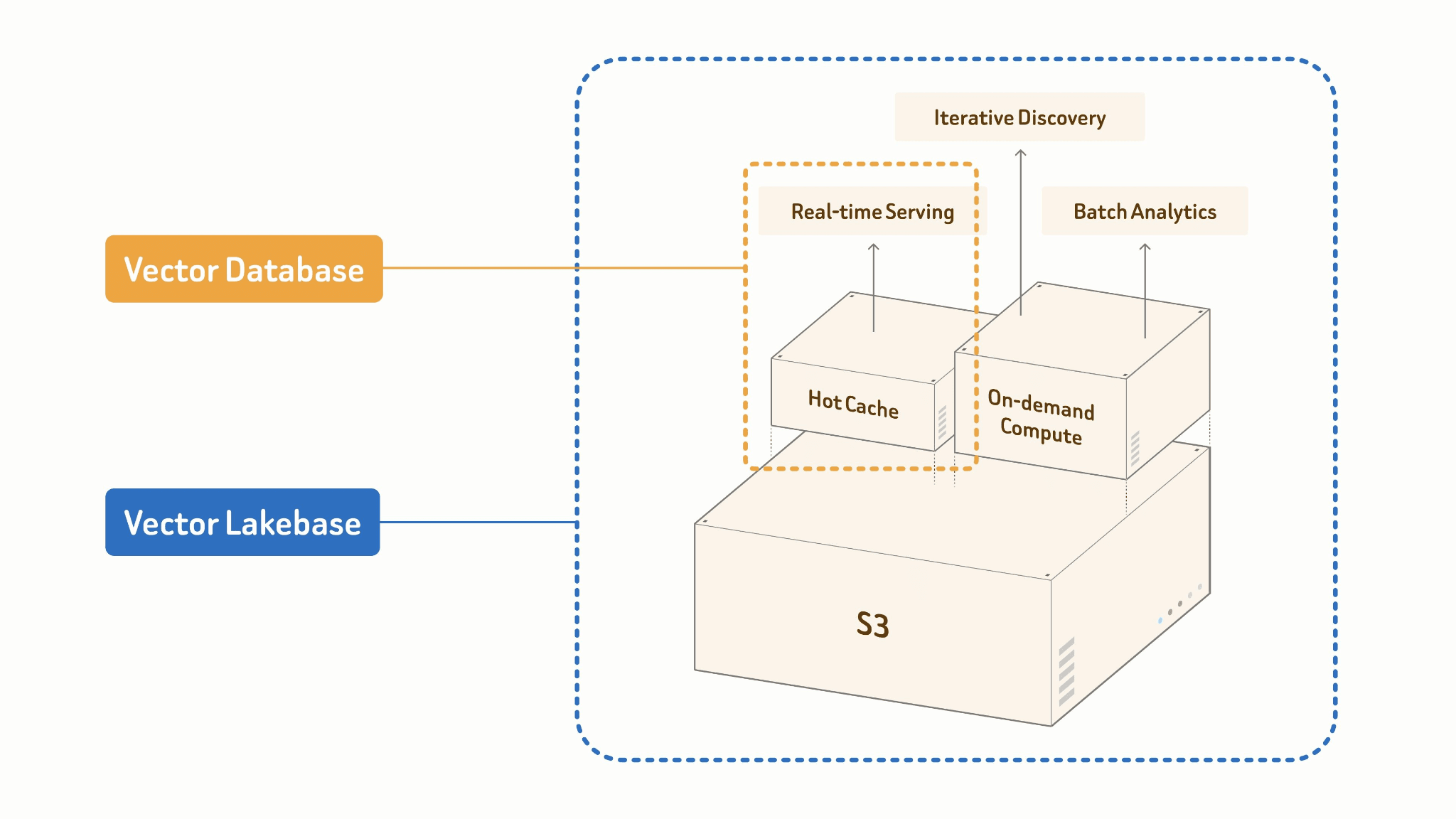
Il principio fondamentale: Un'unica Source of Truth.
La tua tabella lake è l'unica source of truth. Serving online e batch processing offline condividono gli stessi dati, indice e schema. Non c'è alcuna pipeline tra di loro perché non c'è alcun confine tra di loro.
Vector DB: [Lake] ──ETL──▶ [Vector DB] # duplicazione + obsolescenza
Vector Lake: [Lake + Index] ◀── solo query batch # niente serving, niente processing
Vector Lakebase: [Lake + Index + Compute]
├── Online: Cache + Indice ad alte prestazioni
│ → query ANN, serving p99 <100 ms
└── Offline: Batch Processing + Build di indici efficiente nei costi
→ embed, cluster, dedup, feature engineering
Le due modalità sono progettate diversamente per necessità. Il serving online funziona su una cache calda e un indice in-memory ad alte prestazioni — ottimizzato per concorrenza e latenza di coda. I job batch offline costruiscono indici in modo efficiente in termini di costi su larga scala: scansioni colonnari, costruzione accelerata da GPU, scritture staged di ritorno nel lake. Stessi dati, stesso formato di indice, profili di calcolo radicalmente diversi.
Che aspetto ha tutto questo nella pratica? Su una tabella Iceberg da 1 miliardo di vettori:
| Modalità | Latenza | Contesto |
|---|---|---|
| Scansione brute-force Spark (nessun indice) | Ore | Il default attuale per la ricerca vettoriale basata su lake |
| Vector Lakebase — freddo (indice appena costruito) | ~30 secondi | L’indice viene costruito da Iceberg in ~20 minuti |
| Vector Lakebase — caldo (cache su disco) | Decine di ms | Indice memorizzato nella cache su SSD locale |
| Vector Lakebase — molto caldo (in-memory) | Pochi ms | RAG di produzione e serving di agenti |
| Vector Lakebase — clustering / dedup | Ore | KMeans su 1 miliardo di vettori o rilevamento di quasi duplicati, completamente distribuito |
Si passa da ore a pochi millisecondi — e non si copiano mai i dati fuori dal lake.
Questa non è una scelta di prodotto. È la direzione verso cui sta convergendo l’architettura dei dati per l’AI. Qualsiasi sistema che richieda che i dati esistano in due posti ti fa pagare una tassa permanente — in storage, in ore di engineering, in obsolescenza. I sistemi che separano lo storage dalle operazioni AI appariranno, col senno di poi, come transitori.
Cosa consente davvero un Vector Lakebase
Almeno tre classi di workload che in precedenza richiedevano sistemi separati ora possono essere gestite con un vector lakebase.
Collezioni esterne: rendi il tuo lake ricercabile senza spostare nulla
Hai petabyte di embedding in file Parquet su S3. Renderli ricercabili per una nuova applicazione RAG oggi significa caricarli in un database vettoriale — una migrazione misurata in giorni o settimane, più un obbligo continuo di sincronizzazione.
Le collezioni esterne di Vector Lakebase lavorano con la gravità dei dati invece che contro di essa. Punti al bucket, definisci una mappatura dello schema sulle colonne esistenti e costruisci un indice vettoriale in-place. I dati rimangono in S3. L’indice persiste di nuovo su S3. Quando i dati sorgente vengono aggiornati, aggiorni in modo incrementale — vengono rielaborati solo i file modificati.
# 1. Registra i tuoi dati lake esistenti come collezione esterna
client.create_external_collection(
collection_name="enterprise_docs",
src="s3://my-lake/docs/*.parquet", # punta ai tuoi dati esistenti
schema={"text": String, "embedding": FloatVector(768)},
)
# 2. Costruisci un indice vettoriale — i dati rimangono in S3, l’indice persiste di nuovo su S3
client.create_index("enterprise_docs", field="embedding", index_type="HNSW")
# ~20 min per 1B di vettori. I dati non si spostano mai.
# 3. Cerca — pochi ms con cache in-memory
results = client.search(
collection_name="enterprise_docs",
data=[query_embedding],
top_k=10,
output_fields=["text"],
)
Nessuna migrazione, nessuna pipeline, nessun nuovo costo di storage. Il tuo sistema RAG interroga gli stessi dati che il tuo team analytics già governa — tramite Spark, Ray, LangChain, PyMilvus o una REST API. L’indice diventa una proprietà di prima classe della tabella, non un sistema esterno imbullonato accanto a essa.
ETL, Feature Engineering e Context Engineering
Questo è il workload che Vector Database e Vector Lake ignorano entrambi — e sta diventando la parte più importante dello stack dati per l’AI.
Le operazioni sui dati native per l’AI non si limitano a spostare dati tra sistemi — li arricchiscono con significato semantico, in-place, su larga scala:
- Aggiungere una colonna di embedding a una tabella esistente: inferenza batch su 100M righe, scrittura dei risultati nella stessa tabella.
- Suddividere in chunk un corpus di documenti per RAG, mantenendo documenti grezzi e chunk versionati insieme.
- Eseguire l’upgrade da text-embedding-3-small a un modello più recente — backfill di tutti i 500M vettori in place, con embedding vecchi e nuovi che coesistono finché non effettui il cutover.
- Creare e versionare i pacchetti di contesto che i tuoi agenti AI recuperano a runtime — cosa viene recuperato, come è strutturato, come è compresso per una context window.
Man mano che i modelli si commoditizzano, la qualità di ciò che gli fornisci conta più del modello che scegli. Questa disciplina emergente — Context Engineering — appartiene al lake: vicina ai dati, versionata insieme a essi, riproducibile end-to-end. Vector Lakebase la rende un’operazione di prima classe, non script ad hoc incollati insieme con cron job.
Clustering, deduplicazione e scoperta di anomalie
Essenziale per ogni team che addestra o esegue il fine-tuning dei propri modelli — e completamente assente dal paradigma dei database vettoriali:
- Deduplicazione: Esempi quasi duplicati nel tuo dataset di fine-tuning LLM gonfiano la training loss e distorcono il comportamento del modello. Identifica i quasi duplicati, emetti un set canonico, riscrivi le etichette di deduplicazione come colonna.
- Clustering: Comprendi cosa contiene davvero il tuo dataset prima dell’addestramento. Raggruppa il tuo spazio di embedding — spesso scoprirai che il 40% di un dataset “diverso” è composto da piccole variazioni sugli stessi pochi argomenti.
- Scoperta di anomalie: Per veicoli autonomi, robotica o qualsiasi modello safety-critical — trova lo 0,1% dei campioni che non assomigliano per nulla al resto. Contrassegnali, assegna loro priorità per l’etichettatura e includili nell’addestramento. Non puoi trovarli senza un indice; non puoi agire su di essi senza scrivere i risultati nel lake.
Vector Lakebase tratta queste come operazioni distribuite di prima classe: consapevoli degli indici, parallelizzate sui dati dove risiedono, con scrittura dei risultati in formati aperti. L’output di un’esecuzione di deduplicazione diventa una colonna nella stessa tabella.
Chi sta già costruendo su questo
I primi design partner di Vector Lakebase coprono due dei problemi più difficili dei dati AI su larga scala.
Aziende leader nel settore della guida autonoma e dei veicoli elettrici lo usano per estrarre corner case da miliardi di embedding di scene di guida — gli scenari stradali rari che determinano se un sistema di guida autonoma è sicuro. Una delle principali aziende di foundation model lo usa per il rilevamento di quasi duplicati nei corpora di pre-training — deduplicando miliardi di esempi per migliorare la qualità del modello prima che venga spesa una sola ora GPU nell’addestramento.
Abbiamo già Databricks Lakebase. Ne serve un altro?
È una domanda legittima, e la risposta richiede di capire che cos’è davvero Databricks Lakebase.
Databricks Lakebase — costruito sulla loro acquisizione di Neon — integra un motore PostgreSQL serverless nella piattaforma Databricks. Il problema che risolve: OLTP e OLAP sono sempre stati sistemi separati. Databricks sta eliminando questo confine. È un problema reale che vale la pena risolvere. Ma è un problema fondamentalmente diverso.
| Databricks Lakebase | Vector Lakebase | |
|---|---|---|
| Utente principale | Backend engineer, data engineer | ML engineer, team di piattaforma AI |
| Dati principali | Righe, account, transazioni | Embedding, documenti, multimodale |
| Modello di storage | Storage Postgres + Delta Lake (separati) | Singola tabella nel lake, unificata |
| Embedding batch / dedup | Fuori scope | Operazione di prima classe |
| Context Engineering | Fuori scope | Capacità core |
| Si basa sul lake esistente | Parziale | Sì — zero migrazione |
| Ottimizzazione del formato | Delta Lake, Parquet | Parquet, Vortex, Lance, Apache Iceberg, dati non strutturati nativi |
| OLTP (transazioni) | ✓ | N/D |
Databricks Lakebase elimina il confine OLTP/OLAP. Vector Lakebase elimina il confine tra dove vivono i tuoi dati AI e dove vengono eseguite le tue operazioni AI. Sono complementari, non competitivi. Molti team useranno entrambi.
La scommessa architetturale
Nel 2013, Databricks si è chiesta: E se l’analytics SQL vivesse nel lake? Quella domanda valeva $40 miliardi.
La prossima domanda è: E se anche le operazioni sui dati AI-native — recupero RAG, memoria degli agenti, embedding batch, curatela dei dati di training dei modelli, context engineering — vivessero nel lake?
È questa la scommessa dietro Vector Lakebase. Non un nuovo database verso cui migrare. Non un livello di query aggiunto al tuo lake esistente. Una base unificata in cui i tuoi dati vivono una sola volta, vengono indicizzati una sola volta e servono ogni workload di AI — senza duplicazione, senza overhead ETL, senza combattere la gravità.
La corsa all’AI premia la velocità. Ogni settimana che il tuo team passa a costruire pipeline di sincronizzazione, fare debug di dati obsoleti o migrare tra sistemi è una settimana che i tuoi concorrenti passano a rilasciare funzionalità AI. L’infrastruttura dovrebbe essere un acceleratore, non un collo di bottiglia. I team che vincono non sono quelli con i modelli migliori — sono quelli che hanno eliminato l’attrito tra i loro dati e la loro AI.
Costruisci sulle tue tabelle Iceberg o sul tuo data lake esistente. Nessuna migrazione. Nessuna duplicazione. Muoviti velocemente — i tuoi dati restano dove sono e diventano ricercabili, elaborabili e pronti per l’AI in pochi minuti.
Questo è Vector Lakebase.
Zilliz Vector Lakebase è disponibile in public preview
Abbiamo lanciato la public preview di Zilliz Vector Lakebase — una grande evoluzione di Zilliz Cloud da database vettoriale gestito a piattaforma semantica unificata per i dati, che combina il serving vettoriale a bassa latenza con l’apertura, la scalabilità e l’economicità di un data lake.
Funzionalità principali di Zilliz Vector Lakebase:
- Serving a livelli ottimizzato per diversi compromessi tra prestazioni real-time e costi
- Ricerca on-demand per workload su larga scala o esplorativi senza compute sempre attivo
- Ricerca su data lake esterni — indicizza e cerca direttamente sui dati del tuo lake esistente
- Ricerca full-spectrum su vettori, testo, JSON e dati geospaziali con recupero ibrido e reranking
- Storage unificato lake-native basato su Vortex, un formato aperto con letture casuali più rapide ed economiche rispetto a Lance o Parquet
Se il tuo stack attuale separa serving e discovery in sistemi distinti, Vector Lakebase potrebbe valere un’occhiata. Provalo su Zilliz Cloud — le nuove registrazioni con email di lavoro ricevono $100 di crediti gratuiti — oppure parla con noi del tuo caso d’uso.

Continua a leggere

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.