




Introduzione a Functions e Model Inference su Zilliz Cloud: embedding e reranking automatici con modelli hosted
Le pipeline di ricerca AI basate sui database vettoriali di solito richiedono di generare personalmente gli embedding, inserirli nel database vettoriale per il recupero per similarità, incorporare ogni query allo stesso modo e collegare un servizio di reranking separato se si desidera una migliore qualità dei risultati. Funziona, ma significa più codice di integrazione e più punti in cui le cose possono divergere.
Oggi annunciamo Functions and Inference Services su Zilliz Cloud — ora in Public Preview per modelli di terze parti e in Private Preview per Zilliz Hosted Models. Puoi inserire testo grezzo ed effettuare ricerche con il linguaggio naturale. Poi Zilliz Cloud gestisce automaticamente la generazione degli embedding, l’archiviazione vettoriale e il reranking dei risultati.
Cosa sono Functions and Inference Services su Zilliz Cloud?
Una Function Function è un’operazione dichiarativa collegata a una collection che indica a Zilliz Cloud come elaborare i tuoi dati. Invece di inviare vettori, ora devi solo inviare testo grezzo. Invece di incorporare le query lato client, invii direttamente query testuali. Poi Zilliz Cloud gestisce il resto.
Le Functions rientrano in due categorie:
- Le Pre-search Functions vengono eseguite in fase di ingestion e al momento della query, convertendo il testo in rappresentazioni ricercabili. Questo include BM25 per la ricerca full-text basata su parole chiave (nessun modello richiesto) e approcci basati su modelli che producono embedding densi per la ricerca semantica.
- Le Post-search Functions vengono eseguite dopo il recupero, perfezionando e riordinando i risultati. Questo include ranker ibridi che uniscono più set di risultati, ranker basati su regole per la logica di business e ranker basati su modelli che valutano la rilevanza tra query e documenti.
Il diagramma seguente fornisce un’astrazione di come funzionano le Functions nel workflow di ricerca.
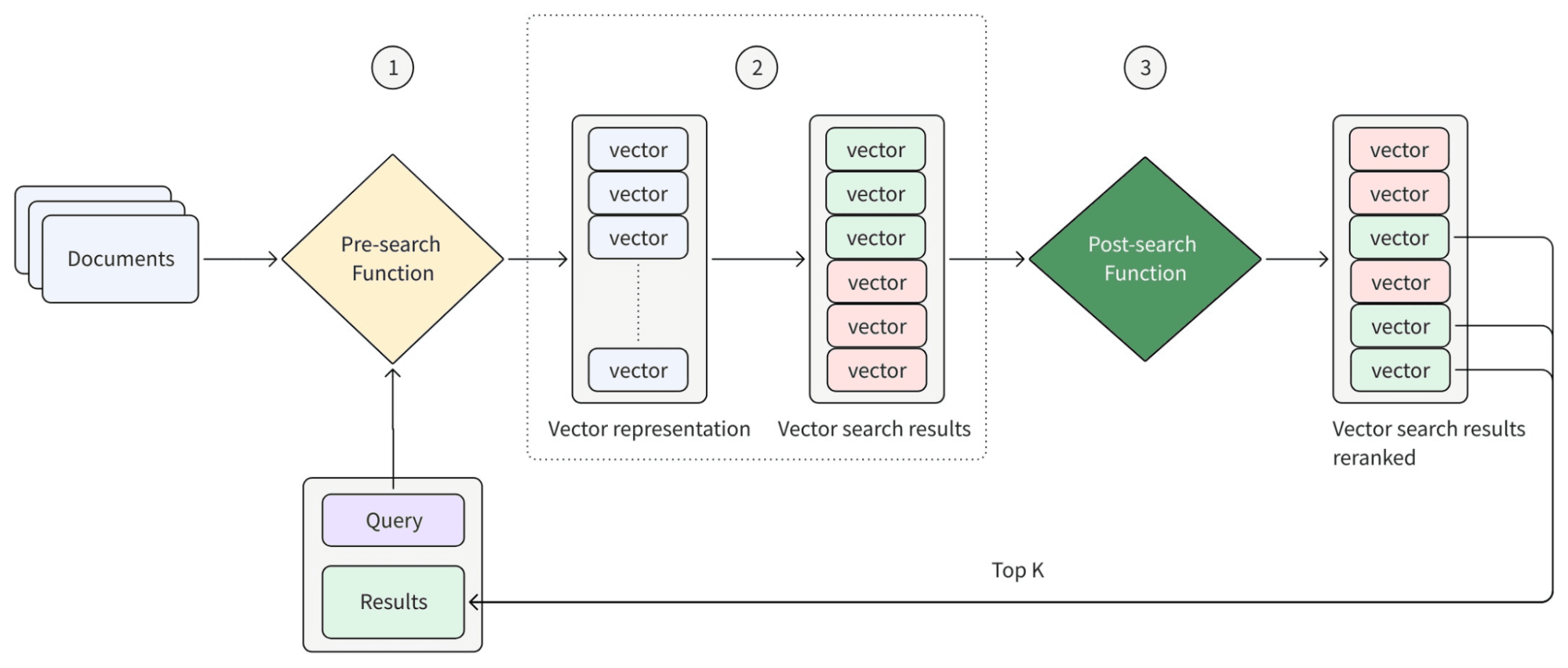
Gli Inference Services alimentano le Functions basate su modelli. Quando una Function deve generare un embedding o assegnare un punteggio a una coppia query-documento, chiama un modello da una delle due fonti:
| Fonte | Come funziona |
|---|---|
| Provider di terze parti (OpenAI, Voyage AI, Cohere) | Porti la tua chiave API. Zilliz Cloud gestisce l’integrazione. |
| Zilliz Hosted Models | Istanze di modello completamente gestite sull’infrastruttura GPU di Zilliz. I tuoi dati non lasciano mai la piattaforma. |
La distinzione più semplice: le Functions definiscono cosa accade ai tuoi dati. Gli Inference Services definiscono quale modello svolge il lavoro.
Perché spostare embedding e reranking dentro Zilliz Cloud?
Se oggi chiami un’API di embedding e inserisci vettori in Zilliz Cloud, questo funziona già. Ma man mano che le applicazioni scalano, emergono diversi punti di attrito.
La coerenza del modello diventa un tuo problema
Il percorso di ingestion e il percorso di query devono usare esattamente lo stesso modello. Se divergono — per esempio, se un deployment aggiorna un lato ma non l’altro — la qualità della ricerca degrada silenziosamente. Con le Functions, la collection possiede la configurazione del modello. Ingestion e query sono garantite per corrispondere.
Il reranking viene saltato perché comporta troppo attrito
Il reranking basato su modelli migliora significativamente la qualità dei risultati, soprattutto per la ricerca ibrida. Ma aggiungere un’altra chiamata di servizio dopo ogni query — con la propria chiave API, il proprio budget di latenza e la propria gestione degli errori — è un attrito sufficiente perché molti team rilascino senza di esso. Quando il reranking è una Function integrata, quell’attrito scompare.
Le credenziali proliferano tra i servizi
Ogni servizio che scrive o cerca dati necessita della chiave API del tuo provider di embedding. Con Functions, le credenziali risiedono nella Model Provider Integration di Zilliz Cloud — un unico punto per gestirle, un unico punto per ruotare le chiavi, nessun segreto nel codice dell'applicazione.
I dati lasciano la tua rete a ogni chiamata di inferenza
Per i team con requisiti di privacy o conformità, inviare testo grezzo a un'API esterna a ogni inserimento e query è una reale preoccupazione. Hosted Models mantiene tutto — dati, inferenza, archiviazione, ricerca — all'interno della rete privata di Zilliz.
Cosa è disponibile in Public Preview
Funzioni di embedding basate su modello
Collega un modello di embedding a una collection. Da quel momento in poi:
- Inserisci testo grezzo tramite Insert, Upsert o Import — Zilliz Cloud genera e archivia automaticamente embedding vettoriali densi.
- Cerca con testo — il sistema incorpora la tua query con lo stesso modello ed esegue la ricerca ANN.
Nessun codice di embedding lato client. Nessuna preoccupazione per la coerenza del modello. La tua applicazione lavora semplicemente con il testo.
Funzioni di reranking basate su modello
Seleziona un modello di reranking e applicalo come passaggio post-ricerca integrato. Questo è particolarmente potente per la ricerca ibrida, in cui combini recupero semantico e per parole chiave in un unico insieme di risultati.
I reranker basati su modello vanno oltre la similarità vettoriale — leggono il contenuto di ciascun candidato e valutano quanto bene risponda effettivamente alla query. È la differenza tra "questi vettori sono vicini" e "questo documento risponde alla domanda."
Provider supportati
| Provider | Embedding | Reranking |
|---|---|---|
| OpenAI | Sì | -- |
| Voyage AI | Sì | Sì |
| Cohere | Sì | Sì |
Model Provider Integration
Registra una sola volta le credenziali API di terze parti nella console di Zilliz Cloud tramite Model Provider Integration. Le collection fanno riferimento all'integrazione tramite ID — nessuna chiave nel codice. Ruota le credenziali in un unico punto; ogni collection che usa quell'integrazione acquisisce automaticamente la modifica.
Cosa è in Private Preview: Hosted Models
Per i team in cui latenza, costo o residenza dei dati sono una priorità, Hosted Models esegue istanze di modello completamente gestite sull'infrastruttura GPU di Zilliz. La differenza architetturale: invece di inviare dati a un'API esterna, il modello viene eseguito proprio accanto ai tuoi dati.
Il diagramma seguente mostra le procedure per l'utilizzo dei modelli hosted.
| Vantaggio | Cosa significa |
|---|---|
| Zero costi di trasferimento dati | L'inferenza avviene all'interno della rete Zilliz |
| Latenza inferiore | Nessun round trip esterno per embedding o reranking |
| Privacy migliorata | Il testo grezzo non lascia mai l'ambiente Zilliz |
| Risorse dedicate | Nessun problema di prestazioni dovuto a noisy neighbor |
Modelli disponibili
| Categoria | Modelli |
|---|---|
| Embedding | Qwen3-Embedding (0.6B, 4B, 8B), serie BAAI BGE (small, base, large — EN & ZH) |
| Reranking | Qwen3-Reranker (0.6B, 4B, 8B), BAAI BGE Reranker (base, large) |
| Semantic Highlighter | zilliz/semantic-highlight-bilingual-v1 — evidenzia segmenti di testo rilevanti nei risultati |
Hosted Models è disponibile su richiesta. Contatta il team Zilliz per ottenere l'accesso.
Riepilogo completo delle funzionalità di Function e inferenza
Funzioni pre-ricerca
| Funzione | Descrizione | Stato |
|---|---|---|
| BM25 | Embedding sparsi per la ricerca full-text per parole chiave — nessun modello richiesto | GA |
| Embedding basato su modello (di terze parti) | Embedding densi tramite OpenAI, Voyage AI, Cohere | Public Preview |
| Embedding basato su modello (Hosted) | Embedding densi tramite Qwen3, BGE ospitati da Zilliz | Private Preview |
Funzioni post-ricerca
| Funzione | Descrizione | Stato |
|---|---|---|
| Ranker ibridi | Uniscono i risultati di più strategie di recupero (ad es., semantica + parole chiave) | GA |
| Ranker basati su regole | Applicano logiche di business — recency, popolarità, punteggi personalizzati | GA |
| Ranker basati su modello (di terze parti) | Reranking semantico tramite Voyage AI, Cohere | Public Preview |
| Ranker basati su modello (Hosted) | Reranking semantico tramite Qwen3, BGE ospitati da Zilliz | Private Preview |
BM25, i ranker ibridi e i ranker basati su regole sono stati generalmente disponibili. La release di oggi aggiunge intelligenza basata su modello sia per l'embedding sia per il ranking — oltre all'infrastruttura per eseguire quei modelli tramite API di terze parti o direttamente su Zilliz Cloud.
Come iniziare con Zilliz Cloud Functions
Public Preview (disponibile ora):
- Registrati o accedi a Zilliz Cloud — i nuovi account registrati con un'email di lavoro ricevono $100 in crediti gratuiti
- Configura una Model Provider Integration nella console
- Crea una collection con una funzione di embedding
- Inserisci testo grezzo ed effettua ricerche con testo — tutto qui
Private Preview (su richiesta):
Contattaci per provare Hosted Models con inferenza dedicata.
Documentazione completa: Guida a funzioni e inferenza dei modelli
Domande frequenti
Alcune domande frequenti su embedding, reranking e inferenza gestita per la ricerca vettoriale:
Un database vettoriale può generare automaticamente embedding?
Sì. Con Zilliz Cloud Functions, associ un modello di embedding a una collection e inserisci testo grezzo — il database genera e archivia embedding vettoriali densi per tuo conto. Le query funzionano allo stesso modo: invii una query testuale e il sistema la trasforma in embedding con lo stesso modello prima di eseguire la ricerca ANN. Questo elimina il codice di embedding lato client e garantisce coerenza del modello tra ingestione e ricerca.
Che cos'è il reranking basato su modello e in che modo migliora la ricerca vettoriale?
Il reranking basato su modello è una fase post-recupero in cui un modello linguistico valuta quanto bene ogni documento candidato risponda effettivamente alla query — invece di basarsi esclusivamente sui punteggi di similarità vettoriale. È particolarmente efficace per pipeline di ricerca ibride che combinano recupero per parole chiave e semantico. Su Zilliz Cloud, puoi applicare il reranking basato su modello come Function integrata usando provider come Voyage AI o Cohere, oppure tramite Zilliz Hosted Models.
Qual è la differenza tra modelli di embedding hosted e di terze parti?
I modelli di terze parti (OpenAI, Voyage AI, Cohere) vengono eseguiti sull'infrastruttura del provider — fornisci una chiave API e paghi per chiamata. Gli Hosted Models vengono eseguiti su infrastruttura GPU gestita da Zilliz, quindi i tuoi dati non lasciano mai la piattaforma. Gli Hosted Models offrono latenza inferiore, zero costi di trasferimento dati e compute dedicato senza problemi di noisy-neighbor. Il compromesso: il pay-per-call di terze parti può essere più economico a bassi volumi, mentre le istanze hosted sono più convenienti su larga scala.
Come si combinano ricerca per parole chiave e ricerca semantica in un'unica query?
Su Zilliz Cloud, puoi collegare sia una Funzione BM25 (per la ricerca per parole chiave tramite embedding sparsi) sia una Funzione di embedding basata su modello (per la ricerca semantica tramite embedding densi) alla stessa collection. Al momento della query, un classificatore ibrido o un riclassificatore basato su modello unisce i risultati in un unico elenco ordinato. La collection gestisce insieme embedding sparsi, embedding densi e riclassificazione — senza bisogno di orchestrazione esterna.

Continua a leggere

A Developer's Guide to Exploring Milvus 2.6 Features on Zilliz Cloud
Milvus 2.6 marks a shift from “vector search + glue code” to a more advanced retrieval engine, and it is now Generally Available (GA) on Zilliz Cloud (a managed Milvus service).

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.