




Tout ce que vous devez savoir sur Llama 2

Tout ce que vous devez savoir sur Llama 2
Qu’est-ce que Llama 2 ?
Llama 2, présenté par Meta AI en 2023, constitue une avancée majeure dans les grands modèles de langage (LLMs). Ces modèles, Llama 2 et Llama 2-CHAT, atteignent jusqu’à 70 milliards de paramètres et sont disponibles gratuitement à des fins de recherche et commerciales, représentant un bond en avant dans les capacités de traitement du langage naturel (NLP), de la génération de texte à l’interprétation du code de programmation.
S’appuyant sur son prédécesseur, LLaMa 1, qui n’était initialement accessible qu’aux institutions de recherche sous une licence non commerciale, Llama 2 marque un tournant important vers la démocratisation de l’accès aux technologies d’IA de pointe. Contrairement à son prédécesseur, les modèles Llama 2 sont « open-source » et donc librement disponibles pour la recherche et les applications commerciales, reflétant l’engagement de Meta à favoriser un écosystème d’IA générative plus inclusif et collaboratif.
La publication de Llama 2 donne accès à des LLMs de pointe et répond aux défis computationnels associés à leur développement. En optimisant les performances sans augmenter exponentiellement le nombre de paramètres, Llama 2 propose des modèles avec différentes tailles de paramètres, allant de 7 milliards à 70 milliards. Cette approche stratégique permet aux petites organisations et aux communautés de recherche d’exploiter la puissance des LLMs sans ressources informatiques exorbitantes.
De plus, l’engagement de Meta en faveur de la transparence est évident dans sa décision de publier à la fois le code et les poids du modèle de Llama 2, facilitant une meilleure compréhension et une collaboration accrue au sein de la communauté de recherche en IA. En abaissant les barrières à l’entrée et en favorisant l’accessibilité, Llama 2 ouvre la voie à un avenir plus inclusif et innovant dans la recherche et le développement en IA.
Llama 2
Llama 2 est une version mise à jour de Llama 1 entraînée sur un nouveau mélange de données publiques. L’ensemble de données préentraîné a été augmenté de 40 %, la longueur du contexte a été doublée, et l’équipe de Meta a adopté l’attention par requêtes groupées lors de la création de Llama 2.
| Données d’entraînement | Paramètres | Longueur du contexte | Attention par requêtes groupées | Tokens | |
| Llama 1 | Voir Touvron et al.(2023) | 7B | 2K | - | 1.0T |
| 13B | 2K | - | 1.0T | ||
| 33B | 2K | - | 1.4T | ||
| 65B | 2K | - | 1.4T | ||
| Llama 2 | Un nouveau mélange de données en ligne publiquement disponibles | 7B | 4K | - | 2.0T |
| 13B | 4K | - | 2.0T | ||
| 34B | 4K | ✓ | 2.0T | ||
| 70B | ✓ | 2.0T |
Llama 2-CHAT
Llama 2-CHAT est une version affinée de Llama 2 que l’équipe Meta a optimisée pour les cas d’utilisation en langage naturel. Les variantes de ce modèle sont disponibles avec 7B, 13B et 70B paramètres. Llama 2-Chat est soumis aux mêmes limitations bien reconnues que les autres LLMs, notamment l’arrêt des mises à jour des connaissances après le préentraînement, le potentiel de génération non factuelle comme des conseils non qualifiés, et une propension aux hallucinations.
Llama 2 open source
Bien que Meta ait généreusement fourni l’accès au code de départ et aux poids des modèles Llama 2 à des fins de recherche et commerciales, des discussions ont émergé concernant la pertinence de le qualifier d’"open source" en raison de certaines restrictions énoncées dans son accord de licence.
Le débat entourant la classification des conditions de licence de Llama 2 repose sur des nuances techniques et sémantiques. Bien que "open source" soit couramment utilisé de manière familière pour désigner tout logiciel dont le code source est librement accessible, il revêt une signification spécifique en tant que désignation formelle supervisée par l’Open Source Initiative (OSI). Pour être qualifiée d’"approuvée par l’Open Source Initiative", une licence logicielle doit respecter les dix critères énoncés dans la définition officielle de l’Open Source (OSD).
Ainsi, l’applicabilité du label "open source" aux modèles Llama 2 dépend de la mesure dans laquelle ses conditions de licence s’alignent sur les critères stricts établis par l’OSI. Cette distinction souligne l’importance de la clarté et de la précision lorsqu’on discute de l’accessibilité et de la distribution des ressources logicielles au sein de la communauté de développement au sens large.
Cependant, même si Llama 2 n’est pas entièrement open-source, il offre aux développeurs un modèle convaincant avec bien plus de flexibilité que les modèles fermés créés par OpenAI, Google et d’autres acteurs majeurs du domaine de l’IA générative.
Architecture de Llama 2
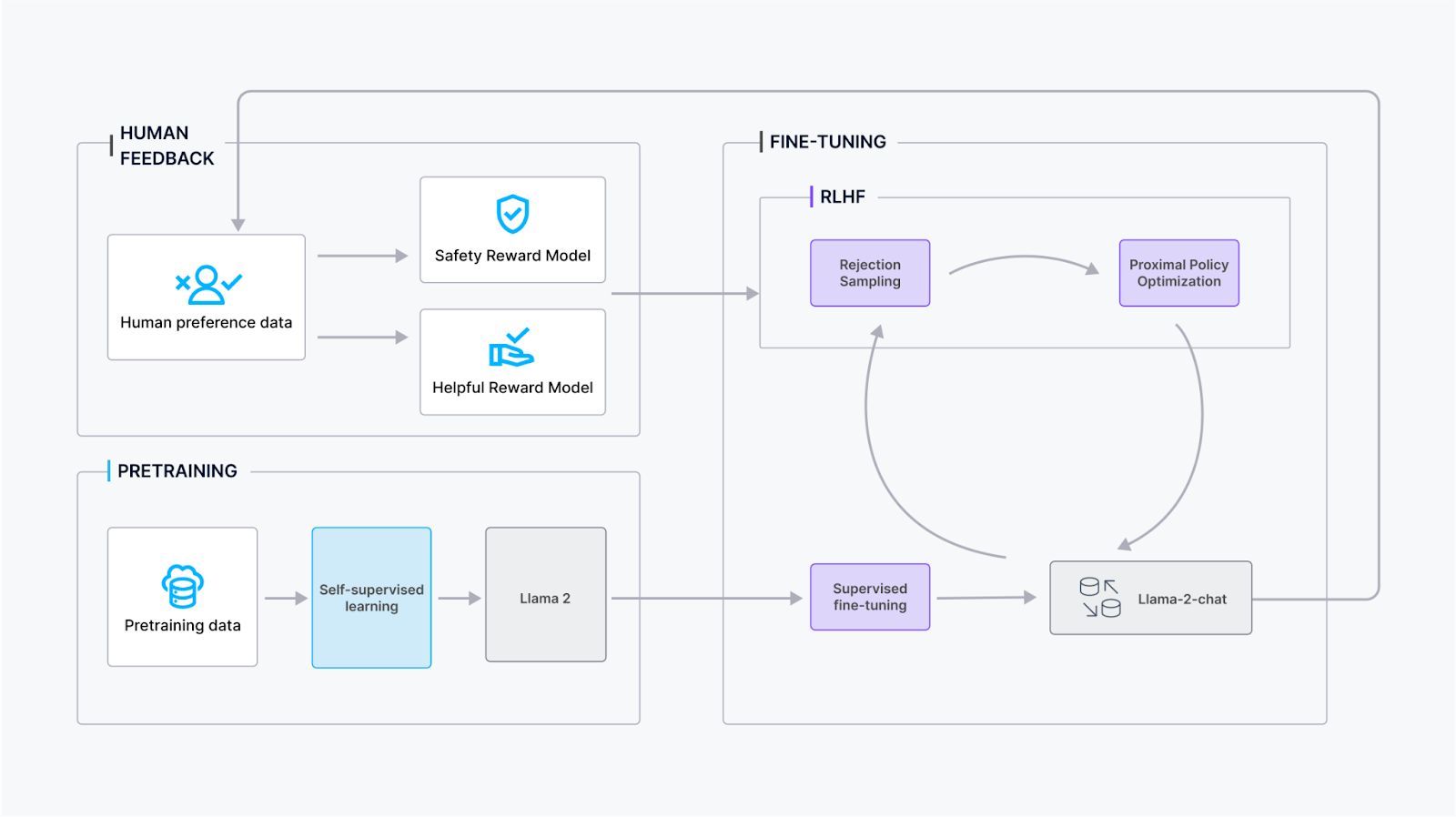
Le processus d’entraînement de Llama 2-Chat implique plusieurs étapes afin de garantir des performances optimales et un raffinement :
Préentraînement: Llama 2 subit un préentraînement à l’aide de sources en ligne publiquement disponibles afin d’établir des connaissances fondamentales et une compréhension du langage.
Affinage supervisé: L’équipe Meta a créé une version initiale de Llama 2-Chat grâce à un affinage supervisé, où le modèle apprend à partir de données étiquetées afin d’améliorer ses capacités conversationnelles.
Apprentissage par renforcement avec retour humain (RLHF): Le modèle fait l’objet d’un raffinement itératif à l’aide de méthodologies RLHF, principalement par échantillonnage par rejet et optimisation de politique proximale (PPO). Cette étape implique une interaction continue avec les retours humains afin d’améliorer la qualité conversationnelle.
Modélisation itérative des récompenses: Tout au long de l’étape RLHF, l’accumulation de données de modélisation itérative des récompenses se produit en parallèle avec les améliorations du modèle. La modélisation itérative des récompenses garantit que les modèles de récompense restent dans la distribution, contribuant ainsi à améliorer constamment les capacités conversationnelles du modèle.
En intégrant ces étapes, l’entraînement de Llama 2-Chat vise à atteindre des performances conversationnelles robustes tout en s’adaptant aux retours des utilisateurs et en maintenant l’alignement avec les modèles de récompense.
Qu’est-ce qu’un Embedding en Machine Learning?
En machine learning, un embedding désigne une représentation apprise d’objets dans un espace vectoriel continu, tels que des mots, des images ou des entités. Ces embeddings capturent les relations sémantiques et les similarités entre les objets, ce qui les rend plus adaptés aux tâches computationnelles. En traitement du langage naturel (NLP), les embeddings de mots, par exemple, projettent les mots d’un vocabulaire vers des vecteurs denses dans un espace de grande dimension, où les mots similaires sont proches les uns des autres.
Dans Llama 2, les embeddings jouent un rôle crucial dans la compréhension et la génération du langage naturel. Llama 2 utilise des embeddings pour représenter des mots, des expressions ou des phrases entières dans un espace vectoriel continu. Llama 2 peut traiter et générer efficacement du texte en intégrant les entrées et sorties linguistiques tout en capturant les relations sémantiques et les nuances.
Par exemple, Llama 2 apprend des embeddings pour les mots et les expressions à partir du vaste corpus de texte sur lequel il est entraîné pendant le processus d’entraînement. Ces embeddings encodent des informations sémantiques sur la langue, permettant à Llama 2 de comprendre et de générer des réponses cohérentes aux requêtes ou aux prompts.
Les embeddings en apprentissage automatique, y compris ceux utilisés dans Llama 2, facilitent la représentation du langage et d’autres données de manière structurée et sémantiquement significative, permettant un traitement, une compréhension et une génération efficaces du langage naturel.
Comment utiliser Llama 2 ?
Pour utiliser efficacement Llama 2, accédez au modèle via l’interface ou l’API fournie, en vous assurant que les autorisations sont en place. Préparez vos données d’entrée, qu’il s’agisse de texte, d’images ou de formats compatibles, et prétraitez-les si nécessaire. Spécifiez la tâche pour Llama 2, comme la génération de texte ou le résumé. Transmettez les données prétraitées à Llama 2, récupérez la sortie et évaluez sa qualité. Expérimentez avec différents formats et configurations pour optimiser les résultats. Surveillez les indicateurs de performance tels que la précision et la vitesse, en ajustant les stratégies en fonction des retours. Restez informé des améliorations pour maximiser l’efficacité, ouvrant de nouvelles possibilités pour les projets et les applications. Vous pouvez également utiliser Llama 2 avec des outils comme LangChain, LlamaIndex et Semantic Kernel lors de la création d’applications RAG.
Performance de Llama 2
La performance globale peut être évaluée en examinant certains benchmarks agrégés populaires. Voici un tableau des résultats de performance comparés à des modèles basés sur l’open source, comme indiqué dans l’article de Llama 2 :
| Modèle | Taille | Code | Raisonnement de bon sens | Connaissance du monde | Compréhension de lecture | Maths | MMLU | BBH | AGI Eval |
| MPT | 7B | 20.5 | 57.4 | 41.0 | 57.5 | 4.9 | 26.8 | 31.0 | 23.5 |
| 30B | 28.9 | 64.9 | 50.0 | 64.7 | 9.1 | 46.9 | 38.0 | 33.8 | |
| Falcon | 7B | 5.6 | 56.1 | 42.8 | 36.0 | 4.6 | 26.2 | 28.0 | 21.2 |
| 40B | 15.2 | 69.2 | 56.7 | 65.7 | 12.6 | 55.4 | 37.1 | 37.0 | |
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 | |
| 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 | |
| 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 | |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 | |
| 33B | 27.8 | 69.9 | 58.7 | 68.0 | 24.2 | 62.6 | 44.1 | 43.4 | |
| 65B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
Vous pouvez constater que Llama 2 surpasse Llama 1 dans un certain nombre de catégories comme MMLU et BBH, et obtient même de bons résultats face au modèle Falcon.
Llama 2 vs GPT 4
L’article Llama 2 couvre également quelques comparaisons avec Llama 2, GPT 4 et quelques autres, comme indiqué ci-dessous :
| Benchmark (shots) | GPT-3.5 | GPT-4 | PaLM | PaLM-2-L | Llama 2 |
| MMLU (5 shot) | 70.0 | 86.4 | 69.3 | 78.3 | 68.9 |
| TriviaQA (1-shot) | — | — | 81.4 | 86.1 | 85.3 |
| Natural Questions (1-shot) | — | — | 29.3 | 37.5 | 33.0 |
| GSM8K (8-shot) | 57.1 | 92.0 | 56.5 | 80.7 | 56.8 |
| HumanEval (0-shot) | 48.1 | 67.0 | 26.2 | — | 29.9 |
| BIG-Bench Hard (3-shot) | — | — | 52.3 | 65.7 | 51.2 |
- MMLU (5-shot) : Le modèle reçoit 5 passages ou exemples pour générer une réponse.
- TriviaQA (1-shot) : Un jeu de données où le modèle reçoit un seul contexte ou une seule question avant de générer une réponse.
- Natural Questions (1-shot) : Un autre jeu de données où le modèle reçoit une question en entrée.
- GSM8K (8-shot) : Un jeu de données où le modèle reçoit 8 passages ou exemples pour répondre à des questions ou effectuer des tâches.
- HumanEval (0-shot) : Un jeu de données ou un cadre d’évaluation où le modèle est évalué sur des tâches ou des questions sur lesquelles il n’a pas été explicitement entraîné, d’où « 0-shot ».
Zilliz fonctionne-t-il avec Llama 2 ?
Le cas d’utilisation le plus courant de Zilliz Cloud avec Llama 2 est le développement d’applications de génération augmentée par récupération (RAG). Les applications RAG exploitent les capacités des grands modèles de langage (LLMs) comme Llama 2, qui sont entraînés sur de vastes jeux de données mais fonctionnent intrinsèquement dans les limites de données finies. À lui seul, Llama 2 a tendance à « halluciner » des réponses, en générant des réponses même lorsqu’il pourrait ne pas y avoir suffisamment de contexte ou d’informations exactes. RAG est une façon de traiter cette hallucination.
La combinaison de Zilliz Cloud et de Llama 2 permet aux utilisateurs d’intégrer de manière fluide des capacités avancées de compréhension et de génération du langage avec des systèmes de récupération vectorielle efficaces et évolutifs fournis par Zilliz Cloud. En exploitant les forces des deux plateformes, les développeurs peuvent créer des applications sophistiquées qui excellent dans les tâches nécessitant un traitement complet du langage, une récupération d’informations et des fonctionnalités de génération.
Ressources clés
- Qu’est-ce que Llama 2 ?
- Architecture de Llama 2
- Qu’est-ce qu’un Embedding en Machine Learning?
- Comment utiliser Llama 2 ?
- Performance de Llama 2
- Llama 2 vs GPT 4
- Zilliz fonctionne-t-il avec Llama 2 ?
- Ressources clés
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement