




Comprendre la modélisation des données
Comprendre la modélisation des données
À une époque où les données constituent l'actif le plus précieux d'une entreprise, la collecte, le stockage et la gestion efficaces de données étendues sont essentiels pour garantir un avantage concurrentiel. Mais comment les entreprises créent-elles du sens à partir de sources de données disparates ? Comment savoir quelles données collecter et comment les stocker ?
La réponse réside dans une modélisation des données efficace - une technique qui permet aux développeurs de visualiser leur système de gestion des données. Elle les aide à comprendre quelles données ils doivent collecter et comment identifier les relations critiques entre plusieurs sources. Ce processus permet aux décideurs d'identifier les ensembles de données pertinents pour une prise de décision efficace.
Cet article explique la modélisation des données, son fonctionnement, ses techniques, ses processus, ses avantages, ses défis et les outils qui peuvent vous aider à rationaliser les flux de travail de modélisation.
Qu'est-ce que la modélisation des données ?
La modélisation des données permet de créer un plan représentant la structure des données d'une application ou d'un système. Le modèle de données est un diagramme illustrant les entités de données pertinentes, les objets, les relations et les schémas complexes de stockage.
Le modèle de données établit également des définitions de données, des glossaires et d'autres métadonnées cruciales pour aider les différentes parties prenantes à extraire des informations significatives pour des cas d'utilisation spécifiques. Les parties prenantes peuvent être des analystes de données, des développeurs et des administrateurs qui analysent, organisent et gèrent l'accès aux sources de données.
Une modélisation efficace des données garantit l'utilisation effective des données par les équipes en favorisant une compréhension commune des données, en éliminant les redondances et en minimisant les obstacles administratifs. Elle permet également aux organisations d'identifier et de résoudre les obstacles potentiels et les contraintes de conception pour construire un système de gestion des données évolutif.
Comment fonctionne la modélisation des données ?
Bien que les techniques de création d'un modèle de données puissent varier d'un cas à l'autre, elles comprennent généralement le développement d'une conception, d'un cadre logique et d'un modèle physique.
Conception
La conception est une abstraction qui permet de visualiser la structure globale des données. Il identifie la portée du projet et établit les exigences de haut niveau pour la création du système.
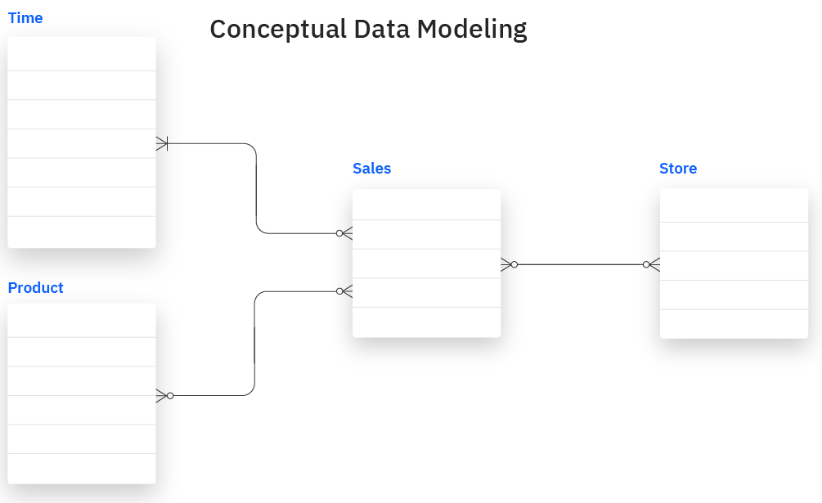
Le modèle conceptuel présente également les entités de données, les relations, les intégrations et les protocoles de sécurité pertinents pour les tâches d'analyse d'entreprise. Par exemple, le diagramme ci-dessous présente un modèle conceptuel simple d'un système de base de données de ventes.
 Conceptual Model.png
Conceptual Model.png
L'objectif est de répondre aux besoins des dirigeants d'entreprise en matière de données et de les aider à découvrir les éléments et les relations de données essentiels pour prendre des décisions efficaces fondées sur les données.
Cadre logique
Le cadre logique offre plus de détails en incluant les types de données, les identifiants uniques et les définitions. Il utilise des notations de données formelles pour marquer les relations entre les entités et permet aux utilisateurs de visualiser plus clairement les attributs et les relations entre les données.
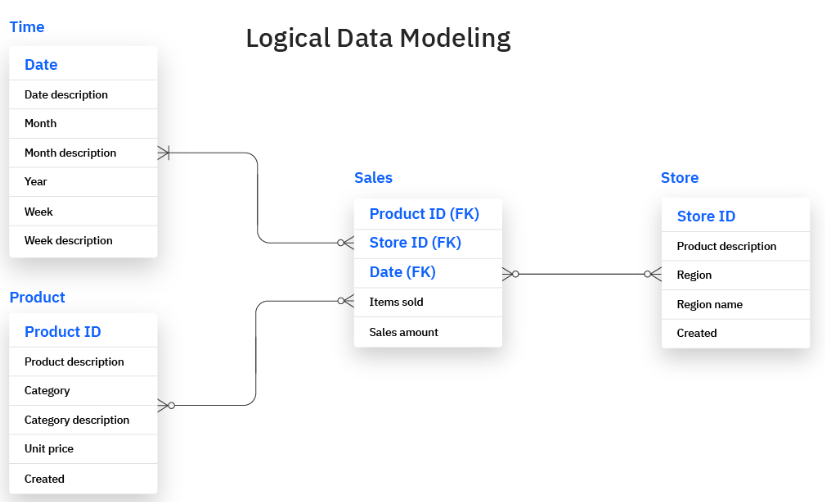
Par exemple, le cadre logique d'une base de données de ventes peut contenir les clés primaires qui relient les tables de produits et de ventes.
 Logical Framework.png
Logical Framework.png
Le modèle logique aide également les utilisateurs à déterminer la nature des informations requises dans chaque entité de données et les règles de mise en œuvre des structures de données.
Modèle physique des données
Le modèle physique des données est la dernière représentation la plus détaillée d'un système axé sur les données. Il comprend un schéma détaillé décrivant la manière dont le système stockera les données.
Par exemple, le modèle de données physique d'un système de base de données relationnelle comprendra les noms de chaque table, de chaque colonne et du type de données correspondant.
 Physical Data Model.png
Physical Data Model.png
Les modèles physiques sont spécifiques au système et changent en fonction du type de modèle que vous essayez de construire. La section suivante explique plus en détail les différents types de modèles de données.
Types de modèles de données
Avec le temps, des systèmes de gestion de bases de données (SGBD) plus complexes sont apparus en raison de l'augmentation des volumes de données. La diversité des architectures de SGBD a donné naissance à de nombreux types de modèles de données qui aident les organisations à concevoir des systèmes de gestion plus efficaces.
Bien que les types de modèles continuent d'évoluer, les modèles de données hiérarchiques, relationnels, entités-relations, orientés-objets et dimensionnels sont les plus répandus.
Modèles de données hiérarchiques
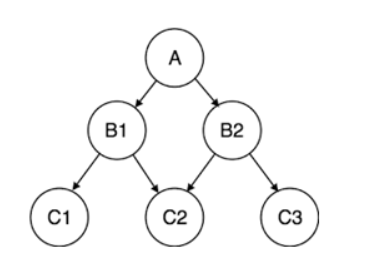
Le modèle de données hiérarchique organise les données dans une structure arborescente de type "un à plusieurs", avec un seul parent relié à plusieurs enregistrements enfants.
 Hierarchical Model.png
Hierarchical Model.png
Le système de gestion de l'information d'IBM (IMS) a été le premier à utiliser la structure hiérarchique introduite en 1966. Bien que ce modèle soit rare aujourd'hui, il est toujours utilisé pour organiser les données dans les fichiers XML (Extensible Markup Language) et les systèmes d'information géographique (SIG).
Modèles de données relationnelles
Les modèles de données relationnels, introduits par Edgar F. Codd, chercheur chez IBM, en 1970, sont plus polyvalents que les structures hiérarchiques. Ils organisent les données en tableaux avec des lignes et des colonnes, ce qui rend plus facile la découverte de multiples éléments de données et de relations.
| ID | Nom | Adresse |
| 125 | Nom 1 | Adresse 1 |
| 236 | Nom 2 | Adresse 2 |
Tableau : Modèle relationnel
Les modèles relationnels permettent aux utilisateurs de joindre plusieurs tables sur la base de clés primaires et de réduire la complexité des données. Le langage de requête structuré (SQL) est principalement utilisé pour manipuler et analyser les données dans les bases de données relationnelles.
Modèles de données entité-relation
Les modèles entité-relation (ER) organisent les attributs des données en fonction des entités et cartographient les relations entre plusieurs entités.
Par exemple, dans un SGBD de vente, un client est une entité dont les attributs peuvent inclure le nom du client, son adresse, ses coordonnées et d'autres caractéristiques. L'entité client peut être reliée à l'entité produit par le biais des articles achetés par un client donné.
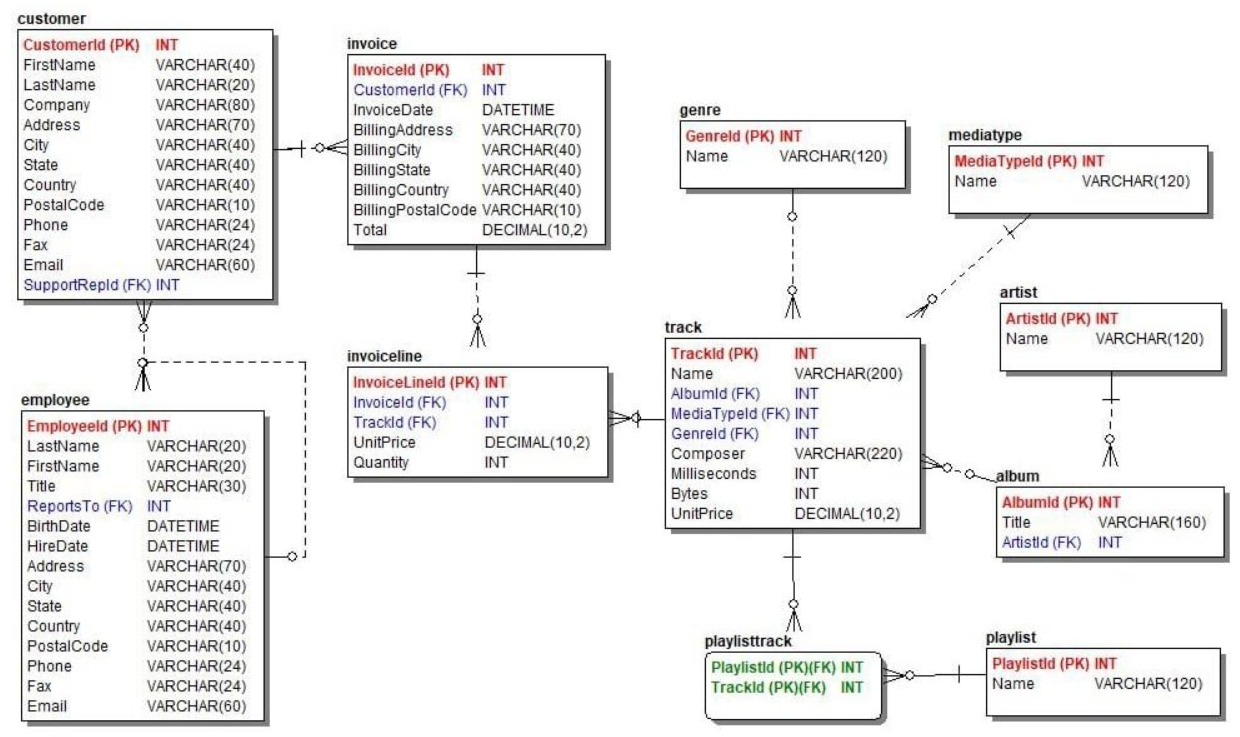 ER Model.png
ER Model.png
La structure est plus dynamique que les modèles relationnels car elle permet de capturer et d'analyser plus efficacement les données transactionnelles.
Modèles de données orientés objet
Les modèles de données orientés objet sont devenus populaires avec la programmation orientée objet, qui organise les objets de données en fonction de leurs attributs.
Les objets de données ayant des attributs similaires sont regroupés en classes. Les programmeurs peuvent créer de nouvelles classes qui peuvent hériter des attributs des classes précédentes.
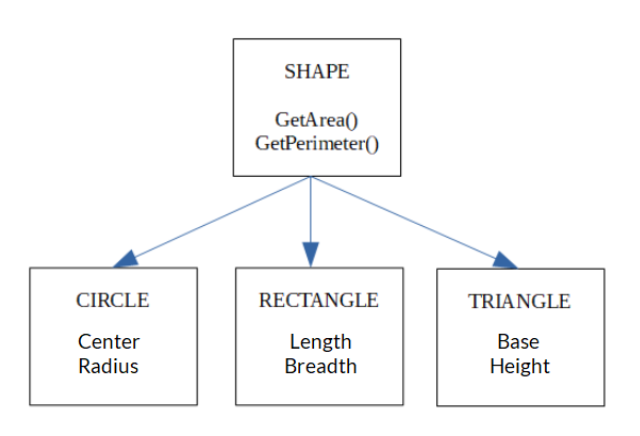 Modèle de données orienté objet- .png
Modèle de données orienté objet- .png
[Modèle de données orienté objet] (https://www.tutorialspoint.com/object-oriented-data-model)_ : Les objets CIRCLE, RECTANGLE et TRIANGLE héritent de l'objet FORME_ ___. Chaque forme a ses attributs.
Par exemple, dans un modèle de données orienté objet, les données relatives aux clients et aux employés peuvent appartenir à la même classe car elles ont des attributs identiques, tels que le nom, l'adresse et les coordonnées. Cela diffère des modèles ER, dans lesquels les clients et les employés sont des entités distinctes.
Modèles de données dimensionnels
Les modèles de données dimensionnelles organisent les entités de données sous forme de dimensions connectées à des fiches, ce qui améliore l'analyse dans les entrepôts de données et les marts. Une fiche d'information contient des données sur les événements, tandis que les dimensions contiennent des informations sur les entités apparaissant dans ces événements.
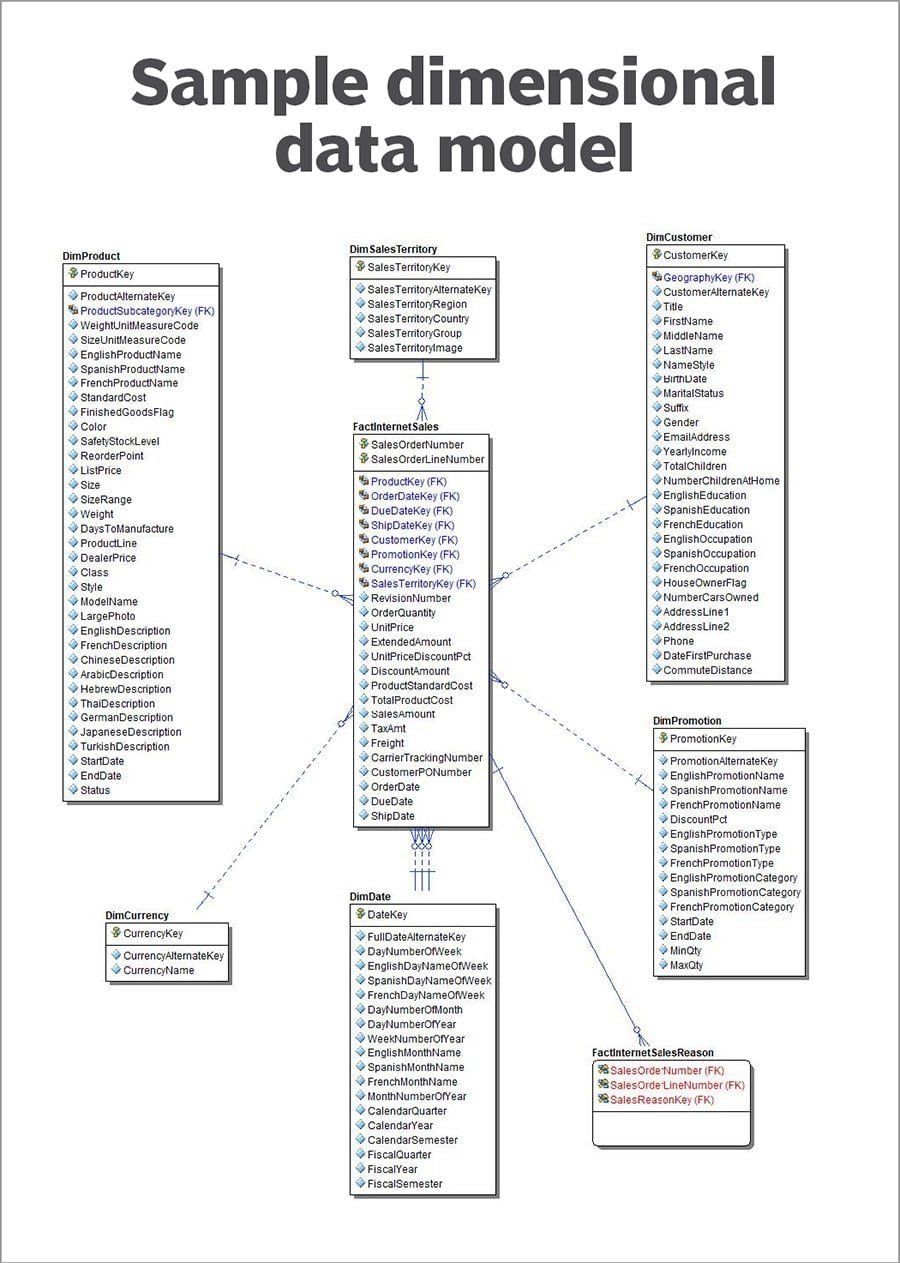 Modèle de données dimensionnelles- .jpg
Modèle de données dimensionnelles- .jpg
Modèle de données dimensionnelles_ : La fiche d'information sur les ventes est liée à plusieurs dimensions d'entités qui y figurent.
Par exemple, une fiche d'information peut être un tableau enregistrant les transactions quotidiennes de plusieurs clients. Toutefois, les utilisateurs peuvent trouver davantage d'informations sur chaque client ou produit dans les tables de dimensions stockant les données relatives aux clients ou aux produits.
Le schéma en étoile est une structure de données dimensionnelle célèbre dans laquelle une seule feuille de données est connectée à plusieurs dimensions. Une variante plus complexe est la structure en flocon de neige, dans laquelle de nombreuses tables de dimensions sont liées à plusieurs fiches.
Comparaison avec la conception de bases de données et l'ingénierie des données
Bien que la conception de bases de données et l'ingénierie des données soient des concepts similaires, ils diffèrent de la modélisation des données à plusieurs égards.
La modélisation des données par rapport à la conception de la base de données:** La modélisation des données est la phase initiale de la construction d'une base de données. La conception de la base de données est un processus moins abstrait qui détermine les exigences de mise en œuvre du modèle de données. Les développeurs étudient la structure de base de données la plus optimale pour améliorer l'évolutivité et l'intégrité des données. Par exemple, il peut s'agir du choix des clés primaires, des techniques d'indexation et de la conception du schéma.
La modélisation des données par rapport à l'ingénierie des données:** L'ingénierie des données est un concept plus large qui inclut le développement de pipelines de données automatisés pour traiter, transformer et déplacer les données entre plusieurs plateformes. Un modèle de données efficace peut aider à construire une conception de base de données robuste, aidant les développeurs à rationaliser les flux de travail d'ingénierie des données.
Processus de modélisation des données
La conception d'un modèle de données nécessite la contribution de plusieurs parties prenantes afin de comprendre le champ d'application, les objectifs et les contraintes en matière de ressources du système de base de données.
Les experts en données doivent sélectionner le type de modèle de données approprié pour représenter la structure de données nécessaire à un cas d'utilisation particulier. Ils doivent également déterminer les symboles et les conventions de notation nécessaires à la construction du modèle.
Bien que les processus de modélisation des données puissent varier en fonction des besoins de l'entreprise et de la nature des données, la liste suivante présente quelques étapes de la conception d'un modèle.
Identification des entités** : La première étape consiste à identifier les entités pertinentes que les données doivent inclure. Ces entités doivent s'exclure mutuellement et constituer la base de la conception du modèle.
Identification des attributs** : les développeurs doivent identifier les attributs propres à chaque entité. Par exemple, dans une base de données contenant les coordonnées bancaires des clients, les "comptes bancaires" peuvent constituer une entité distincte dotée d'attributs uniques tels que la nature du compte, le numéro de compte, la date de création, le montant initial déposé, etc.
Relations entre les entités:** Cartographier les relations entre plusieurs entités. Par exemple, l'entité "compte bancaire" peut être liée à l'entité "client", chaque client possédant un compte supplémentaire.
Attribution de clés primaires:** Les développeurs doivent attribuer des clés uniques aux entités pour représenter formellement leurs relations. Par exemple, le numéro de compte peut être une clé primaire qui relie l'entité "clients" à l'entité "comptes bancaires".
Création et finalisation du modèle de données:** Après avoir identifié toutes les entités, tous les attributs et toutes les relations avec les clés primaires, les développeurs peuvent déterminer le modèle de données approprié et finaliser la conception qui répond le mieux aux besoins de l'entreprise en matière de données.
Avantages de la modélisation des données
Un modèle de données est l'épine dorsale d'un système de gestion des données efficace. Il permet à de nombreuses parties prenantes d'utiliser les données afin de découvrir des informations précieuses pour la prise de décisions stratégiques.
La liste ci-dessous présente quelques avantages d'un modèle de données efficace.
Une meilleure communication:** Un modèle de données permet de communiquer plus facilement les flux de données et les concepts aux parties prenantes concernées.
Documentation cohérente:** Puisque le modèle de données fournit une visualisation standardisée de la structure globale des données, la documentation est plus cohérente, ce qui permet une conception plus robuste du système.
Amélioration de la collaboration entre les équipes:** Grâce à une compréhension commune des données, les équipes de plusieurs domaines peuvent collaborer plus efficacement sur les projets.
Une meilleure qualité des données:** Un modèle bien conçu garantit l'intégrité des données à travers les sources de données et permet aux utilisateurs de développer des flux de travail d'analyse de données rapides et efficaces.
Les défis de la modélisation des données
Bien que la modélisation des données offre de nombreux avantages, elle implique quelques défis de mise en œuvre. Comprendre ces obstacles et les moyens de les surmonter peut aider les entreprises à tirer plus rapidement parti de la modélisation des données.
Voici quelques défis auxquels les développeurs peuvent être confrontés lors de la conception d'un modèle de données.
Complexité croissante des données:** Les SGBD modernes doivent être dynamiques et répondre à l'évolution des besoins de l'entreprise et à la variété croissante des données. Cependant, prévoir les changements futurs est complexe et implique une spéculation considérable. La décomposition des modèles en composants plus petits et l'utilisation de normes industrielles peuvent contribuer à atténuer ces problèmes.
Convaincre l'équipe dirigeante des avantages d'un modèle de données peut s'avérer fastidieux. La conversation peut devenir trop abstraite pour les utilisateurs professionnels. Pour s'assurer du soutien de l'équipe de gestion des données, celle-ci doit s'adresser à la direction générale en lui présentant des buts et des objectifs clairs qui s'alignent sur la mission et la vision globales de l'entreprise.
La conception d'un modèle de données est un processus itératif qui peut nécessiter des changements de périmètre et d'objectifs. Cependant, des changements fréquents peuvent faire déraper la conception et augmenter les coûts de développement. L'identification et l'implication des parties prenantes dès le départ, ainsi que l'obtention d'un retour d'information régulier, peuvent aider à surmonter ces problèmes.
Outils de modélisation des données
Les développeurs peuvent utiliser des outils de modélisation des données pour créer rapidement des conceptions plus efficaces. Bien que de nombreux fournisseurs proposent des solutions de modélisation des données, le choix de celle qui répond le mieux aux besoins de votre entreprise demande du temps et des efforts. La liste ci-dessous présente quelques outils populaires qui peuvent vous aider à simplifier votre recherche.
Erwin Data Modeler: Aide à créer des schémas détaillés et à concevoir des visualisations prenant en charge plusieurs systèmes de base de données. Il dispose d'un système de contrôle des versions et permet aux utilisateurs d'inverser les modèles de données à partir des structures de données existantes.
DbSchema: Interface utilisateur intuitive qui permet aux utilisateurs d'interagir avec les modèles de données et de construire des requêtes visuellement sans utiliser de code.
ER/Studio: Prend en charge plusieurs systèmes de base de données, y compris les structures relationnelles et dimensionnelles. Il comprend des outils de collaboration qui permettent aux équipes de comprendre les données plus efficacement grâce à des flux d'activités et de discussions.
FAQ sur la modélisation des données
- **Quelle est la différence entre la modélisation des données et la conception de la base de données ?
La modélisation des données consiste à identifier les entités de données, les attributs et les relations entre les différentes entités. Elle permet de créer la structure globale de la manière dont une base de données stockera ces entités et dont les utilisateurs pourront exploiter les relations pour effectuer des analyses.
La conception de la base de données intervient après la finalisation du modèle de données et implique la mise en œuvre du modèle de données dans un système de gestion de base de données (SGBD). Elle comprend les techniques d'indexation, les noms de schémas et les structures de stockage.
- **Qu'est-ce que la normalisation dans la modélisation des données ?
La normalisation organise les données en groupes afin d'éliminer les redondances et d'améliorer la cohérence des données. Par exemple, considérons le tableau suivant dans un SGBD relationnel :
| Client | Article acheté | Prix | ||
| A | Téléphone | 200 $ | ||
| B | Ordinateur | $1500 | ||
| C - Chargeur | 50 $ | D - Téléphone - 200 $ | B - Ordinateur - 1500 $ | C - Chargeur - 50 |
| D | Téléphone | 200 $ |
Ici, l'utilisateur supprimera le prix d'un article s'il souhaite supprimer l'enregistrement d'un client particulier. La normalisation permet de séparer les données sur les clients des informations sur les prix en créant deux tables.
Ce processus garantit la cohérence des données et permet à l'utilisateur de manipuler les données avec plus de souplesse sans modifier la structure globale des informations.
- **Comment concevoir des modèles de données pour les données non structurées ?
Les [données non structurées] (https://zilliz.com/glossary/unstructured-data) comprennent les images, les vidéos et les données textuelles. Les modèles pour les ensembles de données non structurées nécessitent des techniques différentes, car leur représentation est plus complexe que les schémas traditionnels.
Les développeurs peuvent utiliser des bases de données vectorielles pour stocker et développer des modèles de données pour les ensembles de données non structurées. Les bases de données utilisent des algorithmes d'intelligence artificielle (IA) pour convertir les échantillons de données en [embeddings] (https://zilliz.com/learn/everything-you-should-know-about-vector-embeddings), des représentations vectorisées de chaque point de données. Chaque élément du vecteur correspond à un attribut particulier de l'échantillon de données.
Une fois les échantillons sous forme de vecteurs, les utilisateurs peuvent calculer des mesures de similarité pour évaluer la similarité entre différents points de données. Ils peuvent utiliser les scores de similarité pour organiser les données en groupes et développer des modèles représentant les relations entre eux.
- **Quelles sont les erreurs courantes à éviter dans la modélisation des données ?
Les développeurs compliquent souvent à l'excès le modèle et n'impliquent pas les parties prenantes concernées dans la phase de conception. En outre, l'inclusion d'entités de données inutiles et l'absence de prise en compte des contraintes de performance sont des erreurs fréquentes qui réduisent l'efficacité du modèle de données.
- **Comment choisir le bon outil de modélisation des données ?
Vous devez tenir compte des facteurs suivants lorsque vous investissez dans une solution de modélisation des données :
Facilité d'utilisation
Systèmes de base de données pris en charge
Fonctions de visualisation
Outils de collaboration
Évolutivité
Prix
Ressources connexes
Pour en savoir plus sur les techniques de gestion et de modélisation des données non structurées, consultez les articles suivants.
Introduction aux données non structurées](https://zilliz.com/learn/introduction-to-unstructured-data)
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ?](https://zilliz.com/learn/what-is-vector-database)
[Comprendre les bases de données vectorielles] (https://zilliz.com/learn/comparing-vector-database-vector-search-library-and-vector-search-plugin)
Techniques de modélisation des données pour les bases de données vectorielles
- Qu'est-ce que la modélisation des données ?
- Comment fonctionne la modélisation des données ?
- Types de modèles de données
- Modèles de données dimensionnels
- Comparaison avec la conception de bases de données et l'ingénierie des données
- Processus de modélisation des données
- Avantages de la modélisation des données
- Les défis de la modélisation des données
- Outils de modélisation des données
- FAQ sur la modélisation des données
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement