




Moyenne mobile intégrée autorégressive (ARIMA)

Moyenne mobile intégrée autorégressive (ARIMA)
Vous êtes-vous déjà demandé comment les entreprises prédisent avec précision la demande de produits pour les saisons à venir et optimisent leurs lancements ? C’est là qu’ARIMA entre en jeu. ARIMA est un modèle statistique qui prévoit les valeurs futures de séries temporelles en analysant les tendances passées.
Discutons de l’importance, des avantages et des défis d’ARIMA en examinant son fonctionnement.
Qu’est-ce qu’ARIMA ?
La moyenne mobile intégrée autorégressive (ARIMA) est un modèle statistique populaire pour la prévision des séries temporelles. Il utilise les données historiques pour comprendre les tendances d’un jeu de données et prévoir les valeurs futures. Le modèle utilise trois composantes pour prédire les valeurs futures : l’autorégression (AR), la différenciation (I) et la moyenne mobile (MA). Chaque composante façonne les prédictions du modèle en décrivant une relation entre les valeurs passées et futures.
Voici ce que fait chaque composante :
Autorégression (p) : AR suppose que la valeur future dépend de la valeur passée. L’ordre AR fait référence au nombre de valeurs passées que le modèle utilise pour prédire la valeur actuelle. Par exemple, si l’ordre AR est 3, le modèle prédit la valeur actuelle sur la base des trois valeurs passées les plus récentes.
Différenciation/ Intégration (d) : Cela détermine le degré de différenciation requis pour rendre une série temporelle stationnaire. Dans les séries temporelles non stationnaires, où les propriétés statistiques comme la moyenne et la variance changent au fil du temps, l’application de la différenciation aide à stabiliser la série.
Moyenne mobile (q) : MA capture la relation entre la valeur actuelle d’une série temporelle et les erreurs de prévision passées. L’ordre MA reflète la relation entre la valeur actuelle de la série temporelle et les erreurs de prévision passées. Par exemple, MA(2) ou MA d’ordre 2 calcule la moyenne pondérée des deux erreurs passées pour prédire la valeur actuelle.
Mathématiquement, le modèle ARIMA est représenté comme ARIMA (p, d, q) et exprimé ainsi :
y′t=I+α1y′t−1+α2y′t−2+⋯+αpy′t−p+et+θ1et−1+θ2et−2+⋯+θqet−q
Où :
Yt : La valeur actuelle de la série temporelle
c : Terme constant
φ₁, φ₂, ..., φp : Coefficients autorégressifs
θ₁, θ₂, ..., θq : Coefficients de moyenne mobile
εt : Terme d’erreur bruitée
p : L’ordre de l’autorégression
q : L’ordre de la moyenne mobile
d : L’ordre de différenciation/ intégration
Cela représente le fait que la valeur actuelle de la série temporelle différenciée (y′t) est une combinaison linéaire de ses valeurs passées (y′t-₁, y′t-₂, ..., y′t-p) et des termes d’erreur passés (et-₁, et-₂, ..., et-q).
Comment fonctionne ARIMA ?
L’autocorrélation et les moyennes mobiles sont des composantes essentielles des modèles ARIMA. L’autocorrélation aide à identifier les relations directes entre les valeurs passées et actuelles, tandis que les moyennes mobiles aident à prendre en compte les effets indirects des erreurs de prévision passées.
Voici une explication étape par étape de la manière dont elles fonctionnent ensemble :
Stationnarité
La première étape de la prévision des séries temporelles avec les modèles ARIMA consiste à s’assurer que la série temporelle est stationnaire. Comme les données non stationnaires peuvent entraîner des prévisions inexactes et des résultats de modèle biaisés, ARIMA repose sur l’hypothèse de stationnarité. Si les données de la série temporelle ne sont pas stationnaires, ARIMA applique la différenciation pour les rendre stationnaires. Cela consiste à soustraire la valeur précédente de la valeur actuelle. L’ordre de différenciation (d) détermine le nombre de fois où ce processus est répété.
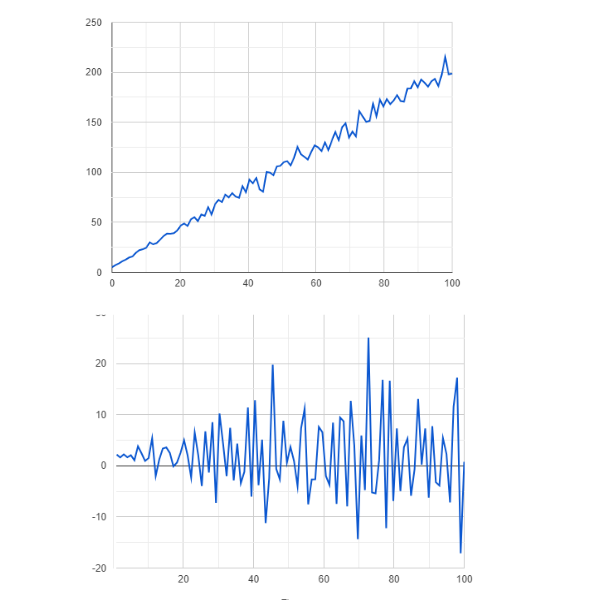 Figure- Données non stationnaires vs stationnaires .png
Figure- Données non stationnaires vs stationnaires .png
Figure : Données non stationnaires vs stationnaires
Identification du modèle
L’identification du modèle détermine les valeurs appropriées pour les composantes autorégressive (p) et de moyenne mobile (q). La fonction d’autocorrélation (ACF) et la fonction d’autocorrélation partielle (PACF) sont des outils essentiels pour ce processus :
Fonction d’autocorrélation
La fonction d’autocorrélation identifie l’ordre de la composante autorégressive (AR) (p). Si elle montre une corrélation au décalage k, cela suggère que la valeur actuelle est liée à la valeur d’il y a k périodes, où k représente le nombre de décalages (pas de temps) entre la valeur actuelle et une valeur précédente dans la série temporelle.
Fonction d’autocorrélation partielle
La fonction d’autocorrélation partielle (PACF) identifie l’ordre de la composante de moyenne mobile (MA) (q). Si elle montre une corrélation significative au décalage k, cela indique que la valeur actuelle est liée à l’erreur de prévision qui s’est produite il y a k périodes.
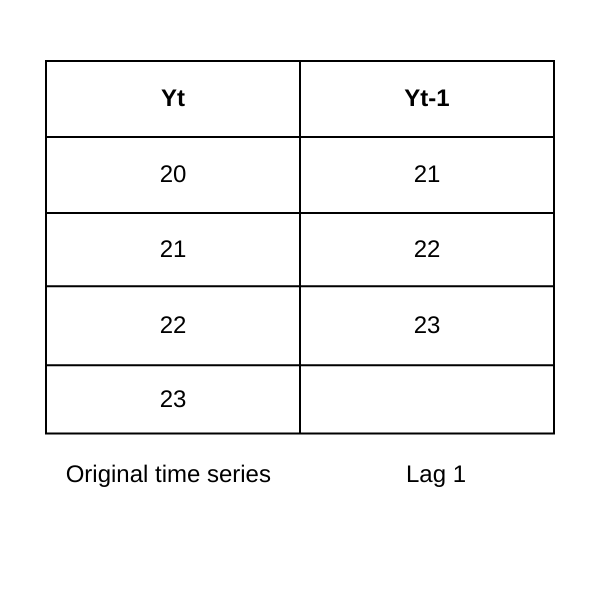 Figure- Lag-1 autocorrelation.png
Figure- Lag-1 autocorrelation.png
Figure : Autocorrélation au décalage 1
Estimation du modèle
Après avoir déterminé les ordres autorégressifs (AR) et les composantes de moyenne mobile (MA), ARIMA estime les paramètres du modèle. Les paramètres du modèle quantifient la force des relations entre la valeur actuelle et ses valeurs passées (AR), ainsi qu’entre la valeur actuelle et les erreurs passées (MA).
L’estimation du maximum de vraisemblance (MLE) est la méthode la plus courante pour l’estimation des paramètres dans les modèles ARIMA. La MLE estime les paramètres du modèle en trouvant les valeurs qui maximisent la vraisemblance d’observer les données données. Pour les modèles ARIMA, la fonction de vraisemblance repose généralement sur l’hypothèse que les erreurs sont distribuées normalement. Les moindres carrés et les méthodes bayésiennes sont d’autres approches pour l’estimation des paramètres dans les modèles ARIMA.
Prévision du modèle
Le modèle ARIMA estimé prédit finalement les valeurs futures à partir des données historiques. Si nécessaire, le modèle peut également être affiné en ajustant les ordres des composantes AR et MA ou en prenant en compte d’autres facteurs comme la saisonnalité.
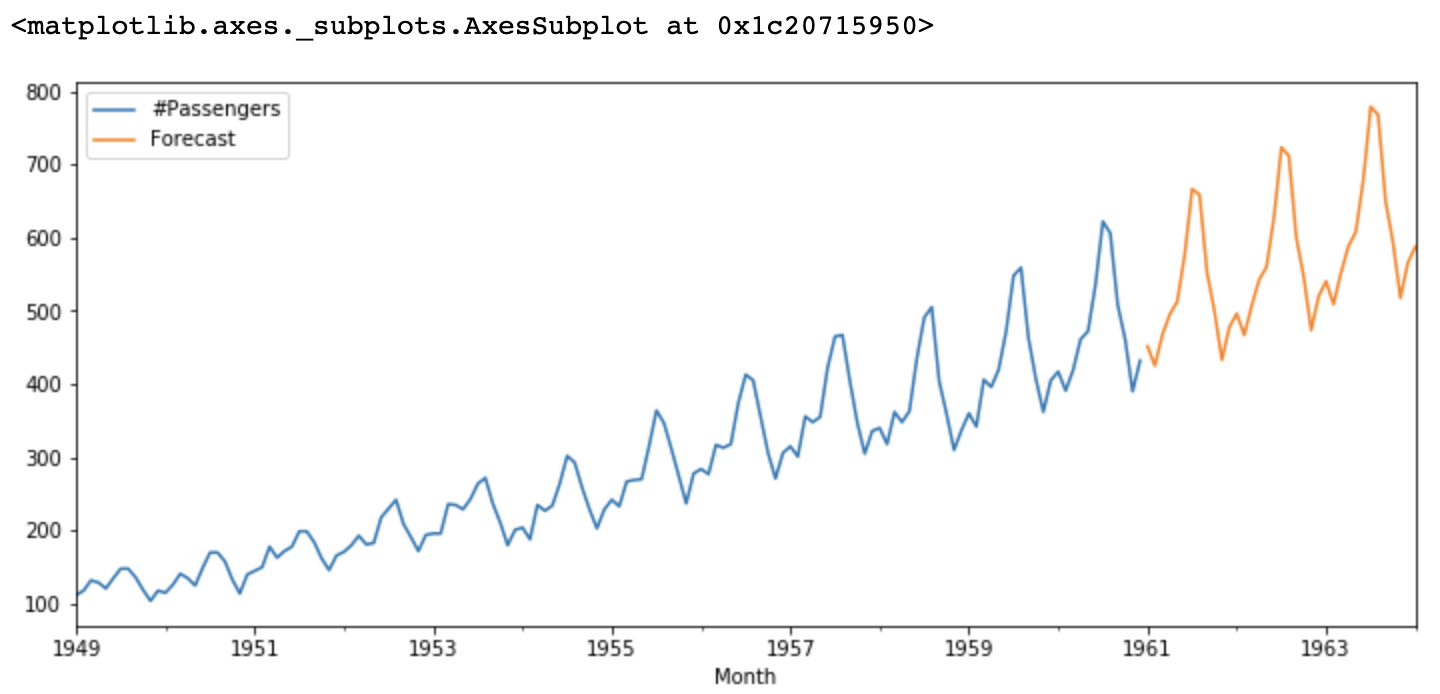 Figure- ARIMA forecasts.png
Figure- ARIMA forecasts.png
Figure : Prévisions ARIMA
Comparaison avec des concepts similaires
ARIMA est souvent comparé à d’autres concepts similaires dans le contexte de l’analyse de données et de la prévision. Voici une comparaison pour dissiper les malentendus courants :
ARIMA vs. SARIMA : SARIMA (Seasonal ARIMA) est une extension d’ARIMA qui intègre spécifiquement la saisonnalité dans l’analyse des données de séries temporelles. ARIMA est un modèle statistique pour les données de séries temporelles sans motif saisonnier clair.
ARIMA vs. Lissage exponentiel : ARIMA et le lissage exponentiel sont des méthodes de prévision des séries temporelles. ARIMA utilise des techniques statistiques pour modéliser les schémas sous-jacents, y compris les tendances, la saisonnalité et l’autocorrélation. Le lissage exponentiel, en revanche, applique une méthode plus simple de moyenne pondérée, dans laquelle les observations récentes reçoivent plus de poids que les anciennes. Alors qu’ARIMA est mieux adapté aux données présentant des schémas complexes, le lissage exponentiel fonctionne bien pour les séries temporelles avec une tendance relativement stable et une saisonnalité minimale, ce qui le rend moins adaptable aux données complexes.
ARIMA vs. Vector Autoregression (VAR) : VAR convient à la prévision de séries temporelles multivariées où plusieurs variables s’influencent mutuellement. ARIMA convient aux séries temporelles univariées et nécessite de différencier la série pour atteindre la stationnarité.
Avantages et défis d’ARIMA
ARIMA offre plusieurs avantages, ce qui en fait l’un des modèles de prévision de séries temporelles les plus largement utilisés. Cependant, il comporte également certains défis, qui nécessitent de prendre en compte les propriétés et les objectifs spécifiques de votre analyse avant d’appliquer ARIMA.
Avantages
Les avantages de l’utilisation des modèles ARIMA pour la prévision des séries temporelles comprennent :
Flexibilité : ARIMA peut gérer un large éventail de données de séries temporelles, notamment les tendances linéaires et non linéaires, les schémas saisonniers, la volatilité et l’autocorrélation. Cela lui permet de traiter les caractéristiques courantes des séries temporelles du monde réel, telles que les indicateurs économiques et les schémas non linéaires dans les prix des actions.
Simplicité : Les modèles ARIMA sont faciles à comprendre en raison de leur fonctionnement simple et de leurs hypothèses transparentes. Ils peuvent gérer de longues séries temporelles avec un nombre relativement important d’observations.
Précision : La précision des modèles ARIMA dépend de la qualité des données. Par conséquent, prendre en compte les hypothèses et choisir des modèles appropriés conduit à des résultats précis.
Interprétabilité : Les paramètres du modèle ARIMA ont des interprétations claires, notamment les coefficients autorégressifs et de moyenne mobile. Ces coefficients donnent un aperçu de la manière dont les valeurs passées et les erreurs affectent les valeurs futures.
Large applicabilité : Les modèles ARIMA sont largement utilisés dans tous les secteurs pour des applications de prévision telles que la modélisation financière, la prévision de la demande et la prévision de charge. Par conséquent, ils sont intégrés dans de nombreux langages de programmation et bénéficient d’une large communauté de partisans.
Fondement pour d’autres modèles : Les modèles ARIMA constituent un fondement pour des modèles de séries temporelles plus complexes tels que SARIMA et ARIMAX. En tenant compte de facteurs supplémentaires, ils contribuent à améliorer la précision des prévisions au-delà des valeurs historiques de la série temporelle.
Défis
Les défis des modèles ARIMA incluent :
Hypothèse de stationnarité : Le ****modèle ARIMA suppose que la série temporelle est stationnaire ; sinon, il transforme les données pour atteindre la stationnarité. Cependant, de nombreux ensembles de données réels sont non stationnaires, et leur prétraitement peut compliquer le processus de modélisation.
Relations linéaires : ARIMA est un modèle linéaire et ne peut pas capturer les relations non linéaires complexes dans les données. Par conséquent, il pourrait ne pas capturer avec précision les changements soudains dans les données causés par des crises économiques, des chocs externes, etc.
Identification du modèle : Les performances du modèle ARIMA dépendent du choix des paramètres appropriés (p, d, q). Cependant, cela nécessite souvent des méthodes d’essais et d’erreurs ou de recherche par grille et peut conduire à un surajustement ou à un sous-ajustement.
Sensibilité aux valeurs aberrantes : Les modèles ARIMA peuvent être sensibles aux valeurs aberrantes, ce qui peut affecter leurs performances. Par conséquent, un prétraitement soigneux des données est nécessaire pour obtenir les résultats souhaités.
Prévision à long terme : ARIMA n’est pas bien adapté à la prévision à long terme. Cela s’explique par le fait que les modèles ARIMA sont basés sur des schémas passés et peuvent ne pas capturer correctement les événements imprévus ou les changements structurels dans le processus de génération des données.
Cas d’utilisation, outils et fournisseurs d’ARIMA
Les modèles ARIMA sont largement appliqués à la prévision et à l’analyse des séries temporelles dans divers domaines. Cela inclut l’économie et la finance, la prévision de la demande, la planification de la production et des capacités, les soins de santé, etc.
Par exemple, des modèles ARIMA ont été utilisés pour prévoir la propagation des cas de COVID-19 en Inde. Les chercheurs ont entraîné les modèles ARIMA en utilisant les données quotidiennes des cas de COVID-19 du 14 mars au 3 mai 2020, ce qui a donné une précision satisfaisante.
De nombreux langages de programmation et packages statistiques fournissent des outils pour mettre en œuvre les modèles ARIMA. Ils incluent :
R
R dispose de capacités étendues d’analyse des séries temporelles, notamment la modélisation ARIMA. Plusieurs bibliothèques, notamment stats, forecast et tseries, offrent des fonctions pour implémenter le modèle ARIMA dans R.
Python
Python offre également de vastes bibliothèques statistiques pour implémenter ARIMA. Certaines d’entre elles incluent Statsmodels, Numpy et Pandas.
MATLAB
MATLAB est un logiciel commercial de calcul mathématique avec des fonctions intégrées pour la modélisation ARIMA. Il permet également l’intégration avec d’autres outils logiciels et langages de programmation afin de combiner la modélisation ARIMA avec d’autres flux de travail.
FAQ sur ARIMA
À quoi sert ARIMA ?
AutoRegressive Integrated Moving Average (ARIMA) est un modèle statistique utilisé pour l’analyse et la prévision des séries temporelles. C’est une méthode populaire pour prédire les valeurs futures d’une série temporelle sur la base de ses valeurs passées.
En quoi ARIMA diffère-t-il des autres modèles de prévision des séries temporelles ?
ARIMA diffère des autres modèles de prévision de séries temporelles par sa flexibilité, son interprétabilité et sa large applicabilité. ARIMA peut capturer un large éventail de motifs dans les données de séries temporelles, notamment les tendances, la saisonnalité et l’autocorrélation. Les paramètres d’un modèle ARIMA ont des interprétations claires, et ils peuvent servir de référence pour la comparaison avec des modèles plus complexes.
Comment interpréter les prévisions ARIMA ?
Les prévisions ARIMA sont généralement interprétées comme des estimations ponctuelles des valeurs futures attendues de la série temporelle. Diverses métriques, telles que l’erreur quadratique moyenne (MSE), l’erreur absolue moyenne (MAE) et la racine de l’erreur quadratique moyenne (RMSE), peuvent être utilisées pour évaluer la précision des prévisions.
Quelles sont les hypothèses du modèle ARIMA ?
Voici les hypothèses du modèle ARIMA :
Stationnarité : Les propriétés statistiques des séries temporelles (moyenne, variance, autocorrélation) doivent rester constantes au fil du temps.
Linéarité : ARIMA suppose une relation linéaire entre la valeur actuelle et ses valeurs passées et erreurs.
Normalité : Les erreurs sont supposées être distribuées normalement.
Absence d’autocorrélation dans les erreurs : Les erreurs sont supposées être non corrélées.
Ressources connexes
En savoir plus sur le stockage et le prétraitement des données de séries temporelles :
- Qu’est-ce qu’ARIMA ?
- Comment fonctionne ARIMA ?
- Comparaison avec des concepts similaires
- Avantages et défis d’ARIMA
- Cas d’utilisation, outils et fournisseurs d’ARIMA
- FAQ sur ARIMA
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement