




Exa construit un moteur de recherche d’entités pour les agents IA avec Zilliz Cloud
<200 ms de latence de recherche
La latence de recherche neuronale d’Exa réduite de quelques secondes à moins de 200 ms grâce à la recherche hybride de Zilliz
Haute fiabilité
Quasi zéro incident opérationnel, libérant du temps d’ingénierie pour le travail produit
Zéro interruption de service pour les changements de schéma
De nouveaux champs filtrables et métadonnées peuvent être ajoutés sans reconstruire les index ni mettre les collections hors ligne
We believe AI agents will become a fundamental interface for how people work, learn, and make decisions, and that only happens if those systems can access real-world information with speed, precision, and trust. That’s what we’re building at Exa. Aside from web search, Exa also operates entity search, and Zilliz Cloud has been an important part of that journey, giving us the retrieval performance and operational simplicity we need to scale our entity search product quickly and confidently.
Jeffrey Wang
La recherche pour les agents IA ressemble à une extension naturelle de la recherche web, mais en pratique, elle exige un standard produit différent. Les agents n’ont pas seulement besoin de liens ; ils ont besoin d’informations ancrées, actuelles et structurées, fournies assez rapidement pour prendre en charge de vrais workflows, des interactions vocales aux tâches de recherche approfondie.
Exa construit exactement ce type de moteur de recherche pour l’IA. Son Search API donne aux développeurs accès à une recherche web de haute qualité et à faible latence sur un large éventail de latences de calcul, de la recherche instantanée pour les agents vocaux à la recherche plus approfondie avec des sorties structurées et des enrichissements. Exa sert des clients allant de startups AI-native telles que Cursor et Lovable à des entreprises comme AWS, qui s’appuient toutes sur un contexte ancré et réel pour des workflows pilotés par des agents.
Alors qu’Exa s’étend à la recherche d’entités pour les entreprises, les personnes et le code, elle a été confrontée à un défi d’infrastructure plus spécialisé : comment prendre en charge la récupération hybride, le filtrage riche par métadonnées, les mises à jour fréquentes et une latence de l’ordre de la milliseconde sans détourner l’attention de l’ingénierie du moteur de recherche principal. C’est le rôle précis que Zilliz Cloud (Milvus entièrement managé) joue dans l’histoire ci-dessous.
| Latence de recherche faible de 200 ms | Recherche hybride combinant vecteurs denses, vecteurs creux, reranking RRF et filtres de métadonnées dans un seul appel API. Exa Instant a réduit la latence de recherche neuronale de plusieurs secondes à moins de 200 ms |
| Haute fiabilité | Le service managé a fourni des incidents opérationnels quasi nuls, libérant du temps d’ingénierie pour le travail produit |
| Zéro temps d’arrêt pour les changements de schéma | De nouveaux champs filtrables et de nouvelles métadonnées peuvent être ajoutés sans reconstruire les index ni mettre les collections hors ligne |
Ci-dessous se trouve le script d’une conversation avec Exa au sujet de sa mission produit, du passage de la recherche web générale à la recherche d’entités, et de la façon dont Zilliz Cloud s’inscrit dans cette évolution.
1. La promesse produit d’Exa : une recherche ancrée pour les agents IA
Nous avons commencé par demander à Exa de décrire le produit qu’elle construit et les clients qu’elle sert, car ce contexte explique pourquoi la qualité de la récupération et la latence ne sont pas des préoccupations secondaires pour l’entreprise.
Q : Quel produit ou service Exa fournit-elle, et qui sont vos principaux clients ?
Exa : Exa construit le moteur de recherche pour l’IA. Nous avons créé une API de recherche qui permet aux développeurs d’accéder à une recherche web de haute qualité et à faible latence à travers leurs agents. Notre API offre une recherche couvrant tout le spectre de la latence de calcul, des recherches instantanées (<200 ms) pour les agents vocaux à la recherche approfondie avec des sorties structurées et des enrichissements. Nous sommes spécialisés dans la recherche de code, la faible latence et la recherche de personnes/entreprises, avec des extraits qui garantissent l’efficacité en tokens.
Nous avons construit notre moteur de recherche de zéro en utilisant de nouvelles architectures neuronales, plutôt que de nous appuyer sur des moteurs de recherche hérités. Construire son propre moteur de recherche exige tout, de l’entraînement de modèles d’embeddings et de rerankers à l’exploration et l’indexation de milliards de pages web. Cette maîtrise de bout en bout nous permet d’optimiser chaque couche de la stack pour la qualité et la vitesse. Lors du récent lancement d’Exa Instant, par exemple, nous avons atteint une latence de recherche <200 ms — une amélioration significative qui rend la recherche neuronale viable comme primitive en temps réel pour les agents IA. La combinaison de la qualité, de la vitesse et de la personnalisabilité est un différenciateur clé.
Nos clients vont d’entreprises AI-native comme Cursor et Lovable à de grandes entreprises. Toute entreprise utilisant des agents pour piloter le travail de connaissance a besoin d’un contexte ancré pour répondre au monde réel ; ainsi, quelle que soit la taille de l’entreprise, nous travaillons avec des équipes qui donnent la priorité aux workflows pilotés par des agents.
2. Le point d’inflexion : de la recherche web à la recherche d’entités
Ce contexte produit clarifie aussi pourquoi la décision d’Exa concernant la base de données ne consistait pas à remplacer sa stack de recherche principale. La recherche vectorielle était déjà fondamentale pour l’entreprise. Le véritable changement est survenu lorsque la recherche d’entités a introduit de nouvelles contraintes.
Q : À quel moment de votre parcours produit avez-vous réalisé que vous aviez besoin d’une base de données vectorielle ?
Exa : Étant donné que notre moteur de recherche reposait sur les embeddings et la similarité vectorielle, la recherche vectorielle a toujours fait partie intégrante de la stack technique d’Exa. À mesure que nous nous sommes étendus à la recherche d’entités, nous avons dû mettre à jour notre infrastructure de base de données vectorielle afin de prendre en charge les sorties structurées et les enrichissements que nous proposions désormais.
La recherche d’entités nécessite des schémas de métadonnées riches, des mises à jour fréquentes des données et une scalabilité gérée. Notre base de données interne était optimisée pour ces nouvelles contraintes, mais nous voulions encore améliorer la vitesse d’itération sur cette couche de recherche d’entités, ce qui nous a conduits à utiliser Zilliz Cloud. Notre index web principal reste sur notre infrastructure interne, et Zilliz Cloud a été introduit spécifiquement pour alimenter cette couche de recherche d’entités.
Q : Quels défis ou exigences rencontriez-vous avec votre solution précédente ?
Exa : Lorsque nous avons commencé à construire la recherche d’entités, les exigences étaient très différentes : recherche hybride combinant vecteurs denses et clairsemés, schémas de métadonnées riches et fréquemment modifiés, et charge opérationnelle liée à la gestion de plusieurs collections spécialisées. Nous recherchions une solution gérée qui permette à nos ingénieurs d’itérer rapidement et de fournir des réponses rapides à grande échelle.
Q : Quel(s) cas d’usage spécifique(s) résolvez-vous avec la recherche vectorielle/base de données vectorielle ?
Exa : Aujourd’hui, Zilliz Cloud alimente notre couche de recherche d’entités, servant à la fois d’index principal et de cache de récence pour les collections d’entités, tandis que notre index web principal fonctionne sur une infrastructure interne distincte. Chaque vertical exige une recherche filtrée à faible latence sur des données fréquemment mises à jour, où les capacités de récupération hybride gérée et de hot-upsert de Zilliz maintiennent la fraîcheur des résultats sans reconstruire les index. Ces verticaux alimentent directement notre Search API, la vitesse et le rappel sont donc essentiels pour l’activité.
3. Ce dont Exa avait besoin d’une couche de récupération vectorielle gérée
Une fois que la recherche d’entités est devenue une couche distincte, l’évaluation portait réellement sur l’adéquation : un système géré pouvait-il soutenir le niveau d’exigence d’Exa en matière de qualité de recherche sans ralentir l’équipe ni imposer de compromis architecturaux ?
Q : Quelles bases de données vectorielles avez-vous évaluées avant de choisir Zilliz Cloud ? Quels étaient les critères clés de votre évaluation ?
Exa : Lorsque nous avons commencé à construire la recherche d’entités, les exigences étaient très différentes : recherche hybride combinant vecteurs denses et clairsemés, schémas de métadonnées riches et fréquemment modifiés, et charge opérationnelle liée à la gestion de plusieurs collections spécialisées. Nous recherchions une solution gérée qui permette à nos ingénieurs d’itérer rapidement et de fournir des réponses rapides à grande échelle.
Nous avons étudié toutes les principales options de bases de données vectorielles du marché. Nos critères clés étaient :
Prise en charge de la recherche hybride : capacité native à combiner des vecteurs sémantiques denses avec des vecteurs de mots-clés clairsemés dans une seule requête, avec reranking intégré
Latence des requêtes : réponses rapides et constantes sur des collections contenant des dizaines de millions de vecteurs
Filtrage riche des métadonnées : filtres complexes sur des champs structurés sans dégrader les performances de recherche
Scalabilité : mise à l’échelle fluide à mesure que nous ajoutons de nouveaux verticaux et de nouvelles sources de données
Zilliz Cloud cochait toutes les cases, et ses performances sur les benchmarks de recherche hybride étaient clairement en avance sur le marché.
Q : Comment avez-vous entendu parler de Zilliz Cloud / Milvus pour la première fois ?
Exa : Nous connaissions Milvus depuis longtemps, car c’est l’une des bases de données vectorielles open source les plus matures, et pour une équipe qui vit et respire la recherche vectorielle, il est difficile de passer à côté. Lorsque nous avons commencé à définir le périmètre de notre infrastructure de recherche d’entités, Zilliz Cloud s’est imposé comme l’offre gérée naturelle au-dessus de Milvus, avec des améliorations de performance de niveau entreprise.
Q : Qu’est-ce qui vous a marqué chez Zilliz Cloud pendant votre évaluation ? Quelles sont les principales raisons qui vous ont conduits à choisir Zilliz Cloud ?
Exa : Quelques éléments se sont immédiatement démarqués.
Recherche hybride native : Zilliz Cloud prend en charge la recherche vectorielle dense et clairsemée en un seul appel API, avec des stratégies de reclassement intégrées (RRF, pondérée). C’était une exigence incontournable pour plusieurs concurrents, et nous ne la prenions pas en charge nativement.
Performance à grande échelle - leur moteur d’indexation Cardinal offre des temps de requête constamment rapides, même lorsque nos collections atteignent des centaines de millions de vecteurs.
Filtrage mature - la capacité de combiner la recherche vectorielle avec des filtres de métadonnées complexes dans une seule requête, sans chute de performance.
En ce qui concerne les facteurs décisifs pour l’adoption :
Vitesse - la latence des requêtes de Zilliz Cloud répondait à nos exigences strictes pour la recherche en production. Nos utilisateurs s’attendent à obtenir des résultats en quelques millisecondes, et Zilliz est capable de prendre cela en charge.
Capacités de recherche hybride - la capacité de fusionner la recherche sémantique dense avec la correspondance par mots-clés clairsemée BM25 et d’appliquer un reclassement Reciprocal Rank Fusion (RRF) en un seul appel API était importante pour la qualité de la recherche.
Simplicité opérationnelle - en tant que service entièrement géré, Zilliz Cloud permet à notre équipe de se concentrer sur la création de meilleures expériences de recherche et d’itérer rapidement sur les améliorations apportées à l’infrastructure de base de données vectorielle à grande échelle.
4. Comment l’architecture de Zilliz et Exa s’articule
Q : Comment Zilliz Cloud s’intègre-t-il dans votre architecture ?
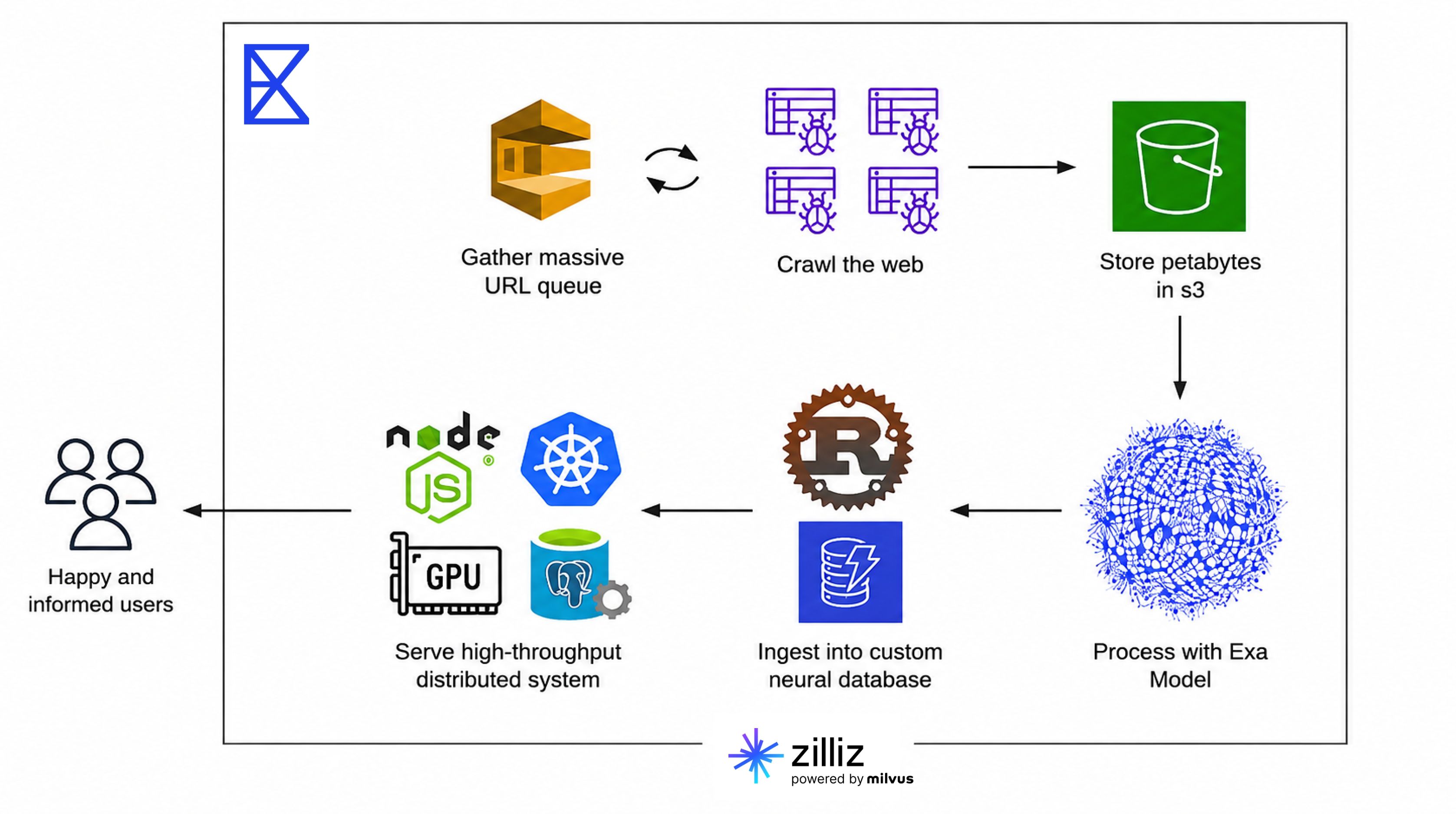
Exa : Notre architecture de recherche d’entités comprend trois couches : ingestion, recherche et API.
Lors de l’ingestion, nous enrichissons et vectorisonsons les données d’entités à l’aide de nos propres pipelines de ML, puis effectuons des upserts de vecteurs denses et clairsemés dans Zilliz Cloud.
Dans la recherche, notre backend génère des embeddings à partir des requêtes des utilisateurs et envoie des requêtes de recherche hybride à Zilliz Cloud, combinant correspondance sémantique et par mots-clés avec reclassement RRF.
Dans la couche API, les résultats sont enrichis avec des métadonnées structurées et servis via notre Search API et notre produit Websets. Zilliz Cloud se trouve au cœur de la récupération pour ce flux de travail : il stocke tous les vecteurs d’entités et les métadonnées et gère la recherche à faible latence. Notre index web principal est construit et géré sur une infrastructure interne distincte.
Q : Quelle a été l’expérience de votre équipe avec Zilliz Cloud ou Milvus ?
Exa : L’API est intuitive, la documentation est solide, et le système s’est avéré fiable en production. La courbe d’apprentissage a été minimale, car les concepts de Milvus : collections, index, paramètres de recherche, correspondent bien à notre manière de concevoir déjà la recherche vectorielle. La nature gérée de Zilliz Cloud signifie que nous avons eu très peu d’incidents opérationnels à traiter.
Q : Comment s’est passée l’intégration de Zilliz Cloud avec AWS ou d’autres services cloud ?
Exa : Sans accroc. Nous exécutons notre infrastructure principalement sur AWS, et Zilliz Cloud s’intègre proprement à cette pile native AWS. Comme il fonctionne sur AWS, la latence réseau entre nos services EKS et Zilliz Cloud est minimale.
5. Ce qui a changé après l’adoption
Q : Quels sont les 3 principaux avantages que vous avez constatés ? Pouvez-vous partager des indicateurs ou améliorations mesurables ?
Exa : Le premier avantage a été la vélocité des développeurs : le service géré et l’API claire ont permis à notre équipe de lancer rapidement de nouveaux verticaux de recherche d’entités sans construire ni gérer d’infrastructure supplémentaire.
Au-delà de cela, la flexibilité et l’adaptabilité du schéma ont beaucoup compté à mesure que ces jeux de données verticaux évoluent, et la qualité de la recherche via autoindex s’est également révélée précieuse dans la pratique.
Q : Quelles fonctionnalités de Zilliz Cloud trouvez-vous les plus précieuses ?
Exa : Deux éléments se démarquent le plus dans l’utilisation quotidienne.
Filtrage sans chute de performance : Filtres de métadonnées complexes superposés à la recherche vectorielle avec un impact négligeable sur la latence.
Lancements rapides de verticaux : La mise à l’échelle gérée nous permet de lancer rapidement de nouveaux verticaux de recherche sans déployer une nouvelle infrastructure à chaque fois.
Démarrer avec Zilliz Cloud
Zilliz est le créateur de Milvus, la base de données vectorielle open source la plus populaire au monde, et de Zilliz Cloud, le service de base de données vectorielle entièrement géré, conçu sur Milvus. Zilliz Cloud permet aux organisations de créer des applications d’IA prêtes pour la production avec une recherche vectorielle haute performance, une récupération hybride, ainsi qu’une sécurité et une conformité de niveau entreprise.
- Démarrez gratuitement avec Zilliz Cloud avec 100 $ de crédits lors de l’inscription avec une adresse e-mail professionnelle
- 1. La promesse produit d’Exa : une recherche ancrée pour les agents IA
- 2. Le point d’inflexion : de la recherche web à la recherche d’entités
- 3. Ce dont Exa avait besoin d’une couche de récupération vectorielle gérée
- 4. Comment l’architecture de Zilliz et Exa s’articule
- 5. Ce qui a changé après l’adoption
- Démarrer avec Zilliz Cloud
Contenu
Cas d'usage
Secteur d'activité
Infrastructure d’IA