




Comment Airtable a construit et fait évoluer son infrastructure vectorielle avec Milvus

Requêtes à faible latence
des performances prévisibles sont essentielles pour la confiance des utilisateurs
Écritures à haut débit
les bases changent constamment, et les embeddings doivent rester synchronisés
Scalabilité horizontale
le système doit prendre en charge des millions de bases indépendantes
Cet article a été initialement publié sur le Medium d’Airtable et est republié ici avec autorisation.
À mesure que la recherche sémantique chez Airtable est passée du concept à une fonctionnalité produit centrale, l’équipe Data Infrastructure a dû relever le défi de sa mise à l’échelle. Comme détaillé dans notre article précédent sur la création du système d’embeddings, nous avions déjà conçu une couche applicative robuste, à cohérence éventuelle, pour gérer le cycle de vie des embeddings. Mais une pièce essentielle manquait encore à notre diagramme d’architecture : la base de données vectorielle elle-même.
Nous avions besoin d’un moteur de stockage capable d’indexer et de servir des milliards d’embeddings, de prendre en charge une multi-location massive, et de maintenir les objectifs de performance et de disponibilité dans un environnement cloud distribué. Voici l’histoire de la manière dont nous avons architecturé, renforcé et fait évoluer notre plateforme de recherche vectorielle pour en faire un pilier central de la pile d’infrastructure d’Airtable.
Contexte
Chez Airtable, notre objectif est d’aider les clients à travailler avec leurs données de manière puissante et intuitive. Avec l’émergence de LLMs de plus en plus puissants et précis, les fonctionnalités qui exploitent le sens sémantique de vos données sont devenues essentielles à notre produit.
Comment nous utilisons la recherche sémantique
Omni (le chat IA d’Airtable) répond à de vraies questions à partir de grands jeux de données
Imaginez poser une question en langage naturel à votre base (base de données) contenant un demi-million de lignes, et obtenir une réponse correcte, riche en contexte. Par exemple :
« Que disent les clients à propos de l’autonomie de la batterie ces derniers temps ? »
Sur de petits jeux de données, il est possible d’envoyer toutes les lignes directement à un LLM. À grande échelle, cela devient rapidement irréalisable. Nous avions donc besoin d’un système capable de :
- Comprendre l’intention sémantique d’une requête
- Récupérer les lignes les plus pertinentes via une recherche de similarité vectorielle
- Fournir ces lignes comme contexte à un LLM
Cette exigence a façonné presque toutes les décisions de conception qui ont suivi : Omni devait donner une impression d’instantanéité et d’intelligence, même sur de très grandes bases.
Recommandations d’enregistrements liés : le sens plutôt que les correspondances exactes
La recherche sémantique améliore également une fonctionnalité centrale d’Airtable : les enregistrements liés. Les utilisateurs ont besoin de suggestions de relations fondées sur le contexte plutôt que sur des correspondances textuelles exactes. Par exemple, une description de projet peut impliquer une relation avec « Team Infrastructure » sans jamais utiliser cette expression précise.
Fournir ces suggestions à la demande nécessite une récupération sémantique de haute qualité avec une latence cohérente et prévisible.
Nos priorités de conception
Pour prendre en charge ces fonctionnalités et bien d’autres, nous avons articulé le système autour de 4 objectifs :
- Requêtes à faible latence (500 ms p99) : des performances prévisibles sont essentielles à la confiance des utilisateurs
- Écritures à haut débit : les bases changent constamment, et les embeddings doivent rester synchronisés
- Scalabilité horizontale : le système doit prendre en charge des millions de bases indépendantes
- Auto-hébergement : toutes les données client doivent rester au sein de l’infrastructure contrôlée par Airtable
Ces objectifs ont façonné chaque décision architecturale qui a suivi.
Évaluation des fournisseurs de bases de données vectorielles
Fin 2024, nous avons évalué plusieurs options de bases de données vectorielles et avons finalement choisi Milvus sur la base de trois exigences clés.
- Premièrement, nous avons privilégié une solution auto-hébergée afin de garantir la confidentialité des données et de conserver un contrôle fin de notre infrastructure.
- Deuxièmement, notre charge de travail intensive en écritures et nos schémas de requêtes en rafales nécessitaient un système capable de se mettre à l’échelle de manière élastique tout en maintenant une latence faible et prévisible.
- Enfin, notre architecture exigeait une forte isolation entre des millions de tenants clients.
Milvus s’est imposé comme le meilleur choix : sa nature distribuée prend en charge une multi-location massive et nous permet de mettre à l’échelle l’ingestion, l’indexation et l’exécution des requêtes indépendamment, en offrant des performances tout en gardant les coûts prévisibles.
Conception de l’architecture
Après avoir choisi une technologie, nous avons ensuite dû déterminer une architecture pour représenter la forme de données unique d’Airtable : des millions de « bases » distinctes appartenant à différents clients.
Le défi du partitionnement
Nous avons évalué deux stratégies principales de partitionnement des données :
Option 1 : partitions partagées
Plusieurs bases partagent une partition, et les requêtes sont limitées en filtrant sur un identifiant de base. Cela améliore l’utilisation des ressources, mais introduit une surcharge de filtrage supplémentaire et rend la suppression des bases plus complexe.
Option 2 : une base par partition
Chaque base Airtable est mappée à sa propre partition physique dans Milvus. Cela offre une isolation forte, permet une suppression de base rapide et simple, et évite l’impact sur les performances du filtrage après requête.
Stratégie finale
Nous avons choisi l’option 2 pour sa simplicité et sa forte isolation. Cependant, les premiers tests ont montré que la création de 100 000 partitions dans une seule collection Milvus entraînait une dégradation significative des performances :
- La latence de création des partitions est passée de ~20 ms à ~250 ms
- Les temps de chargement des partitions ont dépassé 30 secondes
Pour y remédier, nous avons plafonné le nombre de partitions par collection. Pour chaque cluster Milvus, nous créons 400 collections, chacune avec au plus 1 000 partitions. Cela limite le nombre total de bases par cluster à 400 000, et de nouveaux clusters sont provisionnés à mesure que des clients supplémentaires sont intégrés.
Indexation et rappel
Le choix de l’index s’est révélé être l’un des compromis les plus déterminants de notre système. Lorsqu’une partition est chargée, son index est mis en cache en mémoire ou sur disque. Afin de trouver un équilibre entre le taux de rappel, la taille de l’index et les performances, nous avons évalué plusieurs types d’index.
- IVF-SQ8 : Offrait une faible empreinte mémoire mais un rappel plus faible.
- HNSW : Offre le meilleur rappel (99 %-100 %) mais est gourmand en mémoire.
- DiskANN : Offre un rappel similaire à HNSW mais avec une latence de requête plus élevée
En fin de compte, nous avons choisi HNSW pour son rappel supérieur et ses caractéristiques de performance.
La couche applicative
À un niveau élevé, le pipeline de recherche sémantique d’Airtable implique deux flux principaux :
- Flux d’ingestion : Convertir les lignes Airtable en embeddings et les stocker dans Milvus
- Flux de requête : Encoder les requêtes utilisateur, récupérer les identifiants de lignes pertinents et fournir du contexte au LLM
Les deux flux doivent fonctionner en continu et de manière fiable à grande échelle, et nous les détaillons ci-dessous. Nous les détaillons ci-dessous.
Flux d’ingestion : maintenir Milvus synchronisé avec Airtable
Lorsqu’un utilisateur ouvre Omni, Airtable commence à synchroniser sa base avec Milvus. Nous créons une partition, puis traitons les lignes par lots, en générant des embeddings et en effectuant des upserts dans Milvus. À partir de ce moment-là, nous capturons toute modification apportée à la base, puis ré-encodons et effectuons des upserts de ces lignes afin de maintenir la cohérence des données.
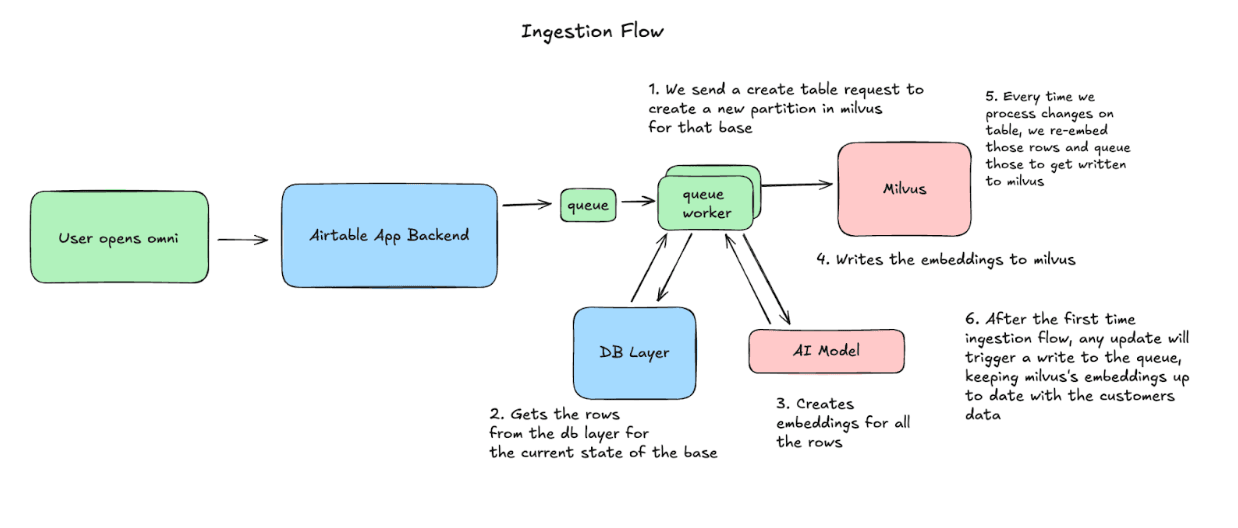
Flux de requête : comment nous utilisons les données
Côté requête, nous encodons la demande de l’utilisateur et l’envoyons à Milvus afin de récupérer les identifiants de lignes les plus pertinents. Nous récupérons ensuite les dernières versions de ces lignes et les incluons comme contexte dans la requête adressée au LLM.
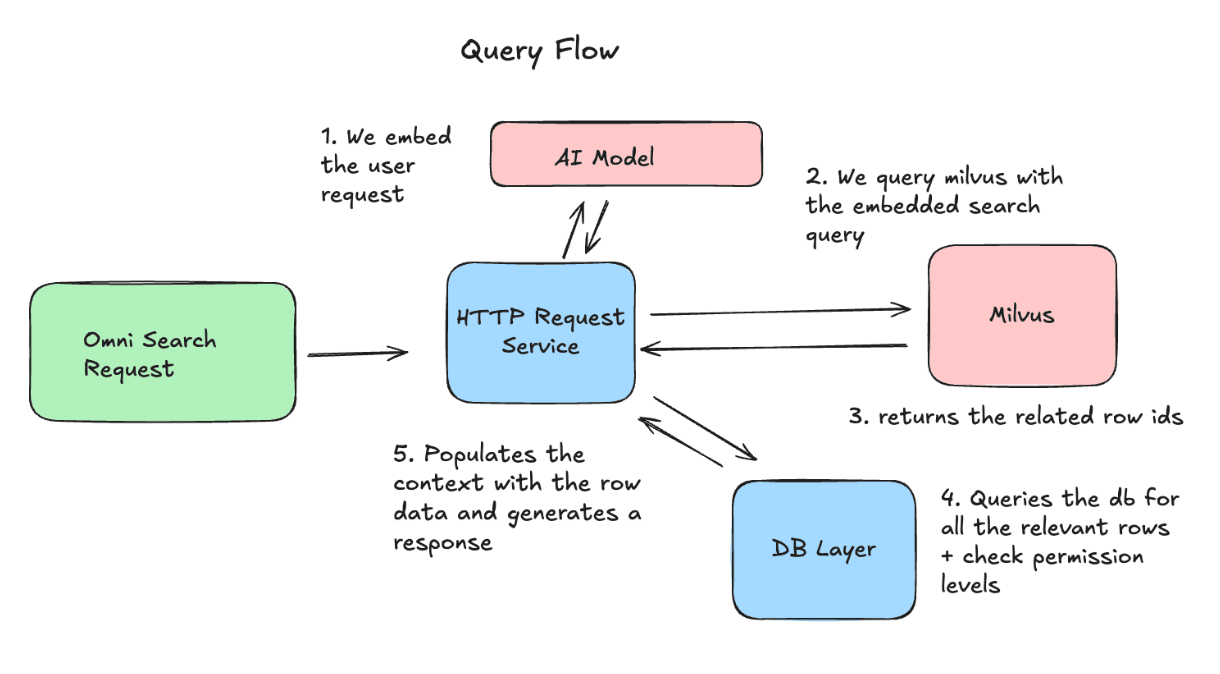
Défis opérationnels et comment nous les avons résolus
Construire une architecture de recherche sémantique est un défi ; l’exécuter de manière fiable pour des centaines de milliers de bases en est un autre. Voici quelques enseignements opérationnels clés que nous avons tirés en cours de route.
Déploiement
Nous déployons Milvus via son CRD Kubernetes avec le Milvus operator, ce qui nous permet de définir et de gérer les clusters de manière déclarative. Chaque changement, qu’il s’agisse d’une mise à jour de configuration, d’une amélioration du client ou d’une mise à niveau de Milvus, passe par des tests unitaires et un test de charge à la demande qui simule le trafic de production avant le déploiement auprès des utilisateurs.
Dans la version 2.5, le cluster Milvus est composé de ces composants principaux :
- Les Query Nodes conservent les index vectoriels en mémoire et exécutent les recherches vectorielles
- Les Data Nodes gèrent l’ingestion et la compaction, et persistent les nouvelles données dans le stockage
- Les Index Nodes construisent et maintiennent les index vectoriels pour que la recherche reste rapide à mesure que les données augmentent
- Le Coordinator Node orchestre toute l’activité du cluster et l’affectation des shards
- Les Proxy nodes acheminent le trafic d’API et équilibrent la charge entre les nœuds
- Kafka fournit la dorsale de journalisation/streaming pour la messagerie interne et le flux de données
- Etcd stocke les métadonnées du cluster et l’état de coordination
Avec une automatisation pilotée par les CRD et un pipeline de tests rigoureux, nous pouvons déployer des mises à jour rapidement et en toute sécurité.
Observabilité : comprendre l’état du système de bout en bout
Nous surveillons le système à deux niveaux pour garantir que la recherche sémantique reste rapide et prévisible.
Au niveau de l’infrastructure, nous suivons l’utilisation du CPU et de la mémoire, ainsi que l’état des pods dans tous les composants Milvus. Ces signaux nous indiquent si le cluster fonctionne dans des limites sûres et nous aident à détecter des problèmes tels que la saturation des ressources ou des nœuds défaillants avant qu’ils n’affectent les utilisateurs.
Au niveau de la couche de service, nous nous concentrons sur la capacité de chaque base à suivre le rythme de nos charges de travail d’ingestion et de requêtes. Des métriques comme le débit de compaction et d’indexation nous donnent de la visibilité sur l’efficacité de l’ingestion des données. Les taux de réussite et la latence des requêtes nous donnent une compréhension de l’expérience utilisateur lors de l’interrogation des données, et la croissance des partitions nous indique comment nos données augmentent, afin que nous soyons alertés si nous devons monter en charge.
Rotation des nœuds
Pour des raisons de sécurité et de conformité, nous procédons régulièrement à la rotation des nœuds Kubernetes. Dans un cluster de recherche vectorielle, ce n’est pas trivial :
- À mesure que les query nodes sont renouvelés, le coordinateur rééquilibre les données en mémoire entre les query nodes
- Kafka et Etcd stockent des informations avec état et nécessitent un quorum et une disponibilité continue
Nous y répondons avec des budgets de perturbation stricts et une politique de rotation d’un nœud à la fois. Le coordinateur Milvus dispose de temps pour rééquilibrer avant que le nœud suivant ne soit renouvelé. Cette orchestration minutieuse préserve la fiabilité sans ralentir notre vélocité.
Déchargement des partitions froides
L’un de nos plus grands gains opérationnels a été de reconnaître que nos données présentent des schémas d’accès clairement chauds/froids. En analysant l’utilisation, nous avons constaté que seulement environ 25 % des données dans Milvus sont écrites ou lues au cours d’une semaine donnée. Milvus nous permet de décharger des partitions entières, libérant ainsi de la mémoire sur les Query Nodes. Si ces données sont nécessaires plus tard, nous pouvons les recharger en quelques secondes. Cela nous permet de conserver les données chaudes en mémoire et de décharger le reste, réduisant les coûts et nous permettant de monter en charge plus efficacement au fil du temps.
Récupération des données
Avant de déployer largement Milvus, nous devions avoir confiance dans notre capacité à récupérer rapidement après tout scénario de panne. Si la plupart des problèmes sont couverts par la tolérance aux pannes intégrée du cluster, nous avons également prévu les rares cas où les données pourraient être corrompues ou où le système pourrait entrer dans un état irrécupérable.
Dans ces situations, notre chemin de récupération est simple. Nous lançons d’abord un nouveau cluster Milvus afin de pouvoir reprendre le service du trafic presque immédiatement. Une fois le nouveau cluster opérationnel, nous ré-embeddons de manière proactive les bases les plus couramment utilisées, puis traitons paresseusement le reste à mesure qu’elles sont consultées. Cela minimise les temps d’arrêt pour les données les plus consultées, tandis que le système reconstruit progressivement un index sémantique cohérent.
Et ensuite
Notre travail avec Milvus a posé des bases solides pour la recherche sémantique chez Airtable : alimenter des expériences d’IA rapides et pertinentes à grande échelle. Avec ce système en place, nous explorons désormais des pipelines de récupération plus riches et des intégrations d’IA plus profondes dans l’ensemble du produit. Il y a beaucoup de travaux passionnants à venir, et nous ne faisons que commencer.
Merci à tous les Airtablets passés et présents de l’infrastructure de données et de toute l’organisation qui ont contribué à ce projet : Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
À propos d’Airtable
Airtable est une plateforme d’opérations numériques de premier plan qui permet aux organisations de créer des applications personnalisées, d’automatiser les workflows et de gérer des données partagées à l’échelle de l’entreprise. Conçue pour prendre en charge des processus complexes et transverses, Airtable aide les équipes à créer des systèmes flexibles pour la planification, la coordination et l’exécution à partir d’une source de vérité partagée. Alors qu’Airtable développe sa plateforme alimentée par l’IA, des technologies comme Milvus jouent un rôle important dans le renforcement de l’infrastructure de récupération nécessaire pour offrir des expériences produit plus rapides et plus intelligentes.
- Contexte
- Comment nous utilisons la recherche sémantique
- Nos priorités de conception
- Évaluation des fournisseurs de bases de données vectorielles
- Conception de l’architecture
- Le défi du partitionnement
- Indexation et rappel
- La couche applicative
- Flux d’ingestion : maintenir Milvus synchronisé avec Airtable
- Flux de requête : comment nous utilisons les données
- Défis opérationnels et comment nous les avons résolus
- Observabilité : comprendre l’état du système de bout en bout
- Rotation des nœuds
- Déchargement des partitions froides
- Récupération des données
- Et ensuite
- À propos d’Airtable
Contenu
Cas d'usage
Secteur d'activité
SaaS d’IA