




Présentation de Loon : un nouveau moteur de stockage pour les données vectorielles qui ne cessent jamais de changer
Points clés à retenir
Il s’agit d’une exploration technique longue et approfondie, voici donc les points clés avant d’entrer dans les détails.
- Les jeux de données d’IA ne sont pas des tables statiques. Les mêmes lignes continuent de changer à mesure que les équipes remplacent les modèles d’embedding, ajoutent des vecteurs creux, révisent les légendes, complètent les étiquettes, reconstruisent les index et exécutent des analyses hors ligne.
- Les agencements de stockage traditionnels se dégradent de trois manières : les longues colonnes vectorielles rendent les backfills coûteux, un format de fichier unique ne peut pas bien servir à la fois les scans et les lectures ponctuelles, et le stockage privé des bases de données oblige les pipelines externes à créer des copies supplémentaires de la source de vérité.
- Loon est le nouveau moteur de stockage pour Milvus et Zilliz Vector Lakebase. Il est construit autour de formats de fichiers hybrides, de l’alignement des ID de ligne et d’un Manifest qui définit l’état versionné du jeu de données.
- L’objectif est de permettre à un seul jeu de données vectoriel de prendre en charge la recherche en ligne, l’analyse hors ligne, les backfills, la compaction et le calcul externe sans devoir constamment copier, réécrire ou réimporter les données.
Introduction
Pendant un certain temps, il existait un argument contre les bases de données vectorielles qui semblait raisonnable.
Les bases de données traditionnelles stockent déjà des entiers, des chaînes, du JSON, des blobs et des index. Pourquoi ne pas ajouter un type _vector_ , construire un index ANN à côté, et s’arrêter là ?
Pour la recherche sémantique initiale, cela fonctionne assez bien. Une colonne vectorielle plus un index peuvent prendre en charge une démo, une petite application RAG ou une fonctionnalité de recherche interne. Le problème apparaît plus tard, lorsque le jeu de données commence à se comporter moins comme une table et davantage comme un système de données d’IA.
Un jeu de données vectoriel de production possède des lignes, des clés primaires, des champs scalaires et des colonnes interrogeables. En ce sens, il ressemble à une table de base de données. Mais il a aussi l’échelle et la forme de workflow d’un data lake. Il peut contenir des centaines de millions d’enregistrements. Il est lu et réécrit à plusieurs reprises par Spark, Ray, DuckDB, des pipelines d’entraînement, des tâches d’évaluation et des systèmes de qualité des données.
Il dépend également du stockage objet. Les objets sources sont souvent des vidéos, des images, des PDF, des fichiers audio ou des documents web qui restent dans S3, GCS, OSS ou un autre stockage objet. La base de données stocke des références, des métadonnées, des caractéristiques dérivées et des index. Puis elle ajoute des éléments que les modèles de stockage traditionnels n’ont pas été conçus pour gérer comme des objets de première classe : embeddings denses, vecteurs creux, légendes, index vectoriels, index textuels, journaux de suppression, statistiques, versions de modèles, versions de parseurs, références à des blobs externes et relations de version entre tous ces éléments.
C’est là que “simplement ajouter une colonne vectorielle” commence à se dégrader. Le problème n’est pas de savoir si une base de données peut stocker des octets vectoriels. De nombreux systèmes le peuvent. La question plus difficile est de savoir si le modèle de stockage peut gérer la manière dont les données vectorielles changent, dont elles sont interrogées et dont elles sont partagées dans la pile de données d’IA.
C’est pourquoi nous avons construit Loon, le nouveau moteur de stockage pour Milvus et Zilliz Vector Lakebase (la prochaine évolution de Zilliz Cloud).
Loon est conçu autour de trois idées :
- Utiliser différents formats physiques pour différents types de colonnes.
- Aligner ces colonnes grâce à un espace d’ID de ligne partagé.
- Utiliser un Manifest pour définir l’état versionné du jeu de données.
Pour comprendre pourquoi ces éléments sont importants, commençons par un workflow multimodal courant.
Un jeu de données vectoriel n’est jamais vraiment terminé.
Imaginez une équipe d’IA construisant un jeu de données vidéo pour l’entraînement multimodal.
Une longue vidéo est téléversée dans un stockage objet. Un pipeline la découpe en clips en fonction des changements de scène, des limites de plans ou de fenêtres temporelles. Les clips trop longs ou trop courts, flous, dupliqués ou de faible qualité sont filtrés. Les clips restants sont notés par un modèle esthétique, légendés par un autre modèle, encodés en embeddings par un modèle vision-langage, et stockés dans une base de données vectorielle pour la recherche, la déduplication et le filtrage des données d’entraînement.
À haut niveau, le workflow paraît simple :
video
→ clips
→ metadata
→ aesthetic_score
→ caption
→ embedding
→ search / dedup / training data filtering
Mais le jeu de données n’arrive pas entièrement formé.
- La première semaine, la table peut ne contenir que
clip_id,video_id,start_offsetetduration. - La deuxième semaine, l’équipe ajoute
aesthetic_score. - La troisième semaine, un modèle de sous-titrage s’exécute, et chaque clip reçoit une
caption. - La quatrième semaine, le premier modèle d’embedding est mis en ligne, et chaque clip reçoit un embedding CLIP à 768 dimensions.
- Un mois plus tard, l’équipe change de modèles et effectue un backfill de
embedding_v2, désormais avec 1024 dimensions. - Deux mois plus tard, la recherche hybride devient une exigence, l’équipe ajoute donc une colonne de vecteur creux.
- Trois mois plus tard, les légendes font l’objet d’une revue humaine et doivent être corrigées sur place.
Le jeu de données n’a jamais été achevé. Il a continué à accumuler de nouvelles interprétations des mêmes lignes sous-jacentes.
C’est l’une des différences fondamentales entre les données vectorielles et les données métier traditionnelles. La même ligne est retraitée encore et encore. Et le passage à l’échelle transforme cela d’un inconvénient en problème de stockage : les jeux de données multimodaux ne comptent souvent pas des millions d’enregistrements, mais des centaines de millions ou des milliards. LAION-5B est une référence utile pour en comprendre la forme — des milliards de paires image-texte, chacune avec des métadonnées, des légendes et des embeddings. La partie difficile n’est donc pas la première insertion. La partie difficile, c’est tout ce qui se passe après que le jeu de données commence à évoluer. Cette évolution met en évidence trois problèmes.
Le premier problème : les colonnes longues rendent l’amplification d’écriture coûteuse
Les formats en colonnes tels que Parquet sont excellents pour de nombreuses charges de travail analytiques. Ils fonctionnent bien lorsque les schémas sont assez stables, que les données sont lues plus souvent qu’elles ne sont réécrites, que les scans ne touchent qu’un sous-ensemble de colonnes, et que la compression compte. C’est le monde pour lequel de nombreux formats analytiques ont été optimisés.
Les lignes vectorielles sont beaucoup plus larges que les lignes analytiques
TPC-H lineitem constitue une bonne référence. Il comporte 16 colonnes : clés entières, valeurs décimales, dates, chaînes courtes et un petit champ de commentaire. Une ligne non compressée représente environ 150 octets. Après compression, elle peut être beaucoup plus petite. Avec un groupe de lignes de 64 Mo, un système de stockage peut regrouper des centaines de milliers de lignes dans un seul groupe.
Les jeux de données vectorielles ne ressemblent pas à cela.
Un jeu de données image-texte de type LAION est beaucoup plus proche de ce que produisent aujourd’hui de nombreux pipelines d’IA. Chaque ligne possède toujours des métadonnées ordinaires : une URL, une légende, une largeur, une hauteur, des scores de qualité, des étiquettes, etc. Mais une fois l’embedding ajouté, la forme physique de la ligne change.
Un vecteur CLIP à 768 dimensions occupe environ 1,5 Ko en fp16 ou 3 Ko en fp32. Cette seule colonne peut être beaucoup plus volumineuse qu’une ligne entière de TPC-H lineitem.
Et 768 dimensions ne sont ni inhabituelles ni importantes selon les standards actuels. Un embedding à 1024 ou 2048 dimensions est courant dans les pipelines multimodaux. text-embedding-3-large d’OpenAI va jusqu’à 3072 dimensions, soit environ 12 Ko par vecteur en fp32.
La comparaison est frappante :
| Forme du jeu de données | Taille approximative de ligne | Champ dominant |
|---|---|---|
| TPC-H lineitem | ~150 octets non compressés | scalaires et chaînes courtes |
| Ligne de type LAION avec vecteur fp16 à 768 dimensions | ~1,5 Ko+ | embedding |
| Ligne de type LAION avec vecteur fp32 à 768 dimensions | ~3 Ko+ | embedding |
| Ligne avec vecteur fp32 à 3072 dimensions | ~12 Ko+ pour le vecteur seul | embedding |
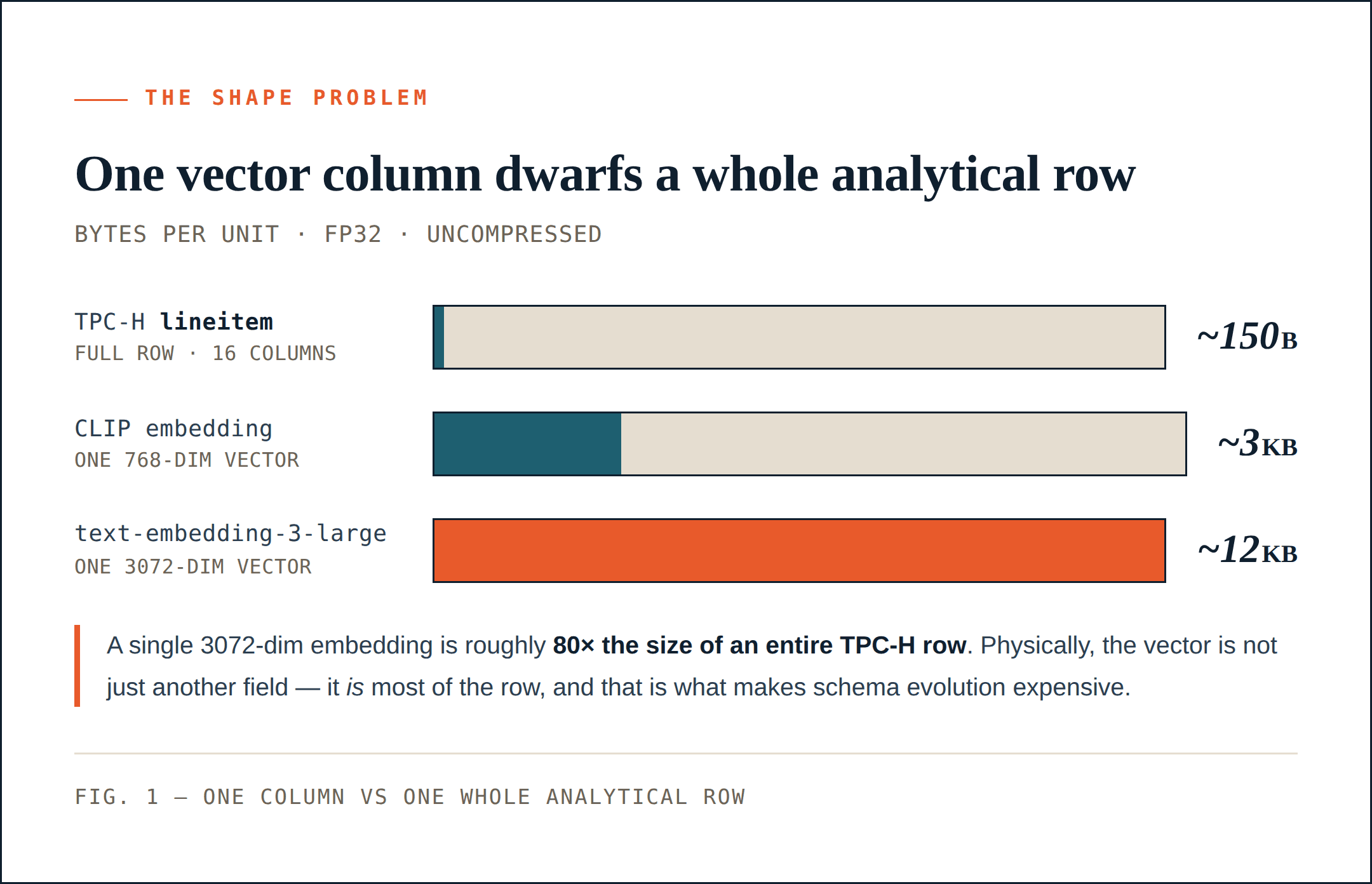
Dans de nombreux jeux de données d’IA, la colonne vectorielle n’est pas simplement un champ de plus. Physiquement, elle constitue l’essentiel de la ligne. Cela change le coût de l’évolution du schéma.
Ajouter une seule colonne vectorielle peut représenter des centaines de gigaoctets
Supposons qu’un jeu de données comporte 100 millions de clips vidéo. Ajouter une nouvelle colonne d’embedding fp32 à 1024 dimensions signifie écrire environ 400 Go de données vectorielles brutes. Cela n’inclut pas les statistiques, les index, les mises à jour des métadonnées, la surcharge du stockage objet, la validation ni l’intégration au chemin de service.

Si l’équipe ajoute une ou deux colonnes de type vecteur chaque mois, telles que embedding_v2, sparse_vector ou des fonctionnalités de rerank, l’évolution du schéma devient une tâche récurrente d’ingénierie des données mesurée en centaines de gigaoctets ou en téraoctets.
De petites mises à jour logiques peuvent déclencher de grandes réécritures physiques
Les mises à jour sont tout aussi importantes.
Dans les systèmes colonnaires, les anciennes données ne sont généralement pas mises à jour sur place. Un journal de suppressions enregistre ce qui a changé, et la compaction réécrit ensuite les lignes actives dans de nouveaux fichiers. Ce modèle est gérable lorsque les lignes sont petites.
Avec les données vectorielles, une petite mise à jour logique peut déclencher une grande réécriture physique.
Une tâche de revue humaine peut ne corriger que quelques centaines d’octets dans une légende. Mais si la légende, le vecteur dense, le vecteur sparse et d’autres fonctionnalités dérivées partagent le même cycle de vie de fichier physique, le système peut finir par réécrire aussi les vecteurs. Le changement logique est petit. Les E/S physiques peuvent être énormes.
C’est le problème de l’amplification d’écriture dans le stockage vectoriel. La partie coûteuse n’est pas seulement que les vecteurs sont volumineux. C’est que de grands champs dérivés et de petits champs mutables se retrouvent souvent liés par une disposition de stockage qui les traite comme une seule unité.
Pour les jeux de données d’IA, le backfill est une charge de travail routinière
Pour les tables analytiques traditionnelles, l’évolution du schéma peut ne se produire qu’occasionnellement. Pour les jeux de données d’IA, elle est routinière. Les modèles de légendage sont mis à niveau. Les modèles d’embedding sont remplacés. Des vecteurs sparse sont ajoutés plus tard. Des fonctionnalités de rerank apparaissent. Les labels humains sont corrigés. Les tags de gouvernance sont backfillés. Les index sont reconstruits.
Ces opérations ne sont pas de simples ajouts. Elles modifient ou étendent fréquemment des lignes existantes.
C’est pourquoi le stockage vectoriel ne peut pas seulement optimiser le débit de scan. Il doit aussi rendre les backfills et les mises à jour partielles moins coûteux.
Le deuxième problème : les mêmes données doivent prendre en charge les scans et les lectures ponctuelles
Une fois les données écrites, le chemin de lecture se divise. Le même jeu de données vectorielles présente généralement deux modes d’accès distincts : les scans analytiques et les lectures ponctuelles.

Les charges analytiques veulent des scans larges et compressés
Un pipeline peut exécuter des filtres tels que :
WHERE aesthetic_score > 0.8 AND duration > 5
Ou il peut exécuter une analyse hors ligne, une évaluation complète des embeddings, des statistiques BM25, la construction de bitmaps, des contrôles de qualité des données, des décomptes et des group-bys.
Ce modèle lit de nombreuses lignes mais seulement quelques colonnes. Il favorise les E/S séquentielles, les groupes de lignes plus grands, la compression, l’élagage de colonnes, le décodage par lots et l’exécution vectorisée.
Les grands groupes de lignes sont utiles ici. Ils permettent à une seule requête d’E/S de récupérer une grande quantité de données utiles, d’améliorer l’efficacité de la compression et de fournir au moteur d’exécution suffisamment de données contiguës pour amortir la surcharge. Lorsque plusieurs colonnes sont lues ensemble, les garder organisées pour le débit de scan aide également à réduire les défauts de cache pendant l’exécution vectorisée.
Parquet est performant sur ce chemin.
Les résultats ANN nécessitent des recherches étroites au niveau des lignes
Une fois que la recherche ANN renvoie les IDs de lignes candidates, le système doit souvent récupérer des champs tels que :
caption
embedding
rerank feature
video_uri
metadata
Ce modèle lit moins de lignes, souvent des centaines ou des milliers, mais il a besoin d’un accès précis par ID de ligne. Il veut localiser une ligne et une colonne spécifiques, récupérer uniquement la plage d’octets requise et éviter de charger un groupe de lignes entier simplement pour récupérer quelques enregistrements.
La recherche ponctuelle a presque la préférence opposée de celle du scan. Elle veut une granularité de lecture plus petite. Idéalement, la couche de stockage peut trouver le segment ou la plage d’octets pertinente par ID de ligne, lire uniquement cette plage et décoder uniquement les données nécessaires au résultat.
La compression implique également un compromis différent. Pour les scans, une compression plus forte en vaut souvent la peine, car le système lit beaucoup de données et économise des E/S. Pour la recherche ponctuelle, la compression peut devenir un handicap si la récupération d’une ligne nécessite de décoder un bloc compressé beaucoup plus grand.
Une seule disposition ne peut pas optimiser les deux chemins
C’est le conflit central. Le filtrage scalaire et l’analytique veulent des mises en page larges, compressées et adaptées au scan. La recherche vectorielle veut des mises en page étroites, précises et adressables par ligne.
Un seul format de fichier peut prendre en charge les deux dans une certaine mesure, mais il ne peut pas être optimal pour les deux simultanément.
Si toutes les colonnes résident dans Parquet, les scans scalaires sont confortables. Mais la recherche ANN après le rappel devient plus difficile. Le système peut n’avoir besoin que de quelques centaines de vecteurs, de légendes ou d’enregistrements de métadonnées, tandis que la couche de stockage peut devoir lire de grands groupes de lignes contenant principalement des lignes non pertinentes.
Sur un SSD local, le cache et mmap peuvent masquer une partie de ce coût. Une fois les données stockées dans un stockage objet, le coût devient plus visible. Chaque échec de cache peut devenir une lecture de plage distante. Si les lignes candidates sont dispersées dans de nombreux groupes de lignes, une seule requête peut déclencher plusieurs lectures, chacune récupérant plus de données que ce dont la requête a besoin. Dans une mise en page mal conçue, récupérer 1 000 lignes candidates peut facilement entraîner des dizaines ou des centaines de mégaoctets d’E/S inutiles, et dans les cas extrêmes, beaucoup plus.
Réduire la taille des groupes de lignes aide la recherche ponctuelle, mais nuit aux scans. Un trop grand nombre de petits fragments réduit l’efficacité de la compression, augmente la surcharge des métadonnées et casse les longues lectures séquentielles dont dépendent les moteurs analytiques.
Le problème ne consiste donc pas à trouver une seule taille magique de groupe de lignes. Le problème est que l’on demande au même jeu de données de se comporter comme deux systèmes de stockage différents.
La recherche hybride force les deux chemins dans une seule requête
La recherche hybride rend le conflit plus difficile à ignorer. Une seule requête peut d’abord appliquer des filtres scalaires :
aesthetic_score > 0.8 AND duration > 5
Puis elle exécute une recherche ANN.
Puis elle récupère la légende, le vecteur et les métadonnées par ID de ligne.
Pour l’utilisateur, il s’agit d’une seule requête de recherche. Pour la couche de stockage, c’est à la fois un scan analytique et une recherche aléatoire à faible latence.
C’est pourquoi le stockage vectoriel a besoin de plus qu’un meilleur réglage de Parquet. Il a besoin d’un moyen de placer différentes colonnes selon la façon dont elles sont réellement lues.
Le troisième problème : le jeu de données ne vit pas à l’intérieur d’un seul moteur
Les deux premiers problèmes se produisent à l’intérieur de la base de données. Le troisième se produit à la frontière entre les systèmes.

Les pipelines de données d’IA couvrent de nombreux systèmes
Dans le flux de travail vidéo, très peu de choses se passent au sein de la base de données vectorielle elle-même.
Les vidéos brutes résident dans un stockage objet. La génération de clips peut s’exécuter dans Spark ou Ray. La notation esthétique peut s’exécuter dans un service GPU. Le sous-titrage peut s’exécuter dans un pipeline d’inférence LLM. Les embeddings peuvent être générés par un autre job GPU. Les vecteurs clairsemés peuvent provenir d’un service SPLADE. L’évaluation hors ligne, le filtrage des données d’entraînement, la revue humaine et les tâches de gouvernance peuvent tous s’exécuter ailleurs.
La base de données vectorielle sert la recherche en ligne, mais le jeu de données est produit, corrigé, évalué et étendu par de nombreux systèmes.
Les formats de stockage privés créent plusieurs copies de la vérité
Si la base de données utilise un format physique privé qu’elle seule peut lire et écrire, chaque job externe nécessite une exportation, une conversion, une copie et une importation. La même collection peut exister dans la base de données, dans un répertoire temporaire Spark, dans une sortie d’évaluation et dans un répertoire local de backfill. La vraie question devient alors :
- Quelle copie est la source de vérité ?
- Laquelle contient le modèle de légendes du mois dernier ?
- Quelles lignes ont déjà été corrigées par revue humaine ?
- Quelle colonne de vecteurs clairsemés a été générée par quel modèle ?
- Quel index vectoriel est encore valide après le backfill ?
- À quel objet vidéo original cette ligne fait-elle référence ?
À petite échelle, les équipes peuvent parfois s’en sortir avec des conventions de nommage et des vérifications manuelles. Avec des centaines de millions de lignes et des téraoctets d’embeddings, cela devient un problème de cohérence.
Les jeux de données vectoriels ont besoin d’un état versionné partagé
Les systèmes Lakehouse ont traité une version de ce problème pour les données structurées. Iceberg, Delta Lake et Hudi ne servent pas seulement à stocker des fichiers. Leur contribution fondamentale est de permettre à plusieurs moteurs de se coordonner autour du même état de table.
Les bases de données vectorielles ont désormais besoin d’une capacité similaire, mais l’état est plus complexe. Il doit inclure non seulement les fichiers de table et les partitions, mais aussi les index vectoriels, les index texte, les caractéristiques sparse, les journaux de suppression, les statistiques, les plages d’ID de ligne et les références à des blobs externes.
La question n’est pas simplement : « Spark peut-il lire les fichiers Milvus ? »
La question est la suivante : après que Spark a rétro-rempli une colonne de vecteurs sparse, comment Milvus sait-il à quelle version cette colonne appartient, quelles lignes elle couvre, quel modèle l’a produite, et quand les requêtes en ligne peuvent-elles l’utiliser en toute sécurité ?
La réponse doit résider dans le modèle de stockage.
Pourquoi les correctifs ne suffisent pas
Il est tentant de traiter ces éléments comme trois problèmes d’ingénierie distincts.
- Amplification d’écriture ? Ajouter du batching.
- Lectures ponctuelles ? Ajouter un cache.
- Systèmes externes ? Ajouter des outils d’export et d’import.
Ces correctifs peuvent aider, mais ils ne traitent pas le problème sous-jacent : un jeu de données vectoriel est physiquement hétérogène.

Dans l’exemple vidéo, clip_id, video_id, duration et aesthetic_score sont des champs scalaires courts. Ils sont utiles pour le filtrage et l’analyse.
captionest du texte. Il peut être utilisé pour BM25, la révision, la correction et le rétro-remplissage.embeddingest un long vecteur dense. Il est utilisé pour le rappel ANN puis pour la recherche au niveau de la ligne ou le reranking.embedding_v2est une sortie d’un nouveau modèle, souvent rétro-remplie longtemps après l’insertion des données d’origine.sparse_vectorprend en charge la recherche hybride et possède son propre schéma d’accès.- La vidéo brute doit rester dans le stockage objet. La base de données doit stocker une référence, une somme de contrôle, un type MIME, une version de parser et une relation au niveau de la ligne.
- Les index vectoriels, les index texte, les statistiques et les journaux de suppression sont des objets dérivés avec leurs propres sémantiques de version.
Ces objets partagent une ligne logique, mais ils ne devraient pas tous partager la même disposition physique ni le même cycle de vie.
- S’ils sont forcés dans une disposition de table ordinaire unique, les mises à jour deviennent coûteuses.
- S’ils sont forcés dans un format de fichier colonnaire unique, les lectures ponctuelles deviennent coûteuses.
- S’ils sont traités comme des fichiers objet sans relation, la gestion des versions devient fragile.
Le modèle de stockage doit donc partir du principe que le jeu de données est hétérogène.
Cela conduit à trois exigences de conception :
- Premièrement, différents groupes de colonnes devraient être stockés dans différents formats physiques.
- Deuxièmement, ces groupes de colonnes ont besoin d’un espace d’ID de ligne partagé, afin qu’ils puissent toujours se comporter comme une seule table logique.
- Troisièmement, le jeu de données a besoin d’un Manifest versionné qui déclare quels fichiers, index, journaux, statistiques et références d’objets appartiennent à la vue actuelle.
C’est la conception derrière Loon, notre nouveau moteur de stockage derrière Milvus et Zilliz Cloud.
Loon : un moteur de stockage derrière Milvus et Zilliz Cloud pour les jeux de données vectoriels évolutifs
Pour résoudre tous les problèmes ci-dessus, nous avons construit Loon, le nouveau moteur de stockage pour Milvus et Zilliz Vector Lakebase (la prochaine évolution de Zilliz Cloud), conçu pour les jeux de données vectoriels évolutifs.
Le nom suit la tradition de Zilliz consistant à nommer ses produits d’après des oiseaux. Un loon est un oiseau plongeur qui vit sur les lacs, ce qui correspond bien à l’objectif du système : une base de données vectorielle ne devrait pas avoir à déplacer, analyser ou réécrire tout un lac de données à chaque fois qu’elle exécute une requête, rétro-remplit une colonne ou construit un index. Elle devrait d’abord comprendre la version actuelle du jeu de données, y compris ses colonnes, index, statistiques, journaux de suppression et références d’objets, puis lire uniquement la partie dont elle a réellement besoin.
Les formats de fichiers hybrides, l’alignement des ID de ligne et le Manifest ne sont pas trois fonctionnalités distinctes. Ils découlent de la même hypothèse de conception : un jeu de données vectoriel est intrinsèquement hétérogène.
Trois éléments, un seul modèle de stockage
Les formats de fichiers hybrides reconnaissent que différentes colonnes ont différents schémas d’accès. Les champs scalaires sont adaptés aux scans et aux filtres. Les champs vectoriels nécessitent une recherche efficace au niveau de la ligne. Les objets bruts tels que les vidéos, les PDF, les images et les fichiers audio ont leur place dans le stockage objet, pas à l’intérieur des fichiers de données de base de données.
L’alignement des ID de ligne reconnaît que ces colonnes peuvent être physiquement séparées, mais qu’elles décrivent toujours les mêmes lignes logiques. Une légende, un embedding, un vecteur sparse et l’URI d’une vidéo peuvent résider dans différents fichiers et formats, mais ils doivent toujours pouvoir être réunis en un seul résultat.
Le Manifest reconnaît que le dataset n’est pas écrit une fois puis laissé tel quel. Il sera modifié par plusieurs systèmes, sur plusieurs versions, pour plusieurs tâches. Les index, les statistiques, les journaux de suppression, les références à des objets externes et les groupes de colonnes doivent tous apparaître dans la même vue versionnée.
C’est pourquoi Loon n’est pas simplement un format de fichier vectoriel plus rapide. Un format plus rapide aide la recherche ponctuelle, mais il ne résout pas l’évolution du schéma ni la coordination multi-moteur. L’alignement des ID de ligne permet à des colonnes séparées de se comporter comme une seule table, mais il ne précise pas quels fichiers appartiennent à la version actuelle. Un Manifest peut décrire l’état d’un dataset, mais sans groupes de colonnes et sans alignement des ID de ligne, il ne peut pas représenter proprement différents agencements physiques au sein d’une même collection logique.
Le modèle de stockage a besoin des trois éléments : différents formats pour différents groupes de colonnes, un espace d’ID de ligne partagé pour reconstruire les lignes, et un Manifest versionné qui indique à chaque lecteur et rédacteur ce qu’est actuellement le dataset.
Où Loon s’inscrit dans Milvus et Zilliz Vector Lakebase
Dans Milvus, il remplace l’ancienne couche de stockage des binlogs de segments par un modèle construit autour des abstractions Manifest, ColumnGroup, format de fichier et système de fichiers. Dans Zilliz Vector Lakebase (la prochaine évolution de Zilliz Cloud), la même orientation s’applique à l’architecture Vector Lakebase : garder le chemin de service de la base de données vectorielle rapide tout en rendant les données sous-jacentes plus faciles à faire évoluer, à analyser et à coordonner avec des systèmes externes.
Les composants de niveau supérieur de Milvus conservent toujours leurs rôles familiers. Proxy gère le routage. QueryCoord et DataCoord gèrent l’ordonnancement. IndexNode construit les index. Les API exposées aux applications pour les collections, les insertions, les recherches et les recherches hybrides n’ont pas besoin d’exposer les fichiers Manifest ni les ColumnGroups.
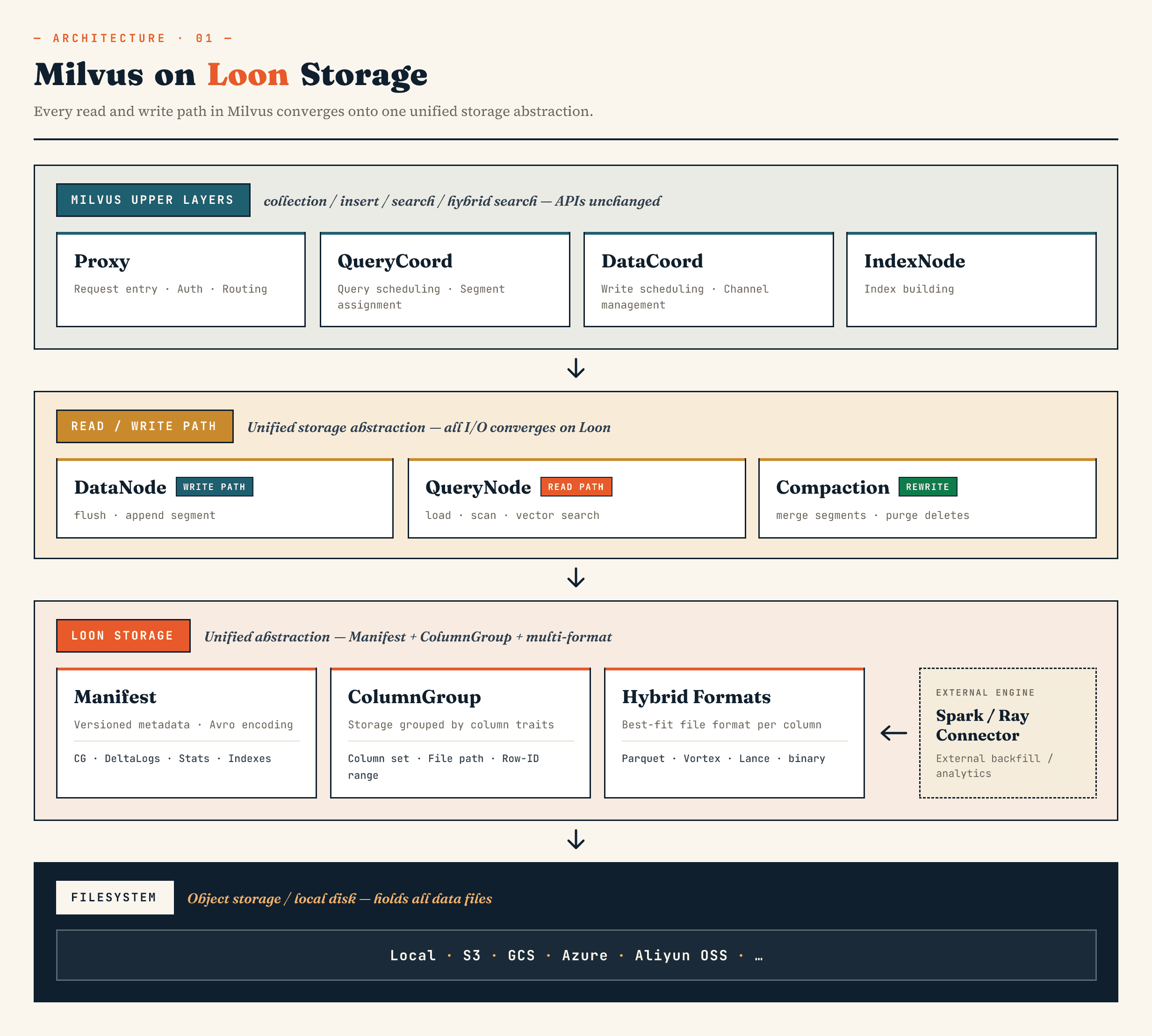
Le changement se situe en dessous.
DataNode, QueryNode, segcore, la compaction et les connecteurs externes peuvent fonctionner via la même abstraction de stockage. C’est important, car le dataset n’est plus écrit et lu uniquement par la base de données. Il peut être étendu par des systèmes de calcul externes et consommé simultanément par la recherche en ligne.
À haut niveau, les couches ressemblent à ceci :
Manifest
→ ColumnGroup
→ file format layer
→ filesystem abstraction
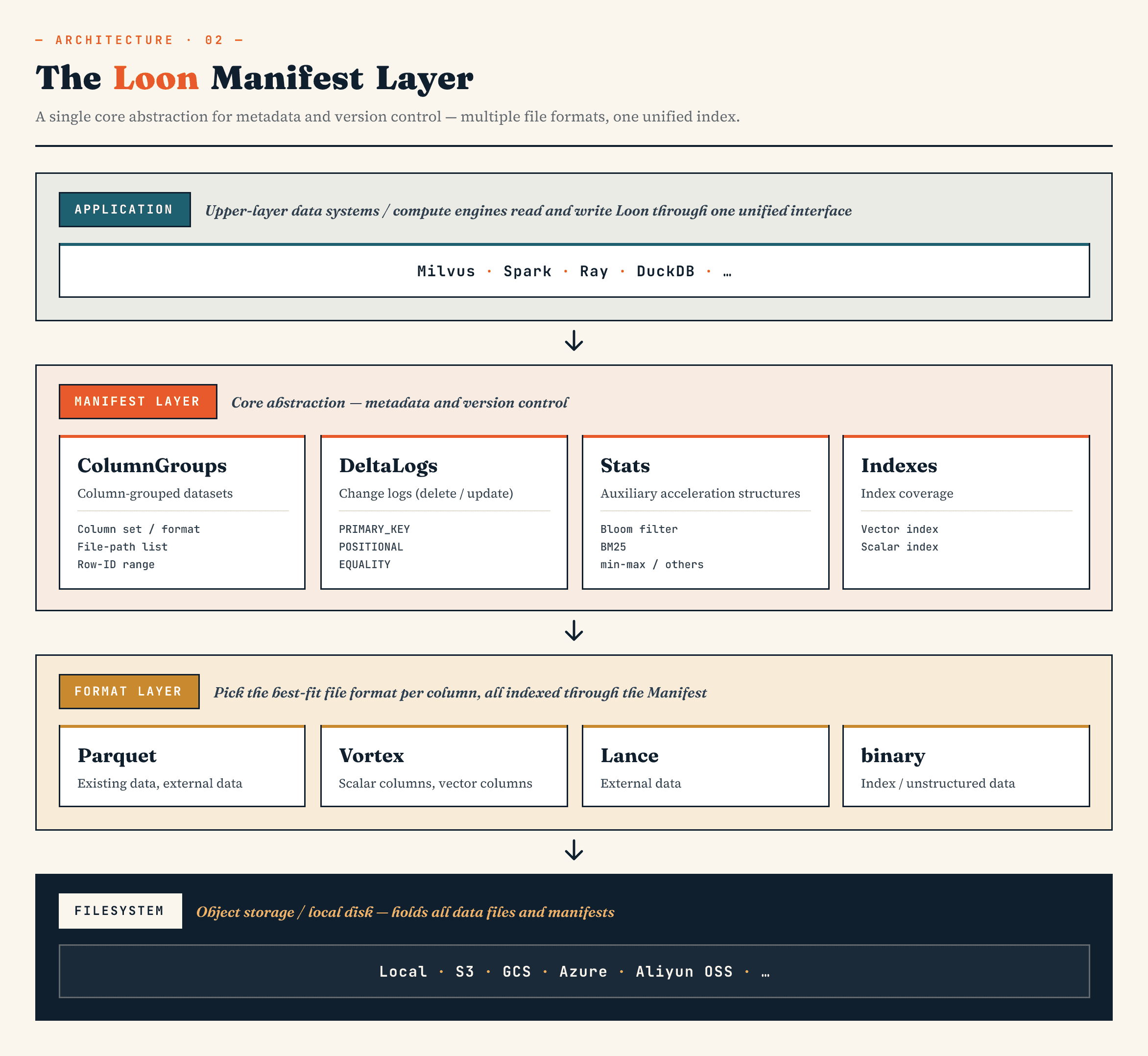
Le Manifest décrit l’état versionné du dataset. Les ColumnGroups mappent une collection logique en groupes physiques de colonnes. La couche de format de fichier permet à chaque ColumnGroup de choisir un format approprié. L’abstraction du système de fichiers fonctionne à travers le stockage objet et le stockage local.
Le point important est que les formats de fichiers hybrides, l’alignement des ID de ligne et le Manifest ne sont pas des fonctionnalités séparées. Ensemble, ils définissent le modèle de stockage.
Une fois ce modèle en place, nous pouvons examiner les trois choix de conception un par un : comment Loon stocke différents ColumnGroups, comment il les réaligne en lignes, et comment le Manifest transforme ces fichiers en un dataset versionné.
Conception 1 : utiliser le bon format de fichier pour le bon groupe de colonnes
Différentes colonnes ont différents schémas d’accès. Elles ne devraient pas être forcées dans le même format de fichier.
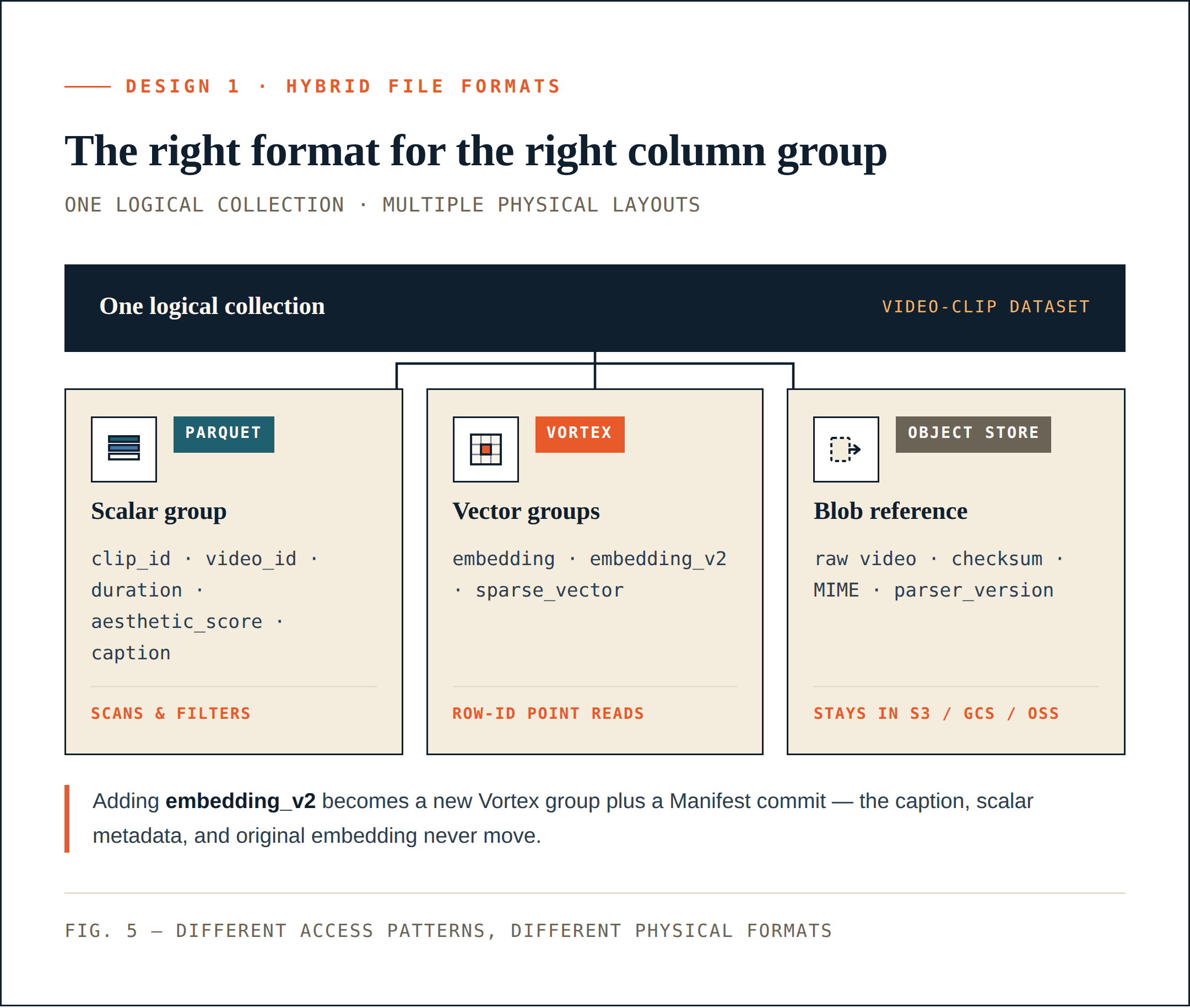
Loon sépare une collection logique en ColumnGroups.
- Les champs scalaires, les champs de filtrage, les clés métier et les champs statistiques sont souvent analysés, filtrés, agrégés ou utilisés pour la planification des requêtes. Ils bénéficient de la compression, de l’élagage de colonnes et de la compatibilité avec l’écosystème. Parquet convient bien à ces colonnes.
- Les vecteurs denses, les vecteurs clairsemés et les fonctionnalités de reclassement sont souvent lus après le rappel ANN par ID de ligne. Ils nécessitent un accès aléatoire à faible latence, des lectures précises par plages d’octets et un décodage sélectif. Une disposition orientée segment convient mieux. Loon utilise Vortex dans cette direction.
- Les objets bruts tels que les vidéos, les PDF, les images et les fichiers audio ne doivent pas être intégrés dans les fichiers de données de la base de données vectorielle. Ils doivent rester dans le stockage d’objets. La base de données enregistre les références, les sommes de contrôle, les types MIME, les versions de parseur et les relations au niveau des lignes.
Pour l’exemple vidéo, une disposition physique pourrait ressembler à ceci :
Parquet ColumnGroup:
clip_id / video_id / start_offset / duration / aesthetic_score / caption
Vortex ColumnGroups:
embedding
embedding_v2
sparse_vector
Object storage:
raw video objects
Pour l’application, il s’agit toujours d’une seule collection. Pour la couche de stockage, différentes parties de cette collection utilisent différents formats physiques. Cela réduit directement les réécritures inutiles. L’ajout de embedding_v2 peut devenir un nouveau ColumnGroup vectoriel plus un commit de Manifest. Il ne nécessite pas de réécrire la colonne caption, les métadonnées scalaires ni la colonne embedding existante.
La même idée s’applique aux vecteurs clairsemés, aux fonctionnalités de reclassement ou à d’autres champs dérivés. Si une nouvelle colonne peut être physiquement indépendante et alignée par ID de ligne, elle n’a pas à entraîner des colonnes non liées dans le même chemin de réécriture.
Loon adapte également l’utilisation des formats de fichiers.
Pour Parquet, les paramètres par défaut ne sont pas toujours idéaux pour les données fortement vectorielles. Un groupe de lignes de 64 MB peut être trop volumineux pour une recherche ponctuelle, car une petite lecture aléatoire peut extraire beaucoup plus de données que nécessaire. Loon réduit les groupes de lignes à 1 MB dans les chemins pertinents et désactive les encodages, comme l’encodage par dictionnaire sur les colonnes vectorielles, lorsqu’ils n’aident pas les données vectorielles d’apparence aléatoire.
Pour Vortex, le travail le plus important concerne la disposition. Loon utilise une disposition qui équilibre l’efficacité de l’analyse et la recherche ponctuelle. Au sein d’un groupe de lignes, les segments de colonnes liées peuvent être placés à proximité pour prendre en charge l’analyse. Pour effectuer des opérations, les lectures de sous-segments permettent au système de récupérer uniquement les octets pertinents plutôt que d’extraire un segment entier.
Loon prend également en charge l’intégration Lance en lecture seule, de sorte que les jeux de données Lance existants peuvent être montés en tant que ColumnGroups lorsque la compatibilité est importante.
Ce que montre le benchmark
Dans un test local, avec un seul fichier contenant 40 000 lignes et le schéma {id: int64, name: utf8, value: float64, vector: list<float32>[128]}, Vortex a affiché les résultats suivants par rapport à Parquet avec des groupes de lignes de 1 MB :
| Opération | Vortex | Parquet | Différence |
|---|---|---|---|
| Take, K=1000 lignes aléatoires | 5,8 ms | 144 ms | 25x plus rapide |
| Analyse complète de la colonne vectorielle | 21 ms | 142 ms | 6,76x plus rapide |
| Taille du fichier, ~21 MB de données brutes | 6,62 MB | 7,16 MB | 7 % plus petit |
Le résultat take provient de la réduction de la quantité de données non pertinentes qui doivent être lues et décodées. Le résultat de l’analyse provient de choix de compression et d’implémentation.
Ces chiffres doivent rester attachés à leur configuration : 8 vCPU Ubuntu 22.04 KVM, système de fichiers local, un fichier, 40 000 lignes, groupes de lignes de 1 MB et le schéma ci-dessus. Sur le stockage d’objets, les E/S réseau peuvent dominer, de sorte que la réduction de l’amplification de lecture peut compter encore plus. Les résultats réels dépendent de la forme du jeu de données, du comportement du stockage d’objets, de l’état du cache et du modèle de requête.
Le point plus général n’est pas que chaque colonne devrait utiliser Vortex.
Le point est que les jeux de données vectoriels nécessitent un choix de format de fichier au niveau du ColumnGroup.

Conception 2 : aligner les fichiers physiques grâce aux ID de ligne
Les formats de fichiers hybrides résolvent un problème : différentes colonnes peuvent désormais résider dans les formats qui leur conviennent le mieux.
Mais cela crée un second problème. Si les champs scalaires résident dans Parquet, les vecteurs dans Vortex et les objets bruts dans le stockage objet, comment le système continue-t-il à les traiter comme une seule collection ?
Loon résout cela avec l’alignement par ID de ligne.
L’ID de ligne est le système de coordonnées de la couche de stockage
Chaque ColumnGroupFile physique enregistre le chemin du fichier et la plage d’ID de ligne qu’il couvre :
path
start_index
end_index
Différents ColumnGroups peuvent couvrir le même espace d’ID de ligne même s’ils résident dans des fichiers et des formats différents.
Pour l’ID de ligne 12345, les métadonnées scalaires peuvent se trouver dans un ColumnGroup Parquet, l’embedding peut se trouver dans un ColumnGroup Vortex, et la vidéo brute peut être représentée par une référence de stockage objet. Logiquement, il s’agit toujours d’une seule ligne. Cela donne à la couche de stockage un système de coordonnées stable.
L’ID de ligne n’est pas la clé primaire métier. C’est le système de coordonnées de la couche de stockage qui permet à Loon de diviser physiquement une collection sans perdre la capacité de la reconstruire logiquement.
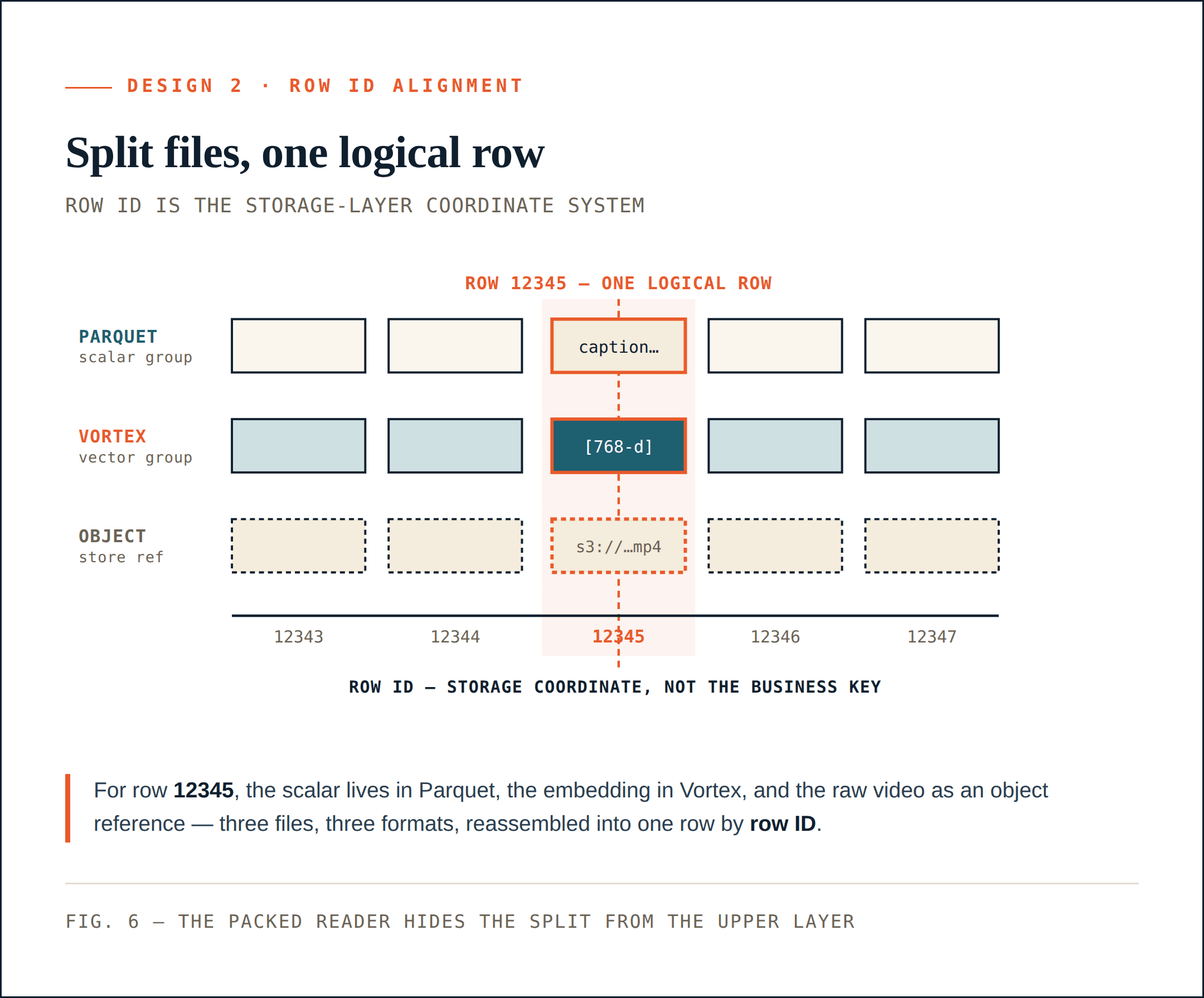
Les nouvelles colonnes n’ont pas à réécrire les anciennes colonnes
Ajouter embedding_v2 ne nécessite pas de réécrire la légende originale, les métadonnées ou les ColumnGroups embedding_v1. Loon peut écrire un nouveau ColumnGroup vectoriel, enregistrer la plage d’ID de ligne qu’il couvre et valider ce changement via le Manifest.
Il en va de même pour les vecteurs creux, les fonctionnalités de reranking ou d’autres champs dérivés qui arrivent plus tard.
Tant que le nouveau ColumnGroup couvre la bonne plage d’ID de ligne, il peut rejoindre la même collection logique sans obliger des données non liées à être déplacées.
Les suppressions et la compaction peuvent être plus ciblées
L’alignement par ID de ligne aide également pour les suppressions.
Une suppression peut d’abord être exprimée via un journal de suppression. La ligne devient invisible au niveau logique, tandis que le nettoyage physique est différé jusqu’à la compaction. Lorsque la compaction s’exécute finalement, elle n’a pas toujours besoin de réécrire chaque ColumnGroup lié aux lignes concernées. Elle peut se concentrer sur les ColumnGroups qui nécessitent un nettoyage.
C’est important, car toutes les colonnes n’ont pas le même profil de coût. Réécrire un court ColumnGroup scalaire est très différent de réécrire des centaines de gigaoctets de vecteurs denses.
La recherche hybride peut ne récupérer que les colonnes dont elle a besoin
L’alignement par ID de ligne est également ce qui rend la recherche hybride praticable au-dessus de formats de fichiers hybrides.
Après que la recherche ANN a renvoyé les ID de ligne candidats, le système peut récupérer uniquement les champs nécessaires au résultat final : légendes, métadonnées, vecteurs, fonctionnalités de reranking ou références d’objets.
Par exemple, une requête peut nécessiter :
caption
embedding
video_uri
Ces champs peuvent résider dans différents ColumnGroups. Loon peut localiser les fichiers pertinents par plage d’ID de ligne, lire les plages d’octets nécessaires et assembler le résultat.
Sans alignement par ID de ligne, les formats hybrides ne seraient que des fichiers séparés côte à côte. Avec l’alignement par ID de ligne, ils se comportent comme une seule collection logique.
Packed Reader masque la séparation à la couche supérieure
Le composant d’exécution qui rend cela utilisable est le Packed Reader.
La couche supérieure voit un flux Arrow RecordBatch unifié. En dessous, les données peuvent provenir de plusieurs ColumnGroups dans différents formats de fichiers. Le Packed Reader masque ces différences, aligne les données par plages d’ID de ligne et planifie les E/S multifichiers avec une utilisation mémoire contrôlée.
Il prend également en charge le take direct par ID de ligne. Étant donné un ensemble d’ID de ligne, il localise les ColumnGroupFiles pertinents, émet des lectures de plages et renvoie les champs demandés.
Pour le workflow vidéo, une requête ANN peut nécessiter caption, embedding et video_uri. Le Packed Reader peut récupérer le ColumnGroup scalaire et le ColumnGroup vectoriel sans toucher aux colonnes non liées.
C’est la différence entre « fichiers séparés » et « un tableau avec plusieurs organisations physiques ».
Conception 3 : faire du Manifest la source de vérité
Les formats de fichiers hybrides définissent la manière dont les données sont stockées physiquement. L’alignement des ID de ligne détermine comment des ColumnGroups séparés forment malgré tout une seule table logique. Mais le système doit encore répondre à une question plus large : quels fichiers, journaux, statistiques, index et références d’objets appartiennent à la version actuelle du jeu de données ? C’est le rôle du Manifest.

Les répertoires de stockage objet ne suffisent pas
Le stockage objet n’est pas un catalogue de base de données. Un répertoire peut contenir d’anciens fichiers, de nouveaux fichiers, des sorties de tâches échouées, des fichiers temporaires, des journaux de suppression, des fichiers encore référencés par d’anciens instantanés et des fichiers en attente de nettoyage. Le fait qu’un fichier existe ne signifie pas qu’il appartient à la version actuelle du jeu de données.
Un jeu de données Loon peut être organisé en répertoires tels que :
_metadata/
_data/
_delta/
_stats/
_index/
Mais la structure des répertoires n’est pas la source de vérité. C’est le Manifest qui l’est. Les lecteurs ne doivent pas lister les répertoires et déduire l’état à partir des fichiers qui s’y trouvent par hasard. Ils doivent lire le Manifest actuel et suivre la vue versionnée qu’il déclare.
Le Manifest définit une vue versionnée unique du jeu de données
Le Manifest définit le jeu de données dans une version donnée. Il enregistre :
- quels ColumnGroups existent
- quelles plages d’ID de ligne ils couvrent
- quel format physique chaque ColumnGroup utilise
- où se trouvent les fichiers
- quels journaux de suppression sont actifs
- quelles statistiques sont disponibles
- quels index existent
- quels blobs externes sont référencés
- quelles colonnes et plages de lignes ces statistiques ou index couvrent
Chaque mise à jour écrit une nouvelle version du Manifest. Un lecteur qui ouvre la version N voit une vue stable du jeu de données à la version N. Un rédacteur peut préparer la version N+1 sans perturber les lecteurs qui utilisent encore la version N.
Le Manifest suit plus que les fichiers de table
Dans Loon, le corps du Manifest est encodé avec Apache Avro et organisé autour de quatre grandes sections.
- Les ColumnGroups décrivent les colonnes, les formats, les fichiers et les plages d’ID de ligne.
- Les DeltaLogs décrivent les suppressions. Différents types de suppression couvrent différentes sources de changement, comme les suppressions par clé primaire provenant des clients, les suppressions positionnelles issues de la compaction interne ou les suppressions par égalité provenant de moteurs externes.
- Les Stats incluent des métadonnées de planification comme les filtres de Bloom, les statistiques BM25 et les valeurs min/max.
- Les Indexes décrivent le type d’index, les paramètres, les colonnes couvertes et les plages d’ID de ligne. Cela peut inclure des index vectoriels tels que HNSW ou IVF, des index textuels, des index inversés, des index bitmap et des structures associées.
C’est là que Loon diffère d’un manifeste de table traditionnel.
Un jeu de données vectoriel doit suivre non seulement les fichiers de données et les partitions. Il doit aussi suivre les index vectoriels, les index textuels, les caractéristiques clairsemées, les journaux de suppression, les statistiques, les références d’objets externes et les plages d’ID de ligne qui les relient.
Le Manifest doit être inscriptible par plus que la base de données
Le plus important n’est pas seulement ce que contient le Manifest. C’est qui peut l’écrire.
- Si seule la base de données peut écrire le Manifest, il reste des métadonnées internes. Des métadonnées plus propres, mais toujours privées à un seul moteur.
- Si des moteurs externes peuvent générer de nouveaux ColumnGroups, des statistiques et des entrées de Manifest, le Manifest devient une interface de coordination.
- Une tâche Spark, par exemple, peut remplir a posteriori une colonne vectorielle clairsemée. Elle écrit un nouveau ColumnGroup, enregistre la couverture des lignes et les statistiques, puis valide un nouveau Manifest. Les requêtes en ligne peuvent continuer à lire l’ancienne version pendant la tâche. Une fois la validation réussie, la nouvelle version devient visible.
C’est similaire dans l’esprit à Iceberg et Delta Lake, mais le modèle objet est plus large. Un jeu de données vectoriel doit suivre les index vectoriels, les index textuels, les caractéristiques clairsemées, les journaux de suppression, les statistiques, les références de blobs et les plages d’ID de ligne, et pas seulement les fichiers de table et les partitions.
Les commits optimistes simplifient les mises à jour de version
Chaque commit écrit une nouvelle version du Manifest. Un writer peut construire du nouveau contenu à partir de la version N, puis tenter d’écrire manifest-{N+1}.avro. Les écritures conditionnelles du stockage objet ou les sémantiques de correspondance de génération peuvent faire échouer le commit si cette version existe déjà. Le writer peut alors réessayer avec la version plus récente.
Cela donne à Loon une concurrence optimiste sans imposer à chaque mise à jour de passer par un chemin de coordination lourd et fortement cohérent. Sans Manifest, le stockage multi-format et multi-moteur finit par devenir un ensemble de conventions de nommage et de rapprochements manuels. Cela peut fonctionner pour de petits jeux de données. Cela ne fonctionne pas pour des données vectorielles à l’échelle du To.
Le Manifest est ce qui transforme des fichiers hétérogènes en un jeu de données que plusieurs systèmes peuvent lire et mettre à jour en toute sécurité.
Ce qui change pour les utilisateurs lorsque le stockage devient versionné
Pour les développeurs d’applications, Loon ne doit pas devenir une nouvelle contrainte d’API.
Les utilisateurs doivent toujours travailler avec des concepts Milvus familiers : collections, insertions, recherche et recherche hybride. Ils ne devraient pas avoir à penser aux fichiers Manifest, aux ColumnGroups, aux plages d’ID de ligne ou à la disposition des fichiers pendant le développement applicatif normal.
Le changement se situe en dessous. Le stockage devient plus conscient de la façon dont les jeux de données d’IA évoluent réellement.
Ajouter un nouvel embedding ne devrait pas déplacer les anciennes données
Auparavant, ajouter embedding_v2 à une collection existante nécessitait souvent d’exporter les données, d’entraîner un nouveau modèle, de générer des vecteurs, puis de réimporter ou de mettre à jour massivement la collection via le SDK. Ce chemin crée beaucoup de travail opérationnel : suivi des versions, reprises après échec de jobs, reconstructions d’index, impact sur le service et contrôles de cohérence.
Avec Loon, cela peut devenir une évolution de schéma plus un nouveau commit de ColumnGroup. La nouvelle colonne d’embedding peut être écrite comme son propre ColumnGroup physique, alignée par ID de ligne, et rendue visible via le Manifest. L’ancienne colonne de légende, la colonne de métadonnées scalaires et la colonne d’embedding d’origine n’ont pas besoin d’être déplacées.
Les backfills ne devraient pas nécessiter une boucle de mise à jour côté client
De nombreuses mises à jour de données d’IA sont des backfills. Une équipe peut ajouter des vecteurs sparse après que la recherche hybride devient importante. Elle peut ajouter des fonctionnalités de rerank après l’entraînement d’un nouveau modèle. Elle peut corriger des légendes après une revue humaine. Elle peut ajouter des tags de gouvernance après une mise à jour de politique.
Dans une disposition traditionnelle, ces changements se font souvent via des mises à jour du SDK client ou des chemins d’écriture uniquement base de données, même lorsque les données sont produites par Spark, Ray ou un autre moteur externe.
Avec Loon, les systèmes de calcul externes peuvent produire de nouveaux ColumnGroups et les committer via le Manifest. La base de données n’a plus à être le seul point d’entrée pour chaque réécriture.
L’analyse hors ligne ne devrait pas nécessiter une autre copie de la vérité
Auparavant, les équipes exportaient souvent une collection en ligne vers Parquet pour l’évaluation ou l’analyse hors ligne. Cela crée deux versions du même jeu de données : la collection en ligne et la copie d’analyse. Une fois les légendes corrigées, les embeddings régénérés, les logs de suppression appliqués ou les index reconstruits, l’équipe doit se demander quelle copie est à jour.
Avec un modèle de stockage basé sur le Manifest, les moteurs d’analyse peuvent lire la même vue versionnée du jeu de données que le système de service. Ils peuvent projeter uniquement les colonnes dont ils ont besoin, scanner uniquement les plages de lignes pertinentes, et travailler sur une version déclarée du jeu de données plutôt que sur un snapshot exporté manuellement.
Les suppressions et corrections ne devraient toucher que ce qui a changé
Les suppressions, corrections de légendes, corrections de labels et mises à jour de gouvernance sont routinières dans les jeux de données d’IA. Elles ne devraient pas forcer chaque longue colonne vectorielle à passer par le même chemin de réécriture.
Avec Loon, les logs de suppression peuvent d’abord être traités comme des suppressions logiques. Plus tard, la compaction peut nettoyer les ColumnGroups affectés sans réécrire les données non liées. Si un court champ texte change, la couche de stockage ne devrait pas avoir à réécrire des centaines de gigaoctets de vecteurs denses simplement parce qu’ils partagent la même ligne logique.
Les moteurs externes deviennent une partie du workflow, pas une porte de sortie
Le changement le plus important est que les moteurs externes ne sont plus traités comme des systèmes situés en dehors de la base de données vectorielle.
Spark, Ray, les tâches d’évaluation, les systèmes d’étiquetage et les pipelines de gouvernance produisent et modifient déjà une grande partie des données. La couche de stockage devrait leur permettre de collaborer autour d’une source unique de vérité plutôt que d’exporter, de copier et de réimporter constamment.
C’est ce qu’une version de Manifest rend possible. Elle donne au service en ligne, à l’analyse hors ligne, aux tâches de backfill et à la compaction une vue partagée du dataset.
Cela peut sembler relever de détails internes de stockage, mais ceux-ci influencent la rapidité avec laquelle les équipes peuvent itérer sur les datasets d’IA. Chaque changement de modèle, backfill de fonctionnalités, correction de légende, filtre de qualité et reconstruction d’index dépend de la même question : "Le système peut-il mettre à jour le dataset sans déplacer des données qu’il n’a pas besoin de déplacer ? "
C’est la valeur pratique du modèle de stockage.
Loon est disponible dans Milvus 3.0 beta et Zilliz Vector Lakebase
Loon est disponible dans Milvus 3.0 beta et fait également partie de la couche de stockage de Zilliz Vector Lakebase, la prochaine évolution de Zilliz Cloud. Et cette version se concentre sur trois domaines clés :
- Le Manifest. L’objectif est que les écritures, les backfills, les suppressions, les statistiques et les mises à jour d’index produisent des vues de dataset versionnées que les lecteurs peuvent ouvrir de manière cohérente. Pour les lecteurs, cela signifie qu’une requête peut ouvrir une version spécifique du Manifest et voir une vue stable du dataset. Pour les rédacteurs, cela signifie que de nouveaux fichiers de données, journaux de suppression, statistiques ou fichiers d’index peuvent d’abord être préparés, puis rendus visibles via un commit versionné.
- Le ColumnGroup et la prise en charge des formats. Parquet prend en charge les colonnes scalaires et compatibles avec l’écosystème. Vortex prend en charge les schémas d’accès fortement orientés vecteurs. Lance peut être intégré en mode lecture seule pour assurer la compatibilité avec les datasets Lance existants.
- L’Index on Lake. Les statistiques scalaires, les index de filtrage et les index inversés de texte peuvent participer à la planification basée sur le Manifest par plage de lignes. Les index vectoriels natifs du lake sont plus complexes. HNSW et IVF ont des comportements différents sur le stockage objet, et HNSW en particulier est sensible aux accès aléatoires et à la localité du cache. Il ne peut pas simplement réutiliser une disposition conçue pour un SSD local et s’attendre au même résultat.
Il reste encore du travail
- Les chemins d’écriture externes sont importants, car Spark et Ray devraient pouvoir produire des ColumnGroups et des commits Manifest sans forcer chaque backfill à passer par une boucle de SDK client.
- L’interopérabilité avec les lakehouses est importante, car de nombreuses équipes utilisent déjà des catalogues et des moteurs de requêtes tels que Iceberg, Delta Lake, Trino, DuckDB et Athena. Les données vectorielles devraient pouvoir participer à cet écosystème sans perdre en performance de recherche vectorielle.
- La disposition des index est importante, car les index de graphes et les structures inversées ont des schémas d’accès différents sur le stockage objet.
- La sémantique des grands objets est importante, car les vidéos brutes, PDF, images et fichiers audio nécessitent une gestion des références, un versionnement et un comportement de suppression alignés sur le dataset vectoriel dérivé.
Le comportement exact de la version, les paramètres par défaut et le chemin de migration doivent suivre les notes de version Milvus et Zilliz Cloud pertinentes. Toutefois, l’orientation du stockage est claire : les bases de données vectorielles ont besoin d’une fondation versionnée et native du lake sous la couche de service.
Essayez Loon avec Zilliz Vector Lakebase
Si votre stack actuelle sépare le service en ligne, l’analyse hors ligne, les backfills et les workflows externes de data lake en différents systèmes, Zilliz Vector Lakebase mérite votre attention. Vous pouvez l’essayer dans Zilliz Cloud. Les nouvelles inscriptions avec une adresse e-mail professionnelle bénéficient de 100 $ de crédits gratuits. Vous êtes également invité à nous contacter pour discuter de votre cas d’utilisation.
Vous pouvez également suivre la version Milvus 3.0 pour voir comment Loon évolue dans le moteur open source.
Zilliz Vector Lakebase réunit :
- Une mise à disposition par niveaux pour différents compromis entre performance en temps réel et coût
- Une recherche à la demande pour les charges de travail à grande échelle ou exploratoires, sans calcul toujours actif
- Une recherche sur lac de données externe, afin que vous puissiez indexer et rechercher directement dans les données de lac existantes
- Une recherche couvrant tout le spectre à travers les vecteurs, le texte, JSON et les données géospatiales, avec récupération hybride et reranking
- Un stockage unifié natif du lac, construit sur Vortex, un format ouvert conçu pour des lectures aléatoires plus rapides et moins coûteuses sur des données à forte composante vectorielle
Continuer à lire

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.