




La panne d’AWS a été un signal d’alarme pour la reprise après sinistre interrégionale des bases de données vectorielles
Les régions cloud tombent en panne. Ce n’est pas une question de si — c’est une question de quand et de gravité.
La semaine dernière, deux régions AWS au Moyen-Orient ont été mises hors ligne en raison de dommages physiques à l’infrastructure des centres de données. Deux des trois zones de disponibilité de la région AWS des Émirats arabes unis (ME-CENTRAL-1) ont été mises hors service, et une installation à Bahreïn (ME-SOUTH-1) a été endommagée. Plus de 60 services AWS ont été touchés, notamment Lambda, EKS, VPC, S3 et CloudWatch. Careem, la plus grande plateforme de VTC de la région, a perdu son service. Alaan, un fournisseur de paiements de premier plan, est devenu indisponible. AWS a conseillé à ses clients de déplacer leurs charges de travail vers d’autres régions — mais il ne s’agissait pas d’un incident de type redémarrage-et-récupération. Avec le remplacement du matériel et la réparation des installations, la reprise peut prendre des semaines.
Et les dommages physiques ne sont qu’un mode de défaillance parmi d’autres. Au cours des 12 derniers mois, un changement de configuration défectueux a mis hors service la région Central US d’Azure pendant 14,5 heures. Un bug dans Google Cloud a simultanément paralysé Cloud Run, GKE et Firebase pendant 8 heures. Une mise à jour logicielle défaillante de CrowdStrike — qui n’était même pas un problème lié à un fournisseur cloud — s’est propagée à travers l’infrastructure hébergée sur Azure, coûtant aux entreprises du Fortune 500 environ 5,4 milliards de dollars.
Le rapport 2025 de l’Uptime Institute estime le coût médian d’une panne à fort impact à 2 millions de dollars par heure, soit environ le double du chiffre d’il y a trois ans. Pourtant, le Data Protection Trends Report 2024 de Veeam a révélé que seules 13 % des organisations peuvent réellement orchestrer une reprise lors d’un véritable sinistre.
Ces chiffres étaient déjà alarmants. Puis l’IA a fait monter les enjeux.
Quand l’IA tombe en panne, les équipes ne ralentissent pas — elles s’arrêtent
Il y a cinq ans, une défaillance régionale du cloud affectait principalement les applications destinées aux clients. C’était pénible, mais la plupart des équipes pouvaient encore fonctionner en interne. Aujourd’hui, l’IA a absorbé des tâches qui traversent des départements entiers — revue de code, documentation, tri du support, et même analyses de routine. Avec près de 60 % des employés utilisant l’IA dans leurs workflows quotidiens, les pannes ne provoquent pas un ralentissement progressif. La productivité s’effondre.
Nous avons déjà vu cela se produire — ChatGPT et Claude ont tous deux subi des pannes importantes au début de 2026, laissant des millions d’utilisateurs et d’équipes d’entreprise sans les outils d’IA autour desquels ils avaient construit leurs workflows.
Mais voici ce que la plupart des équipes négligent. Les pannes de modèles sont perturbatrices, mais les modèles sont en grande partie sans état : les fournisseurs peuvent souvent rediriger assez rapidement le trafic d’inférence vers des régions saines. Le problème le plus difficile est la couche de données sous-jacente — les bases de données, les stockages d’objets et les index vectoriels qui fournissent la mémoire et le contexte. Cette couche est avec état, liée à une région, et bien plus difficile à restaurer. Lorsqu’elle tombe en panne, votre LLM peut encore générer du texte — mais sans le bon contexte, il produit par défaut une sortie générique, sujette aux hallucinations. L’IA ne se contente pas de devenir indisponible. Elle devient peu fiable.
La base de données vectorielle est la mémoire à long terme de votre IA — et elle est probablement monorégion
Les bases de données vectorielles sont devenues l’épine dorsale de l’IA d’entreprise. Les pipelines RAG et les agents IA y récupèrent du contexte. Les moteurs de recommandation les interrogent. La recherche sémantique s’exécute dessus. Lorsque cette couche est indisponible, chaque application construite au-dessus d’elle se casse — pas partiellement, mais complètement.
Et contrairement aux services sans état, la reprise n’est pas simple :
- Les reconstructions d’index sont lentes. La recherche vectorielle dépend de structures d’index comme les graphes HNSW, où le temps de reconstruction augmente de façon non linéaire avec la taille du jeu de données. Reconstruire un index sur plus de 100 M de vecteurs peut prendre plus de 18 heures sur une capacité de calcul standard.
- Les chaînes de connexion sont partout. Chaque application qui se connectait à l’ancien cluster doit voir son endpoint mis à jour — dans les configurations, les variables d’environnement, les pipelines CI/CD, souvent gérés par différentes équipes.
- Dérive du modèle d’embedding. Si vous ne pouvez pas localiser la version exacte du modèle d’embedding qui a généré vos vecteurs actuels, vous devrez peut-être ré-encoder l’intégralité de votre jeu de données.
Pour une panne logicielle, vous attendez un redémarrage. Mais lorsqu’un centre de données est physiquement endommagé, la reprise prend des semaines. La seule stratégie viable consiste à disposer déjà d’une réplique active, indexée et prête pour les requêtes, servie depuis une autre région — avec un reroutage du trafic qui ne nécessite aucune modification du code.
Zilliz Cloud : la première base de données vectorielle au monde avec reprise après sinistre interrégionale native
Zilliz Cloud est la première base de données vectorielle au monde à offrir une reprise après sinistre interrégionale native — avec basculement automatisé, réplication en temps réel et endpoint global ne nécessitant aucune modification de l’application lors des transitions entre régions.
Nous fournissons deux capacités complémentaires : Global Cluster pour le basculement en temps réel, et Cross-Region Backup pour une reprise après sinistre économique.
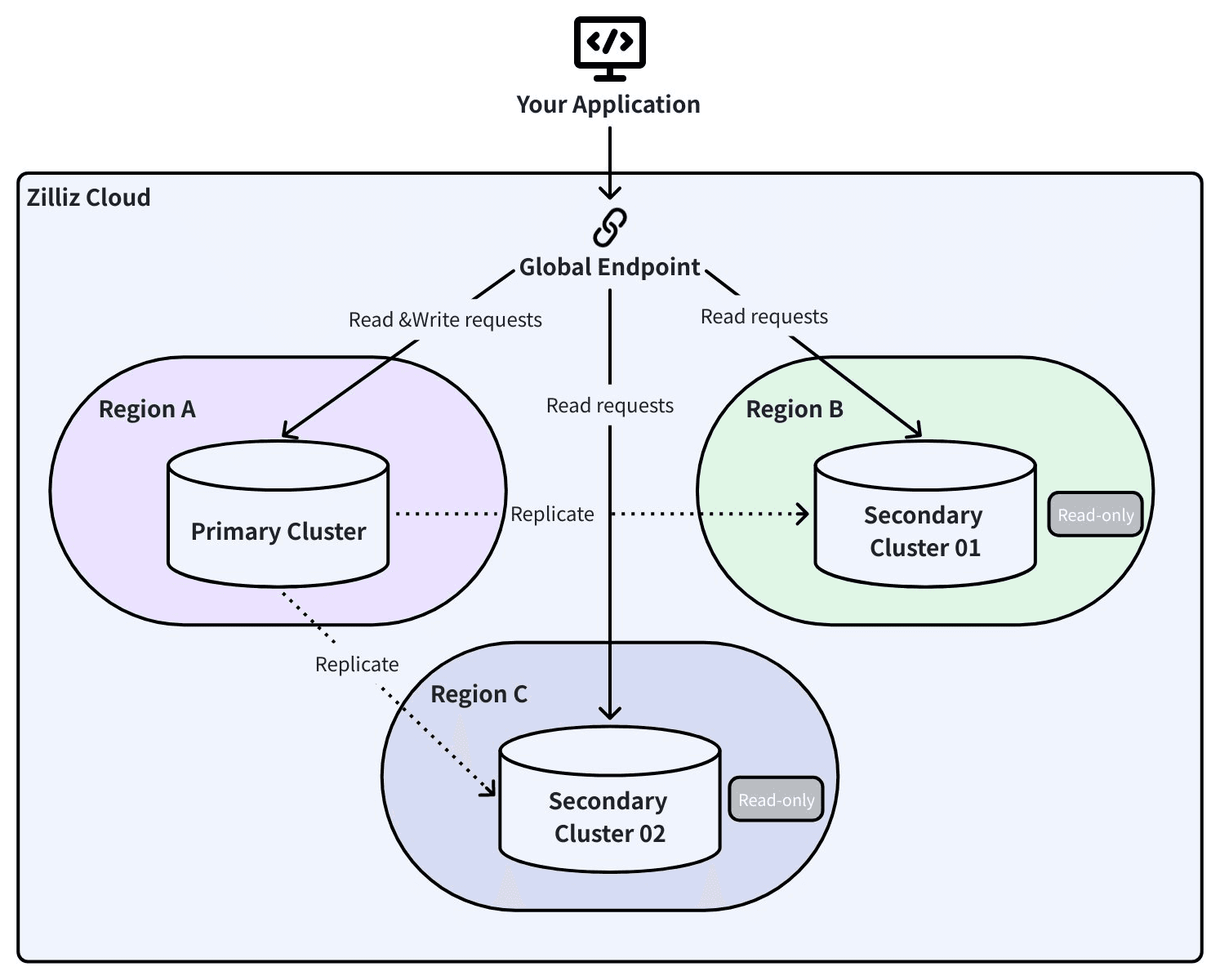
Global Cluster : réplication active avec basculement automatique
Global Cluster utilise Change Data Capture (CDC) pour répliquer les données en continu entre un cluster primaire et un cluster secondaire dans une région différente. Pas des instantanés périodiques — chaque insertion, mise à jour et suppression se propage en temps réel.
- Basculement planifié (maintenance, migration, conformité) : le système vide les messages CDC en cours, confirme la synchronisation complète, puis échange les rôles. Le RPO est nul. Le RTO est inférieur à 30 secondes.
- Basculement automatique (défaillance régionale inattendue) : le secondaire se promeut automatiquement. Le RPO est égal au retard CDC au moment de la défaillance — généralement quelques secondes. Le RTO est inférieur à 60 secondes.
Une capacité unique : après un basculement, l’ancien primaire ne disparaît pas simplement. Il est placé dans une corbeille avec une rétention de 7 jours, et une API de streaming appelée DumpMessages vous permet de récupérer toutes les écritures arrivées sur l’ancien primaire mais pas encore répliquées. Au lieu d’accepter une perte de données, vous disposez d’une fenêtre pour les récupérer.
Global Endpoint : une connexion, toutes les régions
C’est là que l’architecture porte ses fruits dans un scénario de sinistre physique.
Votre application se connecte à un endpoint global unique. En arrière-plan, les enregistrements DNS SRV suivent quel cluster est primaire et lequel est secondaire. Lorsqu’un basculement se produit, le SDK détecte le changement de topologie et reroute automatiquement le trafic. Aucune mise à jour de chaîne de connexion. Aucun redémarrage de l’application. Aucune modification du code.
Pensez à ce que cela signifie lors d’une panne régionale prolongée. Sans endpoint global, la reprise nécessite que quelqu’un trouve un runbook, reconfigure manuellement les clients, mette à jour les chaînes de connexion et coordonne les équipes — à 3 h du matin, sous pression. Votre RTO ne se mesure pas en secondes ; il se mesure au temps nécessaire pour alerter le bon ingénieur.
Avec Global Endpoint, votre pipeline RAG interroge la réplique dans une autre région en moins de 60 secondes, sans changer une seule ligne de code.
Cross-Region Backup : résilience sans le coût d’une réplique active
Toutes les charges de travail ne justifient pas l’exécution d’un cluster secondaire. Cross-Region Backup réplique les données de sauvegarde vers une ou plusieurs régions cibles, chacune avec sa propre politique de rétention. Lorsqu’une défaillance au niveau régional survient, vous lancez un nouveau cluster à partir de n’importe quel point de sauvegarde dans la région cible — aucun transfert de données interrégional n’est nécessaire pendant la crise, car les données sont déjà là.
Le compromis :
- Global Cluster → RPO en secondes, RTO inférieur à 60 secondes. Pour les charges de travail qui ne peuvent tolérer aucune interruption.
- Cross-Region Backup → RPO et RTO en heures. Pour les charges de travail où la survie des données compte davantage qu’une reprise instantanée.
De nombreuses équipes commencent avec Cross-Region Backup pour la garantie essentielle — vos données survivent à une défaillance régionale — puis passent à Global Cluster à mesure que leurs charges de travail d’IA deviennent critiques.
Comment les autres bases de données vectorielles gèrent la DR interrégionale
La plupart des bases de données vectorielles offrent une haute disponibilité au sein d’une seule région grâce à des ensembles de réplicas et à la redondance des nœuds. Cela gère les défaillances de nœuds — pas les défaillances de région. Zilliz Cloud est la seule base de données vectorielle offrant un basculement interrégional automatisé natif avec un cluster global et un endpoint global — des transitions de région sans interruption et sans modification de code.
| Capacité | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Réplication interrégionale | ✅ Basée sur CDC, en temps réel | ❌ | ❌ | ❌ | ❌ |
| Basculement non planifié | ✅ RPO ≈ secondes, RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| Basculement planifié | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Récupération des données après basculement | ✅ Récupération automatique des données non synchronisées. | ❌ | ❌ | ❌ | ❌ |
| Endpoint global | ✅ Un endpoint global, reroutage automatique sans modification de code | ❌ | ❌ | ❌ | ❌ |
| Défaillance régionale RPO/RTO | ✅ RPO ≈ secondes, RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| Sauvegarde interrégionale automatique | ✅ N’IMPORTE QUELLE région avec rétention par région | ❌ | ❌ | ❌ | ❌ |
Au-delà de la reprise après sinistre
Les équipes utilisent également Global Cluster pour des scénarios opérationnels qui n’ont rien à voir avec les pannes :
- Optimisation de la latence : Ajoutez une région secondaire plus proche de vos utilisateurs pour des temps de réponse aux requêtes inférieurs à 100 ms.
- Migration de région : Déplacez les charges de travail entre les régions sans interruption lors de la consolidation de l’infrastructure.
- Conformité à la résidence des données : Conservez les données à l’intérieur de frontières géographiques spécifiques afin de répondre aux exigences réglementaires.
Le même pipeline CDC qui protège contre les pannes vous offre également une réplique accessible en lecture plus proche de vos utilisateurs — la capacité de reprise après sinistre comme effet secondaire de l’optimisation des performances.
Premiers pas
Global Cluster et Cross-Region Backup sont disponibles sur Zilliz Cloud pour les clusters dédiés.
- Si vous avez déjà un compte Zilliz Cloud, il vous suffit de vous connecter et de commencer à utiliser les nouvelles fonctionnalités immédiatement—aucune mise à niveau ni migration requise.
- Vous débutez avec Zilliz Cloud ? Inscrivez-vous gratuitement et recevez \$100 de crédits pour découvrir la base de données vectorielle managée leader mondiale.
- Vous avez des questions sur l’une des mises à jour ? Consultez la dernière documentation ou contactez le support Zilliz—nous sommes là pour vous aider.
Construire sans limites : un examen plus approfondi des capacités de Zilliz Cloud prêtes pour l’entreprise
Global Cluster est l’un des éléments d’une plateforme plus large conçue pour l’IA à l’échelle de la production. Zilliz Cloud fournit également :
- Mise à l’échelle élastique et efficacité des coûts – Déploiement en un clic, autoscaling serverless et tarification à l’usage.
- Recherche IA avancée – Recherche vectorielle, plein texte et hybride (sparse + dense) avec filtrage des métadonnées, schéma dynamique et multi-tenant.
- Sécurité de niveau entreprise – SLA de 99,95 %, certifications SOC 2 Type II et ISO 27001, conformité GDPR, préparation HIPAA, RBAC, BYOC et journaux d’audit. Consultez notre centre de confiance pour en savoir plus.
- Disponibilité mondiale – Déploiements sur AWS, GCP et Azure avec une latence inférieure à 100 ms dans le monde entier.
- Migration transparente – Outils intégrés pour migrer depuis Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate ou Milvus sur site.
- Requêtes en langage naturel – Prise en charge du serveur MCP pour des requêtes intuitives sans API complexes.
- Et plus encore !

Continuer à lire

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.