




VDBBench ajoute une analyse comparative sensible aux coûts pour les bases de données vectorielles
L’année dernière, nous avons publié VectorDBBench 1.0 afin de rapprocher l’évaluation comparative des bases de données vectorielles des charges de travail de production. Au lieu de tester uniquement le QPS maximal sur des données de référence fixes, VectorDBBench (également appelé VDBBench) permet aux équipes d’évaluer des bases de données vectorielles à l’aide de modèles de charge de travail qui reflètent plus fidèlement leurs propres systèmes de production : ingestion, filtrage, rappel, latence, concurrence et jeux de données personnalisés.
La dernière version de VDBBench ajoute une nouvelle dimension : le coût.
Les équipes de production choisissent rarement une base de données vectorielle sur la seule base des performances. Elles doivent savoir combien il en coûte pour atteindre un QPS cible, comment le P99 se comporte dans ce modèle de coût, quand les données insérées deviennent consultables, quand elles sont entièrement indexées, comment la taille de la charge utile affecte la recherche, comment le système se comporte avec de nombreux locataires, et ce qui se passe lors de la première requête après une période d’inactivité. Ces questions font désormais partie de VDBBench.
Pour montrer comment ces nouveaux benchmarks tenant compte des coûts fonctionnent en pratique, nous avons testé trois produits de bases de données vectorielles managées couramment évalués : Zilliz Cloud, Turbopuffer et Pinecone. Les résultats sont publiés dans le nouveau VDBBench Cost Leaderboard, avec des graphiques et des tableaux qui comparent la disponibilité après insertion, la recherche avec charge utile, la recherche multilocataire, la latence à froid et les compromis coût-performance.
Le classement n’est qu’une manière de lire les résultats — il s’agit d’un instantané de trois produits à un moment donné. Comme VDBBench est open source, les équipes peuvent également reproduire ces cas, évaluer des produits qui ne figurent pas dans le classement, ou adapter les charges de travail à leurs propres données similaires à celles de production.
L’objectif n’est pas de désigner un vainqueur universel, mais d’aider les équipes à choisir la base de données vectorielle qui correspond le mieux à leur charge de travail, à leurs objectifs de performance et à leur budget.
- Références : VectorDBBench GitHub | Classements VDBBench
Nouveautés de VDBBench
Cette version ajoute quatre cas de benchmark orientés cloud qui mesurent des comportements de production que les classements fondés sur le QPS maximal manquent souvent.
| Cas | Ce qu’il mesure | Pourquoi c’est important |
|---|---|---|
| CloudInsertCase | Achèvement de l’insertion, état consultable, état entièrement indexé et coût d’écriture | La fraîcheur et le coût de remplissage rétrospectif sont importants pour le RAG, les catalogues et la mémoire des agents |
| CloudPayloadSearchCase | QPS, latence P99, rappel et forme de la charge utile de réponse | Le renvoi de vecteurs ou de métadonnées peut modifier la surface de coût de la recherche |
| MultitenantSearchCase | Débit entre de nombreux locataires ou espaces de noms | Les charges de travail SaaS sollicitent le routage et le comportement des partitions différemment de la recherche monolocataire |
| CloudColdLatencyCase | Première requête après inactivité vs. chemin de requête réchauffé | Le comportement de démarrage à froid est important pour les locataires peu fréquents et la mémoire des agents |
En plus de ces cas, le Cost Leaderboard ajoute une vue de Pareto des coûts qui modélise les coûts d’exploitation à des niveaux de QPS cibles selon les limites de service mesurées de chaque produit — parce que les décisions d’achat dépendent généralement du point d’intersection entre performance et coût.
Le VDBBench Cost Leaderboard utilise ces cas pour comparer publiquement des produits managés. Comme les cas sont inclus dans VDBBench open source, les équipes peuvent les réutiliser pour leur propre évaluation, y compris avec des produits et des charges de travail qui ne figurent pas dans le classement.
Qui nous avons testé : Zilliz Cloud vs. Turbopuffer vs. Pinecone
Pour cette première exécution tenant compte des coûts, nous avons testé trois produits de bases de données vectorielles managées couramment évalués. Tous les produits ont été benchmarkés le 10 mai 2026, dans AWS US West (us-west-2). Leurs modèles d’exploitation diffèrent, de sorte que les résultats doivent être interprétés en termes d’adéquation à la charge de travail plutôt que comme un classement unique.
| Produit | Rôle dans ce benchmark |
|---|---|
| Zilliz Cloud | Base de données vectorielle cloud managée et lakebase vectorielle des créateurs de Milvus, testée dans ses configurations Tiered et Capacity |
| Turbopuffer | Base de données vectorielle serverless testée en modes non épinglé et épinglé |
| Pinecone Serverless | Base de données vectorielle serverless mature à faible charge opérationnelle, utilisée comme point de référence courant en production |
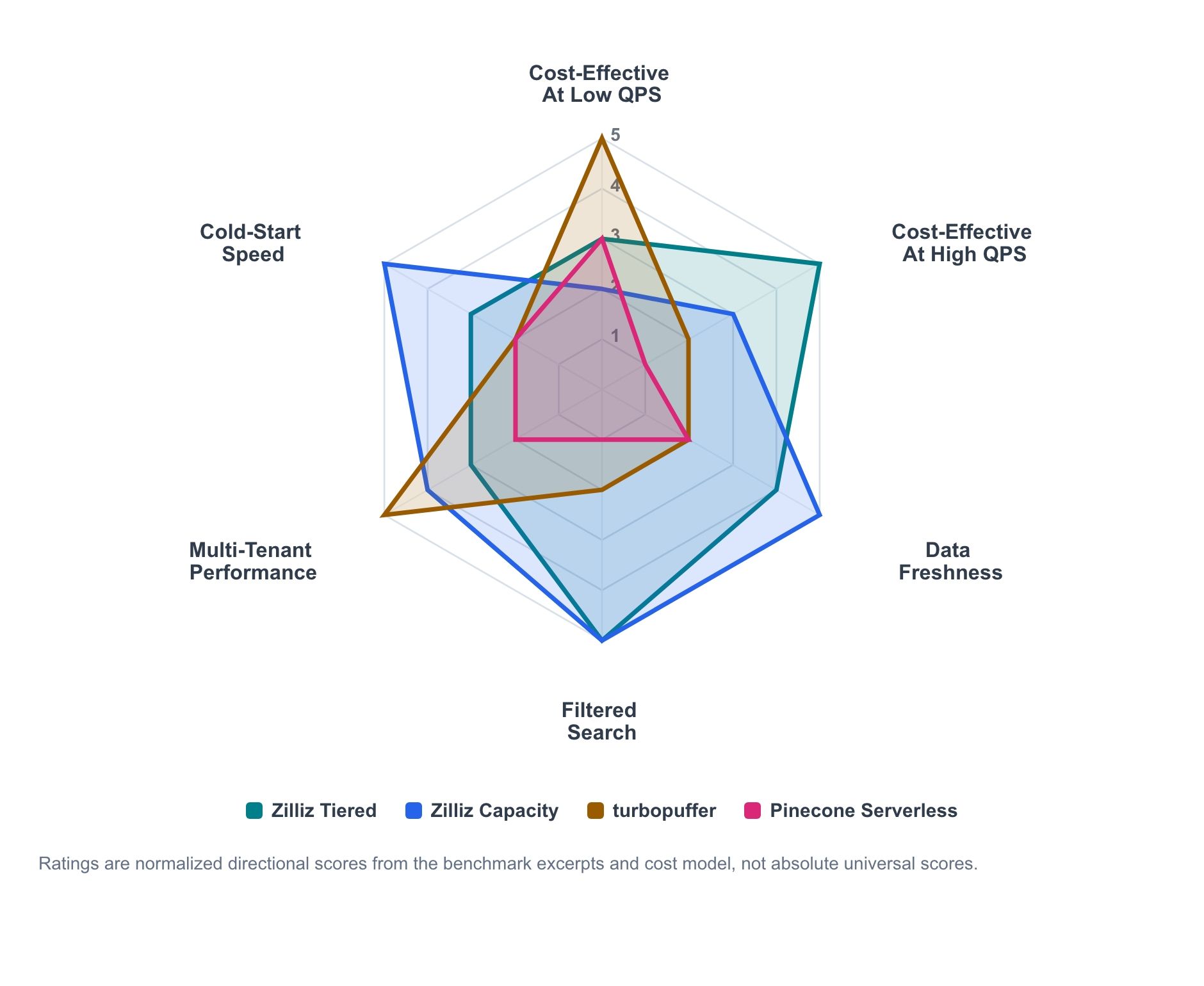
Figure 1. Résumé directionnel de l’adéquation aux charges de travail basé sur des extraits de benchmark et une modélisation des coûts. Les scores sont normalisés pour permettre la comparaison entre les dimensions de charge de travail et ne doivent pas être lus comme des classements absolus universels.
Le graphique radar résume le signal directionnel issu des extraits de benchmark et du modèle de coûts. Ce n’est pas un tableau de scores absolu ; c’est une carte indiquant où chaque produit tend à être le plus fort.
- Zilliz Cloud Tiered est la ligne économique de service actif qui monte en charge à mesure que l’utilisation augmente.
- Zilliz Cloud Capacity est le profil offrant davantage de contrôle pour un service prévisible, la fraîcheur et le comportement à froid.
- Turbopuffer est le plus performant lorsque l’économie serverless facturée à l’usage et le débit orienté namespace correspondent à la charge de travail.
- Pinecone reste une base de référence serverless utile à faible charge opérationnelle, même lorsqu’il n’est pas la frontière coût-performance dans un test donné.
Le schéma principal est clair. L’économie serverless peut être attrayante à faible QPS soutenu. La capacité provisionnée devient plus compétitive à mesure que l’utilisation augmente. La fraîcheur, la recherche filtrée, la taille de la charge utile, le nombre de tenants et le comportement à froid peuvent tous influencer la décision.
Jeux de données et charges de travail
Les cas tenant compte des coûts utilisent deux formes de charge de travail.
- Single-tenant LAION 100M : 100 millions de vecteurs denses à 768 dimensions. Cela représente une grande collection de production où la taille de la charge utile, les filtres, le rappel et le QPS soutenu comptent.
- Multitenant Cohere 10M : 10 millions de vecteurs denses à 768 dimensions, répartis aléatoirement entre 1 000 tenants — environ 10K vecteurs par tenant. Cela représente des charges de travail de type SaaS dans lesquelles chaque tenant dispose d’un jeu de données plus petit, mais le système doit router et servir efficacement de nombreux namespaces ou partitions de tenants.
Les extraits ci-dessous montrent la forme des résultats. Le Cost Leaderboard et le dépôt VectorDBBench restent la source des matrices complètes, des définitions des clients et des détails de reproduction.
CloudInsertCase : Inséré ne signifie pas toujours prêt
La performance d’insertion n’est pas un seul chiffre. Une base de données vectorielle managée peut accepter des données du client avant que ces données ne soient sûres à interroger via le chemin d’index prévu. Pour les charges de travail de production, les équipes doivent savoir quand l’opération d’insertion est terminée, quand les données deviennent interrogeables et quand l’indexation en arrière-plan est entièrement rattrapée.
CloudInsertCase mesure le cycle de vie de l’écriture au service. Cela importe pour les rafraîchissements de corpus RAG, les mises à jour de catalogues produits, les écritures de mémoire d’agents et les chargements rétrospectifs de données. Dans ces systèmes, « insert accepté » ne suffit pas. La question opérationnelle est de savoir quand les données nouvellement écrites peuvent être recherchées de manière fiable avec des performances de production.
| Produit / mode | Taille de lot | Temps d’insertion | Attente avant interrogeabilité | Attente avant indexation complète | Coût d’écriture |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10,000 | 3.2 h | 0 ms | 1.9 min | $9.50 |
| Zilliz Cloud Tiered 4CU | 10,000 | 4.1 h | 0 ms | 10.9 min | $6.34 |
| Turbopuffer (backpressure off) | 10,000 | 1.8 h | 6.4 h | 2.0 min | $302 |
| Pinecone Serverless | 10,000 | 72.4 h | 0 ms | 127 ms | $1,180 |
Tableau 1. Extrait d’insertion LAION 100M par lots de 10k. Les coûts et les durées proviennent de l’exécution actuelle du leaderboard. Pour les configurations Zilliz provisionnées, le coût d’écriture correspond au coût en CU-heures consommé pendant la fenêtre de chargement et d’indexation ; pour Turbopuffer et Pinecone, il s’agit des frais d’écriture mesurés à l’usage. Lisez les durées avec les définitions client des états inséré, interrogeable et entièrement indexé (définies par client dans la source VDBBench).
La taille des lots change les chiffres pour différents produits.
- Turbopuffer affiche une forte ingestion brute avec de grands lots, surtout lorsque la contre-pression est désactivée — son mode d’ingestion le plus agressif. Dans le parcours batch-10k, il termine l’insertion rapidement, mais l’attente de recherchabilité domine la fenêtre de disponibilité complète.
- Zilliz Cloud est plus stable selon les tailles de lots. Dans les configurations Capacity et Tiered testées, les données deviennent recherchables immédiatement après la fin de l’insertion, et l’attente restante jusqu’à l’indexation complète se mesure en minutes.
- Pinecone Serverless constitue la référence d’ingestion en masse la plus lente dans ce test. Une fois les données acceptées, l’attente supplémentaire pour être recherchables et entièrement indexées est effectivement nulle dans ces exécutions, mais l’étape d’insertion elle-même prend beaucoup plus de temps.
La lecture des produits dépend de la charge de travail.
- Zilliz convient aux workflows où les données fraîches doivent être rapidement recherchables et indexées à un coût prévisible.
- Turbopuffer convient aux grands backfills acceptés lorsque la charge de travail peut tolérer une fenêtre de disponibilité plus longue.
- Pinecone convient aux schémas d’ingestion serverless à plus faible volume, où la simplicité opérationnelle compte davantage que la vitesse ou le coût du chargement en masse.
Le chargement en masse est aussi un événement de coût. Dans ce cas d’insertion LAION 100M, les configurations Zilliz maintiennent le coût côté écriture dans une fourchette de quelques dollars pour le parcours batch-10k testé. Turbopuffer est modélisé autour de $302. Pinecone Serverless est modélisé autour de $1,180. Cela ne rend pas un modèle tarifaire universellement meilleur. Cela signifie que l’économie de l’insertion dépend de la fréquence à laquelle la charge de travail exécute ce parcours.
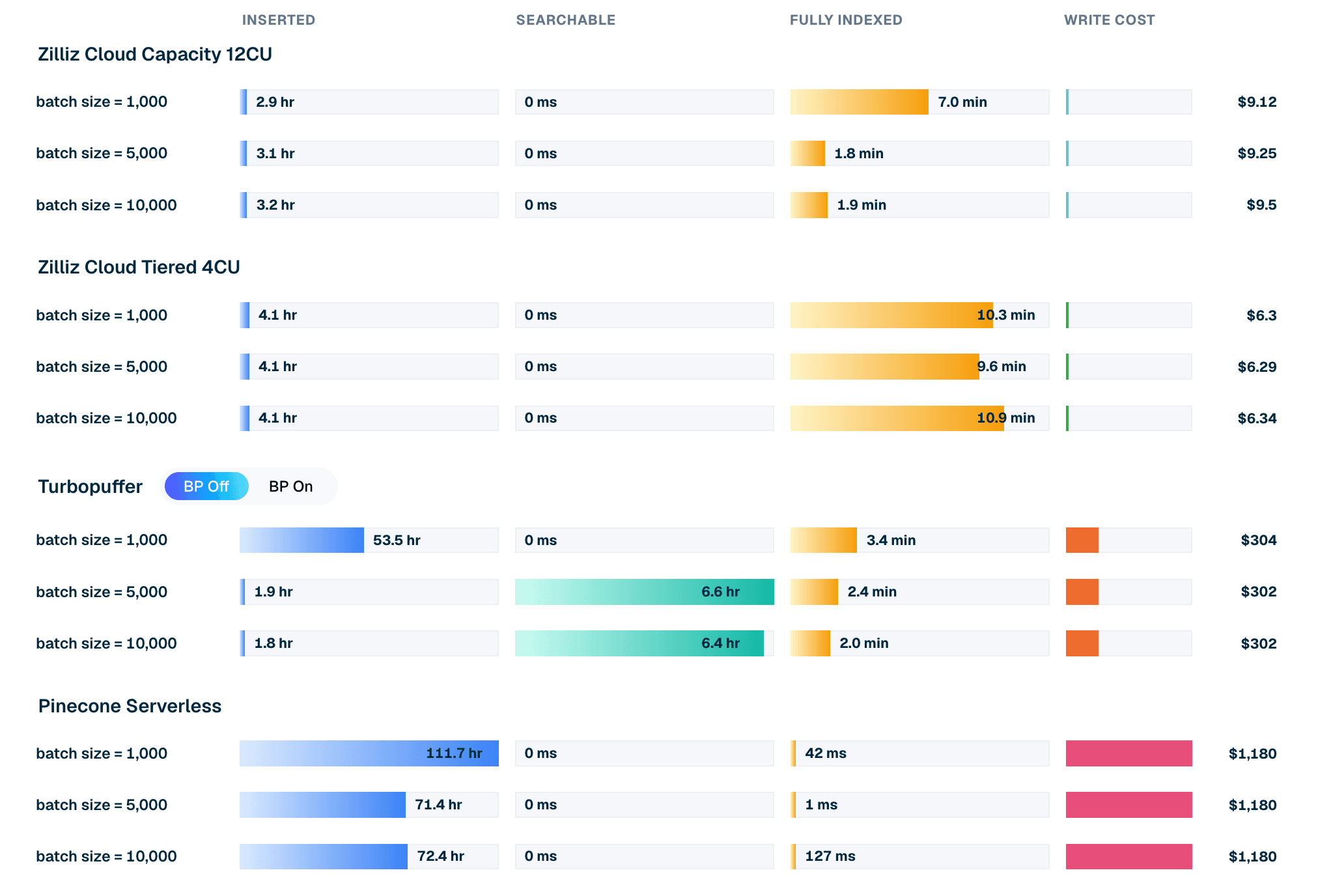
Figure 2. Cycle de vie de l’insertion pour LAION 100M avec un lot de 10k : temps d’insertion, attente de recherchabilité, attente d’indexation complète et coût d’écriture modélisé par produit.
CloudPayloadSearchCase : la charge utile modifie la surface de recherche
Une fois les données recherchables, la question suivante n’est pas seulement de savoir combien de requêtes par seconde la base de données peut traiter. La forme de la réponse compte. Renvoyer uniquement des IDs est très différent de renvoyer des métadonnées ou des vecteurs bruts. Un vecteur à 768 dimensions peut ajouter des milliers d’octets à chaque résultat. À topK=100, la taille de la charge utile peut devenir un facteur majeur dans le coût et la latence des requêtes.
CloudPayloadSearchCase teste LAION 100M en locataire unique avec différentes charges utiles de réponse et formes de filtre. Le résultat combine le QPS concurrent maximal, la latence P99 à cette concurrence, le type de charge utile et le rappel, lorsque disponible.
Une remarque sur la lecture des tableaux : ici, P99 est mesuré à la concurrence maximale — le point de saturation qui produit le QPS de pointe de chaque produit — et non à un point d’exploitation confortable de niveau de service. Il montre comment une configuration se comporte à sa limite mesurée.
| Produit | Latence P99 @ concurrence max | QPS max | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 ms | 786.1 | 0.9728 |
| turbopuffer | 2.34 s | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 ms | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 s | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 s | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 s | 4.6 | 0.9609 |
Tableau 2. LAION 100M en locataire unique, sans filtre, réponses IDs uniquement, topK 100. Remarque sur Pinecone : son débit dans ce cas en locataire unique est limité par la restriction des unités de lecture côté serveur, de sorte que l’exécution plafonne à une concurrence de 4–5, contre 80 pour les autres produits. Lisez ses lignes comme une référence serverless cadencée plutôt que comme un résultat de saturation.
La configuration compte. À 12CU, Zilliz Capacity et Turbopuffer sont proches en QPS brut dans ce cas large avec IDs uniquement, tandis que Zilliz est en avance sur le rappel et la latence P99. À 32CU, Zilliz Capacity dépasse le résultat Turbopuffer testé pour cette charge de travail en locataire unique.
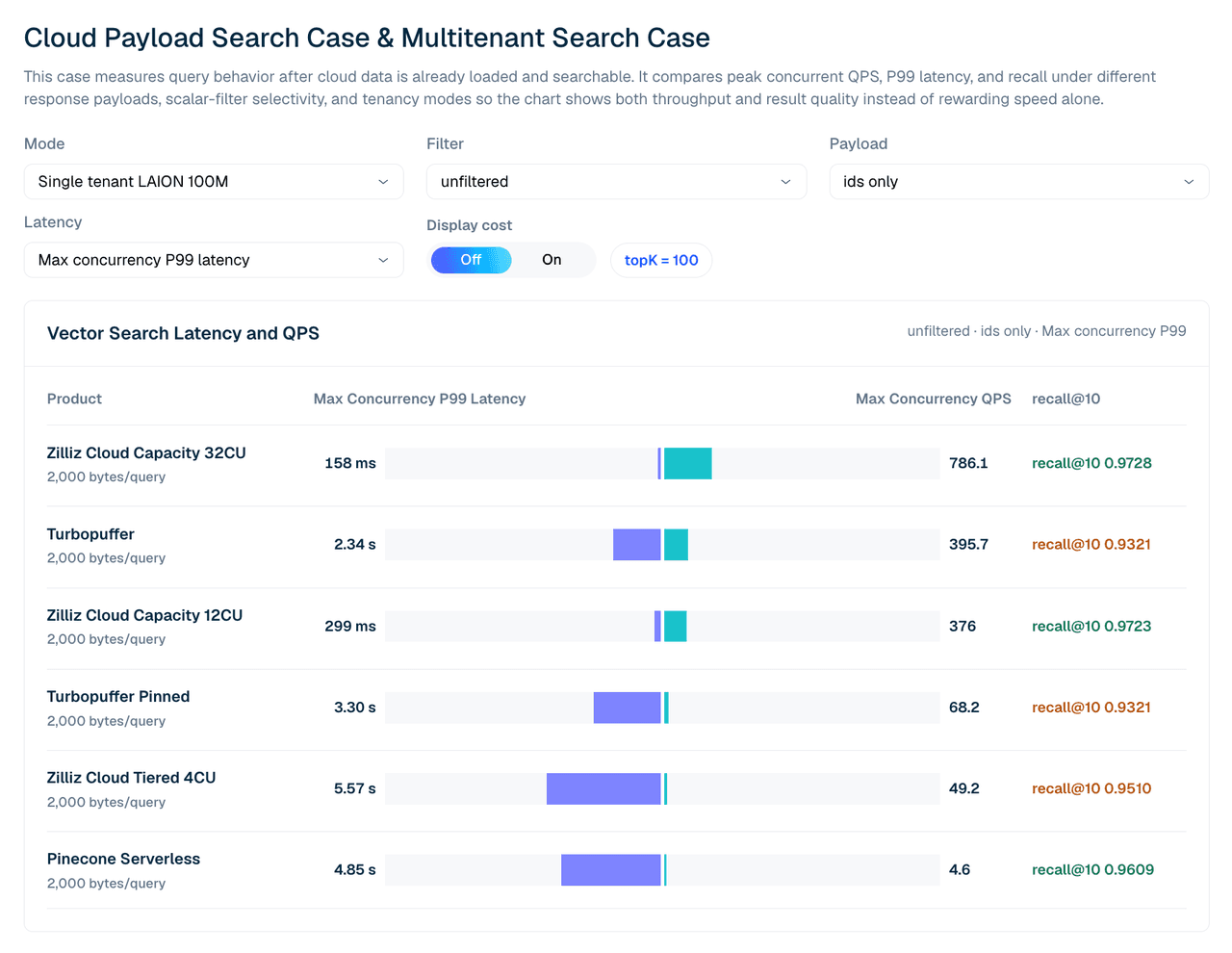
Figure 3. Recherche LAION 100M en locataire unique avec réponses IDs uniquement. Cette vue compare le QPS concurrent maximal, la latence P99 et recall@10 entre les configurations managées testées.
La question n’est pas seulement de savoir quel produit est le plus rapide dans une configuration donnée. Elle est de savoir comment les performances évoluent lorsqu’une équipe achète davantage de capacité, modifie la forme du payload ou doit atteindre un objectif de rappel. Lorsque la requête renvoie des payloads vectoriels bruts, le débit peut changer de manière significative.
| Produit | QPS IDs uniquement | QPS payload vectoriel | Rappel |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
Tableau 3. Extrait de payload pour une récupération large non filtrée. Les équipes doivent évaluer la forme de payload que leur application renvoie réellement, et pas seulement la recherche IDs uniquement.
Recherche filtrée : là où la sélectivité compte
De nombreuses charges de travail de recherche vectorielle en production sont soumises à des permissions ou à des filtres. Un copilote de support peut ne rechercher que les documents que l’utilisateur est autorisé à consulter. Un système de recommandation peut filtrer par région, catégorie, vendeur ou disponibilité. Une application de recherche d’entreprise peut appliquer des contraintes de tenant, de contrôle d’accès, de fraîcheur et de type de document avant de classer les résultats.
Ces filtres ne sont pas cosmétiques. Ils changent le chemin d’exécution. Au point de stress avec filtre entier à 99,9 % plus payload vectoriel, le comportement des produits change fortement.
| Produit | QPS max | Rappel | Latence P99 |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
Tableau 4. Point de stress avec filtre sélectif single-tenant : filtre entier à 99,9 % avec payload vectoriel. Le rappel pour l’exécution Pinecone Serverless à ce point de stress n’était pas encore disponible au moment de la publication ; son QPS et sa latence proviennent de l’exécution mesurée.
C’est l’un des exemples les plus clairs montrant pourquoi l’évaluation tenant compte des coûts nécessite plusieurs formes de charge de travail. Un produit performant sur une récupération large non filtrée n’est pas nécessairement le meilleur choix pour une recherche filtrée sélective. Pour la recherche avec permissions, le RAG fortement axé sur le contrôle d’accès ou les charges de travail à forte sélectivité de filtre, les lignes filtrées peuvent compter davantage que les lignes non filtrées.
MultitenantSearchCase : de nombreux petits tenants se comportent différemment
Les benchmarks single-tenant ne capturent pas toutes les charges de travail cloud.
De nombreuses applications d’IA ont une forme SaaS. Un produit peut servir des milliers de tenants, chacun avec un jeu de données plus petit. Le défi opérationnel n’est pas seulement la recherche vectorielle dans une seule grande collection. Il s’agit du routage, de l’isolation, de la gestion des namespaces et du maintien du débit sur de nombreuses petites partitions.
Le cas multitenant utilise le jeu de données Cohere 10M réparti sur 1 000 tenants. La forme de requête utilise topK 50 et compare les lignes IDs uniquement, payload vectoriel et filtrées.
Deux notes de configuration influencent la lecture de ce tableau.
Premièrement, les configurations Zilliz ici sont intentionnellement petites — Tiered 1CU et Capacity 2CU, juste assez pour contenir le jeu de données Cohere 10M. Le cas single-tenant ci-dessus montre déjà que le QPS de Zilliz évolue avec le nombre de CU ; la question que pose ce cas est la rentabilité dans une configuration dimensionnée pour les données, et non le débit maximal.
Deuxièmement, la colonne Pinecone est une exécution détachée à faible concurrence (concurrency 4), non normalisée par rapport aux lignes à concurrence plus élevée ; il faut donc la considérer comme du contexte plutôt que comme une comparaison directe.
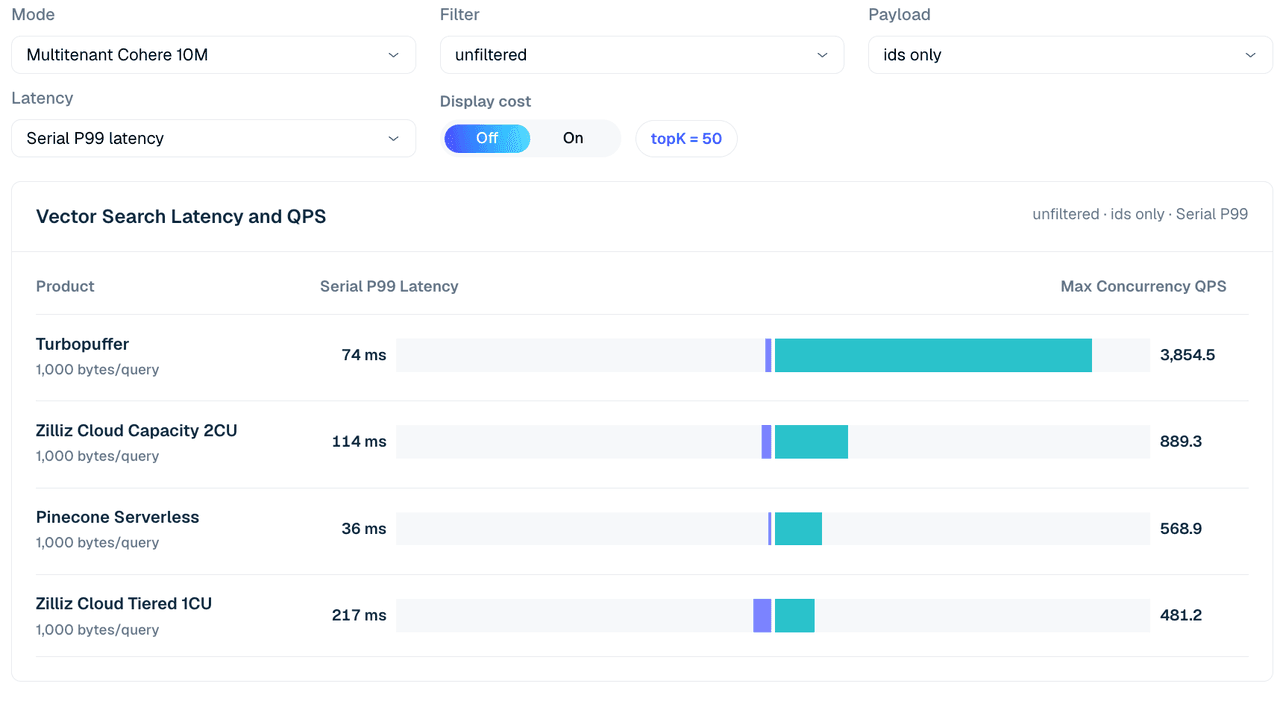
Figure 4. Recherche multitenant Cohere 10M sur 1 000 tenants, non filtrée IDs uniquement, topK 50. La vue compare la latence P99 en série et le QPS concurrent maximal entre les configurations testées ; le tableau ci-dessous ajoute les variations de payload et de filtre.
| Cas | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| Non filtré, IDs uniquement | 481 | 889 | 3,855 | 569 |
| Non filtré, vecteur | 34 | 371 | 1,775 | 542 |
| Filtre entier 99,9 %, vecteur | 625 | 1,307 | 3,835 | 526 |
| Libellé scalaire 1 %, vecteur | 152 | 588 | 1,767 | 600 |
| Libellé scalaire 50 %, vecteur | 29 | 317 | 1,760 | 562 |
Tableau 5. Extrait de recherche multitenant sur 1 000 tenants, topK 50.
Dans ce mode, Turbopuffer est performant sur toute la ligne. Il atteint 3 855 QPS sur une recherche non filtrée avec IDs uniquement et 3 835 QPS sur la ligne filtre entier sélectif/vecteur. Zilliz Cloud Capacity 2CU reste le profil Zilliz le plus performant dans cet extrait, atteignant 889 QPS en non filtré avec IDs uniquement et 1 307 QPS sur la ligne filtre entier 99,9 %/vecteur.
La lecture produit dépend encore une fois de la charge de travail. Turbopuffer convient très bien à de nombreux tenants légers et au débit orienté namespace. Zilliz est plus solide lorsque les charges de travail sont filtrées, soumises à des autorisations, sensibles au rappel ou plus lourdes par tenant, surtout lorsque les équipes peuvent choisir une configuration Zilliz Capacity correspondant à l’objectif de service.
CloudColdLatencyCase : la première requête après une période d’inactivité
Les boucles de benchmark à chaud peuvent masquer le comportement à froid. Pour de nombreuses applications d’IA en production, en particulier la mémoire d’agent, le RAG de longue traîne et les charges de travail de tenants peu fréquentes, la première requête après une période d’inactivité compte. Un système peut sembler rapide après préchauffage, mais ajouter des secondes de latence lorsqu’une collection, un namespace ou un chemin de cache froid est de nouveau consulté.
CloudColdLatencyCase isole ce comportement. Il mesure la première requête contre une collection restée inactive pendant au moins 24 heures — suffisamment longtemps pour que les caches et les chemins de service deviennent aussi froids qu’ils peuvent l’être de façon réaliste — et la compare à la première requête sur le chemin réchauffé du même run.
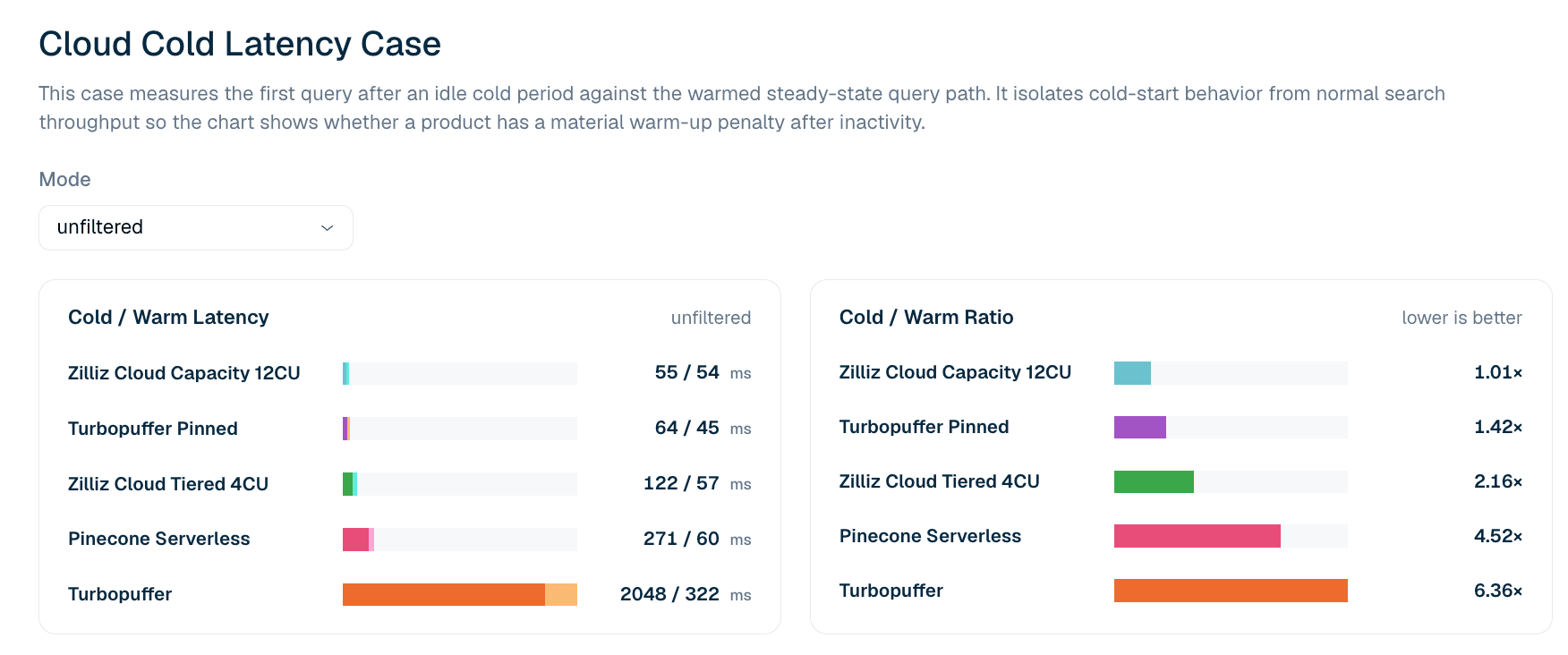
Figure 5. Latence de la première requête après inactivité par rapport au chemin de requête réchauffé pour la recherche LAION 100M non filtrée. Le ratio froid/chaud met en évidence si un produit présente une pénalité matérielle de première requête après inactivité.
| Produit | Première requête après inactivité | Première requête à chaud | Ratio froid/chaud |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
Tableau 6. Extrait de latence de première requête à froid et à chaud pour LAION 100M non filtré. Le cas rapporte la latence de première requête plutôt que les percentiles de queue : les ratios froid/chaud au P99 tendent à capter du bruit réseau dans les requêtes ultérieures qui ne se reproduit pas de façon fiable, de sorte que le classement utilise la définition plus stricte de première requête.
Dans le cas actuel de latence à froid non filtrée, Zilliz Cloud Capacity 12CU affiche le profil froid-chaud le plus serré : 55 ms à froid et 54 ms à chaud, soit un ratio de 1.01x. Turbopuffer pinned présente également un profil solide, à 64 ms à froid et 45 ms à chaud. Turbopuffer non pinned montre une pénalité à froid plus importante : 2 048 ms à froid et 322 ms à chaud, soit un ratio de 6.36x.
La latence à froid doit toujours être lue conjointement avec le coût. Les réplicas pinned et la capacité provisionnée peuvent réduire les pénalités de premier accès, mais ils modifient le modèle économique. Un produit peut présenter un excellent comportement à froid parce qu’il conserve davantage de chaleur. Cela peut être le bon compromis pour les applications interactives, mais ne doit pas être dissocié du coût de maintien de ce chemin.
Lignes de Pareto des coûts : là où les modèles de tarification se croisent
Une grille tarifaire ne suffit pas. Un prix unitaire bas n’aide pas si le produit ne peut pas atteindre le QPS cible. Une configuration à haut débit n’est pas attractive si elle coûte plus cher qu’un autre produit qui satisfait aux mêmes exigences de latence, de rappel et de charge utile.
La vue Pareto des coûts combine les limites de benchmark mesurées avec les modèles de tarification. Pour le scénario LAION 100M avec requêtes uniquement, chaque gamme de produits s’arrête au QPS maximal observé dans le benchmark. Le graphique estime ensuite le coût d’exploitation à des niveaux de QPS cibles et indique les choix Pareto-optimaux sous ces contraintes mesurées.
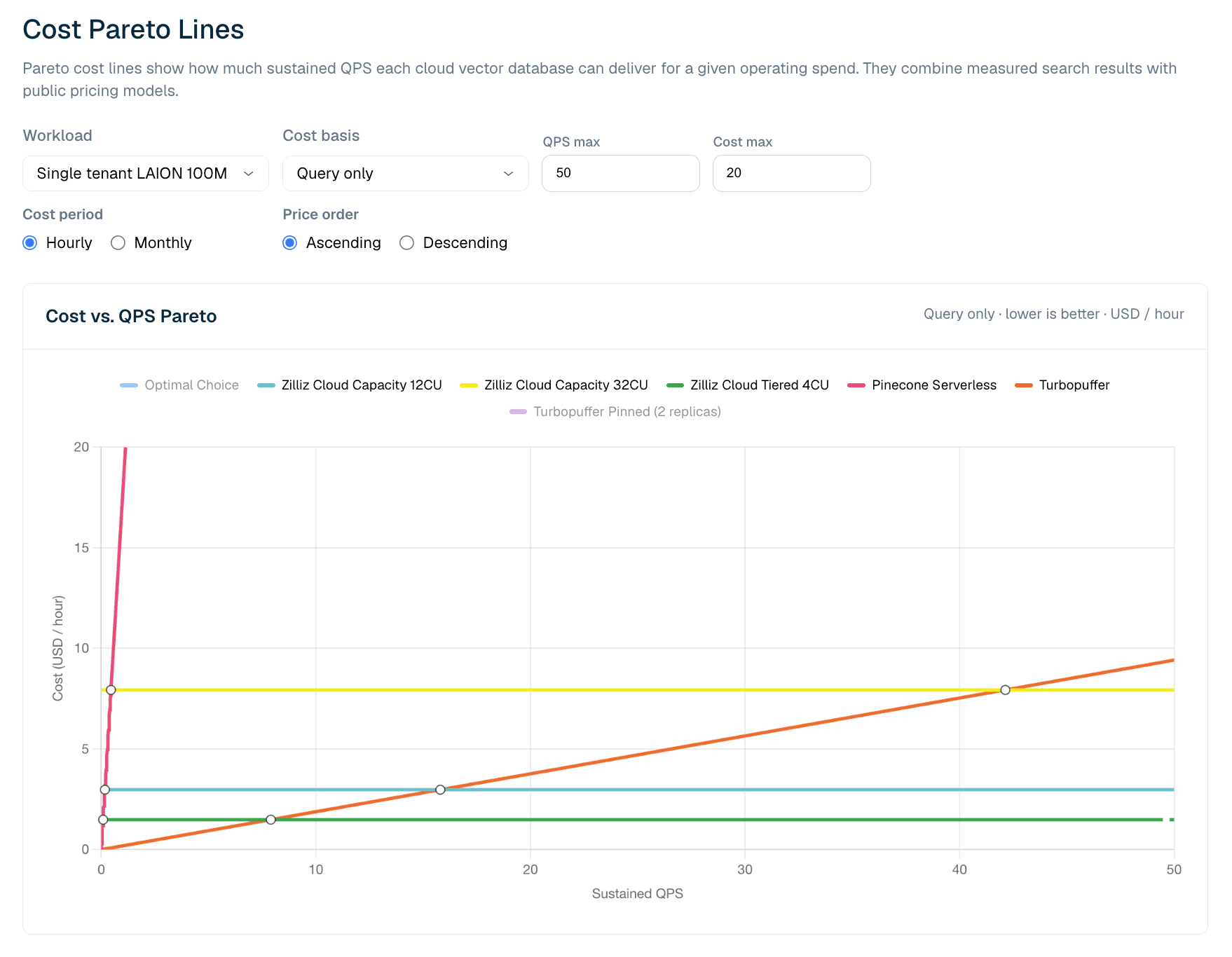
Figure 6. Coût vs QPS soutenu pour les charges de travail LAION 100M avec requêtes uniquement. La vue Pareto montre où la tarification serverless est plus efficace à faible QPS et où les configurations Zilliz provisionnées deviennent plus rentables à mesure que l’utilisation augmente.
Dans le modèle actuel LAION 100M avec requêtes uniquement, Turbopuffer présente un avantage à très faible QPS soutenu. Le point de croisement mesuré se situe à environ 8 QPS : en dessous, la tarification des requêtes mesurée à l’usage de turbopuffer est la ligne la moins chère ; au-dessus, Zilliz Cloud Tiered 4CU devient moins cher, car son coût de service en CU-heure est principalement fixe une fois provisionné. À mesure que le QPS augmente, l’utilisation s’améliore et la capacité provisionnée devient plus rentable.
Cela ne signifie pas que le serverless est moins bon. Cela signifie que les économies du serverless et du provisionné se croisent. Pour les charges de travail faibles, irrégulières ou imprévisibles, le serverless mesuré à l’usage peut être le meilleur choix. Pour le trafic de production soutenu, un modèle fixe en CU-heure peut devenir moins cher une fois que l’utilisation dépasse le point de croisement. Pour les équipes qui ont besoin d’enveloppes de service plus robustes, d’un meilleur comportement à froid ou d’un contrôle opérationnel, Zilliz Capacity peut être le bon profil même lorsque Tiered est la ligne la moins coûteuse.
Zilliz Cloud vs. Turbopuffer vs. Pinecone : meilleur choix selon la charge de travail
| Forme de la charge de travail | Signal le plus fort | Pourquoi |
|---|---|---|
| QPS soutenu très faible | turbopuffer | Les économies du serverless mesuré à l’usage sont attractives avant le point de croisement à faible QPS |
| QPS soutenu au-dessus du point de croisement (~8 QPS dans ce modèle) | Zilliz Cloud Tiered | Les économies fixes en CU-heure s’améliorent à mesure que l’utilisation augmente |
| Données fraîches ou actualisations fréquentes | Zilliz Cloud Capacity / Tiered | Le délai insertion-recherche et la disponibilité entièrement indexée sont solides dans le cas d’insertion LAION 100M |
| Forte sensibilité au coût de chargement complet | Zilliz Cloud Capacity / Tiered | Le coût côté écriture est beaucoup plus faible dans le chemin de chargement en masse LAION 100M testé |
| Recherche large de payload non filtrée | Turbopuffer et Zilliz Capacity 32CU | Turbopuffer est performant en récupération large ; Zilliz évolue avec davantage de capacité |
| Filtres sélectifs ou recherche avec permissions | Zilliz Cloud Capacity / Tiered | Zilliz affiche un QPS beaucoup plus élevé et une latence P99 plus faible au point de stress avec filtre à 99,9 % |
| Nombreux locataires légers | turbopuffer | QPS brut le plus élevé dans l’extrait à 1 000 locataires |
| Applications interactives sensibles au démarrage à froid | Zilliz Cloud Capacity ; Turbopuffer pinned | Les deux réduisent les pénalités de première requête, avec des modèles de coûts différents |
| Base serverless à faible charge opérationnelle | Pinecone Serverless | Point de référence serverless mature, même lorsqu’il n’est pas à la frontière dans cette charge de travail |
Comment utiliser ces résultats de benchmarking
VDBBench et son Cost Leaderboard sont conçus pour rapprocher l’évaluation des bases de données vectorielles de la manière dont les équipes achètent et exploitent réellement les produits cloud managés. Le QPS maximal reste important, mais il ne suffit plus à lui seul. La question la plus utile est de savoir si un produit peut répondre simultanément aux exigences de la charge de travail en matière de latence, de rappel, de fraîcheur, de payload, de tenancy et de coût.
Un flux d’évaluation pratique ressemble à ceci :
- Utilisez le Performance Leaderboard pour comprendre la capacité brute de service dans des conditions de benchmark contrôlées.
- Utilisez le Cost Leaderboard pour comprendre les compromis coût-performance entre les produits cloud managés et les formes de charges de travail.
- Utilisez VDBBench lui-même pour reproduire les cas, tester d’autres produits ou exécuter le benchmark sur des données et des distributions de requêtes proches de la production.
Les résultats actuels doivent être lus avec plusieurs réserves.
- Les produits ont été évalués le 10 mai 2026, et le modèle de coût utilise les tarifs AWS us-west-2 en vigueur à cette date. Les tarifs peuvent varier selon la date et la région.
- Les choix de configuration, tels que les modes épinglés, la capacité provisionnée, les contrôles de mise à l’échelle et la limitation serverless, peuvent affecter les résultats.
- Les états de disponibilité ne sont pas toujours exposés de la même manière, les définitions d’inséré, interrogeable et entièrement indexé doivent donc être vérifiées pour chaque client.
- Enfin, les charges de travail sont spécifiques par conception. Les résultats Pareto en matière de coût doivent toujours être lus conjointement avec la latence, le rappel, la forme de la charge utile et les limites de service mesurées.
Évaluez vos propres charges de travail
Le Cost Leaderboard est un instantané public des résultats actuels, mais le changement le plus important se trouve dans VDBBench lui-même. Il permet désormais aux équipes d’évaluer ensemble les performances et les coûts par rapport à des contraintes propres à la charge de travail : fraîcheur, taille de la charge utile, forme des tenants, comportement à froid et modèle opérationnel.
Un produit serverless peut être bien adapté à un faible QPS soutenu. La capacité provisionnée peut devenir plus rentable lorsque l’utilisation augmente. Un système peut dominer la recherche large, tandis qu’un autre peut être plus performant avec des filtres sélectifs, des rafraîchissements fréquents ou des charges de travail sensibles aux démarrages à froid.
L’objectif n’est pas d’obtenir le meilleur chiffre accrocheur. C’est de trouver la meilleure adéquation avec votre charge de travail.
- Consultez les résultats actuels : VDBBench Cost Leaderboard
- Reproduisez ces cas, ou évaluez vos propres candidats : VectorDBBench sur GitHub
- Des questions ou des résultats à partager ? Ouvrez une issue sur GitHub ou rejoignez la conversation sur Discord

Continuer à lire

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.