




Comment détecter et corriger les erreurs logiques des modèles de la GenAI ?
Introduction
Les [grands modèles de langage (LLM)] (https://zilliz.com/blog/will-retrieval-augmented-generation-RAG-be-killed-by-long-context-LLMs) ont transformé le domaine de l'IA, en particulier l'IA conversationnelle, la génération de texte, etc. Les LLM sont entraînés sur des quantités massives de données avec des milliards de paramètres pour générer du texte comme des humains. De nombreuses entreprises sont impatientes de développer des chatbots basés sur les LLM pour répondre aux questions des clients, prendre des avis, résoudre des réclamations, etc. Alors que l'utilisation et l'adoption du LLM se développent, nous devons nous attaquer à un problème critique : Les fautes de logique dans les résultats des LLM. Il est essentiel de relever ce défi et de rendre les systèmes d'IA plus responsables et dignes de confiance.
Jon Bennion, un ingénieur en IA doté d'une riche expérience en ML appliquée, en sécurité de l'IA et en évaluation, a récemment discuté d'une approche intéressante pour s'attaquer aux sophismes logiques lors du Unstructured Data Meetup organisé par Zilliz. Jon est un contributeur important à LangChain, mettant en œuvre de nouvelles approches pour traiter les fallacies dans les résultats.
Regarder l'intervention de Jon
Au cours de sa présentation, Jon explique les pièges courants du raisonnement par modèle qui peuvent conduire à des erreurs logiques. Il aborde également les stratégies d'identification et de correction de ces erreurs, en soulignant l'importance d'aligner les résultats du modèle sur un raisonnement logique et humain.
Qu'est-ce qu'une erreur logique ?
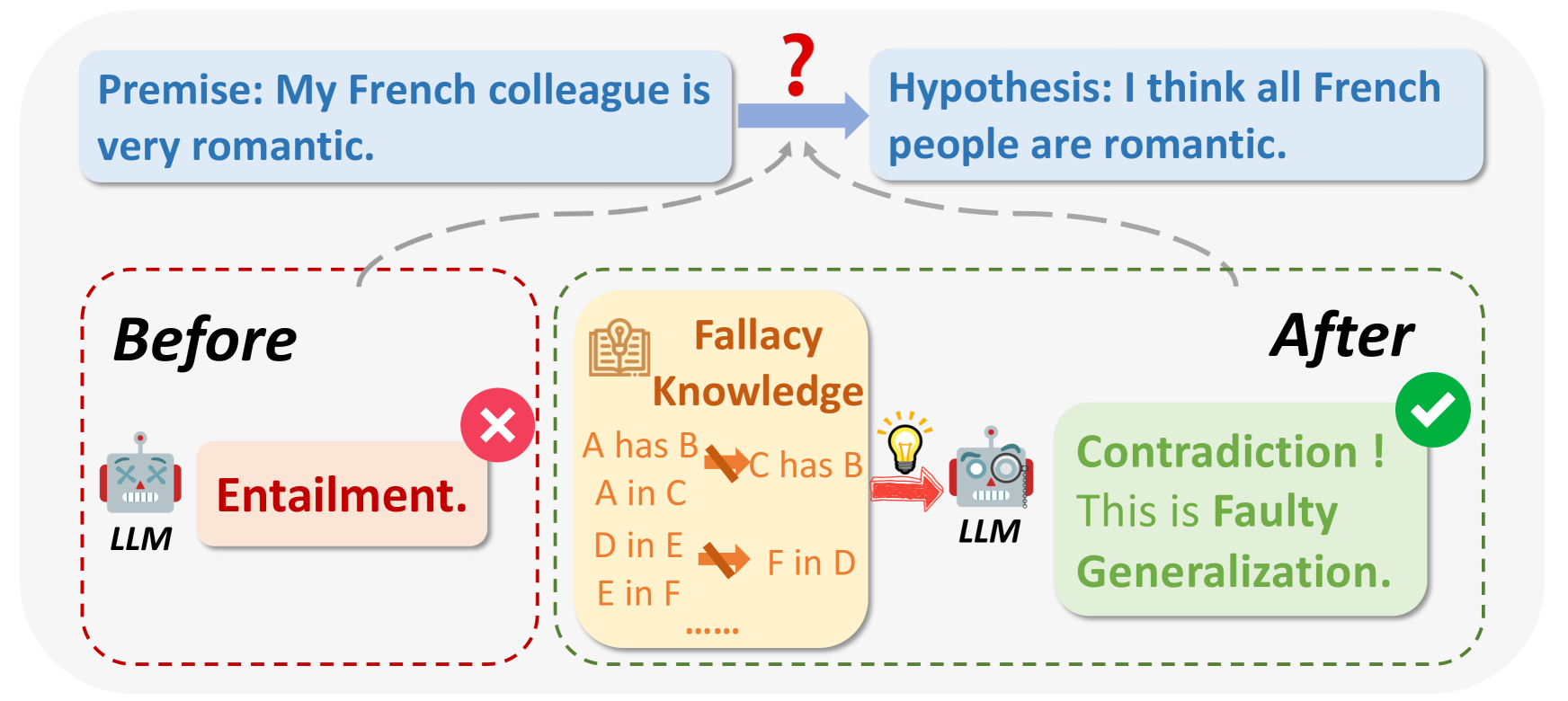
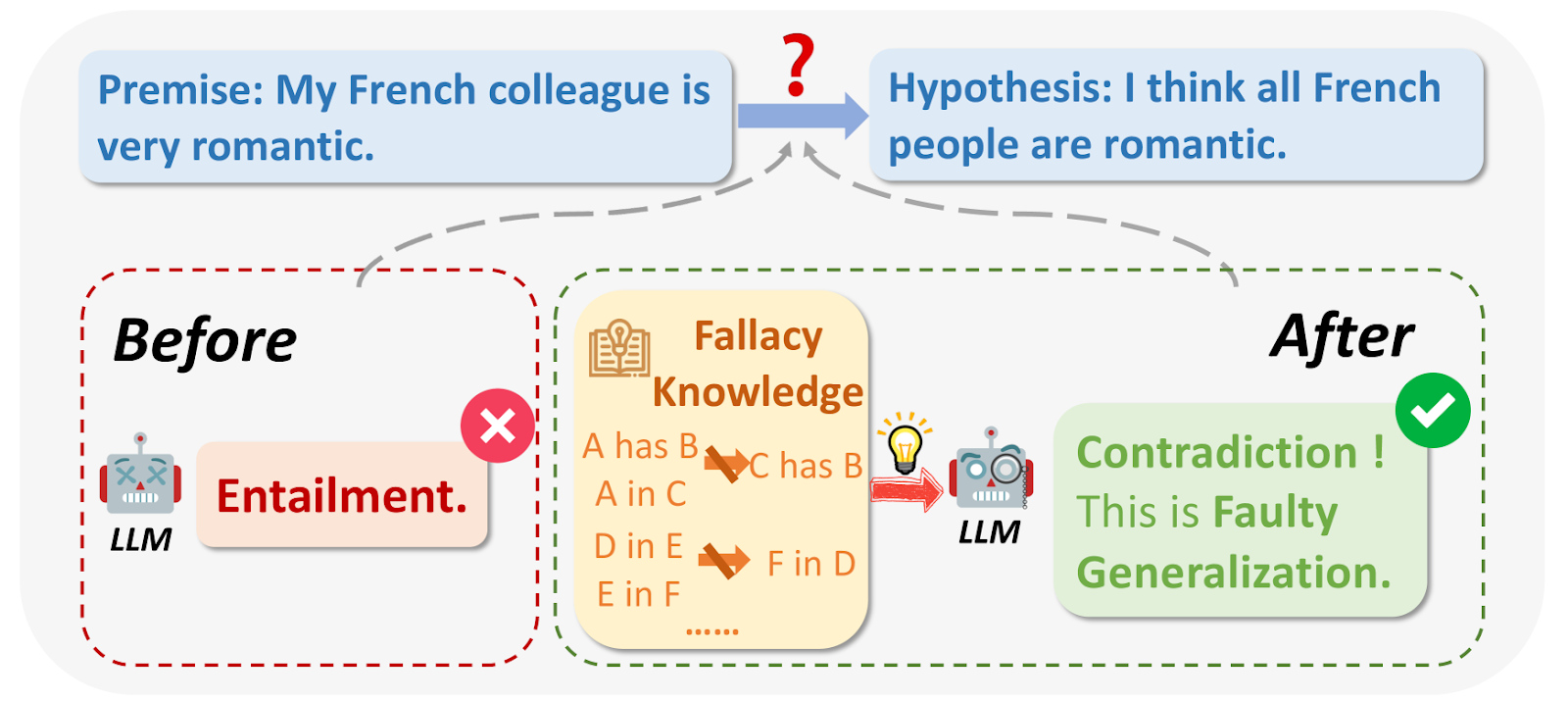 Qu'est-ce que les sophismes ?.png
Qu'est-ce que les sophismes ?.png
Fig 1 : Qu'est-ce qu'un sophisme logique ?
Source de l'image:_https://arxiv.org/html/2404.04293v1/x1.png
Lors de l'interrogation des LLM, dans certains cas, les résultats peuvent être erronés pour des raisons logiques ou ne pas correspondre à la question. Les sophismes logiques comprennent Ad Hominem, le raisonnement circulaire, l'appel à l'autorité, etc. Ils font souvent de grandes généralisations basées sur des échantillons de petite taille, par exemple : "Mon ami français est grossier, donc tous les Français doivent être grossiers".
Dans certains cas, ils peuvent supposer qu'une chose est vraie ou juste parce qu'elle est populaire.
Exemple : "Tout le monde utilise cette nouvelle application, elle doit donc être la meilleure". Parfois, les MFR ont du mal à se souvenir des détails de la conversion précédente et ne peuvent pas fournir une réponse précise.
Pourquoi les fautes de logique se produisent-elles ?
Il existe de multiples raisons pour lesquelles des erreurs logiques peuvent se produire. Comme nous le savons tous, les LLM ne sont pas parfaitement formés pour faire face à toutes les situations de la même manière que notre cerveau les comprendrait.
Données de formation imparfaites
Les données de formation que nous fournissons proviennent de diverses sources sur Internet et ne sont pas parfaites. Elles contiennent de nombreux biais humains, des incohérences et même des informations erronées dans certains cas. Au cours de la formation, le LLM est exposé à des raisonnements erronés et incohérents qu'il apprend également. Si les données d'apprentissage contiennent des arguments erronés, il reprendra ces modèles et les imitera dans ses réponses.
Petite fenêtre contextuelle
Dans son exposé, Jon mentionne qu'"une petite fenêtre contextuelle peut causer des problèmes dans la réponse. De nombreuses équipes s'efforcent d'optimiser la fenêtre contextuelle en fonction des besoins en mémoire et des performances".
La fenêtre de contexte se réfère à la quantité d'informations qu'un LLM peut prendre en compte à un moment donné, et elle est fixe. Lorsque la fenêtre contextuelle est petite, le modèle peut manquer des détails importants et ne peut pas former une réponse cohérente. Il peut en résulter des erreurs telles que des généralisations hâtives ou de fausses dichotomies.
Nature probabiliste
Les LLM génèrent des textes en se basant sur le mot le plus probable de la séquence. Ils ne peuvent pas comprendre la véritable signification des mots comme le font les humains. Nous formons les modèles pour qu'ils atteignent une cohérence locale en fonction du contexte. Parfois, cela peut entraîner des erreurs logiques, car le contexte plus large peut ne pas être pris en compte.
Comment s'attaquer aux fautes de logique ?
Il est essentiel de détecter et d'empêcher le LLM de produire des réponses dont la logique est erronée afin que les utilisateurs puissent lui faire confiance. Jon discute brièvement des pratiques courantes utilisées pour résoudre ce problème, telles que le retour d'information humain, l'apprentissage par renforcement, l'ingénierie d'aide, etc.
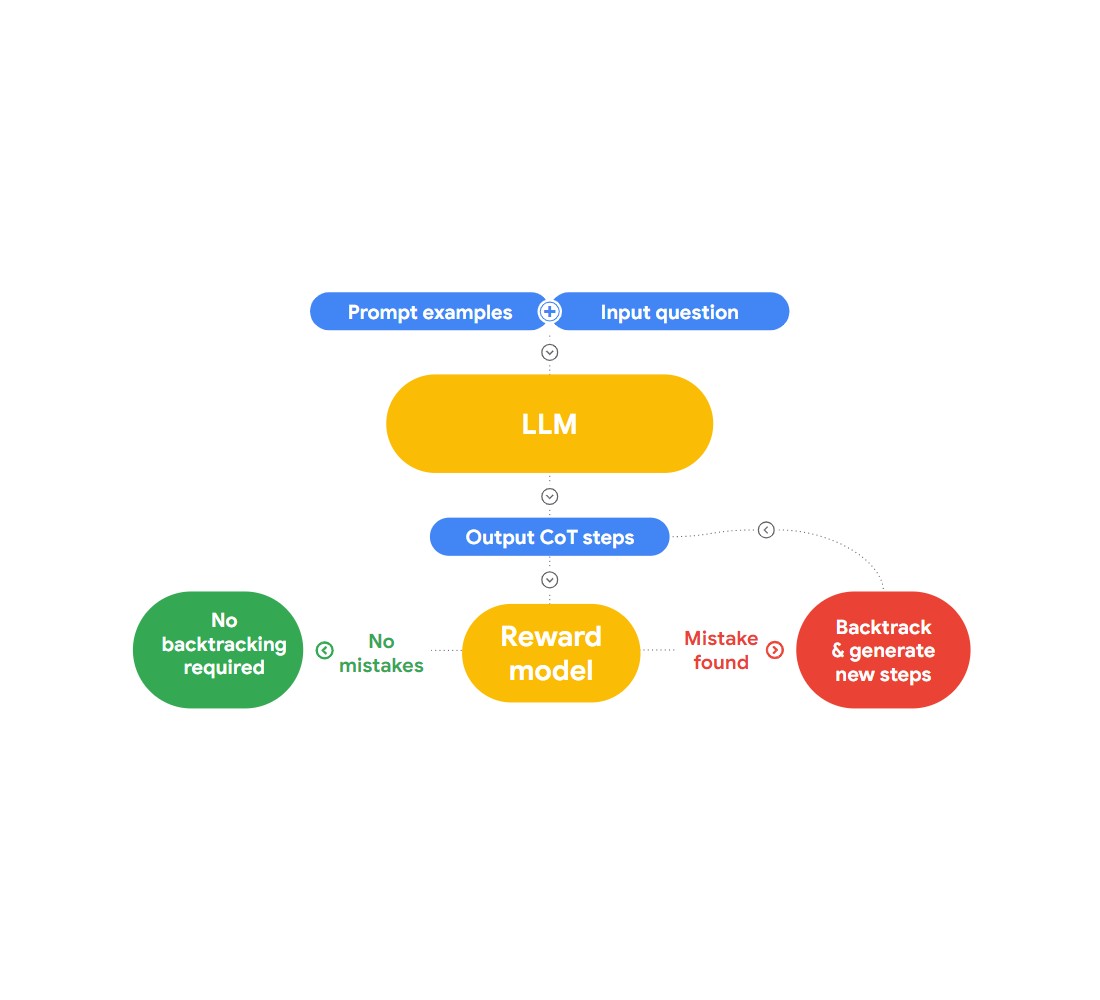
Dans cet exposé, Jon présente une approche intéressante de la détection et de la correction des fautes de logique, "RLAIF". L'idée est d'utiliser l'IA pour se corriger elle-même.
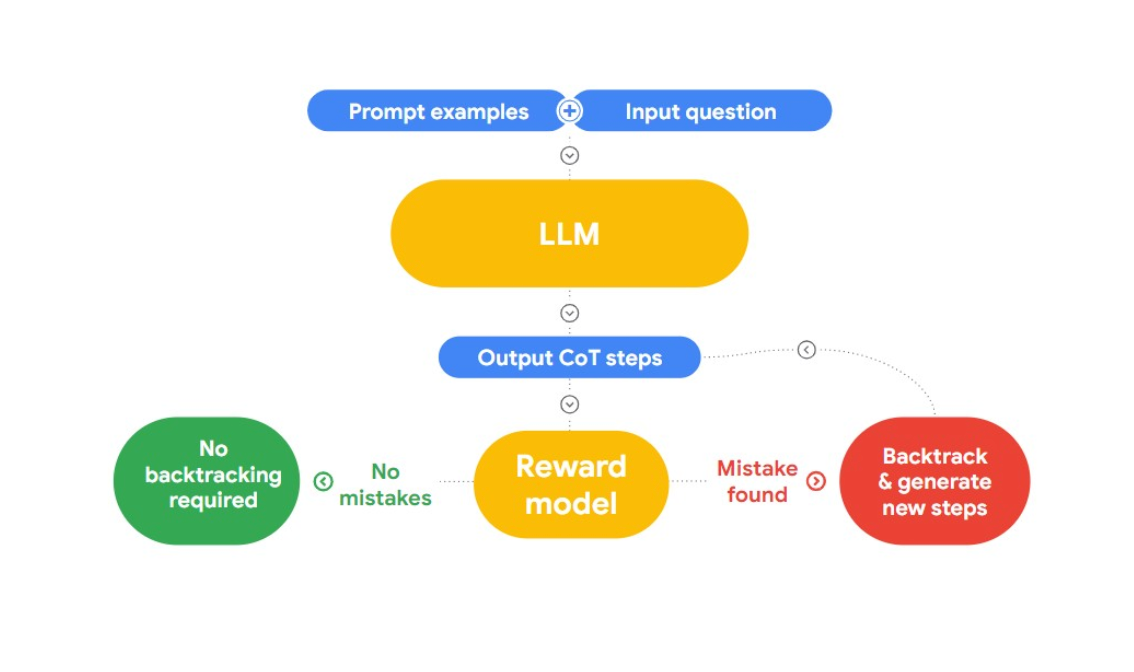
Fig 2 : Comment fonctionne RLAIF?
Il fait référence au document de recherche "Case-based Reasoning with Language Models for Classification of Logical Policies", qui est utile pour notre problème. Ce document présente le [raisonnement basé sur les cas (CBR)] (https://arxiv.org/abs/2301.11879), qui permet de classer les sophismes logiques. Il fonctionne en trois étapes :
**Récupération : nous fournissons à CBR une collection de données textuelles (base de cas) contenant des fautes de logique et identifiées par des humains. Lorsqu'un nouveau texte est fourni, CBR effectue une recherche dans la base de cas pour trouver un cas similaire.
Adaptation: Les cas récupérés sont ensuite adaptés au contexte spécifique du nouvel argument, en tenant compte de facteurs tels que les objectifs, les explications et les contre-arguments.
Classification: Sur la base des informations disponibles, CBR identifie et classifie les fautes de logique.
Jon a repris cette approche, l'a développée et a mis en œuvre une fonction de détection des fautes dans [LangChain] (https://zilliz.com/learn/LangChain).
Prévenir les sophismes en utilisant la chaîne de sophismes de LangChain
Jon montre un exemple en demandant au modèle de fournir des résultats comportant des fautes de logique. L'exemple ci-dessous montre une sortie qui souffre d'un "appel à l'autorité" et qui est logiquement erronée.
# Exemple d'une sortie de modèle renvoyée avec une erreur de logique
misleading_prompt = PromptTemplate(
template="""Vous devez répondre en utilisant uniquement les sophismes logiques inhérents aux explications de votre réponse.
Question : {question}
Mauvaise réponse :""",
input_variables=["question"],
)
llm = OpenAI(temperature=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="Comment puis-je savoir que la terre est ronde ?")
La sortie :
'La terre est ronde parce que mon professeur l'a dit, et tout le monde croit mon professeur'
Il s'agit d'une méthode de rétro-ingénierie qui consiste à repérer les erreurs que le modèle a apprises et à l'empêcher de les utiliser.
Jon a expliqué comment nous pouvions utiliser le module FallacyChain de LangChain pour effectuer des corrections. Tout d'abord, nous initialisons un LangChain avec l'invite trompeuse pour mettre en évidence les faussetés inhérentes présentes.
fallacies = FallacyChain.get_fallacies(["correction"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain,
sophismes = sophismes,
llm=llm,
verbose=Vrai,
)
fallacy_chain.run(question="Comment puis-je savoir que la terre est ronde ?")
Ensuite, nous initialisons une chaîne d'erreurs, en fournissant la chaîne trompeuse en entrée et le modèle LLM. Il détectera le type d'erreur présent et mettra à jour la réponse en l'éliminant.
> Entrée d'une nouvelle chaîne FallacyChain...
Réponse initiale : La terre est ronde parce que mon professeur l'a dit et que tout le monde croit mon professeur.
Application de la correction...
Critique du sophisme : La réponse du modèle fait appel à l'autorité et à l'ad populum (tout le monde croit le professeur). Critique de l'erreur nécessaire.
Réponse mise à jour : Vous pouvez trouver des preuves de l'existence d'une terre ronde grâce à des preuves empiriques telles que des photos prises dans l'espace, des observations de navires disparaissant à l'horizon, l'observation de l'ombre incurvée de la lune ou la possibilité de faire le tour du monde.
> Chaîne terminée.
Vous pouvez trouver des preuves de l'existence d'une terre ronde grâce à des preuves empiriques telles que des photos prises dans l'espace, des observations de navires disparaissant à l'horizon, la vision de l'ombre incurvée de la lune, ou la capacité de faire le tour du monde.
Jon se plonge dans le fonctionnement du module Fallacy Chain, qu'il a intégré à LangChain. L'architecture du Fallacy Chain est composée de deux éléments principaux : La chaîne de critique et la chaîne de révision. L'ingénierie rapide est exploitée dans les deux chaînes pour détecter et modifier les faussetés dans la réponse. Voici un bref aperçu de son fonctionnement :
Lorsque nous fournissons l'entrée, le LLM la traite et génère une réponse initiale.
L'étape suivante est la détection des erreurs. La chaîne critique identifie et classifie tout sophisme présent sur la base des modèles identifiés. Jon mentionne l'utilisation de la liste des sophismes qui a été extraite et utilisée à partir du document de recherche mentionné plus haut.
La chaîne de révision est codée à l'aide d'une ingénierie d'incitation afin de générer une réponse révisée en évitant les sophismes détectés. Cela peut impliquer une reformulation, l'ajout d'un contexte ou la modification de la structure de l'argument.
Application de démonstration
Jon a également fait la démonstration d'une application permettant d'extraire les sophismes logiques des articles de presse. Dans cette démonstration, il a montré comment les nouveaux articles provenant de différentes régions pouvaient avoir un biais politique et d'autorité. Il a également fait la démonstration d'une application construite à l'aide d'Open AI pour extraire de nouveaux articles sur un sujet donné et identifier les principaux sophismes qu'ils contiennent. Avec cette application, il a recherché de nouveaux articles liés à la "Chine" en tant que mot-clé, et le résultat est illustré ci-dessous.

Les articles expliquent comment la chaîne des sophismes a identifié et expliqué le problème de l'"appel à l'autorité". Jon explique comment des outils comme ceux-ci peuvent nettoyer nos données de formation des sophismes logiques, ce qui permet au modèle d'apprendre sans faille. FallacyChain peut considérablement améliorer la fiabilité des résultats du LLM et accroître la confiance des utilisateurs. Elle assure également la transparence en expliquant les changements et leurs raisons, aidant ainsi les utilisateurs à comprendre comment la cohérence logique a été obtenue.
Pour plus d'informations sur cette démo, [regardez la rediffusion de l'intervention de Jon lors du meetup] (https://www.youtube.com/watch?v=yqaG2XSv89I&t=75s).
Conclusion
La FallacyChain dans LangChain est une approche puissante pour améliorer l'intégrité logique des textes générés par les LLM. Elle peut accroître la confiance des utilisateurs et faciliter la mise en œuvre des LLM conformément à la conformité. Bien que les avantages soient étonnants, il est nécessaire d'évaluer les coûts de mise en œuvre à grande échelle. C'est un espace passionnant, et de nouvelles expériences sont menées pour l'améliorer en utilisant des méthodes d'apprentissage automatique pour la classification des erreurs, etc.

{kind=link}
{kind=link}
Continuer à lire

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.