




Milvus 2.4 dévoile CAGRA : améliorer la recherche vectorielle grâce à l'indexation GPU de nouvelle génération
Qu'est-ce qu'un index basé sur le GPU ?
La recherche vectorielle est par nature gourmande en calculs. En tant que base de données vectorielles la plus performante, Milvus alloue plus de 80 % de ses ressources informatiques à ses bases de données vectorielles et à son moteur de recherche, [Knowhere] (https://github.com/zilliztech/Knowhere). Compte tenu des exigences de calcul de haute performance, les GPU apparaissent comme un élément central de notre plateforme de base de données vectorielles, en particulier dans le domaine de la recherche vectorielle.
Milvus a créé un précédent en devenant la première base de données vectorielles à exploiter l'accélération GPU avec sa [version 1.1] (https://milvus.io/docs/v1.1.1/release_notes.md) en 2021. Dans la version 2.3, en exploitant la bibliothèque RAFT de NVIDIA pour la recherche vectorielle, Milvus a introduit des index accélérés par le GPU et l'intégration avec le cadre de recommandation NVIDIA Merlin (utilisé pour construire des systèmes de recommandation). L'introduction des index IVFFLAT et IVFPQ dans cette version a montré des améliorations de performances remarquables [https://zilliz.com/blog/milvus-2-3-beta-new-features-and-updates].
Malgré ces avancées, des défis tels que l'optimisation des performances pour les requêtes en petits lots et l'amélioration de la rentabilité des index basés sur le GPU persistent, ce qui incite à rechercher en permanence des solutions innovantes. Le passage de l'industrie aux [algorithmes de recherche vectorielle] basés sur les graphes (https://zilliz.com/learn/popular-machine-learning-algorithms-behind-vector-search), reconnus pour leurs performances supérieures à celles des méthodes basées sur le FVI, représente une évolution cruciale. Cependant, l'adaptation de ces algorithmes aux GPU n'est pas simple en raison de leur exécution séquentielle et de leurs schémas d'accès aléatoire à la mémoire, ce qui rend difficile la mise en œuvre efficace des GPU pour des algorithmes tels que GGNN et SONG.
Pour relever ces défis, la dernière innovation de NVIDIA, l'index graphique basé sur le GPU [CAGRA] (https://arxiv.org/abs/2308.15136), représente une étape importante. Avec l'aide de NVIDIA, Milvus a intégré la prise en charge de CAGRA dans sa version 2.4, marquant ainsi une avancée significative pour surmonter les obstacles d'une mise en œuvre efficace du GPU dans la recherche vectorielle.
Qu'est-ce que CAGRA ?
Construire CAGRA
CAGRA (CUDA Anns GRAph-based) introduit une nouvelle approche de la construction de graphes, s'écartant de la méthode itérative d'insertion et de mise à jour utilisée pour les graphes de petits mondes navigables hiérarchiques (HNSW) sur les CPU. Ce changement répond au défi d'exploiter pleinement les capacités de construction de graphes hautement parallèles des GPU, dont le processus de construction de HNSW basé sur les CPU ne tire pas profit. CAGRA commence par créer un graphe initial en utilisant IVFPQ ou NN-DESCENT, où chaque nœud est connecté à de nombreux voisins. Les étapes suivantes consistent à trier ces connexions par importance, à élaguer les arêtes les moins critiques et à fusionner les graphes dirigés pour finaliser la structure et construire un graphe initial. Dans le graphe initial, chaque nœud a un grand nombre de nœuds voisins. CAGRA trie ensuite toutes les arêtes adjacentes en fonction de leur importance sur la base du graphe initial et élague les arêtes sans importance.
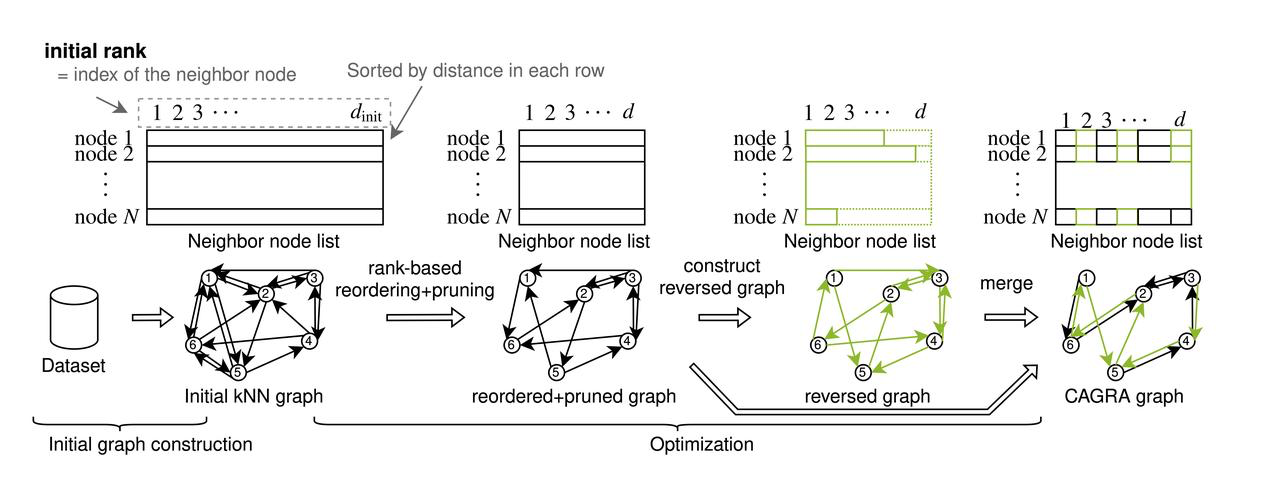 Le processus de construction de CAGRA
Le processus de construction de CAGRA
Construction du graphe initial
IVFPQ
En mode IVFPQ, le CAGRA exploite l'ensemble de données pour construire un index IVFPQ, en utilisant la fonction de quantification de l'index Product Quantization (PQ) pour minimiser l'utilisation de la mémoire vidéo. Après la création de cet index, CAGRA effectue une recherche pour chaque point de l'ensemble de données, en utilisant les plus proches voisins approximatifs identifiés par l'index IVFPQ en tant que recherche des plus proches voisins des points adjacents. Ce processus constitue la base de la construction du graphe initial, garantissant une configuration efficace sans occuper trop de mémoire.
NN-DESCENT
Le CAGRA utilise l'algorithme NN-DESCENT pour une autre approche de la construction du graphe initial, qui implique les étapes détaillées suivantes :
Initialisation: Sélection aléatoire de k points de l'ensemble de données v pour créer la liste d'adjacence initiale B[v].
Inversion et fusion: Prendre l'inverse de B[v] pour générer la liste d'adjacence inversée R[v], puis fusionner B et R pour former H[v].
Expansion des voisins: Pour tout nœud v de l'ensemble de données, identifiez tous les voisins des voisins sur la base de H[v], en sélectionnant les nœudsk supérieurs les plus proches comme nouveaux voisins.
Itération: Répéter le processus d'inversion et de fusion et d'expansion des voisins jusqu'à ce que B se stabilise et ne change plus ou jusqu'à ce qu'un seuil d'itération prédéfini soit atteint.
Comparé à HNSW, NN-Descent offre une parallélisation plus facile et moins d'interaction de données entre les tâches, ce qui augmente considérablement le temps de construction du graphe et l'efficacité du graphe d'adjacence CAGRA sur les GPU. Cependant, il convient de noter que la qualité initiale du graphe dans NN-DESCENT peut être légèrement inférieure à celle obtenue avec le mode IVFPQ.
Optimisation du CAGRA
La stratégie d'optimisation des graphes de CAGRA repose sur deux hypothèses principales :
Tri de l'importance: La préférence est donnée au tri basé sur le chemin plutôt qu'au tri traditionnel basé sur la distance pour déterminer l'importance des arêtes. Cette méthode soutient que la connectivité des graphes ne bénéficie pas nécessairement d'un tri d'importance basé sur la distance.
Fusion de graphes inversés: Le principe selon lequel un nœud jugé important pour l'un peut également trouver l'autre important sous-tend la stratégie de fusion de graphes inversés.
Le processus d'optimisation comprend deux étapes principales :
- L'élagage: Initialement, les arêtes adjacentes de chaque nœud sont affectées de différents poids ('w') en fonction de la distance. Le CAGRA utilise une stratégie d'élagage dans laquelle les arêtes sont coupées si elles connectent des nœuds qui sont les plus "détournables", sur la base de la condition "max(w_{x to z},w_{z to y}) < w_{x to y}". Cette méthode permet d'éliminer les connexions les moins critiques afin de rationaliser le graphe.
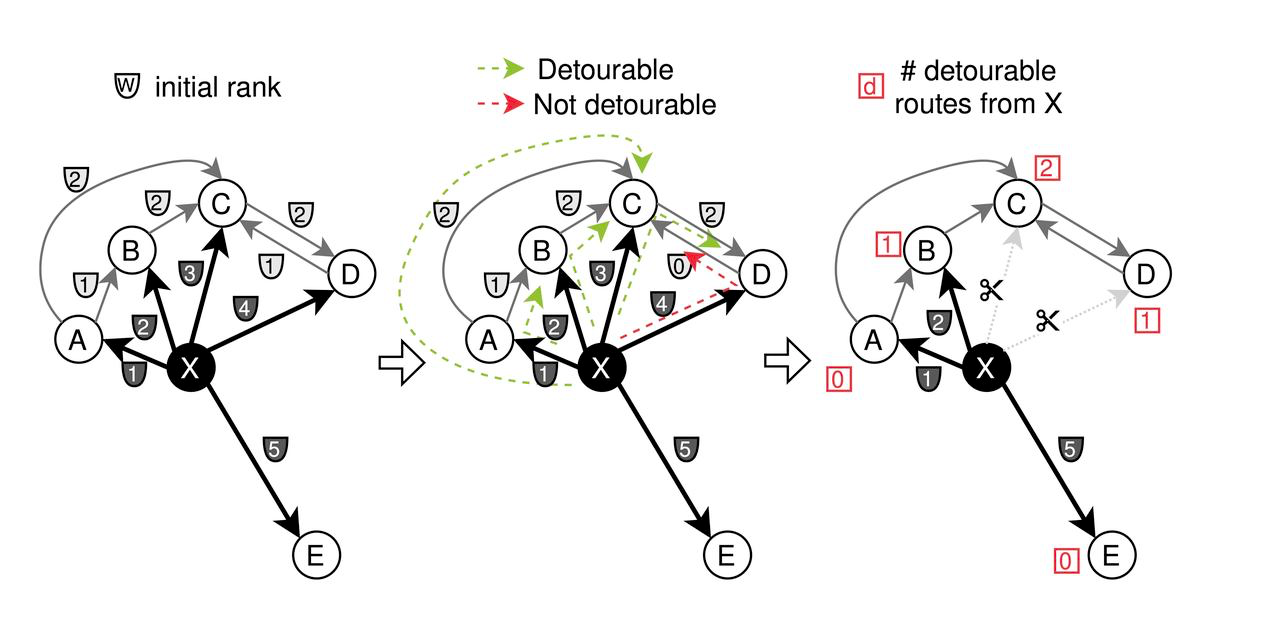 Processus d'élagage pour l'optimisation CAGRA
Processus d'élagage pour l'optimisation CAGRA
- Fusion: Après avoir élagué le graphe avant sur la base de l'importance des chemins, les arêtes sont inversées et fusionnées. Plus précisément, la moitié des arêtes sont sélectionnées à partir des graphes avant et arrière pour créer le graphe CAGRA optimisé final.
Cette approche détaillée de la construction et de l'optimisation du graphe garantit l'efficacité de CAGRA dans les opérations de recherche vectorielle, en tirant parti des capacités uniques des GPU tout en relevant les défis inhérents aux algorithmes de recherche basés sur les graphes.
La recherche avec CAGRA
Le mécanisme de recherche CAGRA emploie une approche méthodique utilisant une file d'attente prioritaire ordonnée de taille fixe pour une navigation efficace dans le graphe. Ce processus détaillé est décrit à travers une série d'étapes dans un cadre structuré :
Cadre de recherche CAGRA
CAGRA fonctionne avec une mémoire tampon séquentielle comprenant une liste top-M interne et une liste de candidats. La liste top-M interne fait office de file d'attente prioritaire, sa longueur étant fixée à M (où M ≥ k), ce qui lui permet de stocker les résultats les plus pertinents jusqu'au nombre souhaité de plus proches voisins, k. La taille de la liste des candidats est déterminée par p × d, p représentant le nombre de nœuds sources explorés à chaque itération et d indiquant le degré du graphe. Chaque élément de ces listes associe un index de nœud à la distance par rapport à la requête, ce qui permet une gestion efficace de la recherche.
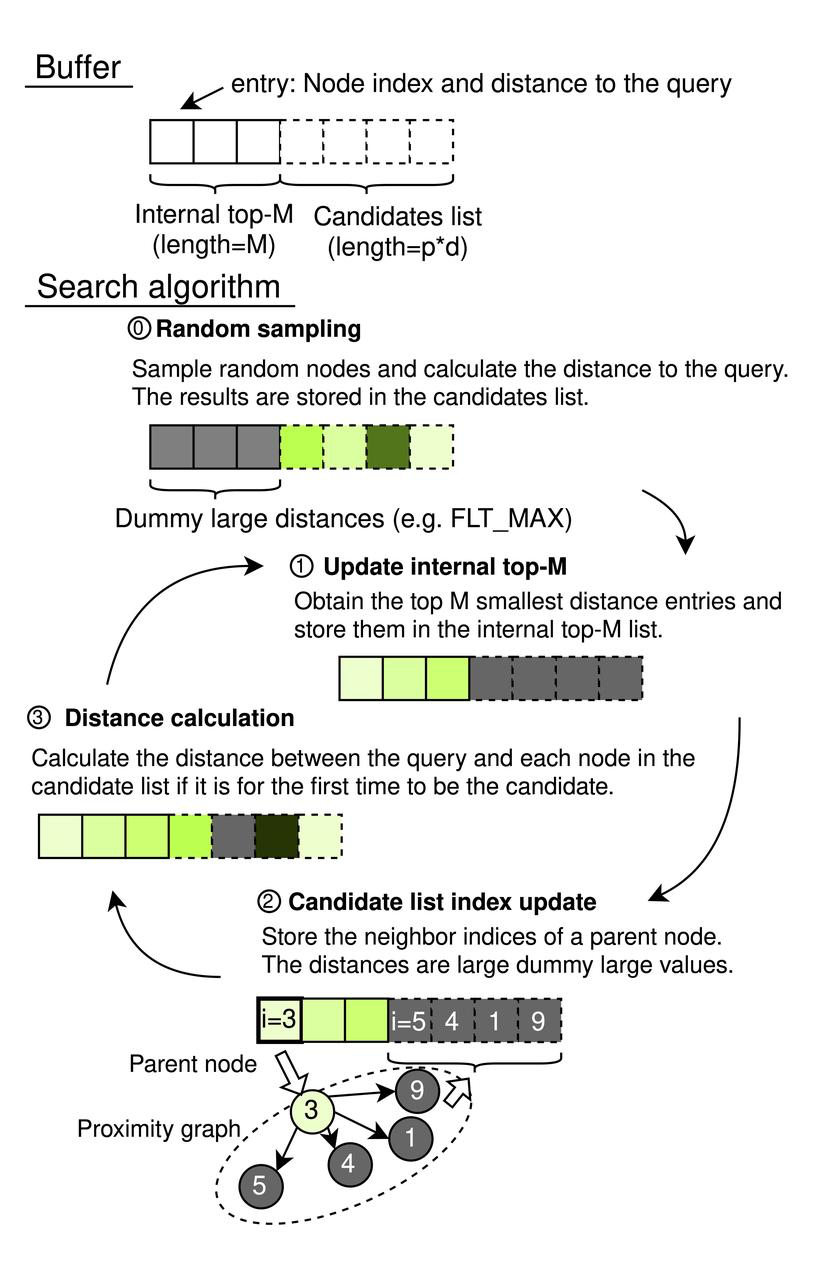 Processus de recherche CAGRA
Processus de recherche CAGRA
Étapes du processus de recherche
- Échantillonnage aléatoire (initialisation)
- Utilise un générateur pseudo-aléatoire pour sélectionner p × d indices de nœuds aléatoires, en calculant la distance entre chaque nœud et la requête.
- Les résultats alimentent la liste des candidats, tandis que la liste interne top-M s'initialise avec des entrées virtuelles (réglées sur FLT_MAX) pour éviter d'influencer les résultats du tri initial.
Mise à jour de la liste Top-M interne: Sélectionner les nœuds Top-M en fonction des distances les plus faibles sur l'ensemble de la mémoire tampon pour les inclure dans la liste Top-M interne.
Mise à jour de l'index de la liste des candidats (parcours du graphe) :
- Identifie tous les nœuds voisins des p premiers nœuds de la liste top-M interne, en excluant les nœuds précédemment utilisés via un filtre de table de hachage.
- Ajoute ces voisins à la liste des candidats sans recalculer les distances à ce stade.
- Calcul de la distance:
- Effectue les calculs de distance pour les nœuds nouvellement apparus dans la liste des candidats, en évitant les calculs redondants pour les nœuds évalués lors des itérations précédentes.
- Veille à ce que les nœuds ne soient ajoutés à la liste top-M que si leur distance justifie leur pertinence, selon qu'ils sont suffisamment petits pour faire partie de la liste ou trop grands pour être pris en compte.
L'algorithme effectue ces étapes de manière itérative, en parcourant tous les nœuds de la liste top-M interne jusqu'à ce qu'ils aient tous servi de points de départ à la recherche. La recherche se termine par l'extraction des k premières entrées de la liste top-M interne, ce qui donne les résultats de la recherche Approximate Nearest Neighbor (ANNS).
Performance
La décision d'exploiter les index GPU a été principalement motivée par des considérations de performance. Nous avons entrepris une évaluation complète des performances de Milvus à l'aide d'un outil de référence [base de données vectorielles à source ouverte] (https://zilliz.com/product/open-source-vector-database), en nous concentrant sur les comparaisons entre les index HNSW, IVFFLAT basé sur le GPU et CAGRA.
Configuration de l'analyse comparative
Pour une évaluation réaliste, nos benchmarks ont été réalisés sur des machines hébergées par AWS et équipées de GPU NVIDIA T4 et A10G, en veillant à ce que les environnements de test reflètent les ressources couramment disponibles. Les machines sélectionnées étaient d'un prix comparable, ce qui a permis d'évaluer les performances sur un pied d'égalité. Tous les tests visaient à atteindre un taux de rappel de 100 %@98 %, en utilisant une instance AWS m6i.4xlarge (16C64G) comme client.
 Informations de base sur la machine sélectionnée
Informations de base sur la machine sélectionnée
Aperçu des performances
Performance des petits lots:
Dans les situations où les lots de recherche sont petits (taille de lot de 1), où les GPU sont généralement sous-utilisés, CAGRA a considérablement surpassé ses homologues. Nos tests ont révélé que CAGRA pouvait fournir près de 10 fois la performance des méthodes traditionnelles dans ces conditions.
Comparaison des performances pour un ensemble de données en petits lots] (https://assets.zilliz.com/Performance_Comparison_for_Small_Batch_Data_Set_b9bcc9f26e.png)
Performance des grands lots:
Lors de l'examen de lots de recherche plus importants (tailles de 10 et 100), l'avantage de CAGRA est devenu encore plus prononcé. Par rapport à HNSW, CAGRA a fait preuve d'une augmentation spectaculaire de la performance, améliorant l'efficacité de la recherche par des dizaines de fois.
Comparaison des performances pour un ensemble de données de grande taille] (https://assets.zilliz.com/Performance_Comparison_for_Large_Batch_Data_Set_ef371476c6.png)
Index Building Efficiency:
Au-delà des capacités de recherche, les compétences de CAGRA s'étendent à la construction d'index. Avec l'accélération GPU, CAGRA a démontré sa capacité à construire des index environ 10 fois plus vite que les méthodes alternatives.
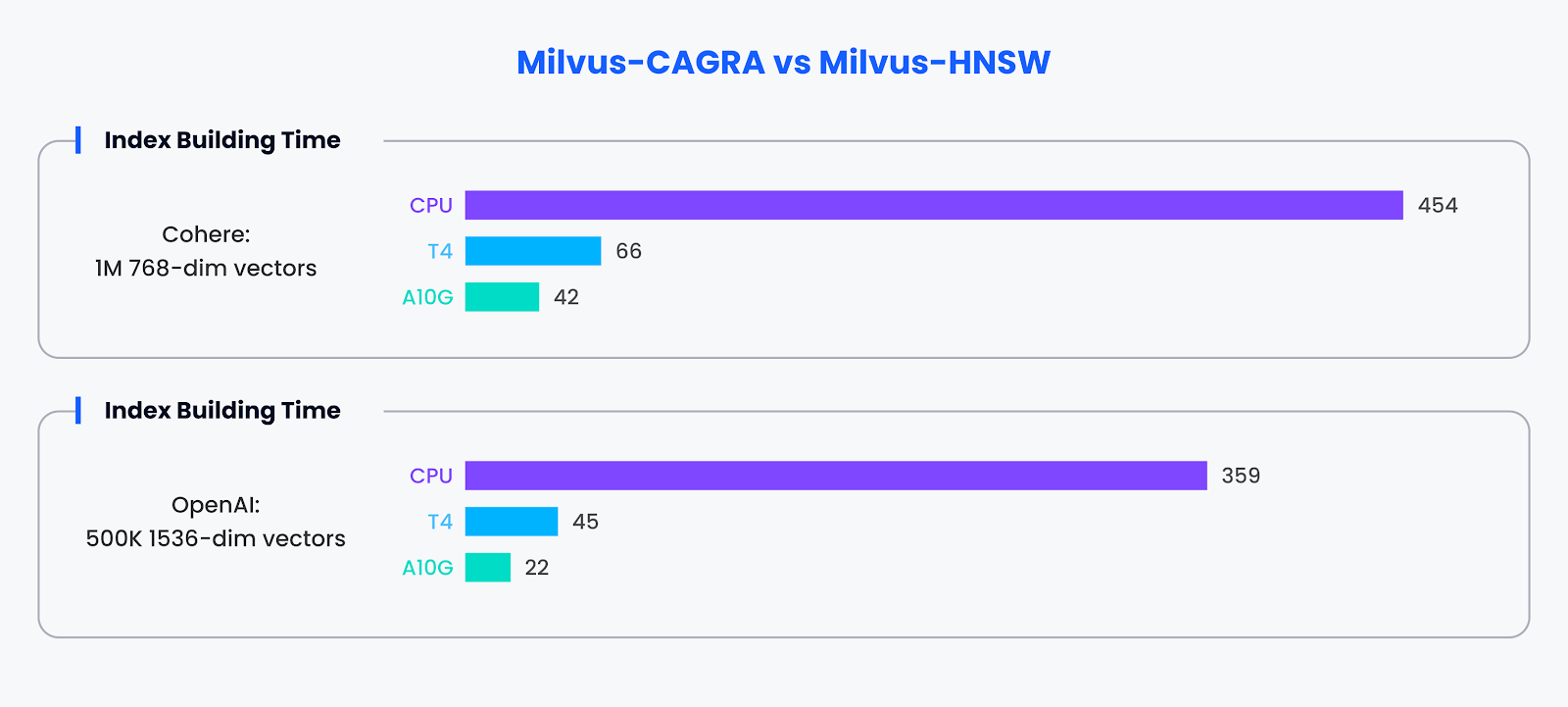 Comparaison des performances pour la construction d'index
Comparaison des performances pour la construction d'index
Les résultats du benchmark soulignent les avantages considérables en termes de performances de l'adoption d'index accélérés par le GPU tels que CAGRA dans Milvus. Non seulement il excelle dans l'accélération des tâches de recherche en fonction de la taille des lots, mais il améliore également de manière significative la vitesse de construction de l'index, affirmant la valeur des GPU dans l'optimisation des performances des bases de données vectorielles.
Quelle est la prochaine étape ?
CAGRA marque une avancée significative dans notre quête pour redéfinir les limites de la recherche vectorielle, en démontrant le potentiel de la recherche basée sur les GPU pour relever les défis de production les plus exigeants. À mesure que nous avançons, Milvus est déterminé à explorer plus en profondeur les aspects de [haut rappel] (https://zilliz.com/blog/diskann-a-disk-based-anns-solution-with-high-recall-and-high-qps-on-billion-scale-dataset), de faible latence, de rentabilité et d'évolutivité dans la recherche vectorielle. Notre engagement va au-delà des réalisations actuelles pour englober une gestion des données plus flexible, des capacités de recherche enrichies et des optimisations de performances révolutionnaires.
Cette vision nous pousse à innover en permanence, en veillant à ce que Milvus soit le leader et le pionnier de l'avenir de la recherche accélérée pour les [données non structurées] (https://zilliz.com/glossary/unstructured-data). En repoussant les limites de ce qui est possible aujourd'hui, nous visons à ouvrir de nouvelles possibilités pour demain, en rendant la recherche vectorielle plus puissante, plus efficace et plus accessible.
 Conseils pratiques et astuces pour les développeurs utilisant des bases de données vectorielles.png
Vous ne savez pas quel index choisir pour votre solution ? Nous avons un blog qui vous aide à faire le bon choix!*
Conseils pratiques et astuces pour les développeurs utilisant des bases de données vectorielles.png
Vous ne savez pas quel index choisir pour votre solution ? Nous avons un blog qui vous aide à faire le bon choix!*

Continuer à lire

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Balancing Precision and Performance: How Zilliz Cloud's New Parameters Help You Optimize Vector Search
Optimize vector search with Zilliz Cloud’s level and recall features to tune accuracy, balance performance, and power AI applications.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.