




Cómo una plataforma líder mundial de GPU e IA utiliza Milvus para escalar la minería de datos multimodal para su sistema de conducción autónoma

-30% de costo
Menor consumo de memoria y almacenamiento mediante claves primarias basadas en disco y un diseño de segmentos optimizado en Milvus 2.5.
Escala 10×
Margen de capacidad comprobado para escalar un orden de magnitud más sin rediseños ni sorpresas de costos.y sin cambios arquitectónicos ni costos inesperados.
Confiabilidad empresarial
Producción continua a una escala masiva sin incidentes importantes.
Búsqueda híbrida
Búsqueda vectorial unificada y filtrado de metadatos para admitir consultas complejas.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
Acerca de la empresa
El cliente es un líder global en computación acelerada e inteligencia artificial, con décadas de experiencia en la creación de GPU y plataformas de software utilizadas en videojuegos, robótica, centros de datos y aplicaciones automotrices. Una de sus iniciativas insignia es una plataforma de extremo a extremo para asistencia avanzada al conductor y conducción autónoma. Esta plataforma admite el ciclo de vida completo del desarrollo de conducción autónoma: desde la recopilación de datos a gran escala y el entrenamiento de modelos de IA hasta la inferencia en el vehículo y la toma de decisiones en tiempo real.
Detrás de esta plataforma se encuentra la organización de Ingeniería de Datos de Vehículos Autónomos (AV) de la empresa, responsable de la infraestructura de datos que impulsa su tecnología de conducción autónoma. Cada hora de conducción en el mundo real produce terabytes de datos de sensores multimodales, incluidos flujos de cámaras sincronizados, nubes de puntos LiDAR, mediciones de radar, datos de localización de alta precisión y metadatos detallados del estado del vehículo. La misión del equipo es hacer que este conjunto de datos masivo y en constante crecimiento sea buscable, descubrible y operativamente utilizable por cientos de ingenieros que deben encontrar escenarios de cola larga, identificar casos límite raros y validar el comportamiento de los modelos en condiciones del mundo real.
Para cumplir con estos requisitos, el equipo creó un sistema de minería de datos multimodal capaz de buscar entre decenas de miles de millones de puntos de datos de sensores indexados recopilados de flotas de prueba. El sistema convierte los datos de sensores sin procesar en incrustaciones vectoriales para que los ingenieros puedan ejecutar consultas profundas y conscientes del contexto, por ejemplo: “vehículos incorporándose desde la derecha bajo lluvia intensa”, “peatones cruzando al anochecer en intersecciones no señalizadas” o “rotondas de dos carriles con visibilidad obstruida”.
El sistema inicialmente se ejecutaba en FAISS, pero a medida que crecieron el volumen de datos y las demandas operativas, el equipo migró a Milvus para lograr una mayor escalabilidad, un menor esfuerzo de mantenimiento y una fiabilidad de producción más sólida. Milvus proporcionó una vía clara para admitir un orden de magnitud más de datos, reducir la sobrecarga operativa y mejorar la eficiencia de agrupamiento, indexación y almacenamiento a medida que la flota de conducción autónoma continuaba expandiéndose.
El desafío: FAISS no podía escalar
El cuello de botella de la gestión de datos
El diseño inicial de este sistema de minería de datos fue intencionalmente simple. Cada sesión de conducción autónoma —por lo general, un viaje de una hora— se procesaba en fotogramas, se transformaba en incrustaciones vectoriales mediante los modelos propietarios de la empresa y se agrupaba en archivos de índice FAISS, normalmente uno por día.
Aunque esa estructura funcionó bien al principio, no escalaba. A medida que el conjunto de datos aumentó de forma explosiva, también lo hizo el número de archivos de índice, hasta llegar finalmente a cientos de miles. Cada uno representaba un pequeño bolsillo aislado de información. Buscar en todos ellos introducía una complejidad significativa: los índices diarios a menudo contenían datos superpuestos, lo que requería una lógica intrincada para filtrar y fusionar metadatos. En la práctica, esto significaba que, aunque buscar dentro de un solo día funcionaba bien, la mayoría de los usuarios quería consultar condiciones más amplias, como escenarios de conducción específicos que abarcaran varios días o regiones. Esas búsquedas tenían que acceder a muchos archivos de índice separados a la vez, lo que resultaba computacionalmente costoso. Los ingenieros a menudo tenían que reducir manualmente su alcance, adivinando qué archivos podrían contener los datos relevantes antes de ejecutar una consulta. Estas conjeturas hacían que el proceso de búsqueda fuera lento y poco fiable.
La brecha de flexibilidad
FAISS no es una base de datos: es una biblioteca. Está bien para encontrar los vecinos más cercanos de un vector determinado, pero los sistemas de búsqueda de nivel de producción requieren mucho más que solo una coincidencia rápida por similitud.
En la práctica, los ingenieros no querían buscar en todo el corpus de una sola vez. Necesitaban filtrado contextual: encontrar, por ejemplo, “fotogramas de cámara frontal capturados con lluvia ligera en carreteras urbanas” o “conducciones nocturnas en autopistas de California”. Lograr ese nivel de precisión requería combinar la búsqueda vectorial con filtros de metadatos como tipo de cámara, hora, ubicación, clima y versión del modelo. Pero FAISS no proporcionaba estas capacidades de forma nativa. Para cerrar esa brecha, el equipo tuvo que crear una pila compleja de lógica personalizada: bases de datos de metadatos independientes, planificadores de consultas a medida para decidir qué índices de FAISS escanear, y posfiltrado manual de los resultados después de la recuperación.
Con el tiempo, estas personalizaciones crearon un importante problema de escalabilidad. Los distintos ángulos de cámara, los múltiples modelos de embeddings y los pipelines de preprocesamiento versionados exigían estrategias de gestión diferenciadas. No existía un concepto integrado de colecciones, particiones o agrupación lógica de datos: solo archivos de índices. Cada capa de organización, desde el versionado de datos hasta el filtrado de consultas, tenía que escribirse y mantenerse en código personalizado. El sistema funcionaba, pero a costa de la flexibilidad, la mantenibilidad y la escalabilidad a largo plazo.
El problema de escalabilidad
El sistema ya estaba bajo presión con miles de millones de vectores, y los vehículos de prueba de la empresa generaban nuevos datos todos los días. Mientras tanto, los equipos de investigación introducían nuevos modelos de embeddings, cada uno de los cuales requería reindexar datos históricos a gran escala. Era solo cuestión de tiempo antes de que las cargas de trabajo crecieran diez veces, pero la configuración de FAISS basada en archivos no tenía una forma práctica de escalar a ese nivel.
Peor aún, cada nuevo conjunto de datos implicaba más archivos de índices y más actualizaciones manuales del almacenamiento de metadatos. No había sharding automático, ni balanceo de carga integrado, ni forma de añadir capacidad bajo demanda. La arquitectura se había vuelto anticuada: estática, intensiva en mano de obra y resistente al crecimiento.
Los costes de ingeniería ocultos
Más allá de los costes de la nube, el mayor desafío era la sobrecarga de ingeniería oculta de mantener FAISS. Los ingenieros tenían que gestionar sistemas complejos de metadatos, diseñar lógica personalizada para distribuir datos y actualizar manualmente millones de archivos de índices. Con el tiempo, esta sobrecarga ralentizó la innovación: el rendimiento de búsqueda se degradó, los ciclos de desarrollo se alargaron y las nuevas ideas nunca pasaron de la pizarra. A medida que los volúmenes de datos siguieron creciendo, el sistema se volvió cada vez más rígido y frágil. Estaba claro que intentar actualizar la configuración heredada ya no era sostenible.
La solución: rediseñar la arquitectura para escalar con Milvus
Para superar estos desafíos, el equipo de AV Data necesitaba un sistema capaz de manejar decenas de miles de millones de vectores hoy, con un camino claro hacia un crecimiento de 10× y más. Tenía que proporcionar un filtrado sólido, simplicidad operativa y, por encima de todo, fiabilidad en producción con un mantenimiento mínimo.
El proceso de evaluación
En lugar de ejecutar una comparación amplia entre todas las bases de datos vectoriales emergentes, el equipo se centró en la popular Milvus Vector Database, realizando una prueba de concepto con 400–500 millones de vectores, lo suficientemente grande como para exponer cuellos de botella reales. Durante las pruebas, los ingenieros replicaron todo su flujo de trabajo de datos: indexaron conjuntos de datos con distintos tipos de índices para comparar las compensaciones, midieron el tiempo de indexación para estimar las actualizaciones diarias por lotes y evaluaron la latencia con combinaciones de filtros y patrones de consulta realistas. Llevaron deliberadamente Milvus al límite, ejecutando búsquedas complejas con múltiples condiciones y escalando los volúmenes de datos para probar la estabilidad.
¿Por qué Milvus?
Los resultados de la prueba de concepto hicieron de Milvus la opción clara para el equipo de AV Data.
Rendimiento de consulta aceptable: Milvus entregó de forma constante latencias de consulta del orden de segundos incluso para las búsquedas más complejas y con muchos filtros, muy dentro de los requisitos para las cargas de trabajo internas de minería de datos.
Filtrado nativo y flexibilidad de consulta: Los ingenieros ahora podían combinar la búsqueda por similitud vectorial con filtros de metadatos en una sola consulta, capacidades que antes requerían una gran cantidad de código personalizado en FAISS.
Estructura de datos organizada: Los embeddings vectoriales de diferentes modelos se almacenaban en colecciones separadas, cada una particionada por atributos como la fecha de captura o la región. Milvus gestionaba automáticamente la distribución de datos entre segmentos, eliminando la carga de la gestión manual de archivos.
Escalabilidad fluida: A medida que los datos crecían, el equipo añadía más nodos para ampliar la capacidad. La arquitectura distribuida de Milvus escalaba linealmente sin requerir rediseños del sistema.
Comunidad open-source activa: Durante las pruebas, los ingenieros de AV Data recibieron soporte rápido y práctico del equipo de Milvus y de colaboradores de la comunidad, lo que generó una gran confianza en Milvus como un ecosistema fiable y listo para producción.
Implementación de la nueva arquitectura con Milvus
En esencia, la arquitectura de este sistema de minería de datos multimodal es sencilla, pero ejecutarla a escala masiva requiere ingeniería cuidadosa y precisión. Los datos de video sin procesar de recorridos de vehículos autónomos —horas de metraje continuo de múltiples cámaras— fluyen hacia un pipeline de procesamiento que extrae fotogramas individuales o clips cortos, normalmente de unos pocos segundos de duración.
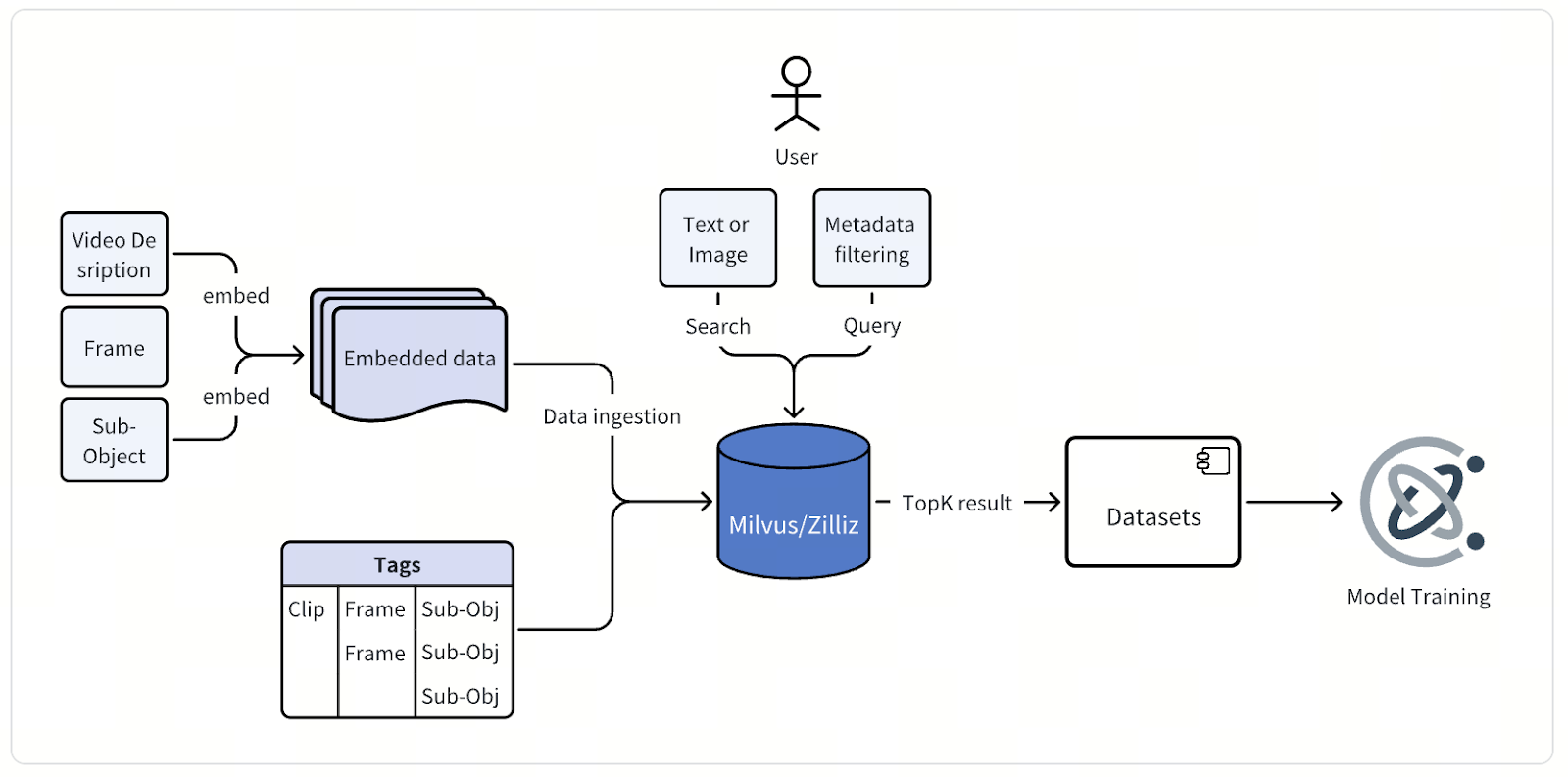
Luego, cada fotograma o clip pasa por los modelos de embedding propietarios de la empresa, diseñados específicamente para la conducción autónoma. Para los datos de imagen, el equipo utiliza modelos derivados de la arquitectura CLIP, personalizados y ajustados para capturar semántica específica de la carretera. Para los datos de video, se apoyan en sus propios modelos desarrollados internamente, una familia de modelos fundacionales para aplicaciones de IA física. En conjunto, estos modelos convierten los datos visuales en embeddings vectoriales de alta dimensionalidad que codifican un rico significado contextual.
Una vez generados, estos embeddings vectoriales, junto con metadatos detallados, se almacenan e indexan en la base de datos vectorial Milvus. Cada punto de datos incluye atributos que describen la sesión de conducción, la posición de la cámara, la marca de tiempo, el estado del vehículo, la ubicación y las condiciones meteorológicas, entre otros. Estos metadatos también se indexan para permitir búsquedas filtradas rápidas y precisas en conjuntos de datos masivos.
A través de una interfaz de consulta unificada, los ingenieros pueden buscar en los datos de múltiples maneras. Pueden escribir una descripción de texto, subir una imagen o video de referencia, o combinar la búsqueda vectorial con filtros de metadatos para localizar exactamente lo que necesitan. Una sola consulta podría pedir, por ejemplo, “intersecciones urbanas de noche con peatones cruzando”, y Milvus devuelve los fotogramas o clips más relevantes para revisión, análisis y mejora del modelo.
Los beneficios: eficiencia de costos, estabilidad y escala
Después de más de un año en funcionamiento continuo, Milvus ha demostrado ser no solo técnicamente sólido, sino también transformador a nivel operativo. Los siguientes resultados muestran cómo su arquitectura y ecosistema se tradujeron en eficiencia real a escala.
Operaciones más simples, menos dolores de cabeza y desarrollo más rápido
Migrar de cientos de miles de archivos FAISS a Milvus eliminó toda una capa de sobrecarga operativa. Ya no hay gestión manual de archivos de índice, ni scripts ad hoc, ni lógica de consulta personalizada. La distribución de datos, la gestión de segmentos y el enrutamiento de consultas ahora ocurren automáticamente. Las actualizaciones son sencillas, el monitoreo está unificado y las métricas cuentan una historia clara. El resultado es menos tiempo dedicado al mantenimiento de sistemas y más tiempo a la minería de datos para obtener información valiosa.
Menor sobrecarga de ingeniería más una reducción adicional de costos del 30% después de actualizar a Milvus 2.5
Implementar Milvus redujo de inmediato tanto los costos de infraestructura como los de ingeniería. El alejamiento del sistema basado en archivos de FAISS eliminó la gestión manual de archivos y el seguimiento complejo de metadatos, ahorrando una cantidad significativa de tiempo de desarrollo y esfuerzo operativo. Luego, la actualización de Milvus 2.4 a Milvus 2.5 ofreció una reducción adicional del 30% en los costos de infraestructura, gracias a un mapeo de memoria más inteligente, almacenamiento de claves primarias basado en disco y una gestión de segmentos más eficiente.
En conjunto, estas mejoras permiten al equipo de AV Data ejecutar las mismas cargas de trabajo en instancias de AWS más pequeñas —o indexar muchos más datos— sin aumentar el gasto ni la sobrecarga de mantenimiento. Animado por estos resultados, el equipo planea probar Milvus 2.6, que introduce nuevos tipos de índices como RaBitQ y más optimizaciones que se espera que impulsen aún más tanto el rendimiento como la eficiencia de costos. Para grandes cargas de trabajo por lotes sin conexión, la velocidad de creación de índices sigue siendo un desafío central. Gracias a las contribuciones del equipo NVIDIA cuVS, Milvus ahora admite creación de índices acelerada por GPU con servicio basado en CPU (GPU-build, CPU-serve). Este enfoque acelera significativamente la construcción de índices al tiempo que mantiene la eficiencia de costos, y se espera que mejore aún más la ventaja de precio-rendimiento de Milvus en cargas de trabajo de conducción autónoma.
Escalabilidad integrada, demostrada en la práctica
La plataforma ahora indexa decenas de miles de millones de vectores e ingiere nuevos datos a diario sin fricción. El modelado interno confirma que puede escalar 10× más sin rediseños ni sorpresas de costos, convirtiendo lo que antes era una restricción de capacidad en una ventaja estratégica a largo plazo. Con este margen, el equipo puede pasar de indexar dos años de datos de conducción recientes a cubrir todo el archivo histórico, permitiendo la búsqueda en cada sesión de conducción registrada. También pueden ejecutar múltiples modelos de embeddings en paralelo para optimizar la recuperación para diferentes tipos de consultas e incluso conservar los datos indefinidamente en lugar de retirarlos por antigüedad. La escalabilidad aquí significa no solo manejar más datos, sino habilitar el aprendizaje continuo y un progreso más rápido hacia una conducción autónoma más segura.
Fiabilidad empresarial a escala masiva
En más de un año de producción ininterrumpida, Milvus ha gestionado discretamente decenas de miles de millones de vectores con ingesta y consultas diarias, sin un solo incidente importante. El sistema funciona de forma estable en segundo plano, requiriendo una supervisión mínima. Sin caídas de fin de semana, sin parches de emergencia: solo rendimiento constante y predecible. Ese tipo de fiabilidad a esta escala se traduce en menos riesgos operativos, menos apagafuegos y más enfoque en crear valor en lugar de gestionar infraestructura.
Búsqueda más rica, flujos de trabajo más inteligentes
Milvus combina la búsqueda vectorial con el filtrado de metadatos, ofreciendo a los ingenieros de la empresa nuevas formas de analizar datos complejos de conducción. Pueden, por ejemplo, encontrar todas las imágenes de zonas de construcción capturadas desde cámaras frontales a la luz del día o filtrar por tiempo y ubicación para comparar el comportamiento del modelo entre actualizaciones y regiones. Diferentes colecciones contienen embeddings de distintos modelos, lo que permite a los equipos probar nuevas arquitecturas sin afectar la producción. Estas capacidades aceleran la experimentación y descubren conocimientos que antes requerían una amplia ingeniería personalizada.
Una comunidad sólida que multiplica el impacto
Más allá de la tecnología, la comunidad de código abierto de Milvus ha sido una parte fundamental del éxito de la empresa. Durante las pruebas y la implementación, los ingenieros recibieron soporte rápido directamente de los colaboradores y mantenedores de Milvus. Esta capacidad de respuesta redujo el tiempo de inactividad, aceleró la depuración y mantuvo el progreso según lo previsto. Con el tiempo, la comunidad activa ha seguido aportando valor al ayudar a validar nuevas ideas, facilitar las actualizaciones y compartir mejores prácticas. Para este cliente, Milvus no es solo software fiable: es un ecosistema colaborativo que fortalece la plataforma y ofrece eficiencia a largo plazo.
Lecciones de producción
Elegir el índice adecuado: equilibrar escala, coste y precisión
Elegir un índice es una de las decisiones prácticas más importantes al crear un sistema de búsqueda vectorial. Milvus admite muchos tipos de índices, cada uno con sus propias ventajas y desventajas en velocidad, uso de memoria y precisión. Para el equipo de AV Data, el objetivo era encontrar un equilibrio entre la escala de los datos, el coste de infraestructura y la precisión de búsqueda, no solo elegir la opción más rápida.
Después de probar varias configuraciones, seleccionaron IVF_FLAT, que agrupa vectores en clústeres y realiza una búsqueda exacta dentro de los relevantes. No es la opción más rápida ni la más compacta, pero para decenas de miles de millones de vectores y necesidades de latencia moderadas, ofreció la combinación adecuada de rendimiento y precisión, sin dejar de ser eficiente.
El equipo descubrió que, una vez que un índice se ajusta bien a la carga de trabajo, rara vez es necesario cambiar a algo más nuevo. En la práctica, un índice bien adaptado ahorra más tiempo y recursos que perseguir pequeñas mejoras de rendimiento. Para los sistemas a gran escala, el rendimiento estable y predecible es lo que mantiene las operaciones fluidas.
Mapeo de memoria: intercambiar latencia por coste a escala
Una de las decisiones técnicas más eficaces del equipo fue usar mapeo de memoria (Mmap) para controlar los costes de infraestructura. En configuraciones tradicionales, mantener todos los datos vectoriales en RAM requeriría instancias enormes y de alto coste. Con el mapeo de memoria en Milvus, la mayoría de los datos permanece en disco mientras el sistema operativo mantiene automáticamente en memoria las partes a las que se accede con frecuencia. Este diseño introduce cierta latencia —las lecturas de disco son más lentas que la RAM—, pero mantiene un rendimiento predecible y un uso eficiente de los recursos. Para la carga de trabajo de la empresa, esa compensación tenía todo el sentido. Sus usuarios son ingenieros que ejecutan consultas analíticas, no usuarios finales que esperan respuestas instantáneas, y la concurrencia se mantiene baja.
Operaciones de eliminación: cuando pequeñas suposiciones fallan a escala
Una de las mayores lecciones del equipo provino de algo que parecía simple: eliminar datos. En la arquitectura de solo anexado de Milvus, los vectores eliminados no se eliminan de inmediato: se marcan para eliminación y se limpian más tarde mediante compactación en segundo plano. Durante las pruebas, eliminar millones de vectores desencadenó inesperadamente la reindexación de miles de millones, ya que los filtros de Bloom produjeron falsos positivos en miles de segmentos. Lo que parecía una limpieza rutinaria acabó sobrecargando los nodos de datos y deteniendo trabajos.
La solución llegó al comprender cómo Milvus gestiona los datos y ajustar su flujo de trabajo: ajustar los filtros de Bloom, usar claves de partición para dirigir las eliminaciones con precisión y cambiar a cargas masivas de solo inserción. La conclusión: a escala, incluso las operaciones simples pueden comportarse de forma diferente, y comprender los componentes internos del sistema es clave para mantener un rendimiento predecible.
Mirando hacia el futuro
El equipo se está preparando para adoptar Milvus 2.6 poco después de su lanzamiento, con la confianza de que los nuevos tipos de índices y las optimizaciones arquitectónicas ofrecerán otro salto en eficiencia. Las primeras conversaciones con el equipo de ingeniería de Milvus apuntan a reducciones continuas de costes y a una mejor utilización de los recursos, que la empresa planea validar mediante benchmarks a escala completa.
De cara al futuro, el equipo ve oportunidades emocionantes para ampliar la funcionalidad y escalar. Funciones como la búsqueda híbrida, que combina consultas de texto y vectoriales, podrían abrir nuevas formas de explorar datos multimodales, mientras que los filtros mejorados de estilo base de datos simplificarán flujos de trabajo complejos. La próxima versión Milvus 3.0 también promete arquitecturas por niveles, lo que permitirá a la empresa mantener un acceso rápido a los datos recientes mientras almacena de manera eficiente todo su archivo histórico. En conjunto, estos avances darán a la empresa una plataforma de datos que escala sin esfuerzo, admite capacidades de búsqueda más profundas y crece de forma más eficiente.
Además, se espera que la introducción y maduración de compilaciones de índices aceleradas por GPU con servicio basado en CPU impulsadas por NVIDIA cuVS (GPU-build, CPU-serve) en Milvus ofrezcan una mejora radical en el rendimiento de la indexación offline. Al aprovechar las GPU de NVIDIA y las bibliotecas cuVS altamente optimizadas, Milvus puede crear índices vectoriales a gran escala drásticamente más rápido que los pipelines basados solo en CPU, mientras continúa sirviendo consultas de manera rentable en CPU. Esto acorta significativamente el tiempo de los datos a la consulta, permite ciclos de actualización de índices más frecuentes y amplifica aún más la ventaja de precio-rendimiento de Milvus para la conducción autónoma y otras cargas de trabajo multimodales a gran escala donde la iteración rápida y los datos frescos son críticos.
Conclusión
El equipo de Datos AV del cliente ha construido una potente plataforma de minería de datos que acelera el desarrollo de la conducción autónoma al hacer que enormes volúmenes de datos multimodales sean buscables y accionables. La migración de FAISS a Milvus resolvió desafíos críticos de escalabilidad, flexibilidad y complejidad operativa, al tiempo que generó ahorros de costos medibles y una notable estabilidad en producción.
Después de más de un año de operación continua y decenas de miles de millones de vectores indexados, la plataforma ha demostrado que Milvus puede servir como una base de nivel de producción para la búsqueda vectorial a gran escala y específica de dominio. El sistema ingiere nuevos datos a diario, apoya a ingenieros en todos los programas de conducción autónoma de la empresa y ofrece una ruta clara para escalar 10× más sin rearquitectura.
Para las organizaciones que construyen sistemas de búsqueda vectorial con una escala masiva de datos, la eficiencia de costos importa, y la estabilidad pesa más que la latencia inferior al milisegundo. La experiencia de la empresa es instructiva. Milvus demuestra que una base de datos vectorial de código abierto no solo puede satisfacer las demandas de producción, sino seguir mejorando con el tiempo, ofreciendo una columna vertebral confiable, escalable y preparada para el futuro para la infraestructura de IA del mundo real.