




Cómo DiDi Food transformó la búsqueda de comestibles en toda América Latina con Milvus

Reducción del 19%
en consultas sin resultados logradas mediante la búsqueda vectorial semántica de Milvus
Aumento del 4%
en conversiones de carrito a partir de la coincidencia semántica de productos impulsada por Milvus
15% de las consultas
ahora se benefician de la búsqueda vectorial, que complementa la búsqueda de texto tradicional
Recuperación vectorial en menos de un segundo
con indexación IVF_FLAT de Milvus y similitud de producto interno
Acerca de DiDi Food
DiDi, líder global en servicios de transporte con más de 800 millones de usuarios en todo el mundo, lanzó DiDi Food—su servicio de entrega de comestibles—en 12 grandes ciudades de América Latina, incluidas México, Colombia y Costa Rica. Aprovechando su red logística existente y sus capacidades de optimización en tiempo real, lograron un crecimiento notable: 2 millones de usuarios activos mensuales, 500.000 pedidos diarios y más de 120 millones de dólares en GMV en el primer trimestre de 2025, todo en apenas seis meses.
La plataforma entrega productos frescos y artículos esenciales para el hogar en 30-45 minutos, con tiendas asociadas que ofrecen hasta 30 millones de SKU cada una. Operando en mercados diversos con interacciones multilingües, precios dinámicos y gestión de inventario en tiempo real, DiDi Food construyó una impresionante base de negocio. Pero a medida que su escala crecía, también lo hacía la complejidad de ayudar a millones de clientes a encontrar exactamente lo que necesitaban en catálogos de productos masivos. Ahí es donde la base de datos vectorial Milvus transformó sus capacidades de búsqueda, permitiendo una comprensión semántica que funciona entre idiomas y maneja el desorden real de cómo las personas buscan en la práctica.
El desafío de búsqueda: cuando Elasticsearch basado en palabras clave falla
El equipo de ingeniería de DiDi se enfrentó a las limitaciones que afectan a su base de datos Elasticsearch basada en palabras clave. Errores ortográficos simples, alternancia de códigos o descripciones poco convencionales a menudo conducían a páginas sin resultados, creando fricción en la experiencia de compra.
Altas tasas de "sin resultados": la pérdida de ingresos oculta
DiDi Food enfrentó un problema crítico: demasiadas búsquedas de clientes devolvían cero resultados, lo que llevaba a sesiones de compra abandonadas y pérdida de ingresos. Ejemplos reales de los datos de búsqueda de DiDi revelaron tres causas principales que impulsaban estos fallos.
Los errores tipográficos y ortográficos eran los culpables más comunes. Los usuarios escribían "Genjibr" al buscar "Jengibre", "hedaho" en lugar de "HELADO", o "Kellongs" por "Kelloggs". Sus sistemas de búsqueda por palabras clave existentes, impulsados por Elasticsearch, no podían salvar estas pequeñas pero críticas brechas ortográficas.
Los artefactos de métodos de entrada creaban otra barrera. Los teclados móviles y diferentes sistemas de entrada generaban variaciones Unicode inusuales como "𝑤𝑖𝑛𝑒" en lugar de "wine", "𝑏𝑎𝑛𝑎𝑛𝑎" por "banana", o "𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠" por "chocolates". Estos problemas técnicos de codificación dejaban a los clientes sin poder encontrar productos que claramente estaban en stock.
Las consultas en idiomas mixtos planteaban el mayor desafío en los mercados latinoamericanos. Los clientes buscaban naturalmente "apple juice orgánico" o "leche sin lactosa", combinando términos en inglés y español. Las variaciones regionales empeoraban esto: el mismo producto podía llamarse de diferentes formas en México, Colombia y Costa Rica.
Cada búsqueda fallida representaba un cliente frustrado y una pérdida directa de ingresos. Para una plataforma que procesa 500.000 pedidos diarios, incluso un pequeño porcentaje de consultas sin resultados puede traducirse en un impacto empresarial significativo.
Escalabilidad y complejidad multilingüe
Más allá de los fallos de búsqueda individuales, DiDi enfrentaba desafíos sistémicos que amenazaban su capacidad de escalar. Indexar textualmente decenas de millones de nombres de SKU distintos inflaba los costos de almacenamiento y degradaba el rendimiento de las consultas a medida que su catálogo de productos se expandía por varios países.
La complejidad multilingüe iba más allá de las consultas en idiomas mixtos. Operar en México, Colombia, Costa Rica y otros mercados latinoamericanos significaba que el mismo producto podía tener nombres completamente diferentes en cada región. "Palta" en algunos países, "aguacate" en otros: ambos se refieren al aguacate. Los sistemas tradicionales de palabras clave impulsados por Elasticsearch requerían mantener índices separados para cada variación regional, lo que multiplicaba los requisitos de almacenamiento y complicaba el mantenimiento.
Los matices culturales y lingüísticos crearon barreras adicionales. La jerga local, las variaciones en los nombres de marca e incluso los distintos sistemas de medición (métrico vs. imperial) contribuyeron a fallos en las búsquedas. Un enfoque basado en palabras clave requeriría mapear manualmente miles de variaciones regionales, una tarea imposible a la escala de DiDi.
El equipo de ingeniería de DiDi necesitaba urgentemente una solución que pudiera superar estos desafíos y comprender la intención detrás de las consultas de los usuarios, independientemente del idioma, la región o la forma en que los clientes eligieran expresar sus necesidades.
La solución: crear un motor de búsqueda semántica con Milvus
El sistema impulsado por Elasticsearch tiene dificultades con la diversidad lingüística y la variabilidad de las entradas de los usuarios porque trata las palabras como tokens discretos en lugar de conceptos significativos. Sin embargo, las bases de datos vectoriales pueden comprender el significado semántico y la intención de las consultas de los usuarios mediante embeddings vectoriales y devolver resultados más precisos y relevantes, independientemente del idioma o de los errores ortográficos.
El equipo de ingeniería de DiDi decidió crear un motor de búsqueda semántica aprovechando modelos de embedding multilingües y una base de datos vectorial. El modelo de embedding convierte tanto los nombres y descripciones de productos como las consultas de los usuarios en embeddings vectoriales que representan su significado semántico en un espacio de alta dimensionalidad, mientras que la base de datos vectorial almacena estos embeddings y realiza búsquedas semánticas calculando las distancias entre los vectores de consulta y los vectores de producto.
Tras una evaluación cuidadosa, eligieron jina-embeddings-v3 como su modelo de embedding principal porque mapea texto de distintos idiomas en el mismo espacio matemático de alta dimensionalidad. Esto significa que las consultas para "苹果" (chino), "apple" (inglés) o "manzana" (español) producen vectores casi idénticos, lo que permite una correspondencia multilingüe precisa sin necesidad de sistemas de traducción complejos. Incluso las entradas con errores ortográficos o fonéticamente similares producen vectores cercanos a los términos correctos.
DiDi seleccionó Milvus como su base de datos vectorial debido a su madurez de código abierto, capacidad para escalar horizontalmente a miles de millones de vectores, latencia de milisegundos, arquitectura probada de alto rendimiento y amplio conjunto de funciones.
Arquitectura de datos y estrategia de optimización
Para admitir la recuperación vectorial de baja latencia sobre 30 millones de SKU y, al mismo tiempo, preservar las asociaciones a nivel de tienda, los ingenieros de DiDi implementaron varias optimizaciones clave.
En lugar de almacenar vectores individuales para cada combinación SKU-tienda, fusionaron nombres de artículos idénticos en entradas vectoriales únicas con los ID de tienda correspondientes almacenados en arrays. Este enfoque redujo su biblioteca vectorial de 30 millones de entradas a 200.000 vectores únicos, disminuyendo drásticamente el uso de memoria y manteniendo al mismo tiempo una cobertura completa de productos.
El equipo eligió una configuración de índice
IVF_FLATen Milvus, priorizando la precisión de búsqueda sobre la complejidad de compresión. Cuando los usuarios consultan el sistema, Milvus devuelve los top-k vectores más similares del índice agregado, seguido de un filtro rápido por ID de tienda para aislar los artículos disponibles en la ubicación actual del comprador.Para la frescura de los datos, DiDi adoptó un ciclo de actualización nocturno T+1. Los SKU nuevos y actualizados se agrupan diariamente, se vuelven a integrar mediante clusters de GPU y se envían para actualizar la colección de Milvus. Esta estrategia equilibra la actualidad de los datos con la eficiencia computacional en todo su enorme catálogo de productos.
Diseño del esquema de Milvus
El esquema de la colección refleja los requisitos específicos de DiDi para la búsqueda de comestibles, equilibrando flexibilidad y rendimiento:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding using jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
Generación de embeddings acelerada por GPU
La generación inicial de embeddings basada en CPU con el modelo jina-embeddings-v3 resultó en una latencia inaceptable de 5 segundos por registro. Para lograr un rendimiento en tiempo real, DiDi desplegó instancias de GPU en su plataforma Luban, reduciendo el tiempo de embedding a aproximadamente 50 milisegundos por consulta:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Arquitectura de pipeline de búsqueda híbrida
En lugar de reemplazar por completo su infraestructura existente, DiDi implementó Milvus como un complemento inteligente para su sistema Elasticsearch establecido. El diseño de doble pipeline permite que Elasticsearch gestione consultas estándar de palabras clave, mientras que Milvus proporciona comprensión semántica para casos complejos.
El flujo de búsqueda opera en los siguientes pasos:
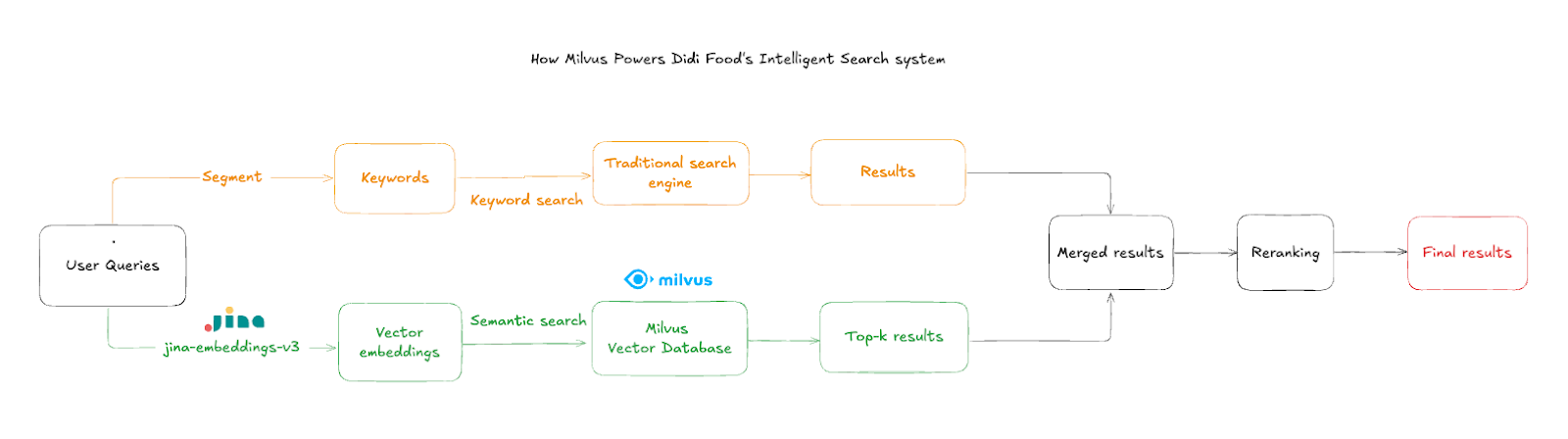
Entrada de consulta del usuario: Los clientes escriben nombres o descripciones de productos, a menudo con errores tipográficos o idiomas mezclados
Embedding de texto: El sistema utiliza
jina-embeddings-v3para convertir la entrada en vectores semánticos de alta dimensión en ~50 msBúsqueda por similitud: Milvus consulta los vectores de productos agregados para encontrar las coincidencias semánticas más cercanas
Filtrado por tienda: Los resultados se filtran por ID de tienda para garantizar que solo se muestren los artículos en stock en la tienda actual
Fusión de resultados: Los resultados vectoriales se combinan con los resultados de Elasticsearch cuando la búsqueda tradicional produce resultados insatisfactorios, proporcionando una experiencia de búsqueda más rica y completa
Crítico para la experiencia del usuario es el filtrado a nivel de tienda, que garantiza que los resultados pertenezcan al contexto de ubicación actual del comprador. El sistema emplea una agregación inteligente de resultados: cuando Elasticsearch produce resultados insatisfactorios, los artículos semánticamente relevantes de Milvus complementan la respuesta.
Resultados de rendimiento e impacto en el mundo real
La implementación de Milvus de DiDi produjo mejoras concretas en métricas empresariales críticas.
El sistema logró una reducción del 19% en las consultas sin resultados, lo que significa que casi una de cada cinco búsquedas que antes fallaban ahora devuelve productos relevantes, recuperando directamente oportunidades de ingresos perdidas. Para una plataforma que procesa 500 000 pedidos diarios, esta tasa de recuperación representa un valor empresarial significativo.
La búsqueda vectorial se activa para el 15% del total de consultas, complementando la búsqueda de texto tradicional precisamente cuando la comprensión semántica aporta valor sin sobrecargar el flujo principal de consultas. Lo más significativo es que los usuarios expuestos a artículos recuperados mediante vectores muestran un aumento del 4% en las conversiones de adición al carrito, lo que demuestra que una mayor relevancia en la búsqueda se traduce en un comportamiento de compra medible.
El sistema ahora gestiona consultas en varios idiomas, incluidos inglés, español, chino, coreano y japonés, con mejoras de precisión particularmente notables para el español, cruciales para la presencia de DiDi en el mercado latinoamericano. Las pruebas de rendimiento multilingüe revelaron el poder de la comprensión semántica: las búsquedas de "Liquid Foundation" funcionan igual de bien tanto si los usuarios escriben el término en inglés, el chino "液体妆前乳," o el español "Base de maquillaje líquida." El sistema salva brechas lingüísticas que desconcertarían por completo a los enfoques tradicionales basados en palabras clave.
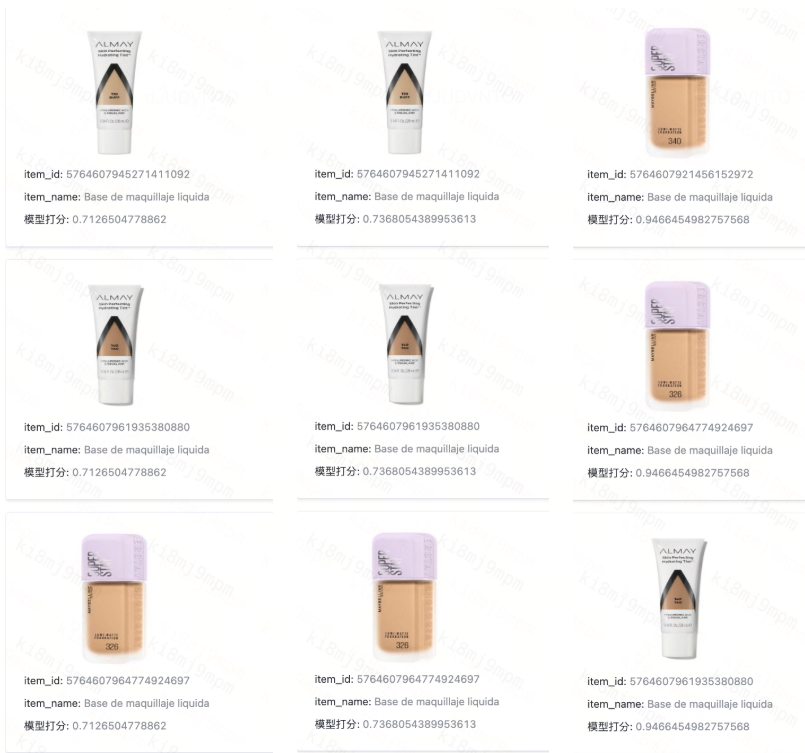
Figura: Las búsquedas de "Liquid Foundation" funcionan igual de bien tanto si los usuarios escriben el término en inglés, el chino "液体妆前乳," o el español "Base de maquillaje líquida."
Las consultas complejas de productos demuestran la comprensión contextual de la búsqueda vectorial. Cuando los usuarios buscan "Redac PalancaPara WC Blanca" (una palanca blanca de descarga para inodoro), el sistema vectorial coincide con precisión con la consulta a pesar de la terminología técnica compuesta, mientras que la búsqueda tradicional no logra analizar la descripción de producto de varias palabras.
Estas mejoras se traducen en una experiencia de compra más fluida, una mayor satisfacción del cliente y una ventaja competitiva definitiva en el mercado de comercio electrónico de productos frescos.
Hoja de ruta futura: Capacidades de búsqueda de próxima generación
Sobre esta base sólida, DiDi y Milvus están colaborando en varias capacidades avanzadas para la siguiente fase de desarrollo.
La sincronización del catálogo en tiempo real reducirá la latencia entre los cambios de inventario y los datos consultables mediante actualizaciones en streaming, garantizando que los usuarios nunca vean productos que no estén realmente disponibles. La integración de señales de comportamiento combinará la similitud vectorial con el historial, las preferencias y las señales contextuales del usuario para ofrecer recomendaciones hiperpersonalizadas que mejoren con el tiempo.
La búsqueda híbrida avanzada y el reranking representan quizá el desarrollo más emocionante. Este sistema combinará métricas de negocio, incluidos precio, valoraciones, promociones y niveles de inventario, con relevancia semántica para mostrar recomendaciones verdaderamente óptimas para cada comprador individual.
El soporte multilingüe mejorado ampliará la cobertura de idiomas y mejorará la gestión de dialectos regionales a medida que DiDi entre en nuevos mercados. La optimización dinámica de embeddings implementará mecanismos de aprendizaje continuo para mejorar la calidad de los embeddings en función de los patrones reales de interacción de los usuarios, creando así un sistema de búsqueda que se vuelve cada vez más inteligente con el uso.
Al innovar continuamente, DiDi está redefiniendo la experiencia de búsqueda de comestibles, asegurando que cada comprador encuentre exactamente lo que necesita, en todo momento.
Conclusión
La trayectoria de DiDi Food con Milvus demuestra que la búsqueda semántica representa más que una actualización técnica: es una reimaginación fundamental de cómo los usuarios interactúan con grandes catálogos de productos. Al combinar una arquitectura de datos bien pensada, elecciones tecnológicas adecuadas y un enfoque inquebrantable en la experiencia del usuario, han creado un sistema de búsqueda que realmente comprende la intención entre idiomas y culturas.
Los resultados validan este enfoque: menos usuarios frustrados, más compras exitosas y una experiencia de compra que funciona independientemente de cómo los clientes elijan expresar sus necesidades. Para los 2 millones de usuarios mensuales de DiDi, esto significa encontrar de manera constante lo que necesitan, cuando lo necesitan, en el idioma que les resulte más natural.
Esta historia de éxito ilustra lo que se vuelve posible cuando las empresas innovadoras adoptan la comprensión semántica a escala. A medida que DiDi continúa expandiéndose por América Latina, su arquitectura de búsqueda impulsada por Milvus proporciona una base sólida para la innovación continua y la satisfacción del usuario. La tecnología funciona, los resultados empresariales son claros y la mejora de la experiencia del usuario es tangible: exactamente lo que una gran ingeniería debería ofrecer.