




La interrupción de AWS fue una llamada de atención para la recuperación ante desastres entre regiones de bases de datos vectoriales
Las regiones de la nube fallan. No es cuestión de si ocurrirá, sino de cuándo y cuán grave será.
La semana pasada, dos regiones de AWS en Oriente Medio quedaron fuera de servicio debido a daños físicos en la infraestructura del centro de datos. Dos de las tres zonas de disponibilidad en la región de AWS en EAU (ME-CENTRAL-1) quedaron inutilizadas, y una instalación en Baréin (ME-SOUTH-1) sufrió daños. Más de 60 servicios de AWS se vieron afectados, incluidos Lambda, EKS, VPC, S3 y CloudWatch. Careem, la mayor plataforma de transporte con conductor de la región, perdió el servicio. Alaan, un proveedor líder de pagos, quedó fuera de línea. AWS aconsejó a los clientes trasladar las cargas de trabajo a otras regiones, pero este no fue un incidente de reiniciar y recuperar. Con reemplazo de hardware y reparación de instalaciones, la recuperación puede llevar semanas.
Y el daño físico es solo un modo de fallo. Durante los últimos 12 meses, un cambio de configuración defectuoso dejó fuera de servicio la región Central US de Azure durante 14,5 horas. Un error en Google Cloud dejó sin servicio simultáneamente a Cloud Run, GKE y Firebase durante 8 horas. Una actualización de software defectuosa de CrowdStrike — ni siquiera un problema de un proveedor de nube — se propagó en cascada por infraestructura alojada en Azure, costando a las empresas Fortune 500 un estimado de 5.400 millones de dólares.
El informe de 2025 del Uptime Institute sitúa el coste mediano de una interrupción de alto impacto en 2 millones de dólares por hora, aproximadamente el doble de la cifra de hace tres años. Sin embargo, el informe Data Protection Trends Report 2024 de Veeam encontró que solo el 13% de las organizaciones puede realmente orquestar la recuperación durante un desastre real.
Estas cifras ya eran alarmantes. Entonces la IA elevó las apuestas.
Cuando la IA cae, los equipos no reducen el ritmo — se detienen
Hace cinco años, un fallo regional en la nube afectaba principalmente a las aplicaciones orientadas al cliente. Doloroso, pero la mayoría de los equipos aún podía funcionar internamente. Hoy, la IA ha absorbido trabajo que abarca departamentos enteros: revisión de código, documentación, clasificación de soporte e incluso análisis rutinario. Con casi el 60% de los empleados usando IA en flujos de trabajo diarios, las interrupciones no causan una desaceleración gradual. La productividad se desploma.
Ya hemos visto esto ocurrir: ChatGPT y Claude sufrieron interrupciones significativas a principios de 2026, dejando a millones de usuarios y equipos empresariales sin las herramientas de IA alrededor de las cuales habían construido sus flujos de trabajo.
Pero esto es lo que la mayoría de los equipos pasa por alto. Las interrupciones de modelos son disruptivas, pero los modelos son en gran medida sin estado: los proveedores a menudo pueden redirigir el tráfico de inferencia a regiones saludables con relativa rapidez. El problema más difícil es la capa de datos subyacente: las bases de datos, almacenes de objetos e índices vectoriales que suministran memoria y contexto. Esa capa tiene estado, está vinculada a una región y es mucho más difícil de recuperar. Cuando cae, tu LLM aún puede generar texto, pero sin el contexto correcto, recurre por defecto a una salida genérica y propensa a alucinaciones. La IA no solo queda fuera de línea. Se vuelve poco fiable.
La base de datos vectorial es la memoria a largo plazo de tu IA — y probablemente esté en una sola región
Las bases de datos vectoriales se han convertido en la columna vertebral de la IA empresarial. Las canalizaciones RAG y los agentes de IA recuperan contexto de ellas. Los motores de recomendación las consultan. La búsqueda semántica se ejecuta contra ellas. Cuando esta capa no está disponible, todas las aplicaciones construidas sobre ella se rompen — no parcialmente, sino por completo.
Y a diferencia de los servicios sin estado, la recuperación no es sencilla:
- La reconstrucción de índices es lenta. La búsqueda vectorial depende de estructuras de índice como grafos HNSW, donde el tiempo de reconstrucción escala de forma no lineal con el tamaño del conjunto de datos. Reconstruir un índice sobre más de 100M vectores puede llevar más de 18 horas en computación estándar.
- Las cadenas de conexión están en todas partes. Cada aplicación que se conectaba al clúster antiguo necesita que se actualice su endpoint — en configuraciones, variables de entorno, canalizaciones CI/CD, a menudo gestionadas por equipos diferentes.
- Deriva del modelo de embeddings. Si no puedes localizar la versión exacta del modelo de embeddings que generó tus vectores actuales, puede que necesites volver a generar embeddings para todo tu conjunto de datos.
Para una interrupción de software, esperas un reinicio. Pero cuando un centro de datos sufre daños físicos, la recuperación tarda semanas. La única estrategia viable es tener ya una réplica activa, indexada y lista para consultas sirviendo desde otra región — con redireccionamiento de tráfico que no requiera cambios en el código.
Zilliz Cloud: La primera base de datos vectorial del mundo con recuperación ante desastres nativa entre regiones
Zilliz Cloud es la primera base de datos vectorial del mundo en ofrecer recuperación ante desastres nativa entre regiones — con conmutación por error automatizada, replicación en tiempo real y un endpoint global que no requiere cambios en la aplicación durante las transiciones de región.
Ofrecemos dos capacidades complementarias: Global Cluster para conmutación por error en tiempo real, y Cross-Region Backup para una recuperación ante desastres rentable.
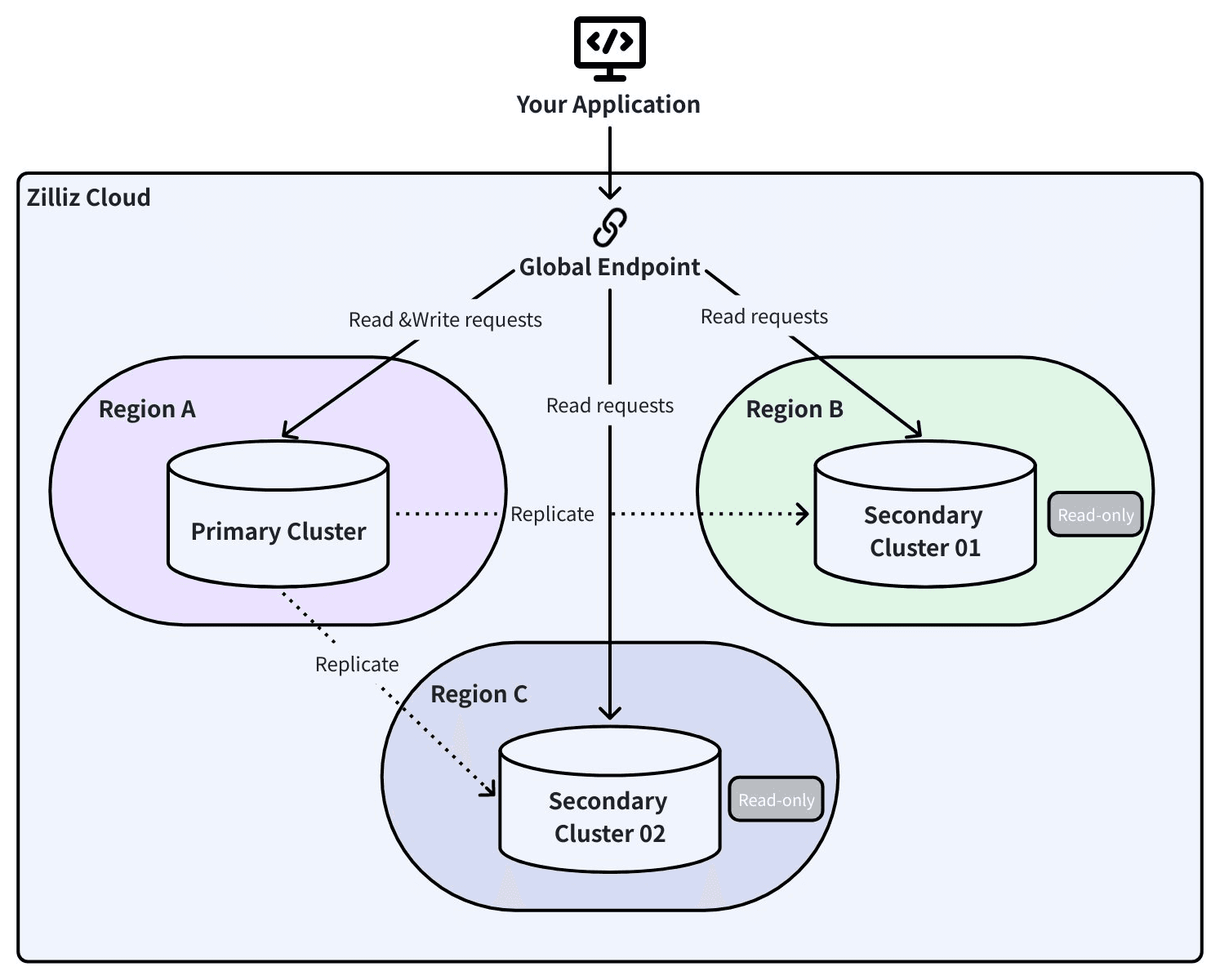
Global Cluster: Replicación activa con conmutación por error automática
Global Cluster utiliza Change Data Capture (CDC) para replicar datos continuamente entre un clúster primario y uno secundario en una región diferente. No son snapshots periódicos — cada inserción, actualización y eliminación se propaga en tiempo real.
- Conmutación planificada (mantenimiento, migración, cumplimiento): El sistema drena los mensajes CDC en curso, confirma la sincronización completa y luego intercambia los roles. El RPO es cero. El RTO es inferior a 30 segundos.
- Conmutación por error automática (fallo inesperado de región): El secundario se promueve automáticamente. El RPO equivale al retraso de CDC en el momento del fallo — normalmente unos pocos segundos. El RTO es inferior a 60 segundos.
Una capacidad única: después de una conmutación por error, el primario antiguo no desaparece sin más. Va a una papelera de reciclaje con retención de 7 días, y una API de streaming llamada DumpMessages te permite extraer cualquier escritura que haya llegado al primario antiguo pero que aún no se hubiera replicado. En lugar de aceptar la pérdida de datos, obtienes una ventana para recuperarlos.
Global Endpoint: Una conexión, todas las regiones
Aquí es donde la arquitectura da sus frutos en un escenario de desastre físico.
Tu aplicación se conecta a un único endpoint global. Detrás de él, los registros DNS SRV rastrean qué clúster es primario y cuál es secundario. Cuando se produce una conmutación por error, el SDK detecta el cambio de topología y redirige el tráfico automáticamente. Sin actualizaciones de cadenas de conexión. Sin reinicios de la aplicación. Sin cambios de código.
Piensa en lo que esto significa durante una interrupción regional prolongada. Sin un endpoint global, la recuperación requiere que alguien encuentre un runbook, reconfigure manualmente los clientes, actualice las cadenas de conexión y coordine entre equipos — a las 3 de la madrugada, bajo presión. Tu RTO no se mide en segundos; se mide en el tiempo que tarde en avisarse al ingeniero adecuado.
Con Global Endpoint, tu canalización RAG consulta la réplica en otra región en menos de 60 segundos, sin cambiar una sola línea de código.
Cross-Region Backup: Resiliencia sin el coste de una réplica activa
No toda carga de trabajo justifica ejecutar un clúster secundario. Cross-Region Backup replica los datos de backup en una o más regiones de destino, cada una con su propia política de retención. Cuando se produce un fallo a nivel de región, levantas un nuevo clúster desde cualquier punto de backup en la región de destino — sin necesidad de transferencia de datos entre regiones durante la crisis, porque los datos ya están allí.
La compensación:
- Global Cluster → RPO en segundos, RTO inferior a 60 segundos. Para cargas de trabajo que no pueden tolerar ningún tiempo de inactividad.
- Cross-Region Backup → RPO y RTO en horas. Para cargas de trabajo donde la supervivencia de los datos importa más que la recuperación instantánea.
Muchos equipos empiezan con Cross-Region Backup por la garantía crítica — tus datos sobreviven a un fallo de región — y pasan a Global Cluster a medida que sus cargas de trabajo de IA se vuelven de misión crítica.
Cómo otras bases de datos vectoriales gestionan la recuperación ante desastres entre regiones
La mayoría de las bases de datos vectoriales ofrecen alta disponibilidad dentro de una sola región mediante conjuntos de réplicas y redundancia de nodos. Eso gestiona fallos de nodos, no fallos de región. Zilliz Cloud es la única base de datos vectorial que ofrece conmutación por error automatizada nativa entre regiones con un clúster global y un endpoint global: transiciones de región sin tiempo de inactividad y sin cambios de código.
| Capacidad | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Replicación entre regiones | ✅ Basada en CDC, en tiempo real | ❌ | ❌ | ❌ | ❌ |
| Conmutación por error no planificada | ✅ RPO ≈ segundos, RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| Conmutación planificada | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Recuperación de datos posterior a la conmutación por error | ✅ Recuperación automática de datos que no se sincronizaron. | ❌ | ❌ | ❌ | ❌ |
| Endpoint global | ✅ Un endpoint global, redireccionamiento automático sin cambios de código | ❌ | ❌ | ❌ | ❌ |
| RPO/RTO por fallo regional | ✅ RPO ≈ segundos, RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| Copia de seguridad automática entre regiones | ✅ CUALQUIER región con retención por región | ❌ | ❌ | ❌ | ❌ |
Más allá de la recuperación ante desastres
Los equipos también usan Global Cluster para escenarios operativos que no tienen nada que ver con interrupciones:
- Optimización de latencia: Añade una región secundaria más cercana a tus usuarios para tiempos de respuesta de consultas inferiores a 100 ms.
- Migración de región: Mueve cargas de trabajo entre regiones sin tiempo de inactividad durante la consolidación de infraestructura.
- Cumplimiento de residencia de datos: Mantén los datos dentro de fronteras geográficas específicas para cumplir con los requisitos regulatorios.
La misma canalización CDC que protege contra interrupciones también te ofrece una réplica con capacidad de lectura más cercana a tus usuarios: capacidad de DR como efecto secundario de la optimización del rendimiento.
Primeros pasos
Global Cluster y Cross-Region Backup están disponibles en Zilliz Cloud para clústeres dedicados.
- Si ya tienes una cuenta de Zilliz Cloud, simplemente inicia sesión y empieza a usar las nuevas funciones de inmediato, sin necesidad de actualizaciones ni migraciones.
- ¿Eres nuevo en Zilliz Cloud? Regístrate gratis y obtén \$100 en créditos para experimentar la base de datos vectorial gestionada líder del mundo.
- ¿Tienes preguntas sobre alguna de las actualizaciones? Consulta la última documentación o ponte en contacto con Zilliz Support; estamos aquí para ayudar.
Crea sin límites: una mirada más cercana a las capacidades de Zilliz Cloud listas para la empresa
Global Cluster es una pieza de una plataforma más amplia creada para IA a escala de producción. Zilliz Cloud también ofrece:
- Escalado elástico y eficiencia de costes – Implementación con un clic, autoescalado serverless y precios de pago por uso.
- Búsqueda de IA avanzada – Búsqueda vectorial, de texto completo e híbrida (dispersa + densa) con filtrado de metadatos, esquema dinámico y multi-tenencia.
- Seguridad de nivel empresarial – SLA del 99,95 %, certificaciones SOC 2 Type II e ISO 27001, cumplimiento de GDPR, preparación para HIPAA, RBAC, BYOC y registros de auditoría. Consulta nuestro centro de confianza para más información.
- Disponibilidad global – Implementaciones en AWS, GCP y Azure con latencia inferior a 100 ms en todo el mundo.
- Migración fluida – Herramientas integradas para migrar desde Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate o Milvus on-prem.
- Consultas en lenguaje natural – Compatibilidad con servidor MCP para consultas intuitivas sin APIs complejas.
- ¡Y más!

Sigue leyendo

Stop Building AI Data Infra for the Wrong Stage
Learn how AI data infrastructure should evolve from prototype to enterprise scale, and when Vector Lakebase becomes the right architecture for AI apps.

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.