




Llamada a funciones con Ollama, Llama 3.2 y Milvus
Actualizado el 25 de septiembre de 2024 con Llama 3.2
La llamada a funciones con LLMs es como dar a tu IA el poder de conectarse con el mundo. Al integrar tu LLM con herramientas externas como funciones definidas por el usuario o API, puedes crear aplicaciones que resuelvan problemas del mundo real.
En esta entrada de blog, comprobaremos cómo integrar Llama 3.2 con herramientas externas como Milvus y APIs para construir aplicaciones potentes y conscientes del contexto.
Introducción a la llamada de funciones
LLMs como GPT-4, Mistral Nemo, y Llama 3.2 ahora pueden detectar cuando necesitan llamar a una función y luego emitir JSON con argumentos para llamar a esa función. Esto hace que tus aplicaciones de IA sean más versátiles y potentes.
La llamada funcional permite a los desarrolladores crear:
Soluciones basadas en LLM para extraer y etiquetar datos (por ejemplo, extraer los nombres de las personas de un artículo de Wikipedia).
aplicaciones que ayuden a convertir el lenguaje natural en llamadas API o consultas válidas a bases de datos
motores de recuperación de conocimiento conversacional que interactúan con una base de conocimientos
**Las herramientas
Ollama**: Lleva la potencia de los LLM a su ordenador portátil, simplificando el funcionamiento local.
Milvus**: Nuestra base de datos vectorial para almacenar y recuperar datos de forma eficaz.
Llama 3.2-3B: La versión mejorada del modelo 3.1, es multilingüe y tiene una longitud de contexto significativamente mayor, de 128K, y puede aprovechar el uso de herramientas.
Uso de Llama 3.2 y Ollama
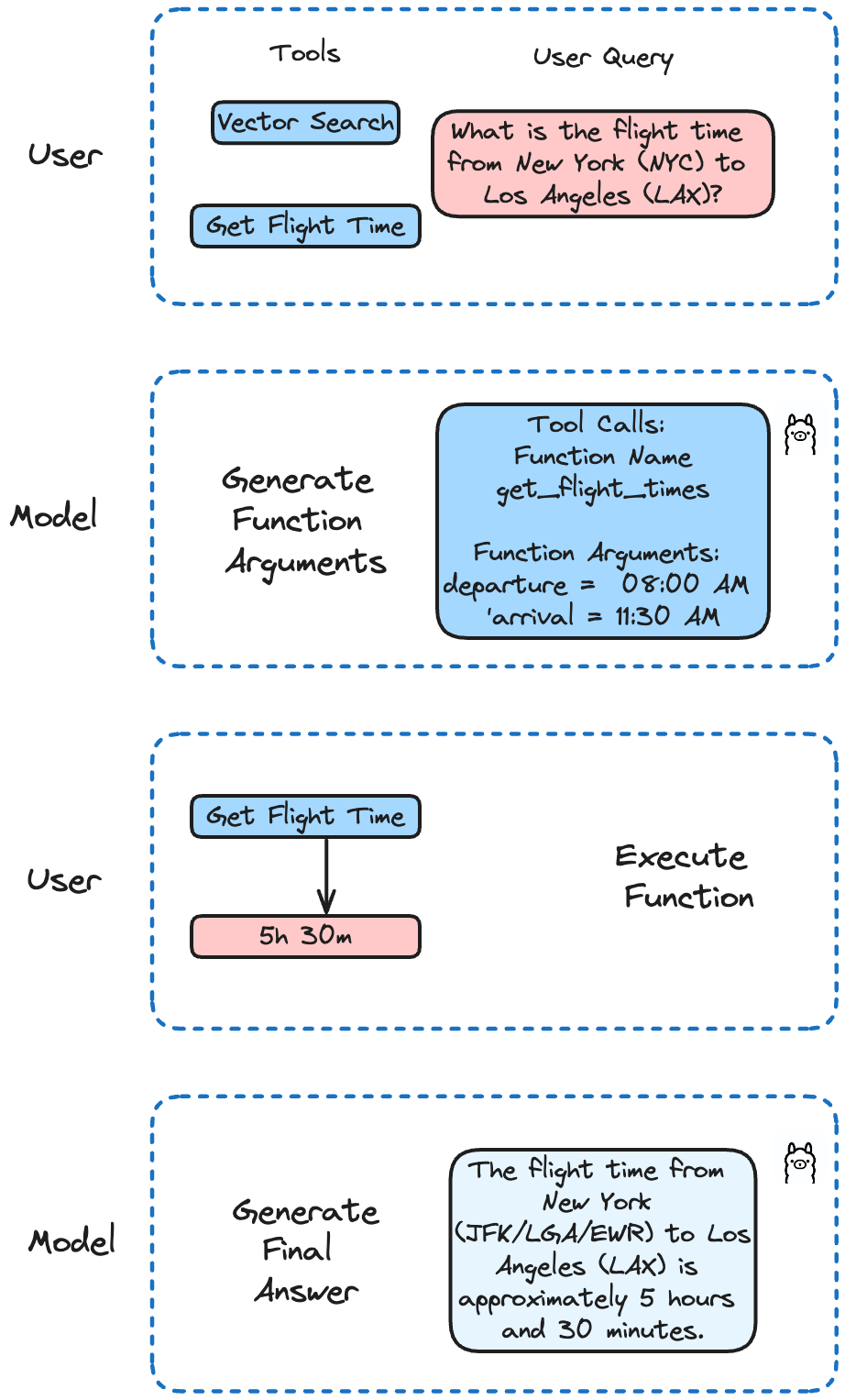
Llama 3.2 se ha afinado en las llamadas a funciones. Soporta llamadas a funciones simples, anidadas y paralelas, así como llamadas a funciones multi-vuelta. Esto significa que tu IA puede manejar tareas complejas que implican múltiples pasos o procesos paralelos.
En nuestro ejemplo, implementaremos diferentes funciones para simular una llamada a la API para obtener tiempos de vuelo y realizar búsquedas en Milvus. Llama 3.2 decidirá a qué función llamar en función de la consulta del usuario.
Instalar Dependencias
Primero, vamos a instalarlo todo. Descarga Llama 3.2 usando Ollama:
ollama run llama3.2
Esto descargará el modelo en tu portátil, dejándolo listo para su uso con Ollama. A continuación, instala las dependencias necesarias:
pip install ollama openai "pymilvus[model]"
Estamos instalando Milvus Lite con la extensión model, que permite incrustar datos utilizando los modelos disponibles en Milvus.
Insertar Datos en Milvus
Ahora, vamos a insertar algunos datos en Milvus. Estos son los datos que Llama 3.2 decidirá buscar más tarde si cree que son relevantes.
Crear e insertar los datos
from pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"La inteligencia artificial se fundó como disciplina académica en 1956",
"Alan Turing fue la primera persona en llevar a cabo una investigación sustancial en IA",
"Nacido en Maida Vale, Londres, Turing se crió en el sur de Inglaterra",
]
vectores = embedding_fn.encode_documents(docs)
# El vector de salida tiene 768 dimensiones, coincidiendo con la colección que acabamos de crear.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# Cada entidad tiene id, representación vectorial, texto en bruto y una etiqueta de asunto.
datos = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "historia"}
for i in range(len(vectors))
]
print("Los datos tienen", len(datos), "entidades, cada una con campos: ", datos[0].claves())
print("Vector dim:", len(datos[0]["vector"]))
# Crear una colección e insertar los datos
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection",
dimension=768, # Los vectores que usaremos en esta demo tienen 768 dimensiones
)
client.insert(nombre_coleccion="coleccion_demostracion", datos=datos)
Deberías tener 3 elementos en tu nueva colección.
Definir las funciones a utilizar
En este ejemplo, estamos definiendo dos funciones. La primera simula una llamada a la API para obtener los horarios de vuelo. La segunda ejecuta una consulta de búsqueda en Milvus.
from pymilvus import model
import json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# Simula una llamada a la API para obtener tiempos de vuelo
# En una aplicación real, esto obtendría los datos de una base de datos en vivo o API
def get_flight_times(salida: cadena, llegada: cadena) -> cadena:
flights = {
'NYC-LAX': {'salida': '08:00 AM', 'llegada': '11:30 AM', 'duración': '5h 30m'},
LAX-NYC {'salida': '02:00 PM', 'llegada': '10:30 PM', 'duración': '5h 30m'},
LHR-JFK {'salida': '10:00 AM', 'llegada': '01:00 PM', 'duración': '8h 00m'},
JFK-LHR {'salida': '09:00 PM', 'llegada': '09:00 AM', 'duración': '7h 00m'},
CDG-DXB {'salida': '11:00 AM', 'llegada': '08:00 PM', 'duración': '6h 00m'},
'DXB-CDG': {'salida': '03:00 AM', 'llegada': '07:30 AM', 'duración': '7h 30m'},
}
key = f'{salida}-{llegada}'.upper()
return json.dumps(flights.get(key, {'error': 'Vuelo no encontrado'}))
# Buscar datos relacionados con la Inteligencia Artificial en una base de datos vectorial
def buscar_datos_en_vector_db(consulta: str) -> str:
query_vectors = embedding_fn.encode_queries([query])
res = cliente.buscar(
nombre_colección="colección_demostración",
data=vectores_consulta,
limit=2,
output_fields=["text", "subject"], # especifica los campos a devolver
)
print(res)
return json.dumps(res)
Dale las instrucciones a la LLM para poder usar esas funciones
Ahora, vamos a dar las instrucciones a la LLM para que pueda utilizar las funciones que hemos definido.
def run(modelo: str, pregunta: str):
cliente = ollama.Cliente()
# Inicializar la conversación con una pregunta de usuario
mensajes = [{"rol": "usuario", "contenido": pregunta}]
# Primera llamada a la API: Enviar la consulta y la descripción de la función al modelo
respuesta = cliente.chat(
modelo=modelo,
mensajes=mensajes,
herramientas=[
{
"tipo": "function",
"función": {
"name": "get_flight_times",
"description": "Obtener los tiempos de vuelo entre dos ciudades",
"parameters": {
"type": "object",
"propiedades": {
"salida": {
"tipo": "cadena",
"description": "La ciudad de salida (código de aeropuerto)",
},
"arrival": {
"tipo": "cadena",
"description": "La ciudad de llegada (código de aeropuerto)",
},
},
"required": ["salida", "llegada"],
},
},
},
{
"tipo": "function",
"function": {
"name": "buscar_datos_en_vector_db",
"description": "Búsqueda sobre datos de Inteligencia Artificial en una base de datos vectorial",
"parameters": {
"tipo": "object",
"propiedades": {
"consulta": {
"tipo": "string",
"descripción": "La consulta de búsqueda",
},
},
"required": ["query"],
},
},
},
],
)
# Añade la respuesta del modelo al historial de la conversación
messages.append(respuesta["mensaje"])
# Comprueba si el modelo ha decidido utilizar la función proporcionada
if not response["message"].get("tool_calls"):
print("El modelo no utilizó la función. Su respuesta fue:")
print(respuesta["mensaje"]["contenido"])
devuelve
# Procesar las llamadas a funciones realizadas por el modelo
if response["message"].get("tool_calls"):
available_functions = {
"get_flight_times": get_flight_times,
"search_data_in_vector_db": search_data_in_vector_db,
}
for herramienta in respuesta["mensaje"]["llamadas_a_herramienta"]:
function_to_call = available_functions[tool["function"]["name"]]
función_args = herramienta["función"]["argumentos"]
función_respuesta = función_a_llamada(**función_argumentos)
# Añadir la función respuesta a la conversación
messages.append(
{
"función": "herramienta",
"contenido": función_respuesta,
}
)
# Segunda llamada a la API: Obtener la respuesta final del modelo
respuesta_final = cliente.chat(modelo=modelo, mensajes=mensajes)
print(respuesta_final["mensaje"]["contenido"])
Ejemplo de uso
Comprobemos si podemos obtener la hora de un vuelo específico:
question = "¿Cuál es el tiempo de vuelo de Nueva York (NYC) a Los Ángeles (LAX)?"
run('llama3.2', pregunta)
Lo que da como resultado:
El tiempo de vuelo desde Nueva York (JFK/LGA/EWR) a Los Ángeles (LAX) está alrededor de 5 horas y 30 minutos. Sin embargo, tenga en cuenta que este tiempo puede variar en función de la compañía aérea, el horario del vuelo y las posibles escalas o retrasos. Siempre es mejor consultar con su compañía aérea para obtener la información de vuelo más actualizada y precisa.
Ahora, veamos si Llama 3.2 puede hacer una búsqueda vectorial utilizando Milvus.
question = "¿Cuándo se fundó la Inteligencia Artificial?"
run("llama3.2", question)
Que devuelve una búsqueda Milvus:
datos: ["[{'id': 0, 'distancia': 0.5738513469696045, 'entity': {'text': 'La inteligencia artificial se fundó como disciplina académica en 1956.', 'subject': 'history'}}, {'id': 1, 'distance': 0.4090226888656616, 'entity': {'text': 'Alan Turing fue la primera persona en llevar a cabo una investigación sustancial en IA.', 'subject': 'history'}}]"]
La Inteligencia Artificial se fundó como disciplina académica en 1956.
Conclusión
Las llamadas a funciones con LLM abren un mundo de posibilidades. Al integrar Llama 3.2 con herramientas externas como Milvus y APIs, puede crear aplicaciones potentes y conscientes del contexto que se adapten a casos de uso específicos y problemas prácticos.
No dude en consultar Milvus, el código en Github y compartir sus experiencias con la comunidad uniéndose a nuestro Discord.

Sigue leyendo

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.