




Semantische Suche schnell entwickeln
Semantische Suche ist ein großartiges Tool, um Ihren Kunden – oder Ihren Mitarbeitern – dabei zu helfen, die richtigen Produkte oder Informationen zu finden. Sie kann sogar schwer zu indexierende Informationen für bessere Ergebnisse zutage fördern. Allerdings gilt: Wenn Ihre semantischen Methoden nicht so eingesetzt werden, dass sie schnell arbeiten, nützen sie Ihnen nichts. Der Kunde oder Mitarbeiter wird nicht einfach herumsitzen, während das System sich Zeit nimmt, auf seine Anfrage zu antworten – und wahrscheinlich werden gleichzeitig tausend weitere Anfragen verarbeitet.
Wie können Sie semantische Suche schnell machen? Langsame semantische Suche reicht nicht aus.
Glücklicherweise ist dies genau die Art von Problem, die Lucidworks gerne löst. Wir haben kürzlich einen Cluster bescheidener Größe getestet – lesen Sie weiter für weitere Details –, der 1500 RPS (Anfragen pro Sekunde) bei einer Sammlung von über einer Million Dokumenten erzielte, mit einer durchschnittlichen Antwortzeit von etwa 40 Millisekunden. Das ist wirklich beeindruckende Geschwindigkeit.
Implementierung semantischer Suche
Um blitzschnelle Machine-Learning-Magie zu ermöglichen, hat Lucidworks semantische Suche mithilfe des Ansatzes der semantischen Vektorsuche implementiert. Es gibt zwei entscheidende Teile.
Teil Eins: Das Machine-Learning-Modell
Zunächst benötigen Sie eine Möglichkeit, Text in einen numerischen Vektor zu codieren. Der Text könnte eine Produktbeschreibung, eine Suchanfrage eines Benutzers, eine Frage oder sogar eine Antwort auf eine Frage sein. Ein semantisches Suchmodell wird darauf trainiert, Text so zu codieren, dass Text, der anderem Text semantisch ähnlich ist, in Vektoren codiert wird, die numerisch „nah“ beieinanderliegen. Dieser Codierungsschritt muss schnell sein, um die tausend oder mehr möglichen Kundensuchen oder Benutzeranfragen zu unterstützen, die jede Sekunde eingehen.
Teil Zwei: Die Vektorsuchmaschine
Zweitens benötigen Sie eine Möglichkeit, schnell die besten Übereinstimmungen zur Kundensuche oder Benutzeranfrage zu finden. Das Modell hat diesen Text in einen numerischen Vektor codiert. Von dort aus müssen Sie ihn mit allen numerischen Vektoren in Ihrem Katalog oder Ihren Listen von Fragen und Antworten vergleichen, um die besten Übereinstimmungen zu finden – die Vektoren, die dem Anfragevektor am „nächsten“ sind. Dafür benötigen Sie eine Vektor-Engine, die all diese Informationen effektiv und mit Höchstgeschwindigkeit verarbeiten kann. Die Engine könnte Millionen von Vektoren enthalten, und Sie möchten wirklich nur die etwa zwanzig besten Übereinstimmungen zu Ihrer Anfrage. Und natürlich muss sie etwa tausend solcher Anfragen pro Sekunde verarbeiten.
Um diese Herausforderungen zu bewältigen, haben wir die Vektorsuchmaschine Milvus in unserer Fusion 5.3-Version hinzugefügt. Milvus ist Open-Source-Software und sie ist schnell. Milvus verwendet FAISS (Facebook AI Similarity Search), dieselbe Technologie, die Facebook in der Produktion für seine eigenen Machine-Learning-Initiativen einsetzt. Bei Bedarf kann sie auf GPU noch schneller ausgeführt werden. Wenn Fusion 5.3 (oder höher) mit der Machine-Learning-Komponente installiert wird, wird Milvus automatisch als Teil dieser Komponente installiert, sodass Sie all diese Funktionen mühelos aktivieren können.
Die Größe der Vektoren in einer bestimmten Sammlung, die bei der Erstellung der Sammlung festgelegt wird, hängt von dem Modell ab, das diese Vektoren erzeugt. Beispielsweise könnte eine bestimmte Sammlung die Vektoren speichern, die durch Codierung (über ein Modell) aller Produktbeschreibungen in einem Produktkatalog erstellt wurden. Ohne eine Vektorsuchmaschine wie Milvus wären Ähnlichkeitssuchen über den gesamten Vektorraum hinweg nicht durchführbar. Daher müssten Ähnlichkeitssuchen auf vorab ausgewählte Kandidaten aus dem Vektorraum beschränkt werden (zum Beispiel 500) und hätten sowohl eine langsamere Leistung als auch Ergebnisse geringerer Qualität. Milvus kann Hunderte Milliarden von Vektoren über mehrere Vektorsammlungen hinweg speichern, um sicherzustellen, dass die Suche schnell ist und die Ergebnisse relevant sind.
Verwendung semantischer Suche
Kehren wir zum Workflow der semantischen Suche zurück, nachdem wir nun ein wenig darüber erfahren haben, warum Milvus so wichtig sein könnte. Semantische Suche umfasst drei Phasen. In der ersten Phase wird das Machine-Learning-Modell geladen und/oder trainiert. Anschließend werden Daten in Milvus und Solr indexiert. Die letzte Phase ist die Abfragephase, in der die eigentliche Suche stattfindet. Im Folgenden konzentrieren wir uns auf diese letzten beiden Phasen.
Indexierung in Milvus
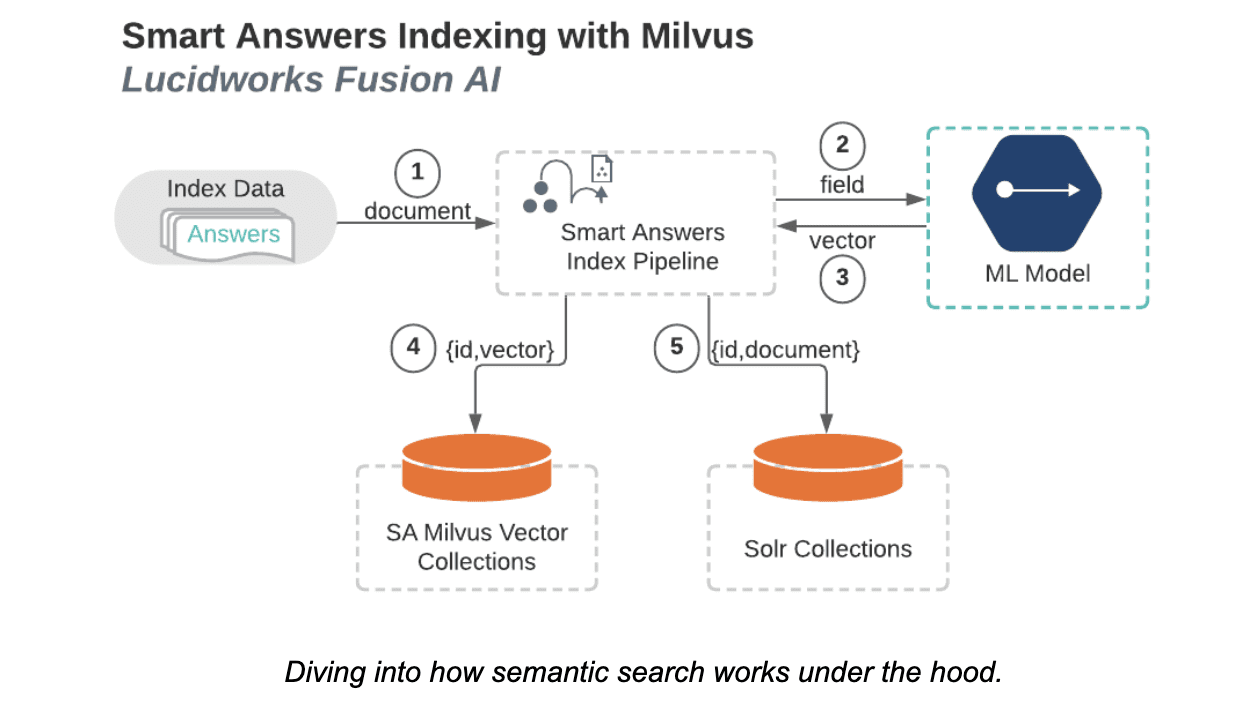 Architekturdiagramm für die Indexierung in Milvus.
Architekturdiagramm für die Indexierung in Milvus.
Wie im obigen Diagramm gezeigt, beginnt die Abfragephase ähnlich wie die Indexierungsphase, nur dass Abfragen statt Dokumente eingehen. Für jede Abfrage:
- Die Abfrage wird an die Smart Answers-Index-Pipeline gesendet.
- Die Abfrage wird dann an das ML-Modell gesendet.
- Das ML-Modell gibt einen numerischen Vektor zurück (aus der Abfrage verschlüsselt). Auch hier bestimmt die Art des Modells die Größe des Vektors.
- Der Vektor wird an Milvus gesendet, das dann bestimmt, welche Vektoren in der angegebenen Milvus-Collection am besten zu dem bereitgestellten Vektor passen.
- Milvus gibt eine Liste eindeutiger IDs und Distanzen zurück, die den in Schritt vier bestimmten Vektoren entsprechen.
- Eine Abfrage, die diese IDs und Distanzen enthält, wird an Solr gesendet.
- Solr gibt dann eine geordnete Liste der Dokumente zurück, die mit diesen IDs verknüpft sind.
Skalierungstests
Um nachzuweisen, dass unsere Abläufe für die semantische Suche mit der Effizienz laufen, die wir für unsere Kunden benötigen, führen wir Skalierungstests mit Gatling-Skripten auf der Google Cloud Platform durch, unter Verwendung eines Fusion-Clusters mit acht Replikaten des ML-Modells, acht Replikaten des Abfragedienstes und einer einzelnen Instanz von Milvus. Die Tests wurden mit den Milvus-Indizes FLAT und HNSW durchgeführt. Der FLAT-Index hat 100 % Recall, ist aber weniger effizient – außer wenn die Datensätze klein sind. Der HNSW-Index (Hierarchical Small World Graph) liefert weiterhin hochwertige Ergebnisse und bietet eine verbesserte Performance bei größeren Datensätzen.
Werfen wir einen Blick auf einige Zahlen aus einem aktuellen Beispiel, das wir durchgeführt haben:
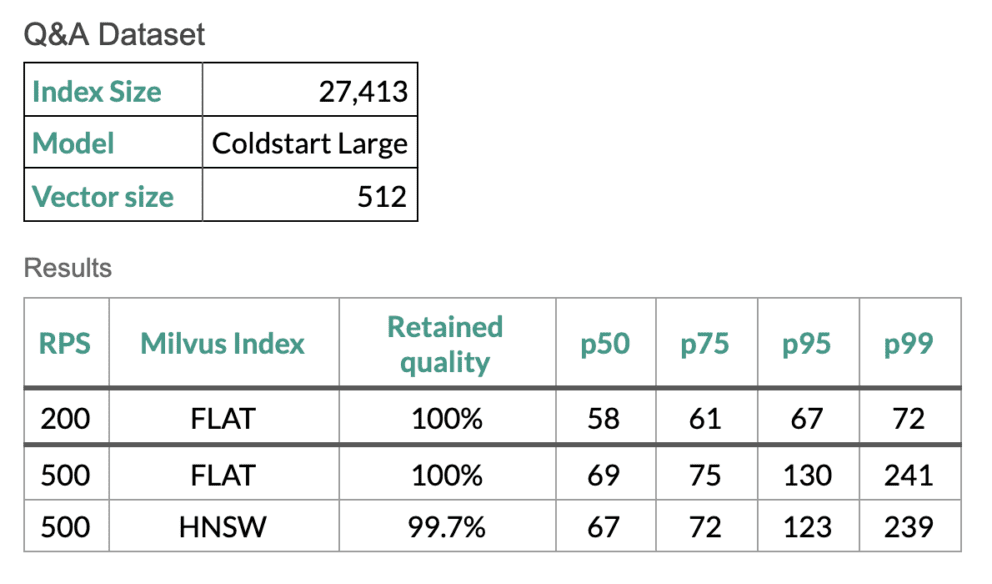 Performance der Milvus-Indizes FLAT und HNSW bei einem kleinen Datensatz.
Performance der Milvus-Indizes FLAT und HNSW bei einem kleinen Datensatz.
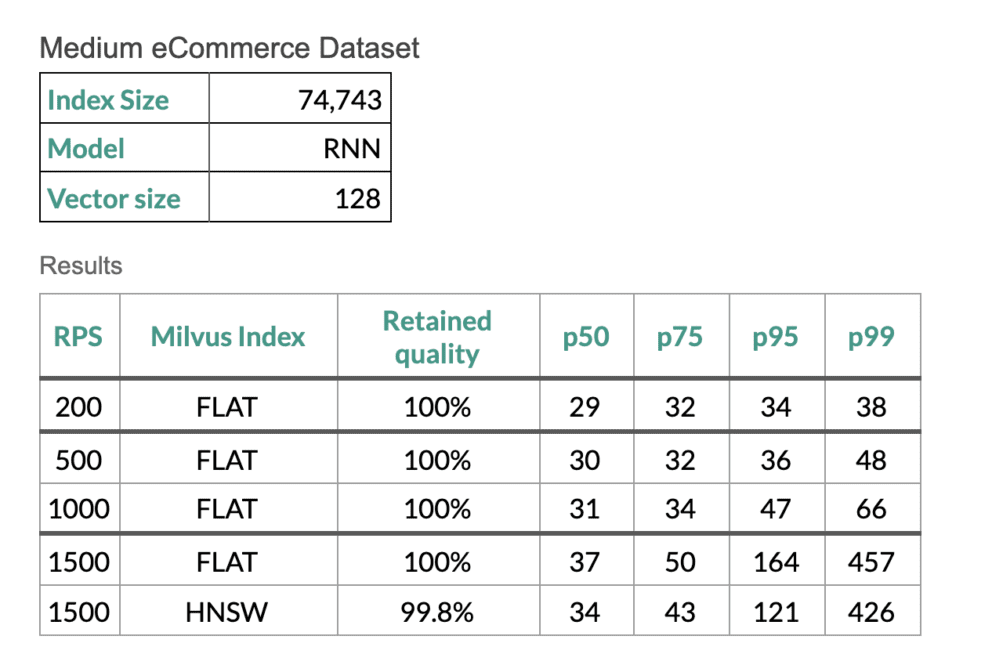 Performance der Milvus-Indizes FLAT und HNSW bei einem mittleren Datensatz.
Performance der Milvus-Indizes FLAT und HNSW bei einem mittleren Datensatz.
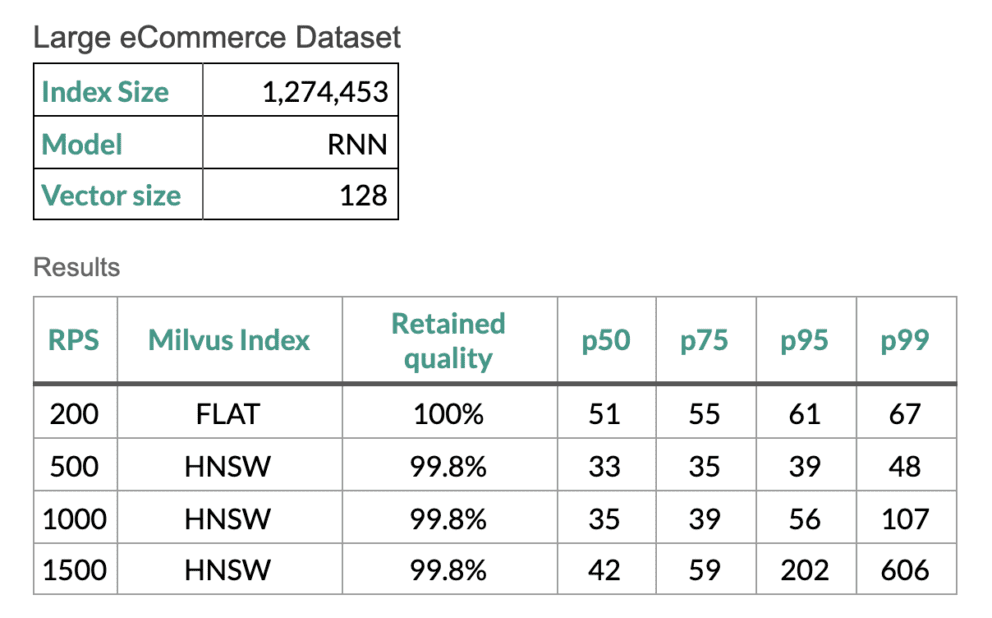 Performance der Milvus-Indizes FLAT und HNSW bei einem großen Datensatz.
Performance der Milvus-Indizes FLAT und HNSW bei einem großen Datensatz.
Erste Schritte
Die Smart Answers-Pipelines sind so konzipiert, dass sie einfach zu verwenden sind. Lucidworks bietet vortrainierte Modelle, die einfach bereitzustellen sind und im Allgemeinen gute Ergebnisse liefern—auch wenn das Training eigener Modelle, zusammen mit vortrainierten Modellen, die besten Ergebnisse bietet. Kontaktieren Sie uns noch heute, um zu erfahren, wie Sie diese Initiativen in Ihre Suchwerkzeuge implementieren können, um effektivere und erfreulichere Ergebnisse zu ermöglichen.
Dieser Blog wurde erneut veröffentlicht von: https://lucidworks.com/post/how-to-build-fast-semantic-search/?utm_campaign=Oktopost-Blog+Posts&utm_medium=organic_social&utm_source=linkedin
Weiterlesen

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.