




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
Utilize esta integração gratuitamente
Combinação das capacidades de processamento de dados e de pesquisa vetorial do Milvus & Zilliz Cloud
A Databricks é uma plataforma analítica unificada que simplifica o processamento de dados e as tarefas de aprendizagem automática. Foi criada com base no Apache Spark, um sistema de computação distribuída de código aberto. Proporciona um ambiente de colaboração para engenheiros de dados, cientistas de dados e analistas colaborarem em projectos de grandes volumes de dados. O Databricks abstrai as complexidades da gestão de clusters Spark, permitindo que os utilizadores se concentrem na análise de dados e nas tarefas de aprendizagem automática. Oferece blocos de notas interactivos, gestão automatizada de clusters e suporte integrado para várias fontes de dados e bibliotecas de aprendizagem automática. No geral, o Databricks melhora a usabilidade e a escalabilidade do Spark, facilitando para as organizações a obtenção de insights a partir de grandes conjuntos de dados.
O Spark Milvus Connector cria sinergias entre o Apache Spark e o Milvus, permitindo que os utilizadores aproveitem as capacidades de processamento do Spark juntamente com as funcionalidades de consulta e armazenamento de dados vectoriais do Milvus. Esta integração desbloqueia uma série de aplicações valiosas, tais como a transferência e integração de dados sem descontinuidades entre o Milvus e diferentes sistemas de armazenamento ou bases de dados, o processamento e análise de dados simplificados no Milvus e operações de processamento vetorial eficientes que tiram partido da Spark MLlib e de outras bibliotecas de IA.
Este mesmo conetor pode ser utilizado entre o Zilliz Cloud e o Databricks, simplificando a transição de dados do processamento offline para o online, importante para a pesquisa orientada para a IA.
Os principais destaques da integração incluem:
- Permitir que os trabalhos Spark geradores de vetores carreguem dados diretamente no Milvus com uma simples chamada de função utilitária, eliminando a necessidade de código de cola personalizado ou trabalhos Spark adicionais
- Inserir diretamente registros Spark DataFrame no Milvus usando o conetor Spark-Milvus simplifica a integração, eliminando a necessidade de código de estabelecimento de conexão e chamadas de API.
Como funciona
Vamos mergulhar no processo de transferência de dados do Spark para o Milvus. Tradicionalmente, essa tarefa exigia um código de backend complexo. No entanto, com o conetor Spark-Milvus, ela é simplificada em uma única chamada de função dentro do seu aplicativo Spark.
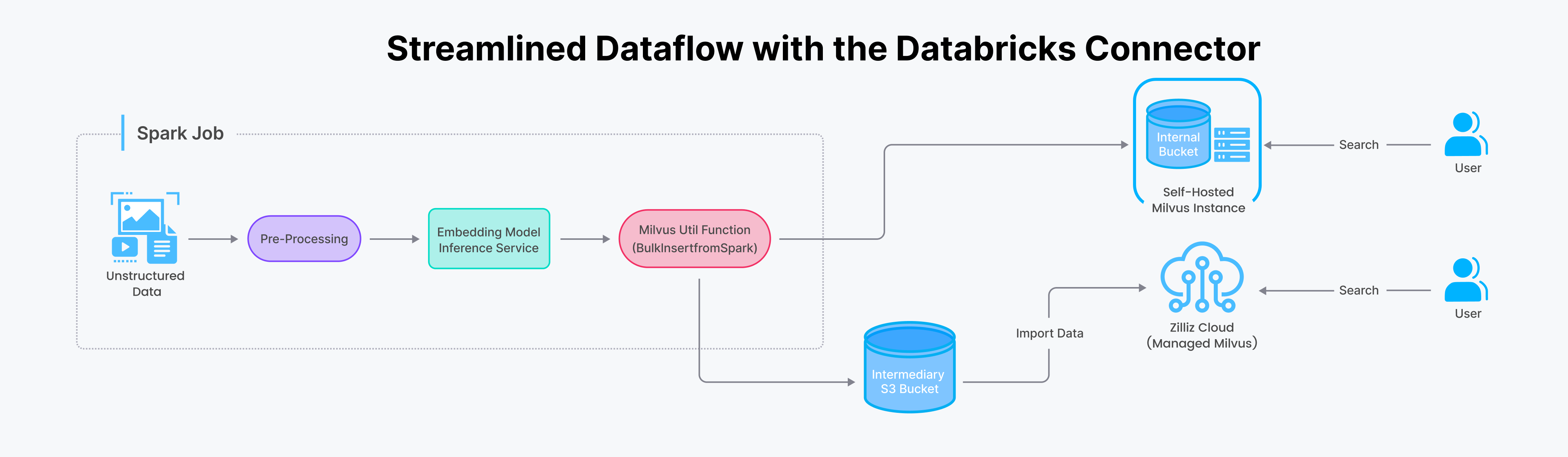 Fluxo de dados simplificado com o conetor Databricks.png
Fluxo de dados simplificado com o conetor Databricks.png
Com o Conector Spark/Databricks, pode importar dados para o Zilliz Cloud (ou Milvus) de duas formas: streaming para actualizações em tempo real e batch para grandes conjuntos de dados. Consulte os nossos notebooks de exemplo para obter um guia passo-a-passo sobre como utilizá-lo eficazmente.
Saiba como usar os conectores Sparks e Databricks
Consulte estes recursos para o ajudar a começar a utilizar o Zilliz Cloud, os Spark e os Databricks Connectors
Conector Spark Milvus
Conector Databricks