




Chamada de função com Ollama, Llama 3.2 e Milvus
*Atualizado em 25 de setembro de 2024 com Llama 3.2
A chamada de funções com LLMs é como dar à sua IA o poder de se conectar com o mundo. Ao integrar o seu LLM com ferramentas externas, tais como funções definidas pelo utilizador ou APIs, pode criar aplicações que resolvem problemas do mundo real.
Nesta publicação do blogue, vamos ver como integrar a Llama 3.2 com ferramentas externas como Milvus e APIs para criar aplicações poderosas e sensíveis ao contexto.
Introdução à chamada de funções
LLMs como GPT-4, Mistral Nemo e Llama 3.2 podem agora detetar quando eles precisam chamar uma função e então produzir JSON com argumentos para chamar essa função. Isso torna seus aplicativos de IA mais versáteis e poderosos.
A chamada funcional permite que os desenvolvedores criem:
Soluções com LLM para extrair e marcar dados (por exemplo, extrair nomes de pessoas de um artigo da Wikipédia)
aplicações que podem ajudar a converter linguagem natural em chamadas API ou consultas válidas a bases de dados
motores de recuperação de conhecimentos por conversação que interagem com uma base de conhecimentos
**As ferramentas
Ollama**: Traz o poder dos LLMs para o seu portátil, simplificando a operação local.
Milvus**: A nossa base de dados vetorial de referência para armazenamento e recuperação de dados eficientes.
Llama 3.2-3B**: A versão actualizada do modelo 3.1, é multilingue e tem um comprimento de contexto significativamente mais longo de 128K, e pode potenciar a utilização de ferramentas.
Usando Llama 3.2 e Ollama
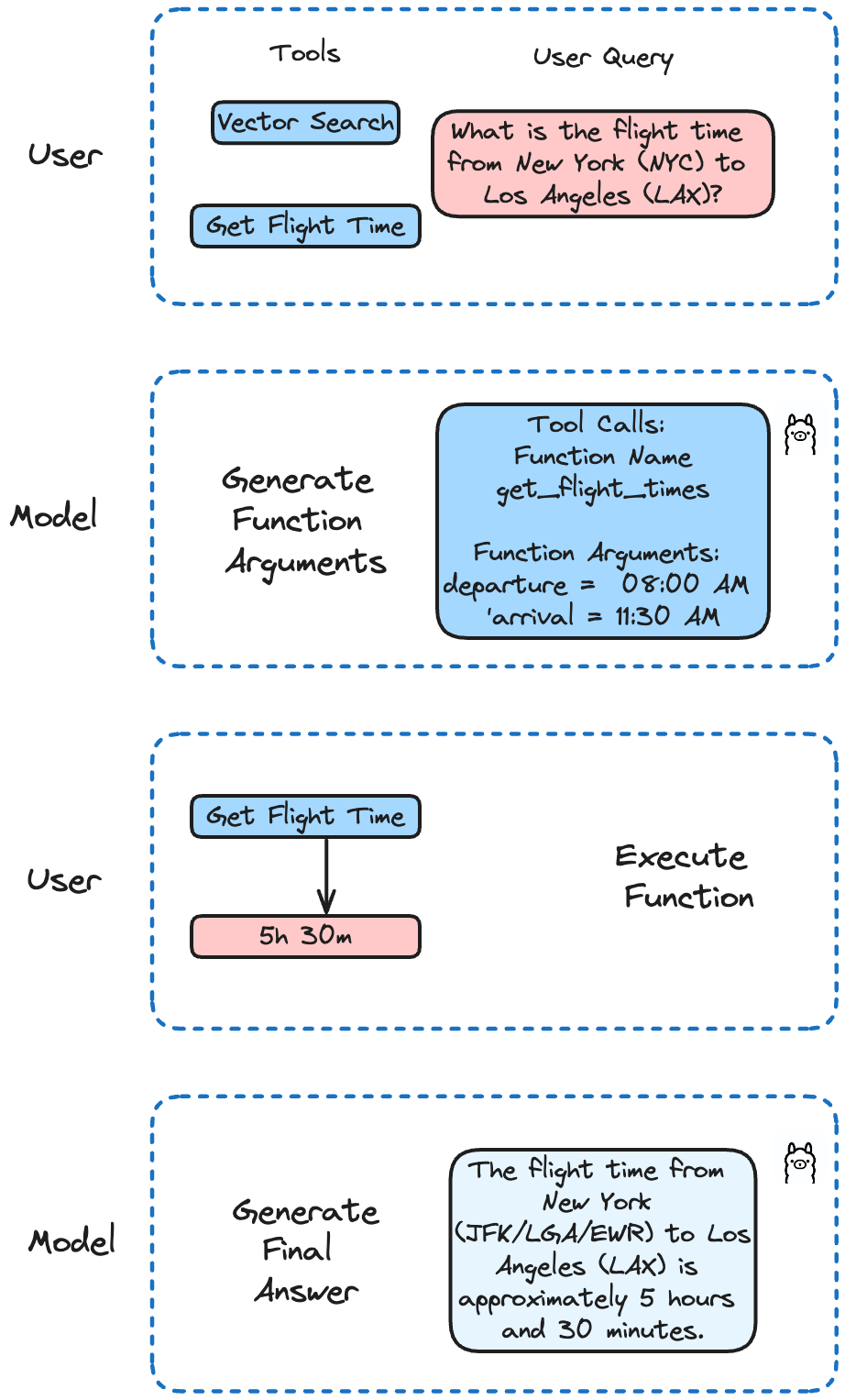
O Llama 3.2 foi aperfeiçoado nas chamadas de funções. Ele suporta chamadas de funções simples, aninhadas e paralelas, bem como chamadas de funções multi-turnos. Isto significa que a sua IA pode lidar com tarefas complexas que envolvem várias etapas ou processos paralelos.
No nosso exemplo, vamos implementar diferentes funções para simular uma chamada API para obter tempos de voo e efetuar pesquisas em Milvus. A Llama 3.2 decidirá qual a função a chamar com base na consulta do utilizador.
Instalar Dependências
Primeiro, vamos configurar tudo. Baixe o Llama 3.2 usando o Ollama:
ollama run llama3.2
Isso vai baixar o modelo para o seu laptop, deixando-o pronto para ser usado com o Ollama. Em seguida, instale as dependências necessárias:
! pip install ollama openai "pymilvus[modelo]"
Estamos a instalar o Milvus Lite com a extensão model, que permite incorporar dados usando os modelos disponíveis no Milvus.
Inserir dados no Milvus
Agora, vamos inserir alguns dados no Milvus. Estes são os dados que o Llama 3.2 decidirá procurar mais tarde se achar que são relevantes!
Criar e inserir os dados
from pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"A inteligência artificial foi fundada como disciplina académica em 1956",
"Alan Turing foi a primeira pessoa a efetuar investigação substancial em IA",
"Nascido em Maida Vale, Londres, Turing foi criado no sul de Inglaterra.",
]
vectores = embedding_fn.encode_documents(docs)
# O vetor de saída tem 768 dimensões, correspondendo à coleção que acabámos de criar.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# Cada entidade tem id, representação vetorial, texto em bruto e uma etiqueta de assunto.
dados = [
{"id": i, "vetor": vectors[i], "text": docs[i], "subject": "history"}
for i in range(len(vectors))
]
print("Os dados têm", len(dados), "entidades, cada uma com campos: ", dados[0].chaves())
print("Dimensão do vetor:", len(dados[0]["vetor"]))
# Criar uma coleção e inserir os dados
cliente = MilvusClient('./milvus_local.db')
client.create_collection(
nome_da_colecção="demo_collection",
dimension=768, # Os vectores que vamos utilizar nesta demonstração têm 768 dimensões
)
client.insert(nome_da_colecção="colecção_de_mostras", dados=dados)
Deverá então ter 3 elementos na sua nova coleção.
Defina as funções a serem usadas
Neste exemplo, estamos a definir duas funções. A primeira simula uma chamada à API para obter os horários dos voos. A segunda executa uma consulta de pesquisa no Milvus.
from pymilvus import model
import json
import ollama
embedding_fn = model.DefaultEmbeddingFunction()
# Simula uma chamada API para obter tempos de voo
# Numa aplicação real, isto iria buscar dados a uma base de dados ou API ativa
def get_flight_times(departure: str, arrival: str) -> str:
voos = {
'NYC-LAX': {'partida': '08:00 AM', 'chegada': '11:30 AM', 'duração': '5h 30m'},
'LAX-NYC': {'partida': '02:00 PM', 'chegada': '10:30 PM', 'duração': '5h 30m'},
'LHR-JFK': {'partida': '10:00 AM', 'chegada': '01:00 PM', 'duração': '8h 00m'},
'JFK-LHR': {'partida': '09:00 PM', 'chegada': '09:00 AM', 'duração': '7h 00m'},
'CDG-DXB': {'partida': '11:00 AM', 'chegada': '08:00 PM', 'duração': '6h 00m'},
'DXB-CDG': {'partida': '03:00 AM', 'chegada': '07:30 AM', 'duração': '7h 30m'},
}
key = f'{departure}-{arrival}'.upper()
return json.dumps(flights.get(key, {'error': 'Flight not found'}))
# Procurar dados relacionados com a Inteligência Artificial numa base de dados vetorial
def search_data_in_vector_db(query: str) -> str:
vectores_consulta = embedding_fn.encode_queries([consulta])
res = client.search(
nome_da_colecção="demo_colecção",
data=query_vectors,
limit=2,
output_fields=["text", "subject"], # especifica os campos a devolver
)
print(res)
return json.dumps(res)
Dê as instruções para o LLM poder usar essas funções
Agora, vamos dar as instruções ao LLM para que ele possa usar as funções que definimos.
def run(model: str, question: str):
cliente = ollama.Client()
# Inicializar a conversa com uma pergunta do utilizador
mensagens = [{"role": "user", "content": question}]
# Primeira chamada à API: Enviar a consulta e a descrição da função para o modelo
resposta = cliente.chat(
model=model,
messages=messages,
tools=[
{
"type": "função",
"função": {
"nome": "get_flight_times",
"description": "Obter os tempos de voo entre duas cidades",
"parameters": {
"tipo": "objeto",
"propriedades": {
"partida": {
"tipo": "string",
"description": "A cidade de partida (código do aeroporto)",
},
"arrival" (chegada): {
"tipo": "string",
"description" (descrição): "A cidade de chegada (código do aeroporto)",
},
},
"required": ["departure", "arrival"],
},
},
},
{
"type": "function" (função),
"function": {
"nome": "search_data_in_vector_db",
"descrição": "Pesquisa sobre dados de Inteligência Artificial numa base de dados vetorial",
"parâmetros": {
"tipo": "objeto",
"propriedades": {
"consulta": {
"tipo": "string",
"descrição": "A consulta de pesquisa",
},
},
"required": ["query"],
},
},
},
],
)
# Adicionar a resposta do modelo ao histórico da conversação
messages.append(response["message"])
# Verificar se o modelo decidiu utilizar a função fornecida
if not response["message"].get("tool_calls"):
print("O modelo não utilizou a função. A sua resposta foi:")
print(resposta["mensagem"]["conteúdo"])
retornar
# Processar chamadas de função efectuadas pelo modelo
if response["message"].get("tool_calls"):
available_functions = {
"get_flight_times": get_flight_times,
"search_data_in_vector_db": search_data_in_vector_db,
}
para ferramenta em response["message"]["tool_calls"]:
function_to_call = available_functions[tool["function"]["name"]]
argumentos_da_função = ferramenta["função"]["argumentos"]
function_response = function_to_call(**function_args)
# Adicionar a resposta da função à conversação
mensagens.append(
{
"role": "ferramenta",
"content": function_response,
}
)
# Segunda chamada à API: Obter a resposta final do modelo
final_response = client.chat(model=model, messages=messages)
print(final_response["message"]["content"])
Exemplo de uso
Vamos verificar se podemos obter a hora de um voo específico:
question = "Qual é o tempo de voo de Nova Iorque (NYC) para Los Angeles (LAX)?"
run('llama3.2', pergunta)
O que resulta em:
O tempo de voo de Nova Iorque (JFK/LGA/EWR) para Los Angeles (LAX) é de aproximadamente 5 horas e 30 minutos. No entanto, note que este tempo pode variar consoante a companhia aérea, o horário do voo e eventuais escalas ou atrasos. É sempre melhor verificar com a sua companhia aérea para obter as informações de voo mais actualizadas e precisas.
Agora, vamos ver se o Llama 3.2 pode fazer uma busca vetorial usando o Milvus.
pergunta = "Quando foi fundada a Inteligência Artificial?"
run("llama3.2", pergunta)
Que retorna uma Pesquisa Milvus:
dados: ["[{'id': 0, 'distance': 0.5738513469696045, 'entity': {'text': 'A inteligência artificial foi fundada como disciplina académica em 1956.', 'subject': 'history'}}, {'id': 1, 'distance': 0.4090226888656616, 'entity': {'text': 'Alan Turing foi a primeira pessoa a efetuar investigação substancial em IA.', 'subject': 'history'}}]"]
A Inteligência Artificial foi fundada como disciplina académica em 1956.
Conclusão
Chamadas de funções com LLMs abrem um mundo de possibilidades. Ao integrar o Llama 3.2 com ferramentas externas como Milvus e APIs, é possível construir aplicações poderosas e sensíveis ao contexto que atendem a casos de uso específicos e problemas práticos.
Sinta-se à vontade para consultar Milvus, o código no Github e partilhar as suas experiências com a comunidade juntando-se ao nosso Discord

Continue lendo

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.