




Confluent
Real-time data ingestion for your RAG applications with Kafka
Utilizzate questa integrazione gratuitamenteZilliz x Confluent: Costruire applicazioni RAG in tempo reale senza allucinazioni
Kafka è una piattaforma open-source di streaming di dati in tempo reale e un broker di messaggi che consente alle applicazioni di pubblicare (scrivere) e sottoscrivere (leggere) flussi di dati in modo efficiente. Gli sviluppatori usano Kafka per costruire pipeline di dati scalabili e tolleranti ai guasti che possono alimentare database vettoriali per migliorare le applicazioni retrieval augmented generation (RAG). Confluent è un'azienda che fornisce soluzioni commerciali e strumenti costruiti attorno a Kafka per semplificarne l'uso nelle applicazioni event-driven e nelle architetture di streaming dei dati.
L'intelligenza artificiale generativa (LLM, modelli di diffusione, GAN, ecc.) è ampiamente applicabile in molti settori e verticali diversi. L'iniezione di dati di dominio in questi modelli tramite RAG sta diventando sempre più comune a livello applicativo: il framework CVP (ChatGPT, vector database, prompting) è un'istanziazione frequentemente utilizzata di RAG che sfrutta un database vettoriale per eseguire ricerche semantiche.
L'integrazione di Confluent sfrutta Zilliz Cloud (Hosted Milvus) e Confluent Kafka per eseguire l'ingestione, il parsing e l'elaborazione dei dati in tempo reale, al fine di ridurre l'allucinazione nei Large Language Models (LLM), fornendo informazioni aggiornate e contestualmente rilevanti che contribuiscono a migliorare l'esperienza dell'utente.
Esiste un gran numero di casi d'uso che possono trarre vantaggio da questa integrazione, come i chatbot, l'analisi del sentiment in tempo reale e l'assistenza clienti.
Oltre a GenAI, è possibile utilizzare questa integrazione per creare sistemi di raccomandazione in tempo reale, rilevare anomalie e sviluppare varie altre applicazioni che traggono vantaggio dall'IA in tempo reale.
Come funziona l'integrazione tra Confluent e Zilliz Cloud
Come funziona l'integrazione
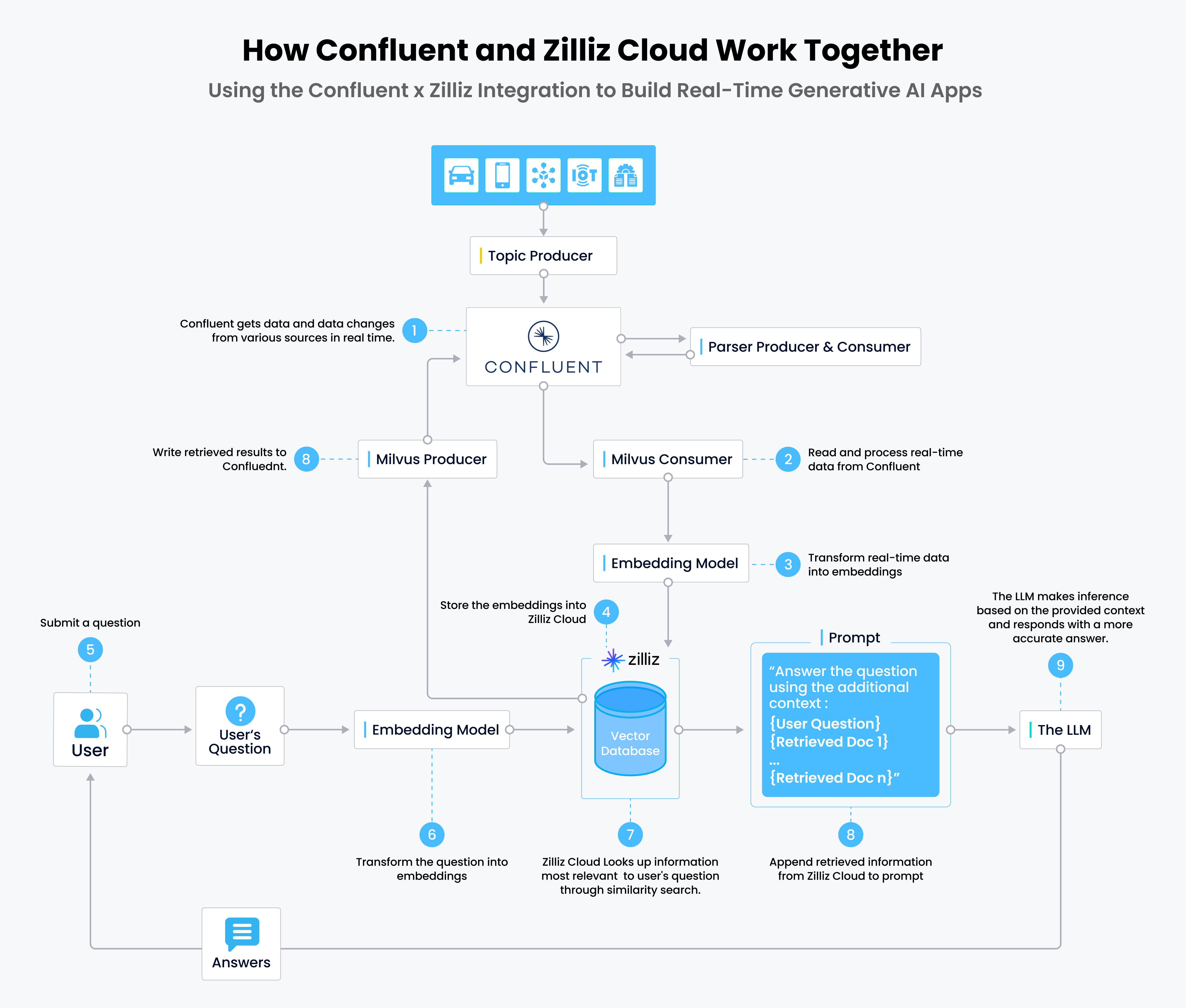
- I dati in tempo reale vengono scritti su Confluent tramite i produttori di argomenti; questi dati vengono analizzati e inviati nuovamente a Confluent.
- I consumatori Milvus leggono ed elaborano i dati in tempo reale da Confluent.
- I dati in tempo reale vengono convertiti in embeddings vettoriali tramite modelli di embedding.
- Gli embeddings vettoriali vengono memorizzati in Zilliz Cloud.
- Gli utenti inviano le loro domande al chatbot (o all'app RAG).
- La domanda viene trasformata in embeddings vettoriali per le query.
- Zilliz Cloud trova i primi k risultati più rilevanti per la domanda attraverso una ricerca di similarità.
- I risultati recuperati da Zilliz Cloud vengono aggiunti al prompt e inviati al LLM.
- L'LLM genera la risposta e la invia all'utente tramite il chatbot.
Imparare come
Date un'occhiata a queste esercitazioni per imparare a usare l'integrazione con Confluent.