




VIPSHOP costruisce un sistema di raccomandazione personalizzato 10 volte più veloce utilizzando Milvus

Velocità delle query 10 volte superiore
rispetto alla precedente soluzione Elasticsearch
Tempo di risposta <30 ms
per effettuare ricerche su milioni di vettori
Esperienza utente ottimizzata
con raccomandazioni più accurate basate sui comportamenti di acquisto degli utenti
Milvus-powered vector search has been running steadily in our recommendation systems, providing high performance and allowing us more flexibility in selecting models and algorithms.
VIPSHOP Search Service Team
Informazioni su VIPSHOP
VIPSHOP è un rinomato rivenditore online quotato al NYSE con sede in Cina, specializzato nell’offrire ai consumatori prodotti di marchi popolari con sconti significativi. La sua gamma diversificata di prodotti include moda, abbigliamento, accessori, prodotti di bellezza, articoli per la casa ed elettronica. Con un’impressionante base clienti di oltre 52 milioni e quasi 270 milioni di ordini gestiti ogni anno, VIPSHOP si è guadagnata il 115º posto nella prestigiosa classifica China 500 di Fortune.
Sfide: alta latenza e costi di manutenzione in aumento utilizzando Elasticsearch
Con la rapida crescita della sua attività, VIPSHOP ha affrontato un dilemma comune: man mano che il suo portafoglio prodotti si ampliava, aumentava anche la complessità nell’aiutare gli utenti a scoprire ciò che stavano cercando. Per affrontare questo problema, VIPSHOP ha creato un sistema di raccomandazione personalizzato basato sulle parole chiave delle query degli utenti e sui comportamenti di acquisto degli utenti.
In precedenza, il team di VIPSHOP utilizzava le funzionalità di Cosine Similarity(7.x) di Elasticsearch per alimentare il sistema di raccomandazione. Tuttavia, questo approccio era inefficiente per due motivi:
Alta latenza nella ricerca vettoriale: in media circa 300 ms per recuperare i risultati Top-K da milioni di vettori, con conseguenti tempi di risposta complessivi del sistema di diversi secondi.
Costi elevati di manutenzione degli indici Elasticsearch: i vettori derivati dai prodotti, dai comportamenti di acquisto dei consumatori e da tutti gli altri dati condividevano lo stesso insieme di indici, rendendo la costruzione, il funzionamento e la manutenzione degli indici molto più complicati.
VIPSHOP ha tentato di migliorare le prestazioni di Elasticsearch sviluppando un plugin di hashing sensibile alla località. Tuttavia, ha migliorato solo il throughput e non è riuscito a ridurre il tempo di ricerca vettoriale al di sotto di 100 ms. Pertanto, il team aveva ancora urgente bisogno di un nuovo stack di ricerca vettoriale per migliorare le prestazioni del proprio sistema.
La soluzione Milvus
Dopo un’ampia ricerca, il team di VIPSHOP ha scelto Milvus, un database vettoriale open-source in grado di gestire miliardi di embedding vettoriali e fornire risposte estremamente rapide. Milvus offre inoltre funzionalità avanzate come deployment distribuito, SDK multilingue e separazione lettura/scrittura, rendendolo una scelta superiore rispetto a Elasticsearch e a molte altre soluzioni di ricerca vettoriale come FAISS.
L’architettura del sistema di raccomandazione di VIPSHOP utilizzando Milvus
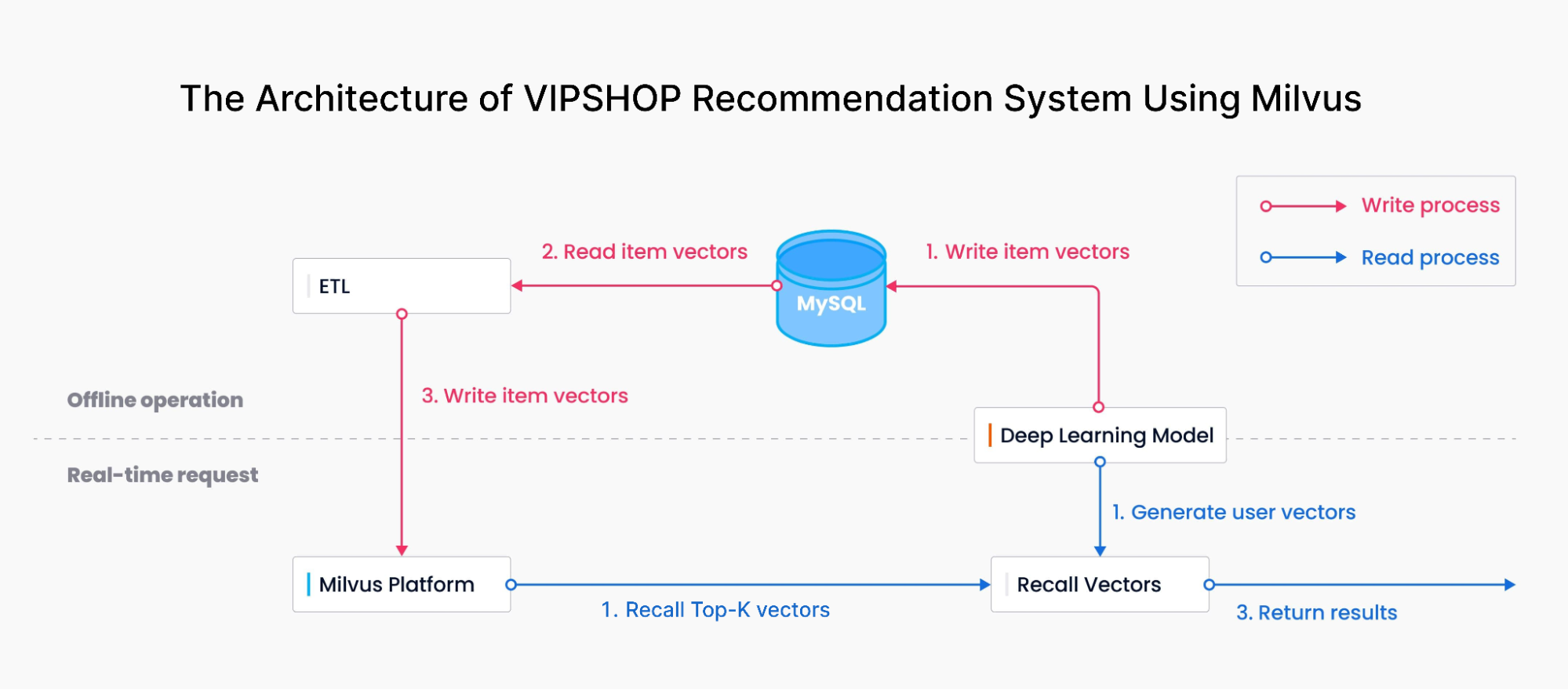
Il diagramma sopra mostra l’architettura del sistema di raccomandazione di VIPSHOP con Milvus. È composto da due parti principali:
Processo di scrittura: il team di VIPSHOP ha utilizzato un modello di deep learning per trasformare le caratteristiche di ciascun prodotto in embedding vettoriali e poi li ha importati in Milvus tramite MySQL e uno strumento ETL.
Processo di lettura: il team ha utilizzato il modello di deep learning per trasformare le query e i comportamenti di acquisto dei consumatori in vettori e poi ha recuperato risultati simili in Milvus. Milvus ha eseguito una ricerca di similarità e ha restituito ai consumatori i risultati Top-K più pertinenti.
Dettagli di implementazione di Milvus: aggiornamento dei dati e recall
L’aggiornamento dei dati e il recall sono i processi più essenziali per il sistema di raccomandazione basato su Milvus.
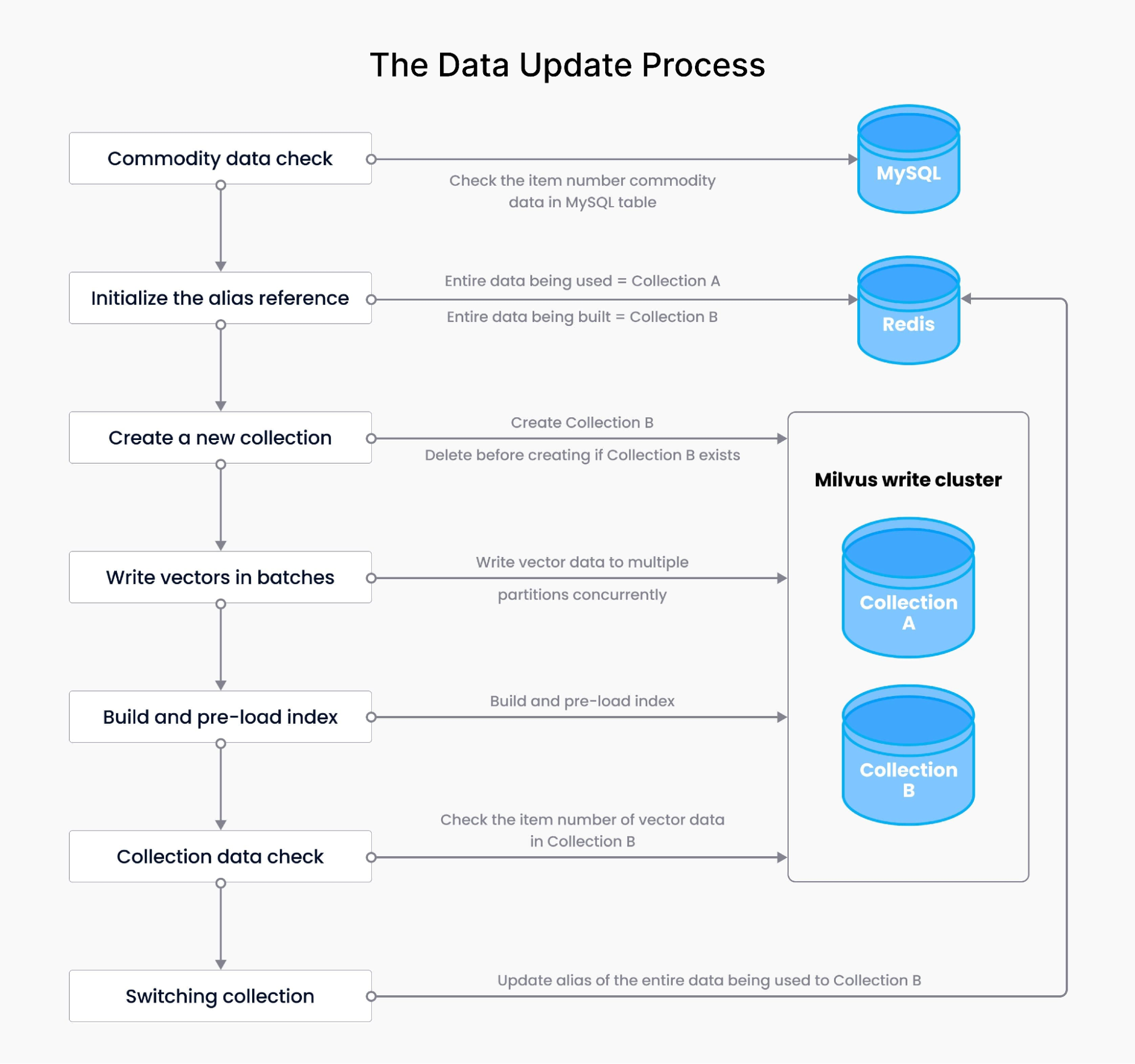
La procedura di aggiornamento dei dati garantisce la sincronizzazione dei dati, includendo attività come la scrittura dei dati vettoriali, il rilevamento dei volumi di dati vettoriali, la costruzione degli indici, il pre-caricamento degli indici e la gestione degli alias. Inizia con controlli sui dati delle commodity, assicurando che la quantità in MySQL sia allineata con i dati esistenti. Segue l’intero processo di costruzione dei dati, inclusa l’inizializzazione degli alias in Redis, la creazione di nuove collection, la scrittura dei vettori in batch e il pre-caricamento dell’indice in Milvus. Dopo aver verificato i dati della nuova collection, il sistema scambia senza interruzioni gli alias tra più collection di dati.
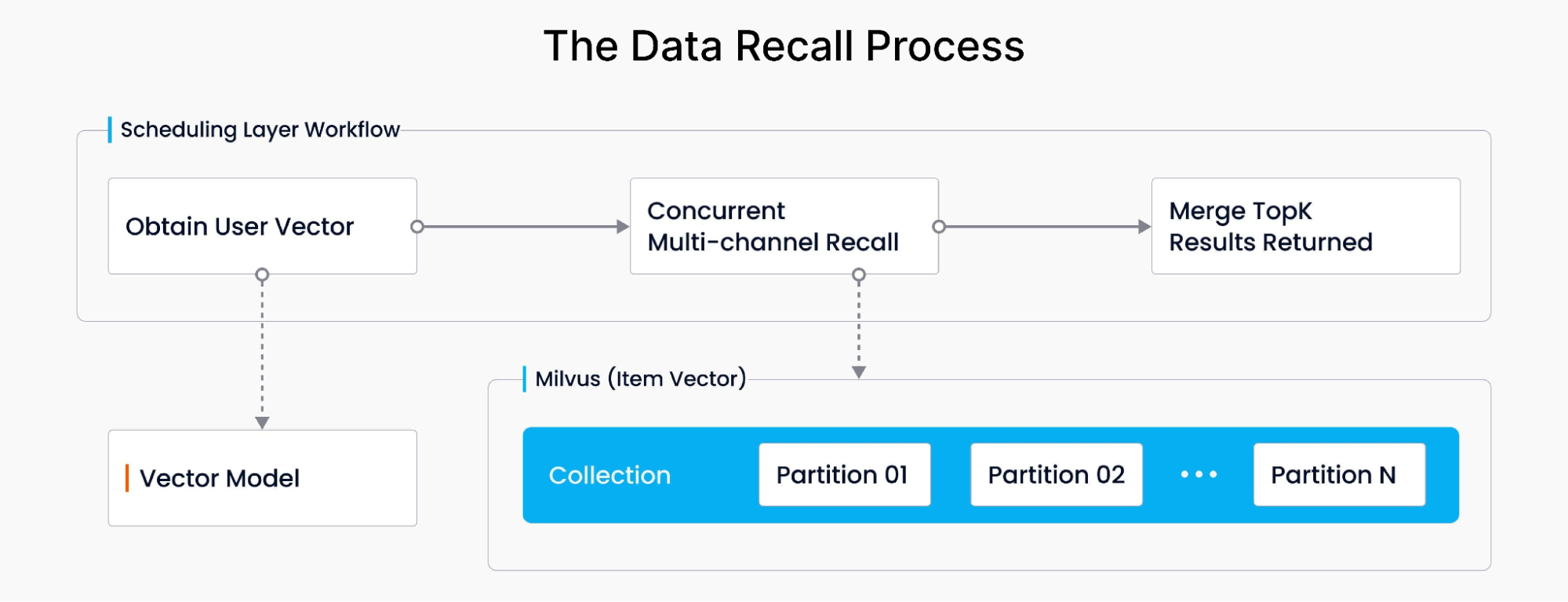
Il processo di recall, cruciale per raccomandare prodotti, prevede l'acquisizione di vettori relativi alle query e ai comportamenti di acquisto dei consumatori, il calcolo della loro distanza e l'unione dei risultati. Utilizzando Milvus, il sistema recupera dati in modo concorrente e asincrono in diverse partizioni Milvus, calcola le similarità vettoriali e classifica i migliori risultati in base alla distanza di similarità. Quindi, dopo più chiamate ai dati delle partizioni Milvus, presenta agli utenti i risultati finali delle raccomandazioni. Il flusso di lavoro complessivo è il seguente:
La seguente tabella mostra le prestazioni di tre servizi Milvus principali. Come mostrato nella tabella, la latenza media per il recall dei risultati Top-K è di circa 10 ms.
| Servizio | Ruolo | Parametri di input | Parametri di output | Latenza di risposta |
|---|---|---|---|---|
| Acquisizione vettori utente | Ottenere il vettore utente | info utente + query | vettore utente | 10 ms |
| Milvus Search | Calcolare la similarità vettoriale e restituire i risultati Top-K | vettore utente | vettore item | 10 ms |
| Logica di scheduling | Recall concorrente e unione dei risultati | Vettori item richiamati da più canali e punteggio di similarità | item Top-K | 10 ms |
Risultati: migliori prestazioni del sistema ed esperienza utente ottimale
L'adozione di Milvus nel sistema di raccomandazione di VIPSHOP ha migliorato significativamente le prestazioni complessive del sistema, tra cui:
Velocità delle query 10 volte più rapida
Utilizzando Milvus, il tempo di query e risposta del sistema è stato ridotto a meno di 30 ms, 10 volte più rapido rispetto alla precedente soluzione Elasticsearch.
Scalabilità del sistema migliorata
Il deployment distribuito di Milvus e il supporto per lo scaling orizzontale consentono al sistema di raccomandazione di gestire senza sforzo volumi di dati e query degli utenti in rapido aumento senza compromettere le prestazioni.
Esperienza utente migliorata
Milvus ottimizza il processo di raccomandazione per fornire suggerimenti di prodotto personalizzati in base alle preferenze degli utenti e all'intento di ricerca, migliorando la soddisfazione e il coinvolgimento degli utenti.
Costi di manutenzione ridotti
Milvus gestisce in modo efficiente i dati vettoriali e semplifica i meccanismi di query, riducendo i costi complessivi di manutenzione per il sistema di raccomandazione.
Lezioni apprese e pratiche consigliate
Nel loro percorso con Milvus, il team VIPSHOP ha imparato alcune lezioni e acquisito diversi insight cruciali per prestazioni di sistema ed esperienza utente ottimali:
In situazioni in cui le operazioni di lettura hanno la precedenza, l'adozione di una strategia di deployment con separazione lettura-scrittura può migliorare le prestazioni complessive del sistema.
Il client Java di Milvus non dispone di un meccanismo di riconnessione integrato a causa della sua residenza in memoria nel servizio di recall. Il team VIPSHOP ha creato il proprio pool di connessioni per garantire una connettività costante tra il client Java e il server tramite un test heartbeat.
In Milvus si verificano occasionalmente query lente a causa dell'insufficiente warm-up delle nuove collection. Per affrontare questo problema, il team VIPSHOP ha simulato query sulla nuova collection.
Per trovare il giusto equilibrio tra prestazioni di recupero e accuratezza, il team VIPSHOP consiglia di condurre rigorosi esperimenti di stress test adattati al proprio specifico scenario aziendale e di impostare un valore soglia ragionevole per ottimizzare questi parametri.
Negli scenari che coinvolgono dati statici, è più efficiente importare prima tutti i dati nella collection e creare gli indici successivamente.