




Come una piattaforma GPU e AI leader a livello globale utilizza Milvus per scalare il data mining multimodale per il suo sistema di guida autonoma

-30% Costo
Impronta di memoria e archiviazione ridotta grazie a chiavi primarie basate su disco e a un layout dei segmenti ottimizzato in Milvus 2.5.
Scala 10×
Margine comprovato per scalare di un ulteriore ordine di grandezza senza riprogettazione o sorprese sui costi.y senza modifiche architetturali o costi imprevisti.
Affidabilità aziendale
Produzione continua su vasta scala senza incidenti importanti.
Ricerca ibrida
Ricerca vettoriale unificata e filtro dei metadati per supportare query complesse.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
Informazioni sull’azienda
Il cliente è un leader globale nel calcolo accelerato e nell’intelligenza artificiale, con decenni di esperienza nella creazione di GPU e piattaforme software utilizzate in gaming, robotica, data center e applicazioni automotive. Una delle sue iniziative di punta è una piattaforma end-to-end per sistemi avanzati di assistenza alla guida e guida autonoma. Questa piattaforma supporta l’intero ciclo di vita dello sviluppo della guida autonoma: dalla raccolta di dati su larga scala e dall’addestramento di modelli di IA all’inferenza a bordo veicolo e al processo decisionale in tempo reale.
Alla base di questa piattaforma c’è l’organizzazione Autonomous Vehicle (AV) Data Engineering dell’azienda, responsabile dell’infrastruttura dati che alimenta la sua tecnologia di guida autonoma. Ogni ora di guida nel mondo reale produce terabyte di dati multimodali dei sensori, inclusi flussi di telecamere sincronizzati, nuvole di punti LiDAR, misurazioni radar, dati di localizzazione ad alta precisione e metadati dettagliati sullo stato del veicolo. La missione del team è rendere questo dataset enorme e in costante crescita ricercabile, individuabile e utilizzabile operativamente da centinaia di ingegneri che devono far emergere scenari long-tail, identificare rari casi limite e validare il comportamento dei modelli in condizioni reali.
Per soddisfare questi requisiti, il team ha creato un sistema di data mining multimodale capace di cercare tra decine di miliardi di punti dati di sensori indicizzati raccolti da flotte di test. Il sistema converte i dati grezzi dei sensori in embedding vettoriali, così gli ingegneri possono eseguire query approfondite e sensibili al contesto, ad esempio: “veicoli che si immettono da destra sotto pioggia intensa”, “pedoni che attraversano al crepuscolo in incroci non segnalati” o “rotatorie a due corsie con visibilità occlusa”.
Il sistema inizialmente funzionava su FAISS, ma con l’aumentare del volume dei dati e delle esigenze operative, il team è migrato a Milvus per ottenere maggiore scalabilità, minore impegno di manutenzione e una più solida affidabilità in produzione. Milvus ha offerto un percorso chiaro per supportare un ordine di grandezza in più di dati, ridurre l’overhead operativo e migliorare l’efficienza di clustering, indicizzazione e archiviazione mentre la flotta di guida autonoma continuava a espandersi.
La sfida: FAISS non riusciva a scalare
Il collo di bottiglia nella gestione dei dati
La progettazione iniziale di questo sistema di data mining era intenzionalmente semplice. Ogni sessione di guida autonoma, in genere un viaggio di un’ora, veniva elaborata in frame, trasformata in embedding vettoriali tramite i modelli proprietari dell’azienda e raggruppata in file indice FAISS, di solito uno al giorno.
Sebbene quella struttura funzionasse bene all’inizio, non era scalabile. Con l’esplosione del dataset, aumentò anche il numero di file indice, arrivando infine a centinaia di migliaia. Ciascuno rappresentava una piccola sacca di informazioni isolata. Cercare attraverso di essi introduceva una complessità significativa: gli indici giornalieri spesso contenevano dati sovrapposti, richiedendo una logica intricata per filtrare e unire i metadati. In pratica, questo significava che, mentre la ricerca all’interno di un singolo giorno funzionava bene, la maggior parte degli utenti voleva interrogare condizioni più ampie, come scenari di guida specifici distribuiti su più giorni o regioni. Quelle ricerche dovevano accedere a molti file indice separati contemporaneamente, il che era computazionalmente costoso. Gli ingegneri spesso dovevano restringere manualmente l’ambito, ipotizzando quali file potessero contenere i dati rilevanti prima di eseguire una query. Questo lavoro di supposizione rendeva il processo di ricerca lento e inaffidabile.
Il divario di flessibilità
FAISS non è un database: è una libreria. Va bene per trovare i vicini più prossimi per un dato vettore, ma i sistemi di ricerca di livello production richiedono molto più della sola corrispondenza rapida per similarità.
In pratica, gli ingegneri non volevano cercare nell’intero corpus in una sola volta. Avevano bisogno di un filtraggio contestuale: trovare, ad esempio, “frame della fotocamera frontale acquisiti con pioggia leggera su strade urbane” o “percorsi notturni su autostrade della California.” Raggiungere quel livello di precisione richiedeva di combinare la ricerca vettoriale con filtri sui metadati come tipo di fotocamera, ora, posizione, meteo e versione del modello. Ma FAISS non offriva queste capacità pronte all’uso. Per colmare il divario, il team ha dovuto costruire uno stack complesso di logica personalizzata: database di metadati separati, pianificatori di query su misura per decidere quali indici FAISS analizzare e post-filtraggio manuale dei risultati dopo il recupero.
Nel tempo, queste personalizzazioni hanno creato un importante problema di scalabilità. Diverse angolazioni delle fotocamere, molteplici modelli di embedding e pipeline di preprocessing versionate richiedevano tutte strategie di gestione distinte. Non esisteva un concetto integrato di collection, partition o raggruppamento logico dei dati: solo file di indice. Ogni livello di organizzazione, dal versionamento dei dati al filtraggio delle query, doveva essere scritto e mantenuto in codice personalizzato. Il sistema funzionava, ma a costo di flessibilità, manutenibilità e scalabilità a lungo termine.
Il problema della scalabilità
Il sistema era già sotto pressione con miliardi di vettori, e i veicoli di test dell’azienda generavano nuovi dati ogni giorno. Nel frattempo, i team di ricerca introducevano nuovi modelli di embedding, ciascuno dei quali richiedeva una reindicizzazione su larga scala dei dati storici. Era solo questione di tempo prima che i carichi di lavoro crescessero di dieci volte, ma la configurazione FAISS basata su file non aveva alcun modo pratico per scalare a quel livello.
Peggio ancora, ogni nuovo dataset significava più file di indice e più aggiornamenti manuali allo storage dei metadati. Non c’era sharding automatico, nessun bilanciamento del carico integrato e nessun modo per aggiungere capacità on demand. L’architettura era diventata antiquata —statica, laboriosa e resistente alla crescita.
I costi ingegneristici nascosti
Oltre ai costi del cloud, la sfida più grande era l’overhead ingegneristico nascosto legato alla manutenzione di FAISS. Gli ingegneri dovevano gestire sistemi di metadati complessi, progettare logiche personalizzate per distribuire i dati e aggiornare manualmente milioni di file di indice. Nel tempo, questo overhead ha rallentato l’innovazione: le prestazioni di ricerca sono peggiorate, i cicli di sviluppo si sono allungati e le nuove idee non sono mai andate oltre la lavagna. Con la continua crescita dei volumi di dati, il sistema è diventato sempre più rigido e fragile. Era chiaro che tentare di aggiornare la configurazione legacy non era più sostenibile.
La soluzione: riprogettare per la scalabilità con Milvus
Per superare queste sfide, il team AV Data aveva bisogno di un sistema capace di gestire decine di miliardi di vettori oggi, con un percorso chiaro verso una crescita di 10× e oltre. Doveva offrire un filtraggio robusto, semplicità operativa e, soprattutto, affidabilità in produzione con manutenzione minima.
Il processo di valutazione
Invece di eseguire un ampio confronto tra ogni database vettoriale emergente, il team si è concentrato sul popolare Milvus Vector Database, eseguendo una proof of concept con 400–500 milioni di vettori, abbastanza grande da esporre colli di bottiglia reali. Durante i test, gli ingegneri hanno replicato l’intero workflow dei dati: indicizzazione di dataset con diversi tipi di indice per confrontare i trade-off, misurazione del tempo di indicizzazione per stimare gli aggiornamenti batch giornalieri e benchmarking della latenza con combinazioni di filtri e pattern di query realistici. Hanno deliberatamente spinto Milvus ai suoi limiti, eseguendo ricerche complesse multi-condizione e scalando i volumi di dati per testarne la stabilità.
Perché Milvus?
I risultati della proof of concept hanno reso Milvus la scelta chiara per il team AV Data.
Prestazioni di query accettabili: Milvus ha fornito costantemente latenze di query nell’ordine dei secondi anche per le ricerche più complesse e ricche di filtri, pienamente entro i requisiti per i carichi di lavoro interni di data mining.
Filtraggio nativo e flessibilità delle query: Gli ingegneri potevano ora combinare la ricerca per similarità vettoriale con filtri sui metadati in un’unica query—funzionalità che in precedenza richiedevano molto codice personalizzato in FAISS.
Struttura dei dati organizzata: Gli embedding vettoriali provenienti da modelli diversi venivano archiviati in raccolte separate, ciascuna partizionata in base ad attributi come la data di acquisizione o la regione. Milvus gestiva automaticamente la distribuzione dei dati tra i segmenti, eliminando l’onere della gestione manuale dei file.
Scalabilità senza interruzioni: Con la crescita dei dati, il team ha aggiunto più nodi per espandere la capacità. L’architettura distribuita di Milvus scalava linearmente senza richiedere riprogettazioni del sistema.
Comunità open-source attiva: Durante i test, gli ingegneri AV Data hanno ricevuto supporto rapido e pratico dal team Milvus e dai contributori della community, rafforzando la fiducia in Milvus come ecosistema affidabile e pronto per la produzione.
Implementazione della nuova architettura con Milvus
Al suo cuore, l’architettura di questo sistema di data mining multimodale è semplice, ma eseguirla su scala massiccia richiede ingegneria accurata e precisione. I dati video grezzi provenienti dai percorsi dei veicoli autonomi—ore di riprese continue da più telecamere—confluiscono in una pipeline di elaborazione che estrae singoli frame o brevi clip, in genere della durata di pochi secondi.
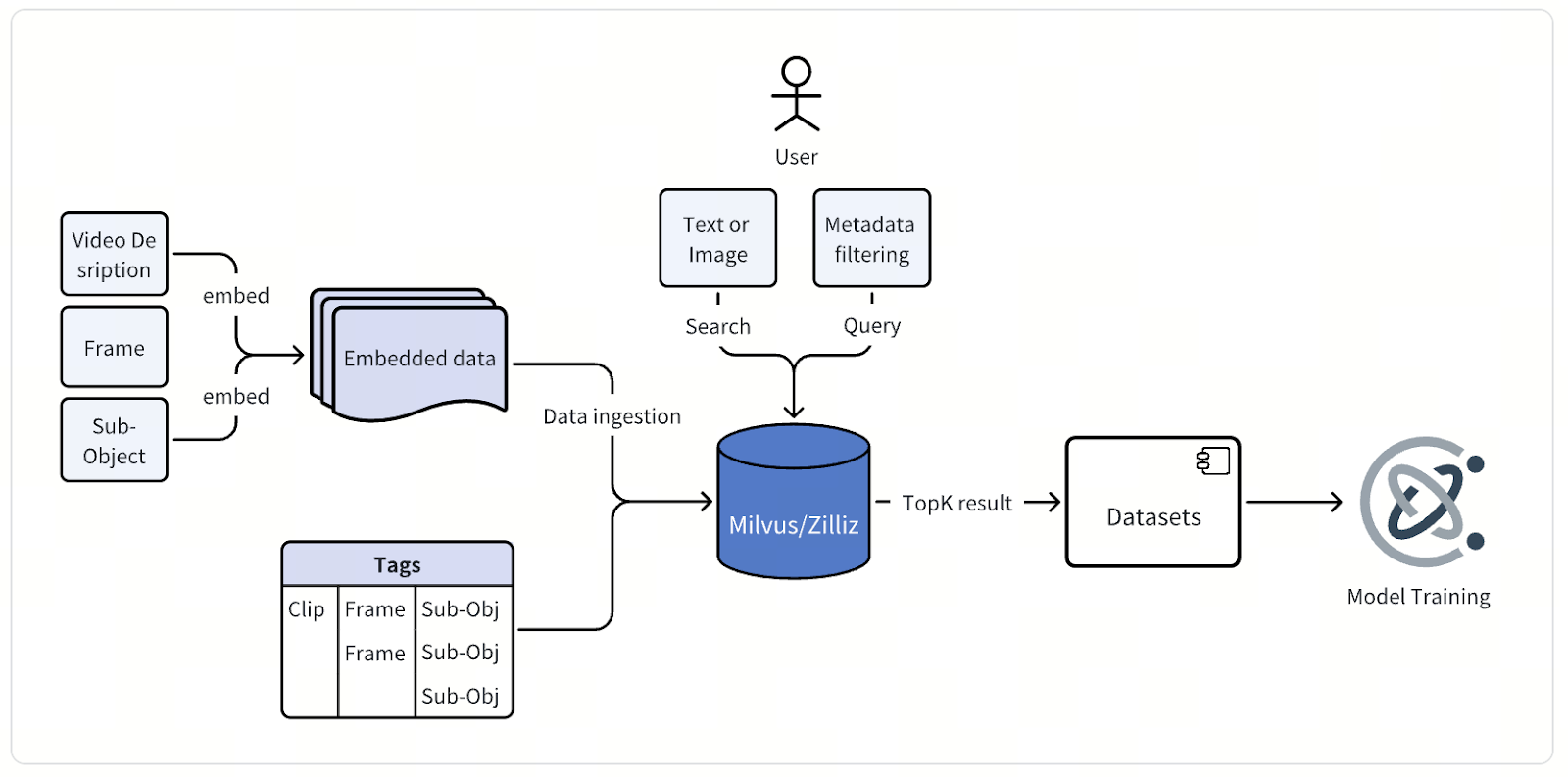
Ogni frame o clip passa quindi attraverso i modelli di embedding proprietari dell’azienda, progettati appositamente per la guida autonoma. Per i dati immagine, il team utilizza modelli derivati dall’architettura CLIP, personalizzati e perfezionati per cogliere la semantica specifica della strada. Per i dati video, si affida ai propri modelli sviluppati internamente, una famiglia di foundation model per applicazioni di IA fisica. Insieme, questi modelli convertono i dati visivi in embedding vettoriali ad alta dimensionalità che codificano un ricco significato contestuale.
Una volta generati, questi embedding vettoriali—insieme a metadati dettagliati—vengono archiviati e indicizzati nel Milvus Vector Database. Ogni punto dati contiene attributi che descrivono, tra gli altri, la sessione di guida, la posizione della telecamera, il timestamp, lo stato del veicolo, la posizione e le condizioni meteorologiche. Anche questi metadati vengono indicizzati per abilitare ricerche filtrate rapide e precise su dataset enormi.
Attraverso un’interfaccia di query unificata, gli ingegneri possono cercare nei dati in più modi. Possono digitare una descrizione testuale, caricare un’immagine o un video di riferimento, oppure combinare la ricerca vettoriale con filtri sui metadati per individuare esattamente ciò di cui hanno bisogno. Una singola query potrebbe richiedere, ad esempio, “incroci urbani di notte con pedoni che attraversano”, e Milvus restituisce i frame o le clip più rilevanti per la revisione, l’analisi e il miglioramento dei modelli.
I vantaggi: efficienza dei costi, stabilità e scalabilità
Dopo più di un anno di funzionamento continuo, Milvus si è dimostrato non solo tecnicamente solido, ma anche trasformativo dal punto di vista operativo. I seguenti risultati mostrano come la sua architettura e il suo ecosistema si siano tradotti in efficienza reale su larga scala.
Operazioni più semplici, meno grattacapi e sviluppo più rapido
La migrazione da centinaia di migliaia di file FAISS a Milvus ha eliminato un intero livello di sovraccarico operativo. Non c’è più gestione manuale dei file di indice, né script ad hoc, né logica di query personalizzata. La distribuzione dei dati, la gestione dei segmenti e l’instradamento delle query avvengono ora automaticamente. Gli aggiornamenti sono semplici, il monitoraggio è unificato e le metriche raccontano una storia chiara. Il risultato è meno tempo dedicato alla manutenzione dei sistemi e più tempo impiegato nel data mining per ottenere insight.
Minore sovraccarico ingegneristico più un’ulteriore riduzione dei costi del 30% dopo l’aggiornamento a Milvus 2.5
L’adozione di Milvus ha ridotto immediatamente sia i costi infrastrutturali sia quelli di engineering. Il passaggio dal sistema basato su file di FAISS ha eliminato la gestione manuale dei file e il complesso tracciamento dei metadati, facendo risparmiare molto tempo agli sviluppatori e notevole impegno operativo. L’aggiornamento da Milvus 2.4 a Milvus 2.5 ha poi prodotto un’ulteriore riduzione del 30% dei costi infrastrutturali, grazie a una mappatura della memoria più intelligente, all’archiviazione su disco delle chiavi primarie e a una gestione più efficiente dei segmenti.
Nel complesso, questi miglioramenti consentono al team AV Data di eseguire gli stessi workload su istanze AWS più piccole — oppure di indicizzare molti più dati — senza aumentare la spesa o l’overhead di manutenzione. Incoraggiato da questi risultati, il team prevede di testare Milvus 2.6, che introduce nuovi tipi di indice come RaBitQ e ulteriori ottimizzazioni che dovrebbero spingere ancora oltre sia le prestazioni sia l’efficienza dei costi. Per i grandi workload batch offline, la velocità di costruzione degli indici rimane una sfida fondamentale. Grazie ai contributi del team NVIDIA cuVS, Milvus ora supporta la costruzione di indici accelerata da GPU con serving basato su CPU (GPU-build, CPU-serve). Questo approccio accelera significativamente la costruzione degli indici mantenendo l’efficienza dei costi — e ci si aspetta che rafforzi ulteriormente il vantaggio prezzo-prestazioni di Milvus nei workload di guida autonoma.
Scalabilità integrata, dimostrata nella pratica
La piattaforma ora indicizza decine di miliardi di vettori e acquisisce nuovi dati quotidianamente senza attriti. La modellazione interna conferma che può scalare di un ulteriore 10× senza riprogettazioni o sorprese sui costi, trasformando ciò che un tempo era un vincolo di capacità in un vantaggio strategico a lungo termine. Con questo margine, il team può passare dall’indicizzare due anni di dati di guida recenti a coprire l’intero archivio storico, abilitando la ricerca in ogni sessione di guida mai registrata. Può anche eseguire più modelli di embedding in parallelo per ottimizzare il recupero per diversi tipi di query e persino conservare i dati a tempo indeterminato invece di eliminarli con il passare del tempo. Qui la scalabilità significa non solo gestire più dati, ma abilitare l’apprendimento continuo e progressi più rapidi verso una guida autonoma più sicura.
Affidabilità enterprise su scala massiva
In oltre un anno di produzione ininterrotta, Milvus ha gestito silenziosamente decine di miliardi di vettori con ingestione e query quotidiane, senza un singolo incidente grave. Il sistema funziona stabilmente in background, richiedendo una supervisione minima. Nessun outage nel weekend, nessuna patch d’emergenza: solo prestazioni costanti e prevedibili. Questo tipo di affidabilità su questa scala si traduce in minori rischi operativi, meno interventi urgenti e più attenzione alla creazione di valore anziché alla gestione dell’infrastruttura.
Ricerca più ricca, workflow più intelligenti
Milvus combina la ricerca vettoriale con il filtraggio dei metadati, offrendo agli ingegneri dell’azienda nuovi modi per analizzare dati di guida complessi. Possono, ad esempio, trovare tutte le immagini di zone di cantiere acquisite da telecamere frontali alla luce del giorno o filtrare per ora e posizione per confrontare il comportamento del modello tra aggiornamenti e regioni. Raccolte diverse contengono embedding di modelli diversi, consentendo ai team di testare nuove architetture senza impattare la produzione. Queste capacità accelerano la sperimentazione e fanno emergere insight che in precedenza richiedevano un’ampia ingegnerizzazione personalizzata.
Una community solida che moltiplica l’impatto
Oltre alla tecnologia, la community open-source di Milvus è stata una parte fondamentale del successo dell’azienda. Durante i test e il deployment, gli ingegneri hanno ricevuto supporto rapido direttamente dai contributori e dai maintainer di Milvus. Questa reattività ha ridotto i tempi di inattività, accelerato il debugging e mantenuto i progressi sulla giusta traiettoria. Nel tempo, la community attiva ha continuato ad aggiungere valore aiutando a validare nuove idee, rendere più fluidi gli aggiornamenti e condividere le best practice. Per questo cliente, Milvus non è solo un software affidabile: è un ecosistema collaborativo che rafforza la piattaforma e offre efficienza a lungo termine.
Lezioni dalla produzione
Scegliere l’indice giusto: bilanciare scala, costo e accuratezza
Scegliere un indice è una delle decisioni pratiche più importanti quando si costruisce un sistema di ricerca vettoriale. Milvus supporta molti tipi di indice, ciascuno con i propri compromessi in termini di velocità, uso della memoria e accuratezza. Per il team AV Data, l’obiettivo era trovare un equilibrio tra scala dei dati, costo dell’infrastruttura e accuratezza della ricerca, non semplicemente scegliere l’opzione più veloce.
Dopo aver testato diverse configurazioni, hanno selezionato IVF_FLAT, che raggruppa i vettori in cluster ed esegue una ricerca esatta all’interno di quelli rilevanti. Non è l’opzione più rapida o più compatta, ma per decine di miliardi di vettori e requisiti di latenza moderati, ha offerto il giusto mix di prestazioni e accuratezza rimanendo efficiente.
Il team ha scoperto che, una volta che un indice si adatta bene al workload, raramente c’è bisogno di passare a qualcosa di più nuovo. In pratica, un indice ben abbinato fa risparmiare più tempo e risorse rispetto all’inseguire piccoli guadagni di prestazioni. Per sistemi su larga scala, prestazioni stabili e prevedibili sono ciò che mantiene fluide le operazioni.
Memory Mapping: scambiare latenza con costo su larga scala
Una delle scelte tecniche più efficaci del team è stata l’uso del memory mapping (Mmap) per controllare i costi dell’infrastruttura. Nelle configurazioni tradizionali, mantenere tutti i dati vettoriali in RAM richiederebbe istanze enormi e ad alto costo. Con il memory mapping in Milvus, la maggior parte dei dati rimane su disco mentre il sistema operativo mantiene automaticamente in memoria le porzioni a cui si accede di frequente. Questo design introduce una certa latenza—le letture da disco sono più lente della RAM—ma mantiene prestazioni prevedibili e un uso efficiente delle risorse. Per il workload dell’azienda, quel compromesso aveva perfettamente senso. I loro utenti sono ingegneri che eseguono query analitiche, non utenti finali che si aspettano risposte istantanee, e la concorrenza rimane bassa.
Operazioni di eliminazione: quando piccole assunzioni si rompono su larga scala
Una delle lezioni più importanti del team è arrivata da qualcosa che sembrava semplice: eliminare dati. Nell’architettura append-only di Milvus, i vettori eliminati non vengono rimossi subito: vengono contrassegnati per l’eliminazione e ripuliti successivamente tramite compattazione in background. Durante i test, l’eliminazione di milioni di vettori ha inaspettatamente innescato la reindicizzazione di miliardi, poiché i filtri di Bloom hanno prodotto falsi positivi su migliaia di segmenti. Quella che sembrava una pulizia di routine ha finito per sovraccaricare i nodi dati e bloccare i job.
La soluzione è arrivata comprendendo come Milvus gestisce i dati e adattando il loro workflow: ottimizzando i filtri di Bloom, usando chiavi di partizione per mirare con precisione alle eliminazioni e passando al caricamento bulk solo in inserimento. Il punto chiave: su larga scala, anche operazioni semplici possono comportarsi diversamente, e comprendere gli interni del sistema è fondamentale per mantenere le prestazioni prevedibili.
Guardando al futuro
Il team si sta preparando ad adottare Milvus 2.6 poco dopo il rilascio, fiducioso che nuovi tipi di indice e ottimizzazioni architetturali offriranno un altro salto in efficienza. Le prime discussioni con il team di ingegneria di Milvus indicano continue riduzioni dei costi e un migliore utilizzo delle risorse, che l’azienda prevede di validare tramite benchmark su scala completa.
Guardando più avanti, il team vede interessanti opportunità per espandere le funzionalità e scalare. Funzionalità come la ricerca ibrida, che combina query testuali e vettoriali, potrebbero sbloccare nuovi modi per esplorare dati multimodali, mentre filtri avanzati in stile database semplificheranno workflow complessi. Anche l’imminente release Milvus 3.0 è promettente per architetture a livelli, consentendo all’azienda di mantenere un accesso rapido ai dati recenti archiviando al contempo in modo efficiente l’intero archivio storico. Nel complesso, questi progressi offriranno all’azienda una piattaforma dati che scala senza sforzo, supporta capacità di ricerca più approfondite e cresce in modo più efficiente.
Inoltre, l’introduzione e la maturazione delle creazioni di indici accelerate da GPU e basate su NVIDIA cuVS con serving basato su CPU (GPU-build, CPU-serve) in Milvus dovrebbero offrire un miglioramento sostanziale delle prestazioni di indicizzazione offline. Sfruttando le GPU NVIDIA e le librerie cuVS altamente ottimizzate, Milvus può creare indici vettoriali su larga scala in modo drasticamente più rapido rispetto alle pipeline basate solo su CPU, continuando al contempo a servire le query in modo economicamente efficiente su CPU. Questo riduce significativamente il tempo tra dati e query, consente cicli di aggiornamento degli indici più frequenti e amplifica ulteriormente il vantaggio prezzo-prestazioni di Milvus per la guida autonoma e altri workload multimodali su larga scala in cui iterazione rapida e dati aggiornati sono fondamentali.
Conclusione
Il team AV Data del cliente ha costruito una potente piattaforma di data mining che accelera lo sviluppo della guida autonoma rendendo enormi volumi di dati multimodali ricercabili e utilizzabili. La migrazione da FAISS a Milvus ha risolto sfide critiche in termini di scalabilità, flessibilità e complessità operativa, offrendo al contempo risparmi sui costi misurabili e una notevole stabilità in produzione.
Dopo oltre un anno di funzionamento continuo e decine di miliardi di vettori indicizzati, la piattaforma ha dimostrato che Milvus può fungere da base di livello production per la ricerca vettoriale su larga scala e specifica per dominio. Il sistema ingerisce nuovi dati quotidianamente, supporta gli ingegneri nei programmi di guida autonoma dell’azienda e offre un percorso chiaro per scalare ulteriormente di 10× senza riprogettazione dell’architettura.
Per le organizzazioni che costruiscono sistemi di ricerca vettoriale con una scala di dati massiva, l’efficienza dei costi è importante e la stabilità prevale sulla latenza inferiore al millisecondo. L’esperienza dell’azienda è istruttiva. Milvus dimostra che un database vettoriale open-source può non solo soddisfare le esigenze della produzione, ma continuare a migliorare nel tempo, offrendo una dorsale affidabile, scalabile e pronta per il futuro per infrastrutture AI nel mondo reale.
- Informazioni sull’azienda
- La sfida: FAISS non riusciva a scalare
- La soluzione: riprogettare per la scalabilità con Milvus
- I vantaggi: efficienza dei costi, stabilità e scalabilità
- Lezioni dalla produzione
- Guardando al futuro
- Conclusione
Contenuto
Settore
Settore automobilistico
Tecnologie Utilizzate