




Ottimizzazione dell'IA conversazionale in FARFETCH

15x
tempo di indicizzazione più veloce
5x
tempo di interrogazione più veloce
Conversione potenziata
attraverso raccomandazioni di prodotti più pertinenti
Più tipi di metriche
per supportare diversi casi d'uso
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
Informazioni su FARFETCH
FARFETCH, leader nella vendita al dettaglio di moda online, sta spingendo i confini dello shopping digitale con la sua ultima innovazione, iFetch. Questo sistema di intelligenza artificiale conversazionale è stato progettato per portare nel mondo digitale il servizio personalizzato e di alto livello tipico dei negozi fisici di lusso. Nell'ambito di questa iniziativa, FARFETCH Chat R&D sta sviluppando un sistema di raccomandazione conversazionale specializzato. Questo chatbot, integrato in iFetch, consente agli utenti di interagire con il catalogo dei prodotti FARFETCH attraverso il linguaggio naturale e le immagini. Ad esempio, un utente può caricare la foto di una giacca che gli piace e il chatbot risponderà con una selezione curata di giacche simili. Combinando senza soluzione di continuità tecnologie AI avanzate con un'attenzione particolare all'esperienza dell'utente, FARFETCH mira a ridefinire ciò che i clienti possono aspettarsi dallo shopping online.
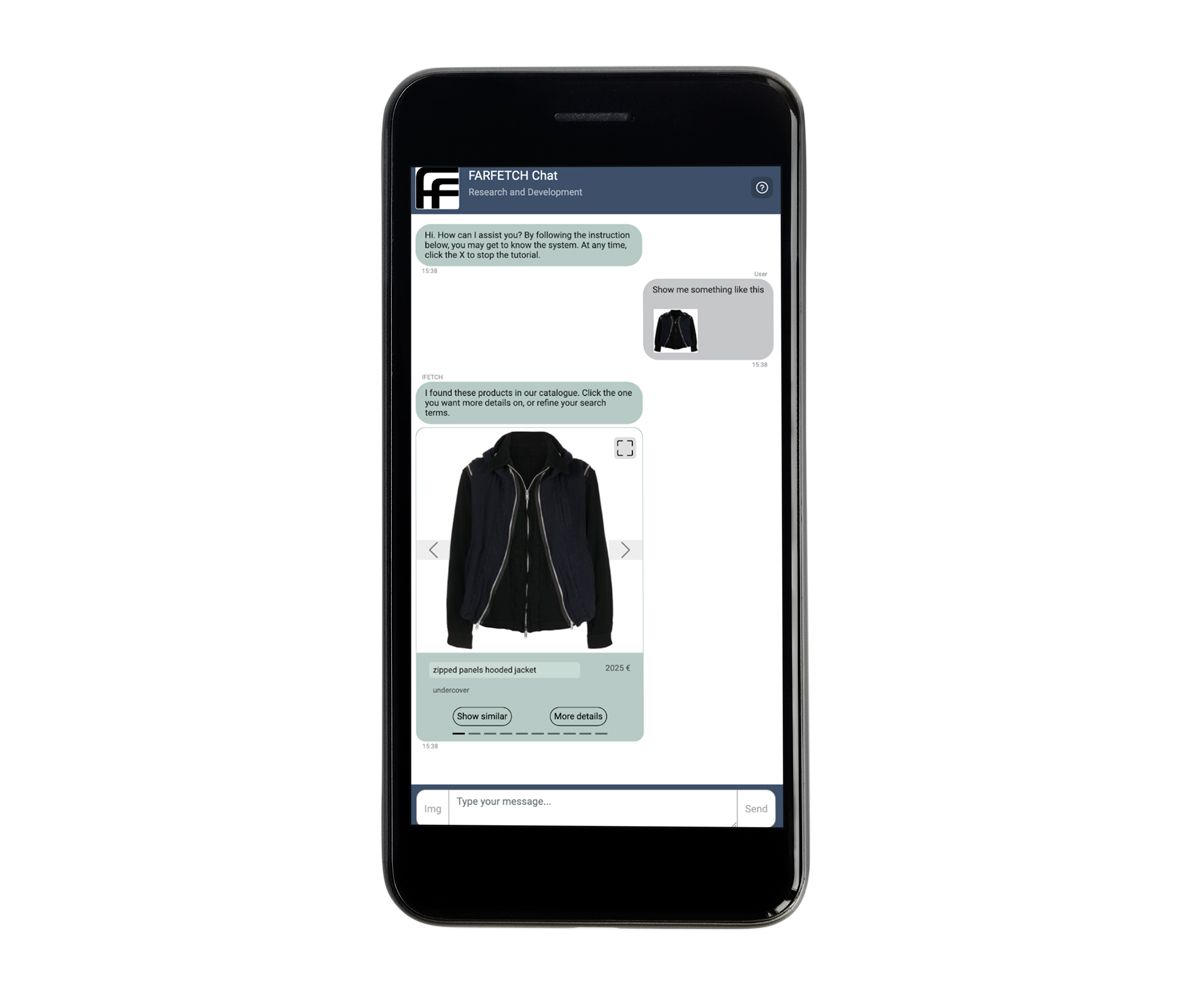 FARFETCH Chat mostra una vetrina simile
FARFETCH Chat mostra una vetrina simile
Tuttavia, hanno incontrato una sfida significativa: con i loro metadati limitati, i cataloghi di prodotti tradizionali faticavano a catturare le relazioni intricate e gli attributi sfumati della loro vasta gamma di prodotti. Per affrontare questo problema, hanno utilizzato algoritmi di apprendimento automatico per sviluppare embeddings di prodotti, punti di dati ad alta densità che servono come linguaggio robusto per il loro sistema di intelligenza artificiale. Ciò consente al chatbot di comprendere e consigliare i prodotti con una precisione senza precedenti. Tuttavia, l'archiviazione e il recupero di questi embeddings in tempo reale ha rappresentato un altro ostacolo, richiedendo una soluzione di archiviazione specializzata in grado di gestire in modo efficiente i dati ad alta dimensionalità.
L'importanza dei database vettoriali
I database vettoriali, noti anche come motori di similarità vettoriale (VSE), sono database specializzati progettati per gestire dati complessi e ad alta dimensionalità chiamati embeddings vettoriali. Questi database utilizzano algoritmi di approssimazione dei vicini (ANN), indispensabili per un recupero rapido e preciso dei dati. Questa caratteristica è particolarmente importante per iFetch, che richiede interazioni in tempo reale con i clienti per fornire raccomandazioni istantanee sui prodotti e rispondere alle loro domande. La scelta di un database vettoriale non è una mera questione tecnica, ma una decisione strategica che ha un impatto diretto sulle prestazioni, la robustezza e l'efficienza di iFetch. Per assicurarsi di aver selezionato il VSE più adatto, l'azienda ha condotto uno studio di benchmarking completo. Il benchmark ha comportato la valutazione di vari database, tra cui Vespa, Milvus, Qdrant, Weaviate, Vald e Pinecone, in base a diversi criteri quali la velocità di indicizzazione, la velocità di interrogazione e la scalabilità. Il benchmarking ha incluso anche stress test per valutare le prestazioni di ciascun VSE in caso di picchi di carico e scenari di failover e ripristino per valutare la resilienza.
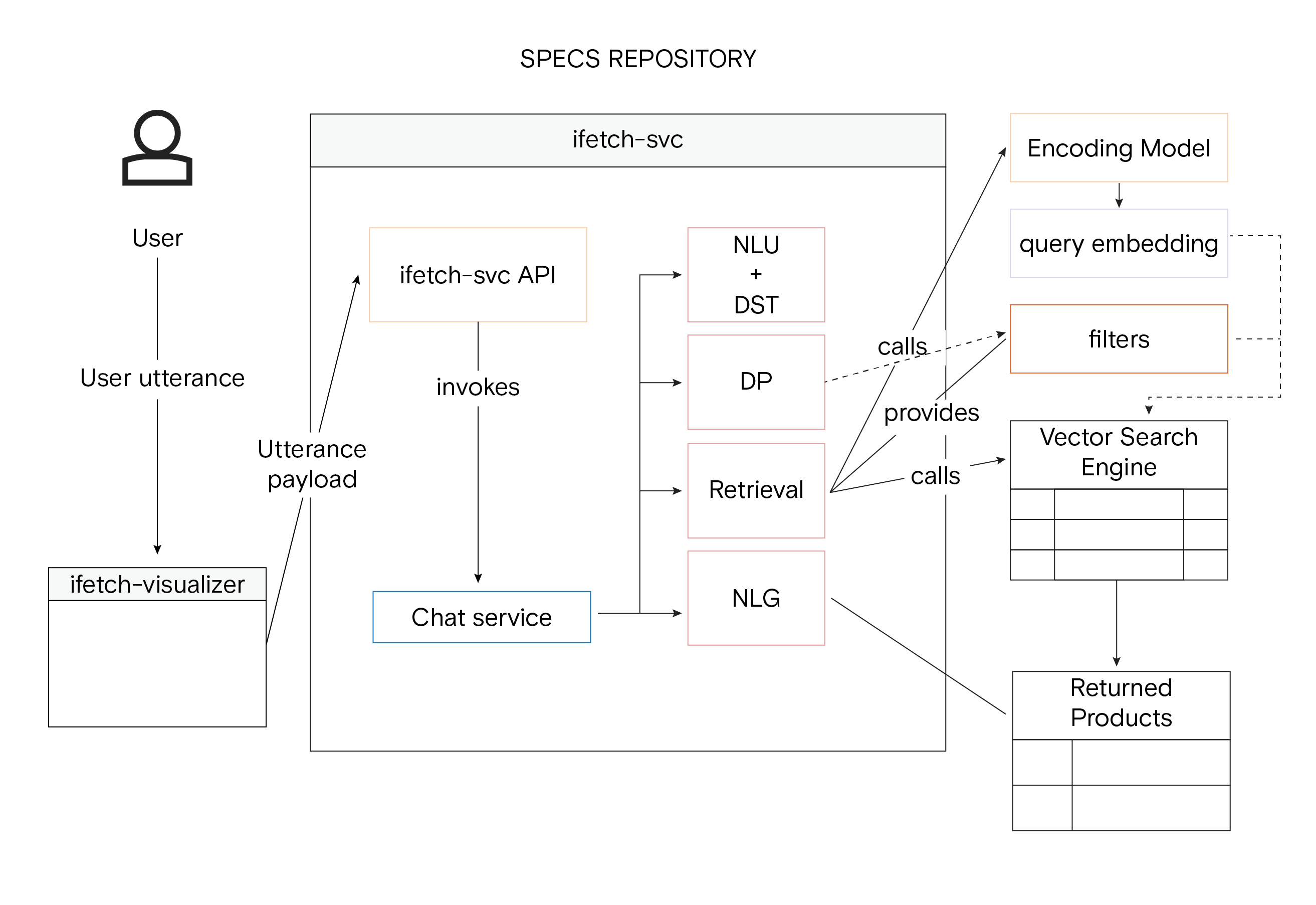 Rappresentazione olistica dell'architettura del sistema iFetch con Vector Similarity Searc
Rappresentazione olistica dell'architettura del sistema iFetch con Vector Similarity Searc
Criteri e selezione dei benchmark
Il processo di benchmarking condotto dal team di Farfetch è stato esaustivo e metodico, coprendo un'ampia gamma di fattori cruciali per il successo a lungo termine di iFetch. Tra questi, la diversità dei tipi di indici, i tipi di metriche, le capacità di servire i modelli e l'adozione da parte della comunità. Sono stati presi in considerazione anche la qualità della documentazione e la disponibilità del supporto, poiché questi fattori avrebbero influito sulla facilità di implementazione e sulla manutenzione continua.
| Feature | Qdrant | Milvus | Weaviate | Vespa | Vald | Pinecone | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Modello di coerenza | N/A | Forte coerenza | Eventuale coerenza | Eventuale coerenza | N/A | Eventuale coerenza | N/A | Eventuale coerenza | ||
| Supporto per GraphQL | N/A | N/A | Sì | N/A | N/A | N/A | N/A | N/A | N/A | |
| Sharding | No (da affrontare data sconosciuta) | Si | Si | Si | Si | N/A | N/A | N/A | ||
| Paginazione | N/A | No (Previsto nella versione 2.2 nella 2022.3) | Si | Si | N/A | N/A | N/A | N/A | ||
| Tipi metrici | Prodotto interno Similitudine cosina Euclidea (L2) | L2 Prodotto interno Hamming Jaccard Tanimoto Superstruttura Sottostruttura | Cosina | Euclidea Angolare Prodotto Interno Geo gradi Hamming | L1 L2 Angolo Hamming Coseno Angolo normalizzato Coseno normalizzato Jaccard | Euclideo Coseno Prodotto Interno | Max dim vettoriale Superstruttura Sottostruttura | Coseno | Euclideo Prodotto interno | |
| Dimensione massima del vettore | N/A | N/A | 32 768 | N/A | max.MaxInt64 | N/A | ||||
| Dimensione massima dell'indice | N/A | N/A | Illimitato | N/A | N/A | N/A | N/A | N/A | ||
| Tipi di indice | HNSW | ANNOY HNSW IVF_PQ IVF_SQ8 IVF_FLAT FLAT IVF_SQ8_H RNSG | NHSW | HNSW BM25 | N/A | Proprietario | ||||
| Model Serving | N/A | N/A | text2vec-contextionary Vettorizzatore linguistico proprio di Weaviate; modulo vettorizzatore Weighted Mean of Word Embeddings (WMOWE) che funziona con modelli popolari come fastText e GloVe. Il più recente text2vec - contextionary è stato addestrato utilizzando fastText su dati Wiki e CommonCrawl. text2vec- transformers I modelli Transfomer differiscono dal Contextionary in quanto consentono di inserire un modulo NLP preaddestrato specifico per il caso d'uso. Ciò significa che modelli come BERT, DilstBERT, RoBERTa, DilstilROBERTa, ecc. possono essere utilizzati in modo immediato con Weaviate. |
Dopo un'analisi rigorosa, sono stati selezionati due VSE, Milvus e Weaviate, per un benchmarking approfondito. Queste piattaforme si sono allineate strettamente con i loro rigorosi requisiti di robustezza, efficienza e scalabilità. Anche le roadmap delle piattaforme hanno influenzato la scelta finale, poiché l'azienda aveva bisogno di una soluzione che continuasse a evolversi e ad adattarsi alle sue crescenti esigenze.
Impostazione sperimentale
Per garantire una valutazione equa e completa, è stata utilizzata una configurazione hardware e software standardizzata.
- Hardware: CPU Intel Xeon E5-2690 v4, 112 GB di RAM, 1024 GB di HDD
- Software: Linux 16.04-LTS, Anaconda 4.8.3 con Python 3.8.12
- Set di dati: Il team di Farfetch ha utilizzato un set di dati pubblici da startups-list.com, comprendente 40.474 record. Il dataset includeva embeddings precalcolati per le descrizioni delle aziende.
Scenari e algoritmo di indicizzazione
Sono stati progettati diversi scenari di test per valutare le prestazioni di questi VSE in diverse condizioni. Gli scenari variavano il numero di record e il numero di codifiche per entità. Per l'indicizzazione è stato utilizzato l'algoritmo Hierarchical Navigable Small World (HNSW), noto per la sua efficienza in spazi di dati altamente dimensionali.
L'elenco finale degli scenari è riportato di seguito.
| Scenario | Numero di entità | Numero di codifiche per entità |
|---|---|---|
| Scenario #1 (S1) | 1.000 | 1 |
| Scenario #2 (S2) | 10.000 | 1 |
| Scenario #3 (S3) | 40.474 | 1 |
| Scenario #4 (S4) | 1.000 | 2 |
| Scenario #5 (S5) | 10.000 | 2 |
| Scenario #6 (S6) | 40.474 | 2 |
| Scenario #7 (S7) | 1.000 | 5 |
| Scenario #8 (S8) | 10.000 | 5 |
| Scenario #9 (S9) | 40.474 | 5 |
Analisi delle prestazioni
Indicizzazione
Weaviate: Consente la dichiarazione esplicita dei parametri dell'indice durante la creazione dello schema della classe. Tuttavia, limita la denominazione delle classi, ad esempio non permette numeri o caratteri speciali.
Milvus: Offre una gamma più ampia di algoritmi di indicizzazione e di tipi di metriche. Consente inoltre di definire le dimensioni dei file di indice, ottimizzando così le operazioni in batch.
Risultato: Milvus è in vantaggio per quanto riguarda i tempi medi di indicizzazione in tutti gli scenari. È stato notevolmente più veloce nello scenario più impegnativo dal punto di vista delle risorse, S9.
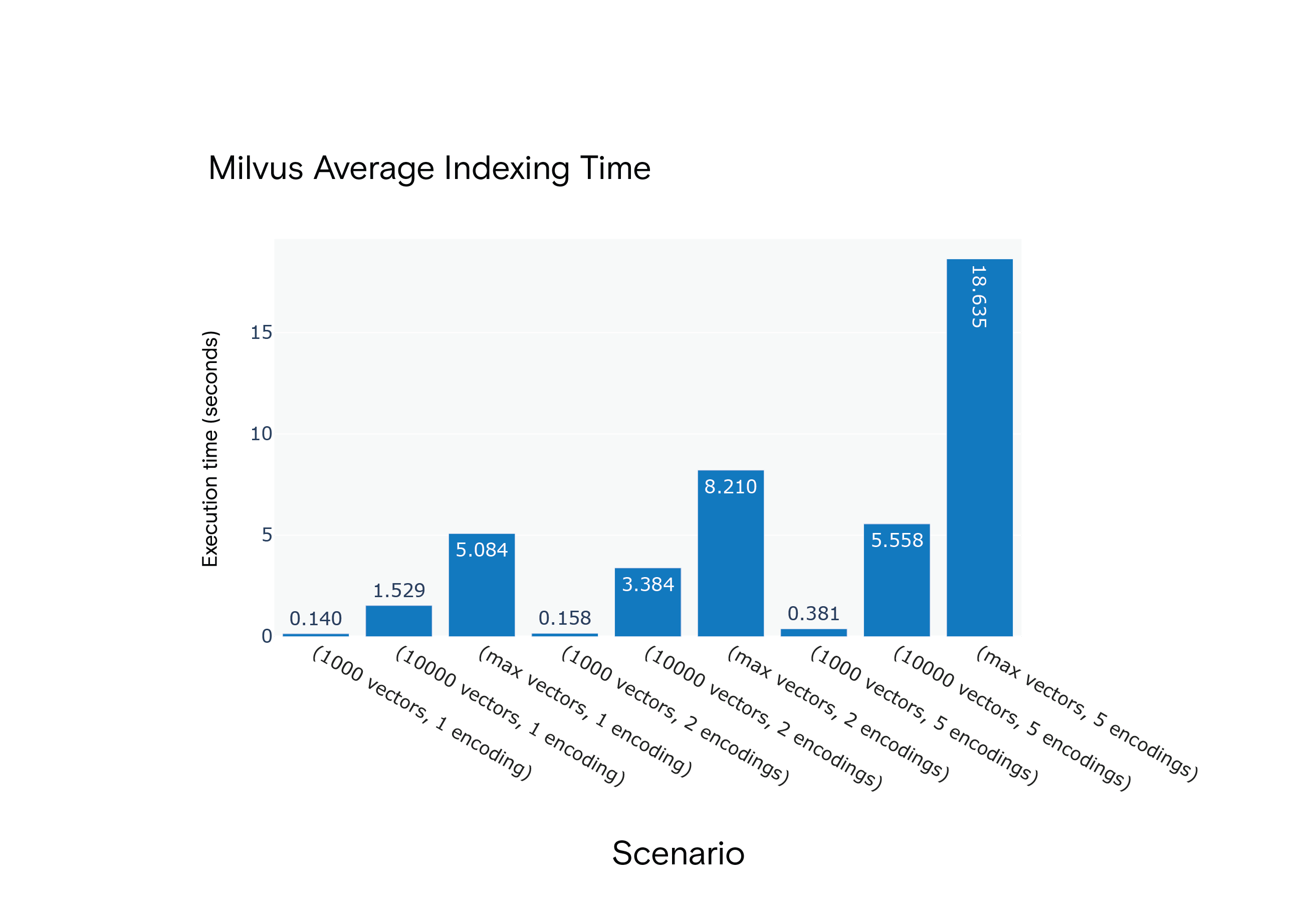 Milvus 1.1.1 Tempo medio di indicizzazione per gli scenari da S1 a S9
Milvus 1.1.1 Tempo medio di indicizzazione per gli scenari da S1 a S9
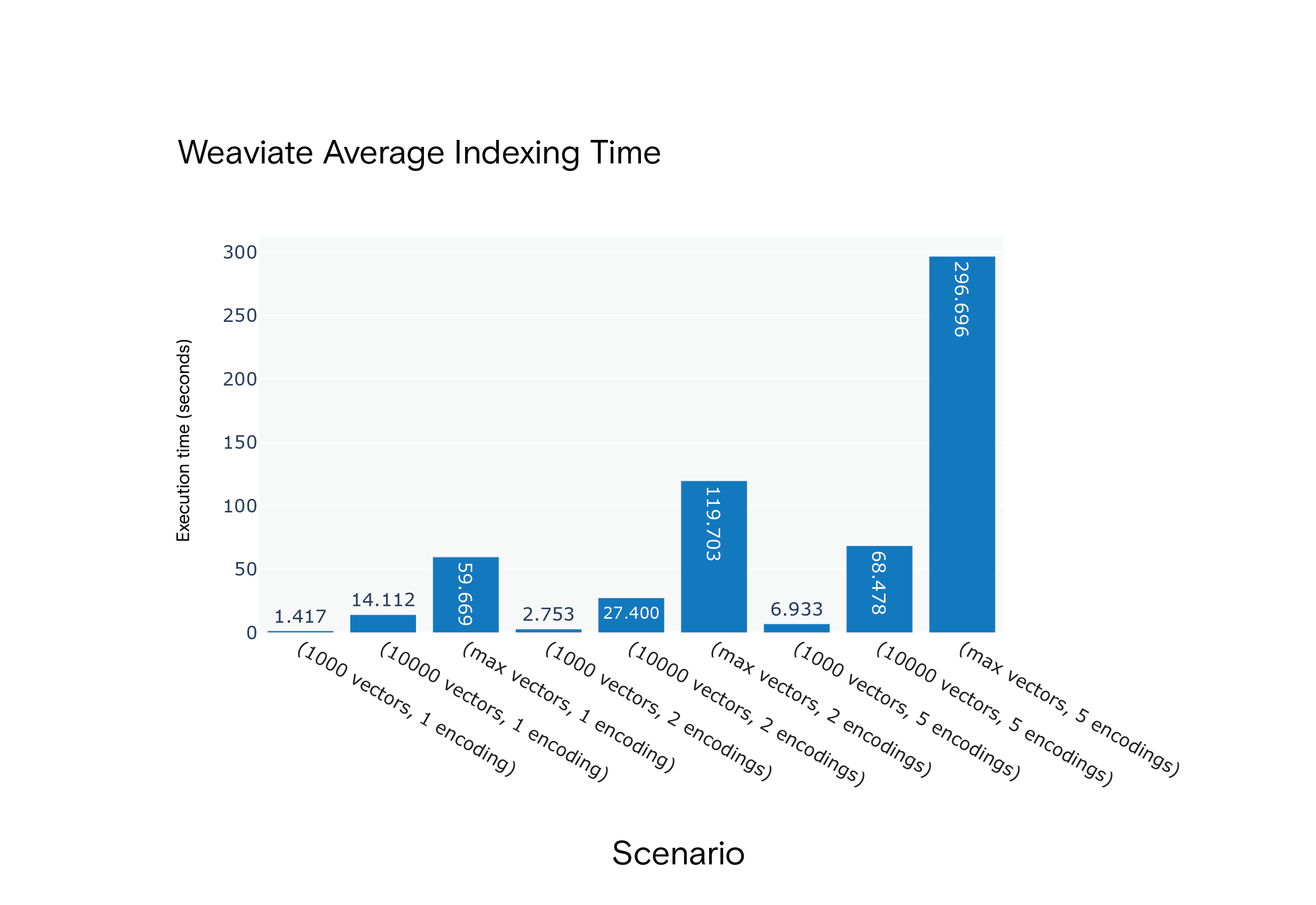 Tempo medio di indicizzazione di Weaviate per gli scenari da S1 a S9
Tempo medio di indicizzazione di Weaviate per gli scenari da S1 a S9
Interrogazione
Weaviate: Il client Python supporta la ricerca vettoriale, ma solo per un singolo vettore alla volta.
Milvus: Offre un metodo di ricerca più flessibile che può gestire un elenco di vettori, facilitando l'interrogazione di più vettori.
Risultato: Milvus ha mostrato tempi medi di interrogazione più brevi in tutti gli scenari, anche se ha richiesto una fase di "riscaldamento" per raggiungere prestazioni ottimali.
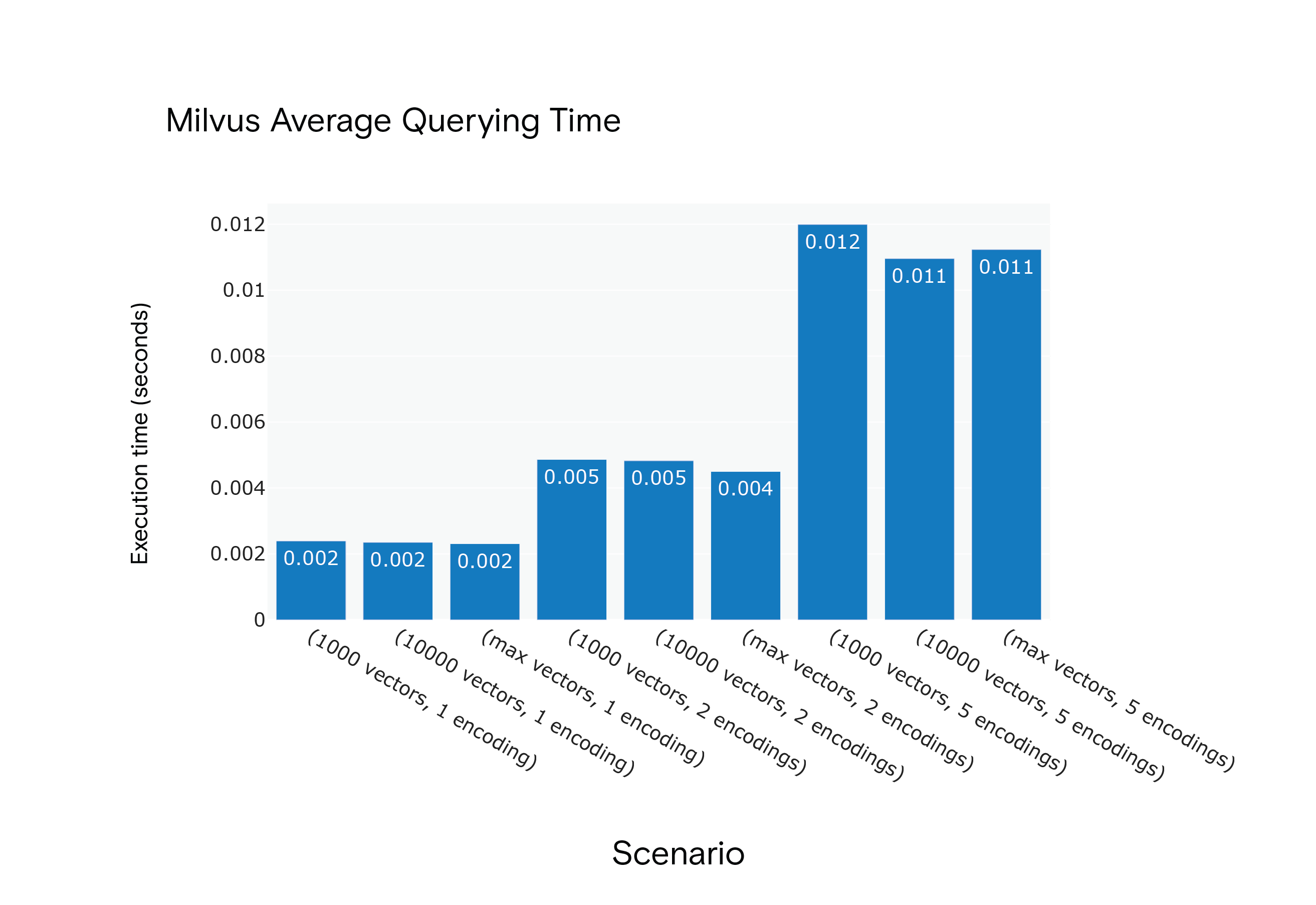 Milvus 1.1.1 Tempo medio di interrogazione per gli scenari da S1 a S9
Milvus 1.1.1 Tempo medio di interrogazione per gli scenari da S1 a S9
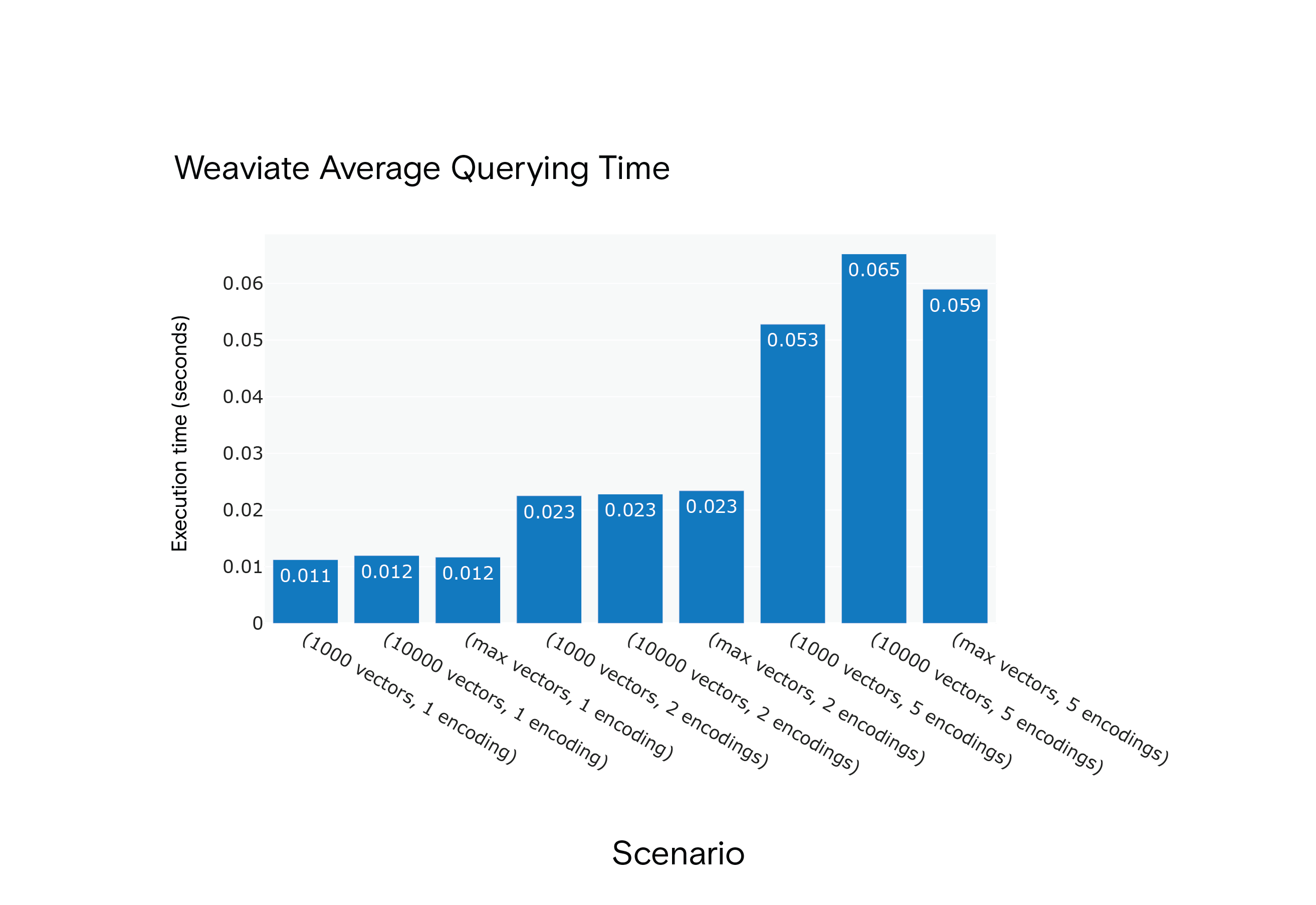 Tempo medio di interrogazione di Weaviate per gli scenari da S1 a S9
Tempo medio di interrogazione di Weaviate per gli scenari da S1 a S9
Il team di Farfetch ritiene che Milvus e Weaviate siano promettenti ma ancora in evoluzione. Caratteristiche come il ridimensionamento orizzontale, lo sharding e il supporto per le GPU sono sulla tabella di marcia. Per FARFETCH, che mira a gestire un catalogo di prodotti che va da 300k a 5 milioni di prodotti, il VSE ideale dovrebbe offrire:
- Risultati accurati e di alta qualità
- Capacità di indicizzazione efficiente
- Esecuzione rapida delle query
- Funzionalità di scalabilità come il bilanciamento del carico e la replica dei dati
Gli esperimenti hanno rivelato che Milvus ha costantemente superato Weaviate nei tempi di indicizzazione e di interrogazione. Tuttavia, vale la pena notare che entrambe le piattaforme presentano alcune limitazioni, come la mancanza di supporto per codifiche multiple. Il lavoro futuro prevede di monitorare da vicino lo sviluppo di queste piattaforme e di rivalutarle man mano che introducono nuove funzionalità.
*Questo caso di studio è una versione condensata di un approfondito blog di benchmarking sui database vettoriali pubblicato originariamente da PEDRO MOREIRA COSTA di Farfetch. Per un'analisi e un approfondimento più dettagliati, consultare i post originali: POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART I e POWERING AI WITH VECTOR DATABASES: A BENCHMARK - PART II.