




Come DiDi Food ha trasformato la ricerca di prodotti alimentari in America Latina con Milvus

Riduzione del 19%
nelle query senza risultati ottenute tramite la ricerca vettoriale semantica di Milvus
Aumento del 4%
conversioni nel carrello derivanti dal matching semantico dei prodotti basato su Milvus
15% delle query
ora beneficia della ricerca vettoriale, a integrazione della tradizionale ricerca testuale
Recupero vettoriale in meno di un secondo
con indicizzazione IVF_FLAT di Milvus e similarità del prodotto interno
Informazioni su DiDi Food
DiDi, leader globale nel ride-hailing con oltre 800 milioni di utenti in tutto il mondo, ha lanciato DiDi Food—il loro servizio di consegna di generi alimentari—in 12 grandi città dell’America Latina, tra cui Messico, Colombia e Costa Rica. Sfruttando la loro rete logistica esistente e le capacità di ottimizzazione in tempo reale, hanno ottenuto una crescita notevole: 2 milioni di utenti attivi mensili, 500.000 ordini giornalieri e oltre 120 milioni di dollari di GMV nel Q1 2025—tutto in soli sei mesi.
La piattaforma consegna prodotti freschi e beni essenziali per la casa in 30-45 minuti, con negozi partner che offrono fino a 30 milioni di SKU ciascuno. Operando in mercati diversi con interazioni multilingue, prezzi dinamici e gestione dell’inventario in tempo reale, DiDi Food ha costruito una solida base commerciale. Ma con l’aumentare della scala, è aumentata anche la complessità nell’aiutare milioni di clienti a trovare esattamente ciò di cui avevano bisogno all’interno di enormi cataloghi di prodotti. È qui che il database vettoriale Milvus ha trasformato le loro capacità di ricerca, abilitando una comprensione semantica che funziona tra le lingue e gestisce la confusione del mondo reale nel modo in cui le persone cercano effettivamente.
La sfida della ricerca: quando Elasticsearch basato su parole chiave non basta
Il team di ingegneria di DiDi ha affrontato le limitazioni che affliggevano il loro database Elasticsearch basato su parole chiave. Semplici errori di ortografia, code-switching o descrizioni non convenzionali spesso portavano a pagine senza risultati, creando attrito nell’esperienza di acquisto.
Alti tassi di "nessun risultato": la perdita di ricavi nascosta
DiDi Food ha affrontato un problema critico: troppe ricerche dei clienti restituivano zero risultati, portando all’abbandono delle sessioni di acquisto e a ricavi persi. Esempi reali dai dati di ricerca di DiDi hanno rivelato tre cause principali alla base di questi fallimenti.
Refusi ed errori di ortografia erano i colpevoli più comuni. Gli utenti digitavano "Genjibr" quando cercavano "Jengibre" (zenzero), "hedaho" invece di "HELADO" (gelato), o "Kellongs" per "Kelloggs." I loro sistemi di ricerca per parole chiave esistenti, basati su Elasticsearch, non riuscivano a colmare questi piccoli ma critici divari ortografici.
Artefatti del metodo di input creavano un’altra barriera. Le tastiere mobili e diversi sistemi di input generavano variazioni Unicode insolite come "𝑤𝑖𝑛𝑒" invece di "wine," "𝑏𝑎𝑛𝑎𝑛𝑎" per "banana," o "𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠" per "chocolates." Questi problemi tecnici di codifica impedivano ai clienti di trovare prodotti che erano chiaramente disponibili.
Query in lingue miste rappresentavano la sfida più grande nei mercati latinoamericani. I clienti cercavano naturalmente "apple juice orgánico" o "leche sin lactosa," combinando termini inglesi e spagnoli. Le variazioni regionali peggioravano la situazione—lo stesso prodotto poteva essere chiamato con nomi diversi tra Messico, Colombia e Costa Rica.
Ogni ricerca fallita rappresentava un cliente frustrato e una perdita diretta di ricavi. Per una piattaforma che elabora 500.000 ordini giornalieri, anche una piccola percentuale di query senza risultati può tradursi in un impatto significativo sul business.
Scalabilità e complessità multilingue
Oltre ai singoli fallimenti di ricerca, DiDi affrontava sfide sistemiche che minacciavano la sua capacità di scalare. L’indicizzazione testuale di decine di milioni di nomi SKU distinti aumentava i costi di archiviazione e degradava le prestazioni delle query man mano che il loro catalogo prodotti si espandeva in più paesi.
La complessità multilingue era più profonda delle query in lingue miste. Operare in Messico, Colombia, Costa Rica e altri mercati latinoamericani significava che lo stesso prodotto poteva avere nomi completamente diversi in ogni regione. "Palta" in alcuni paesi, "aguacate" in altri—entrambi si riferiscono all’avocado. I sistemi tradizionali basati su parole chiave alimentati da Elasticsearch richiedevano di mantenere indici separati per ogni variazione regionale, il che moltiplicava i requisiti di archiviazione e complicava la manutenzione.
Le sfumature culturali e linguistiche hanno creato ulteriori barriere. Lo slang locale, le variazioni dei nomi dei brand e persino i diversi sistemi di misurazione (metrico vs. imperiale) hanno tutti contribuito ai fallimenti della ricerca. Un approccio basato su parole chiave richiederebbe la mappatura manuale di migliaia di variazioni regionali—un compito impossibile alla scala di DiDi.
Il team di ingegneria di DiDi aveva urgente bisogno di una soluzione in grado di superare queste sfide e comprendere l'intento dietro le query degli utenti, indipendentemente dalla lingua, dalla regione o dal modo in cui i clienti sceglievano di esprimere le proprie esigenze.
La soluzione: costruire un motore di ricerca semantica con Milvus
Il sistema basato su Elasticsearch fatica con la diversità linguistica e la variabilità dell'input degli utenti perché tratta le parole come token discreti anziché come concetti significativi. I database vettoriali, tuttavia, possono comprendere il significato semantico e l'intento delle query degli utenti tramite embedding vettoriali e restituire risultati più accurati e pertinenti, indipendentemente dalla lingua o dagli errori di ortografia.
Il team di ingegneria di DiDi ha deciso di costruire un motore di ricerca semantica sfruttando modelli di embedding multilingue e un database vettoriale. Il modello di embedding converte sia i nomi e le descrizioni dei prodotti sia le query degli utenti in embedding vettoriali che rappresentano il loro significato semantico in uno spazio ad alta dimensionalità, mentre il database vettoriale archivia questi embedding ed esegue la ricerca semantica calcolando le distanze tra i vettori delle query e i vettori dei prodotti.
Dopo un'attenta valutazione, hanno scelto jina-embeddings-v3 come modello di embedding principale perché mappa il testo di lingue diverse nello stesso spazio matematico ad alta dimensionalità. Ciò significa che le query per "苹果" (cinese), "apple" (inglese) o "manzana" (spagnolo) producono vettori quasi identici, consentendo un matching cross-lingue accurato senza la necessità di sistemi di traduzione complessi. Anche input con errori di ortografia o foneticamente simili producono vettori vicini ai termini corretti.
DiDi ha scelto Milvus come database vettoriale per la sua maturità open-source, la capacità di scalare orizzontalmente fino a miliardi di vettori, la latenza nell'ordine dei millisecondi, l'architettura comprovata ad alto throughput e il ricco set di funzionalità.
Architettura dei dati e strategia di ottimizzazione
Per supportare il recupero vettoriale a bassa latenza su 30 milioni di SKU preservando al contempo le associazioni a livello di negozio, gli ingegneri di DiDi hanno implementato diverse ottimizzazioni chiave.
Invece di archiviare vettori individuali per ogni combinazione SKU-negozio, hanno unito i nomi degli articoli identici in singole voci vettoriali con gli ID dei negozi corrispondenti archiviati in array. Questo approccio ha ridotto la loro libreria vettoriale da 30 milioni di voci a 200.000 vettori unici, diminuendo drasticamente l'uso della memoria pur mantenendo una copertura completa dei prodotti.
Il team ha scelto una configurazione di indice
IVF_FLATin Milvus, dando priorità all'accuratezza della ricerca rispetto alla complessità della compressione. Quando gli utenti interrogano il sistema, Milvus restituisce i top-k vettori più simili dall'indice aggregato, seguiti da un rapido filtro sugli ID dei negozi per isolare gli articoli disponibili nella posizione attuale dell'acquirente.Per la freschezza dei dati, DiDi ha adottato un ciclo di aggiornamento notturno T+1. Gli SKU nuovi e aggiornati vengono raggruppati quotidianamente, ri-embedded utilizzando cluster GPU e inviati per aggiornare la collection Milvus. Questa strategia bilancia l'attualità dei dati con l'efficienza computazionale nell'intero enorme catalogo prodotti.
Progettazione dello schema Milvus
Lo schema della collection riflette i requisiti specifici di DiDi per la ricerca grocery, bilanciando flessibilità e prestazioni:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="embedding usando jina-embeddings-v3",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
Generazione di embedding accelerata da GPU
La generazione iniziale di embedding basata su CPU con il modello jina-embeddings-v3 ha comportato una latenza inaccettabile di 5 secondi per record. Per ottenere prestazioni in tempo reale, DiDi ha distribuito istanze GPU sulla propria piattaforma Luban, riducendo il tempo di embedding a circa 50 millisecondi per query:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
Architettura della pipeline di ricerca ibrida
Anziché sostituire completamente l’infrastruttura esistente, DiDi ha implementato Milvus come integrazione intelligente al proprio sistema Elasticsearch consolidato. Il design a doppia pipeline consente a Elasticsearch di gestire le query standard basate su parole chiave, mentre Milvus fornisce comprensione semantica per i casi complessi.
Il flusso di ricerca opera nei seguenti passaggi:
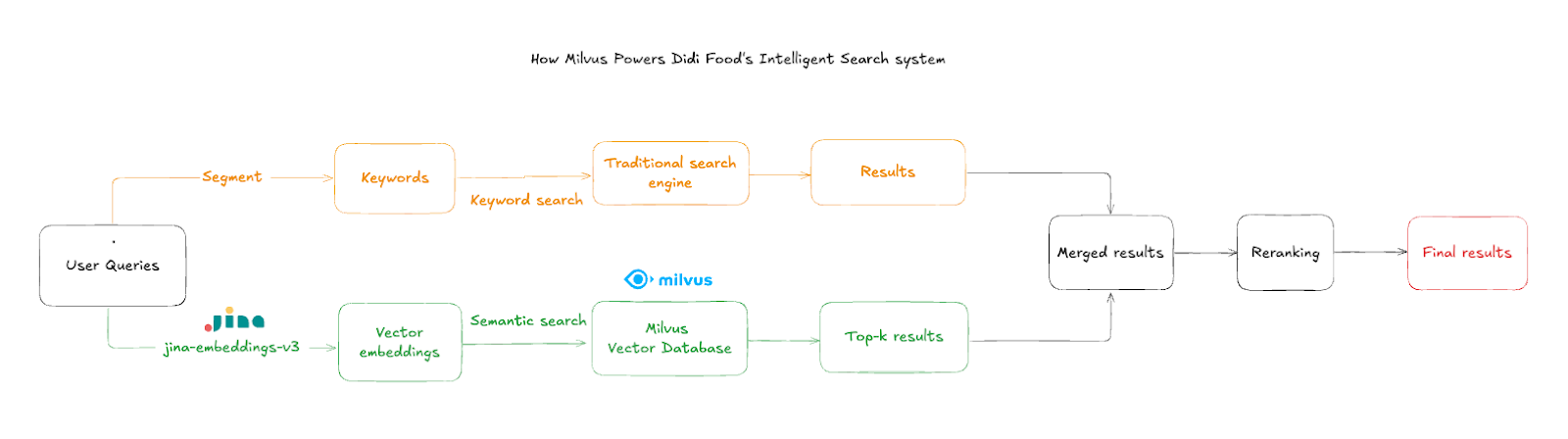
Input della query utente: i clienti digitano nomi o descrizioni di prodotti, spesso con errori di battitura o lingue miste
Embedding del testo: il sistema utilizza
jina-embeddings-v3per convertire l’input in vettori semantici ad alta dimensionalità entro ~50 msRicerca di similarità: Milvus interroga i vettori aggregati dei prodotti per trovare le corrispondenze semantiche più vicine
Filtraggio per negozio: i risultati vengono filtrati per ID negozio per garantire che vengano mostrati solo gli articoli disponibili nel negozio corrente
Unione dei risultati: i risultati vettoriali vengono combinati con i risultati di Elasticsearch quando la ricerca tradizionale produce risultati insoddisfacenti, offrendo un’esperienza di ricerca più ricca e completa
Fondamentale per l’esperienza utente è il filtraggio a livello di negozio, che garantisce che i risultati appartengano al contesto della posizione attuale dell’acquirente. Il sistema impiega un’aggregazione intelligente dei risultati: quando Elasticsearch produce risultati insoddisfacenti, gli articoli semanticamente rilevanti di Milvus integrano la risposta.
Risultati delle prestazioni e impatto nel mondo reale
L’implementazione di Milvus da parte di DiDi ha prodotto miglioramenti concreti in metriche aziendali critiche.
Il sistema ha ottenuto una riduzione del 19% delle query senza risultati, il che significa che quasi una ricerca precedentemente fallita su cinque ora restituisce prodotti pertinenti, recuperando direttamente opportunità di ricavo perse. Per una piattaforma che elabora 500.000 ordini giornalieri, questo tasso di recupero rappresenta un valore aziendale significativo.
La ricerca vettoriale si attiva per il 15% delle query totali, integrando la tradizionale ricerca testuale esattamente quando la comprensione semantica aggiunge valore senza sovraccaricare la pipeline principale delle query. Ancora più significativo, gli utenti esposti a elementi richiamati tramite vettori mostrano un aumento del 4% nelle conversioni di aggiunta al carrello, dimostrando che una maggiore pertinenza della ricerca si traduce in comportamenti di acquisto misurabili.
Il sistema ora gestisce query in più lingue, tra cui inglese, spagnolo, cinese, coreano e giapponese, con miglioramenti dell’accuratezza particolarmente notevoli per lo spagnolo, fondamentale per la presenza di DiDi nel mercato latinoamericano. I test sulle prestazioni multilingue hanno rivelato la potenza della comprensione semantica: le ricerche di "Liquid Foundation" funzionano altrettanto bene sia che gli utenti digitino il termine inglese, il cinese "液体妆前乳," o lo spagnolo "Base de maquillaje líquida." Il sistema colma lacune linguistiche che metterebbero completamente in difficoltà gli approcci tradizionali basati su parole chiave.
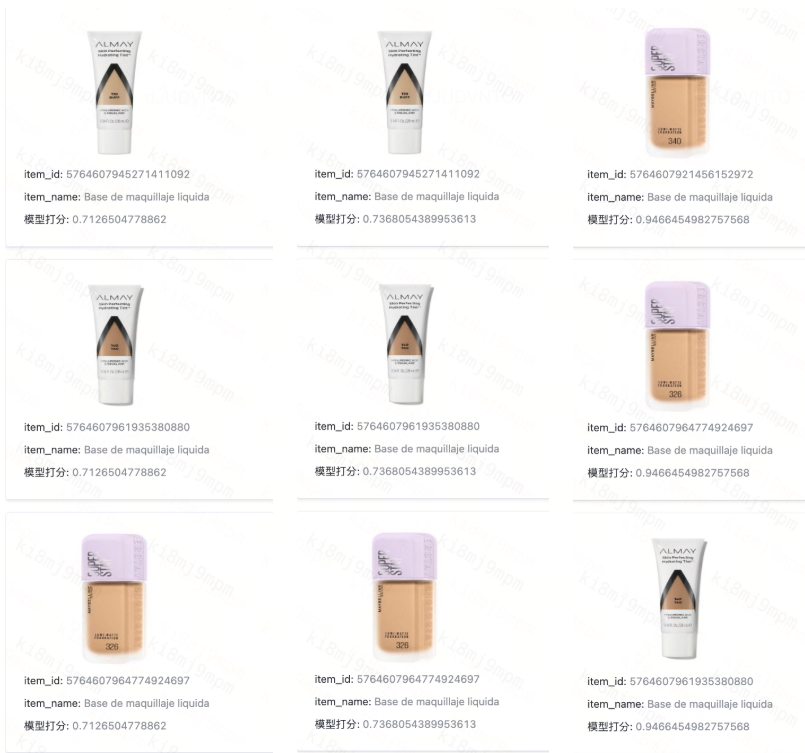
Figura: Le ricerche di "Liquid Foundation" funzionano altrettanto bene sia che gli utenti digitino il termine inglese, il cinese "液体妆前乳," o lo spagnolo "Base de maquillaje líquida."
Le query di prodotto complesse dimostrano la comprensione contestuale della ricerca vettoriale. Quando gli utenti cercano "Redac PalancaPara WC Blanca" (una leva bianca per lo scarico del WC), il sistema vettoriale abbina accuratamente la query nonostante la terminologia tecnica composta, mentre la ricerca tradizionale non riesce ad analizzare la descrizione del prodotto composta da più parole.
Questi miglioramenti si traducono in un’esperienza di acquisto più fluida, una maggiore soddisfazione dei clienti e un vantaggio competitivo definitivo nel mercato dell’e-commerce di generi alimentari freschi.
Roadmap futura: funzionalità di ricerca di nuova generazione
Basandosi su queste solide fondamenta, DiDi e Milvus stanno collaborando a diverse funzionalità avanzate per la prossima fase di sviluppo.
La sincronizzazione del catalogo in tempo reale ridurrà la latenza tra le modifiche dell’inventario e i dati ricercabili tramite aggiornamenti in streaming, assicurando che gli utenti non vedano mai prodotti che in realtà non sono disponibili. L’integrazione dei segnali comportamentali unirà la similarità vettoriale con la cronologia degli utenti, le preferenze e i segnali contestuali per offrire raccomandazioni iper-personalizzate che migliorano nel tempo.
La ricerca ibrida avanzata e il reranking rappresentano forse lo sviluppo più entusiasmante. Questo sistema combinerà metriche di business, tra cui prezzo, valutazioni, promozioni e livelli di inventario, con la rilevanza semantica per far emergere raccomandazioni davvero ottimali per ogni singolo acquirente.
Il supporto multilingue avanzato amplierà la copertura linguistica e migliorerà la gestione dei dialetti regionali man mano che DiDi entrerà in nuovi mercati. L’ottimizzazione dinamica degli embedding implementerà meccanismi di apprendimento continuo per migliorare la qualità degli embedding in base ai modelli reali di interazione degli utenti, creando così un sistema di ricerca che diventa sempre più intelligente con l’uso.
Innovando continuamente, DiDi sta ridefinendo l’esperienza di ricerca della spesa, assicurando che ogni acquirente trovi esattamente ciò di cui ha bisogno, ogni volta.
Conclusione
Il percorso di DiDi Food con Milvus dimostra che la ricerca semantica rappresenta più di un aggiornamento tecnico: è una reinterpretazione fondamentale del modo in cui gli utenti interagiscono con grandi cataloghi di prodotti. Combinando un’architettura dei dati ben ponderata, scelte tecnologiche appropriate e un’attenzione costante all’esperienza utente, hanno creato un sistema di ricerca che comprende davvero l’intento attraverso lingue e culture.
I risultati convalidano questo approccio: meno utenti frustrati, più acquisti riusciti e un’esperienza di acquisto che funziona indipendentemente da come i clienti scelgono di esprimere le proprie esigenze. Per i 2 milioni di utenti mensili di DiDi, questo significa trovare costantemente ciò di cui hanno bisogno, quando ne hanno bisogno, nella lingua che risulta loro più naturale.
Questa storia di successo illustra ciò che diventa possibile quando aziende innovative adottano la comprensione semantica su larga scala. Mentre DiDi continua a espandersi in tutta l’America Latina, la sua architettura di ricerca basata su Milvus fornisce una base solida per l’innovazione continua e la soddisfazione degli utenti. La tecnologia funziona, i risultati aziendali sono chiari e il miglioramento dell’esperienza utente è tangibile: esattamente ciò che un’ingegneria eccellente dovrebbe offrire.
- Informazioni su DiDi Food
- La sfida della ricerca: quando Elasticsearch basato su parole chiave non basta
- La soluzione: costruire un motore di ricerca semantica con Milvus
- Risultati delle prestazioni e impatto nel mondo reale
- Roadmap futura: funzionalità di ricerca di nuova generazione
- Conclusione