




Perché abbiamo creato Vector Lakebase: ripensare l’architettura dei dati non strutturati per l’IA
Di recente abbiamo lanciato Zilliz Vector Lakebase, la prossima evoluzione di Zilliz Cloud da un sistema puramente di database vettoriale a una base dati unificata, lake-native, per workload di IA. L'annuncio ha suscitato molto interesse. Ha anche fatto emergere quasi subito domande su dove fosse diretta Zilliz.
Zilliz si stava allontanando dai database vettoriali? Oppure, più direttamente: i database vettoriali stanno già diventando obsoleti?
Capisco perché siano sorte queste domande. Per anni, Zilliz è stata nota per la creazione di sistemi di database vettoriali pronti per la produzione (l'open-source Milvus e il servizio completamente gestito Zilliz Cloud). Quindi, quando abbiamo iniziato a parlare dell'evoluzione verso una base dati lake-native per l'IA, alcune persone si sono naturalmente chieste se ciò significasse un cambio di direzione.
La risposta breve è NO. Assolutamente NO. Semmai, Vector Lakebase è la nostra risposta a ciò che accade dopo che i database vettoriali hanno avuto successo.
Negli ultimi anni, i database vettoriali sono diventati uno degli strati infrastrutturali fondamentali dello stack IA. L'adozione è cresciuta più velocemente di quanto avremmo potuto immaginare quando abbiamo avviato Milvus quasi dieci anni fa. La categoria è reale e la necessità di retrieval semantico sta diventando sempre più importante.
Ma anche un altro aspetto ci è diventato chiaro: il retrieval vettoriale non è più l'intero problema.
Man mano che i sistemi di IA passano da assistenti statici ad agenti in esecuzione continua, le imprese chiedono qualcosa di più ampio dalla loro infrastruttura per dati non strutturati. Non vogliono solo un sistema in grado di recuperare informazioni. Vogliono un sistema che possa migliorare i dati, riorganizzarli, analizzarli, perfezionarli e reimmettere quei miglioramenti in produzione. Questo cambia l'architettura.
Questo cambiamento mi ricorda un ciclo precedente nella storia delle infrastrutture: l'evoluzione dei database durante l'era dell'internet mobile. I dettagli sono diversi, ma lo schema è familiare. Un nuovo tipo di applicazione crea un nuovo tipo di pressione sui dati. La prima generazione di infrastrutture risolve il problema immediato del servizio. Poi, con la crescita dei dati, l'architettura deve espandersi.
Penso che i database vettoriali stiano entrando ora in quella fase successiva.
L'internet mobile ha già attraversato una volta questo ciclo
Intorno al 2010, con l'esplosione delle applicazioni mobili, MongoDB è diventato uno dei prodotti infrastrutturali più rappresentativi di quel periodo.
Il motivo era semplice. Le applicazioni mobili generavano enormi quantità di dati semi-strutturati: eventi utente, attività social, telemetria dei dispositivi, segnali comportamentali, log di prodotto. Nessuno di questi si adattava perfettamente ai modelli di database relazionale che la maggior parte dei team utilizzava all'epoca. I team di prodotto rilasciavano rapidamente, gli schemi cambiavano di continuo e il primo problema era semplicemente accettare i dati senza rallentare l'applicazione. MongoDB risolse molto bene quel problema immediato: acquisire prima i dati. Struttura e analisi potevano arrivare dopo.

Diversi anni dopo, il settore iniziò a porsi una domanda diversa. Una volta che tutti questi dati esistevano, come potevano le aziende usarli davvero? Quel cambiamento contribuì a favorire l'ascesa di moderni data warehouse come Snowflake e Redshift. L'attenzione si spostò dallo storage operativo all'insight analitico. Le aziende volevano report BI, coorti di utenti, attribuzione, previsioni e analisi della crescita. I dati smisero di essere solo un sottoprodotto operativo e divennero un asset aziendale.
Poi emerse un altro collo di bottiglia.
La separazione tra sistemi transazionali e sistemi analitici divenne sempre più dolorosa. Le pipeline di dati tra ambienti OLTP e OLAP erano fragili, costose e operativamente estenuanti. Gli stessi dataset venivano copiati ripetutamente tra sistemi, spesso con ritardi di sincronizzazione e sottili incoerenze.
Questo era l’ambiente che ha dato origine all’architettura Lakehouse. Databricks, Iceberg, Hudi e sistemi correlati sono tutti confluiti intorno alla stessa idea di base: una singola copia logica dei dati dovrebbe supportare molteplici modelli di calcolo senza richiedere spostamenti infiniti tra sistemi.
Guardando indietro, la progressione sembra quasi inevitabile. Ma all’epoca, nulla di tutto ciò era ovvio. L’ascesa di MongoDB non prevedeva Snowflake. Snowflake non prevedeva il Lakehouse. Ogni transizione è emersa perché la generazione precedente di infrastruttura aveva avuto successo su larga scala e poi aveva esposto una nuova classe di vincoli.
Questo schema è importante perché l’infrastruttura per l’AI sembra sempre più seguire un percorso simile.
Il retrieval ha risolto il primo problema, non quello finale
Quando i modelli linguistici di grandi dimensioni sono entrati nell’adozione mainstream nel 2023, i database vettoriali sono diventati una delle prime categorie infrastrutturali di successo. Il motivo era pratico. I sistemi RAG avevano bisogno di un modo nativo per archiviare embeddings ed eseguire retrieval semantico. La maggior parte dei database tradizionali non era progettata per la ricerca vettoriale ad alta dimensionalità, indici ANN, retrieval ibrido e filtri a bassa latenza su larga scala.
In molti modi, i database vettoriali hanno risolto lo stesso tipo di problema che MongoDB aveva risolto in precedenza. Un nuovo pattern applicativo ha creato una nuova astrazione dei dati, e gli sviluppatori avevano bisogno di un’infrastruttura in grado di supportarla. Questa volta, l’astrazione era la rappresentazione semantica: embeddings generati da dati non strutturati tramite modelli neurali.
Quella prima fase di adozione è avvenuta molto rapidamente. Ma solo pochi anni dopo, le domande che sentiamo dai clienti sono diventate molto più complesse. Non chiedono più soltanto come recuperare vettori in modo efficiente. Chiedono:
- Come possiamo deduplicare e affinare continuamente i dati di training?
- Come possiamo analizzare miliardi di embeddings per problemi di clustering e qualità?
- Come possiamo identificare drift, bias o ridondanza nei dataset multimodali?
- Come possiamo tracciare e ottimizzare le cronologie di esecuzione degli agenti?
- Come possiamo rielaborare e migliorare i dati man mano che i modelli evolvono?
- Come possiamo cercare nei dati cold senza mantenere tutto il compute sempre in esecuzione?
- Come possiamo usare dati che risiedono già in Iceberg, Lance, Parquet e object storage per molteplici workload AI?
Questi non sono più problemi puramente di retrieval. Richiedono elaborazione offline su larga scala, workflow iterativi di discovery, governance dei dati, esplorazione analitica e cicli di feedback continui tra sistemi online e computazione offline. Sempre più spesso, abbiamo notato qualcosa di importante tra i team AI avanzati: il collo di bottiglia non era più soltanto la capacità del modello. Era la velocità di iterazione.
Un’esperienza lo ha reso dolorosamente evidente. Abbiamo visto team tentare di rielaborare grandi dataset vettoriali: riclustering degli embeddings, rimozione della duplicazione, rigenerazione degli indici, re-embedding di interi corpora. In alcuni casi, semplicemente spostare un miliardo di vettori da un sistema a un altro poteva richiedere giorni. Non ore. Giorni.
Nel frattempo, i cicli di iterazione all’interno dei principali team AI si stanno muovendo nella direzione opposta. I ricercatori vogliono sperimentare continuamente. I data engineer sono sotto pressione per pulire, valutare e aggiornare i dataset più velocemente. I modelli migliorano. I modelli di embedding cambiano. Gli agenti creano nuove tracce ogni giorno. Ma lo stack infrastrutturale sottostante non era progettato per cicli di affinamento continuo su dati non strutturati.
Quello è stato il momento in cui abbiamo iniziato a pensare che il settore stesse inquadrando il problema in modo troppo ristretto.
L’infrastruttura per dati non strutturati non è semplicemente un livello di retrieval. Sta diventando un sistema operativo continuo.
Dai sistemi di retrieval ai sistemi continui: CS/CD
Internamente, abbiamo iniziato a descrivere questa architettura come un ciclo continuo tra serving e discovery. Nel tempo, abbiamo iniziato a chiamarla CS/CD: Continuous Serving e Continuous Discovery.
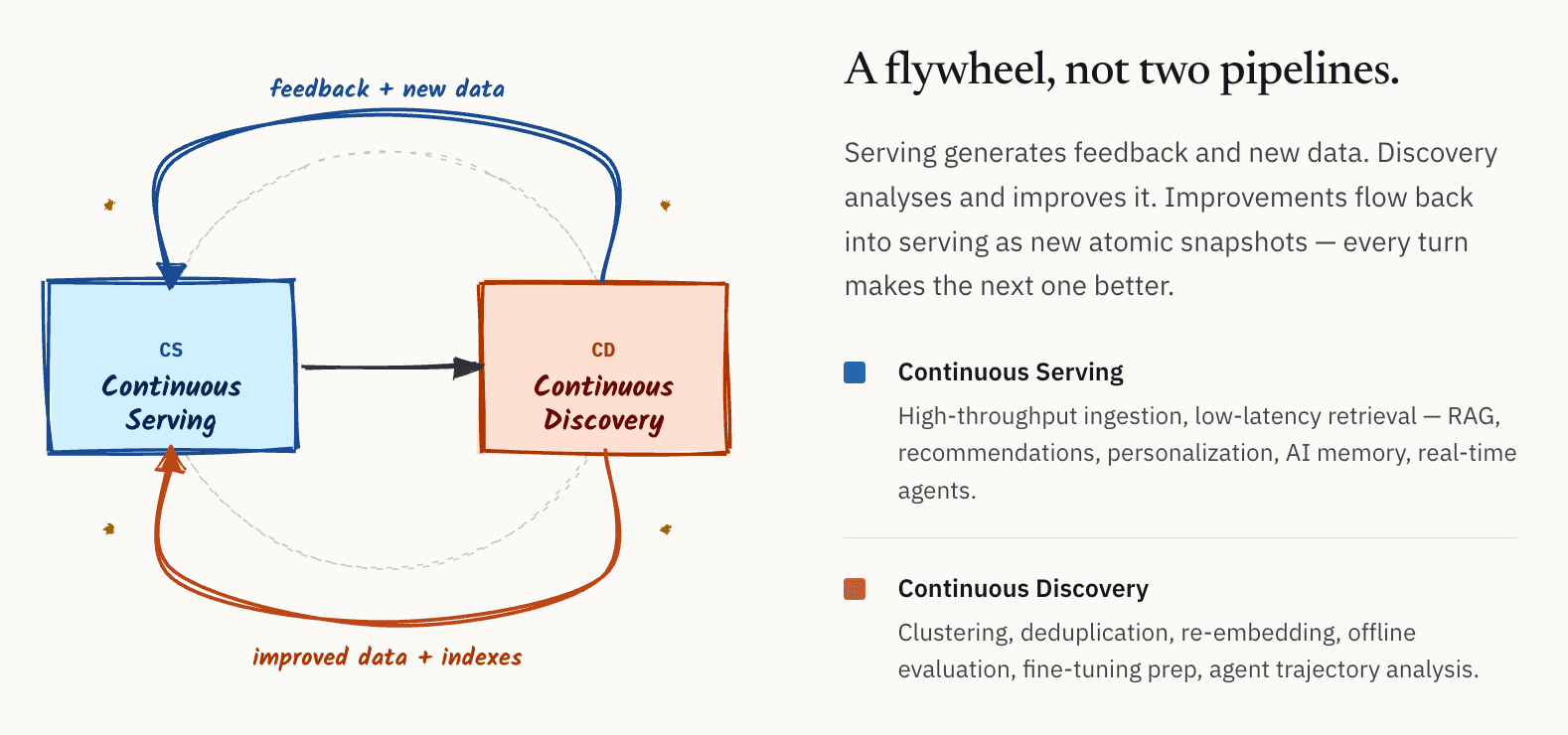
L'idea è concettualmente semplice.
- Da un lato, c'è il serving layer: ingestione ad alto throughput, recupero a bassa latenza per sistemi RAG online, sistemi di raccomandazione, personalizzazione, memoria AI e agenti in tempo reale.
- Dall'altro lato, c'è il discovery layer: clustering, deduplicazione, re-embedding, valutazione offline, analisi della qualità, preparazione del fine-tuning dei modelli e analisi delle traiettorie degli agenti.
Il punto importante è che questi non sono workflow indipendenti. Formano un flywheel. I sistemi di serving generano continuamente feedback e nuovi dati. I sistemi di discovery analizzano e migliorano quei dati. I miglioramenti risultanti, inclusi embedding migliori, dataset più puliti, indici migliorati e metadati perfezionati, confluiscono poi di nuovo nel serving layer.
Ogni iterazione dovrebbe migliorare quella successiva. Almeno in teoria.
In pratica, la maggior parte delle organizzazioni non riesce ancora a gestire questo loop in modo efficiente perché l'infrastruttura sottostante rimane frammentata.
Oggi, se un team vuole eseguire elaborazioni offline su larga scala sui dati vettoriali di produzione, il workflow tipico è ancora dolorosamente manuale. I dati devono prima essere esportati dal database vettoriale in un ambiente lake o batch. Di solito gli indici non possono essere riutilizzati. Le pipeline di sincronizzazione diventano fragili. Gli aggiornamenti incrementali sono difficili. I risultati elaborati devono infine essere reimportati nel sistema di serving, spesso senza alcuna garanzia di consistenza atomica tra i nuovi dati e i nuovi indici.
Il risultato è un workflow lento, fragile e costoso. E poiché mantenerlo è così costoso, molte organizzazioni semplicemente evitano di fare discovery continua. I dati restano lì, recuperabili ma in gran parte inesplorati.
Questo ci ha ricordato sempre più il divario storico tra sistemi OLTP e OLAP, solo che ora la frammentazione è tra il recupero semantico online e l'elaborazione offline di dati non strutturati.
Perché le architetture esistenti alla fine raggiungono i loro limiti
Una cosa di cui ci siamo convinti sempre di più è che nessuno dei due lati dell'attuale stack infrastrutturale è sbagliato.
I database vettoriali e i sistemi Lakehouse risolvono entrambi problemi importanti. Il problema è che ciascuna architettura è stata ottimizzata attorno a una sola metà del workload emergente.
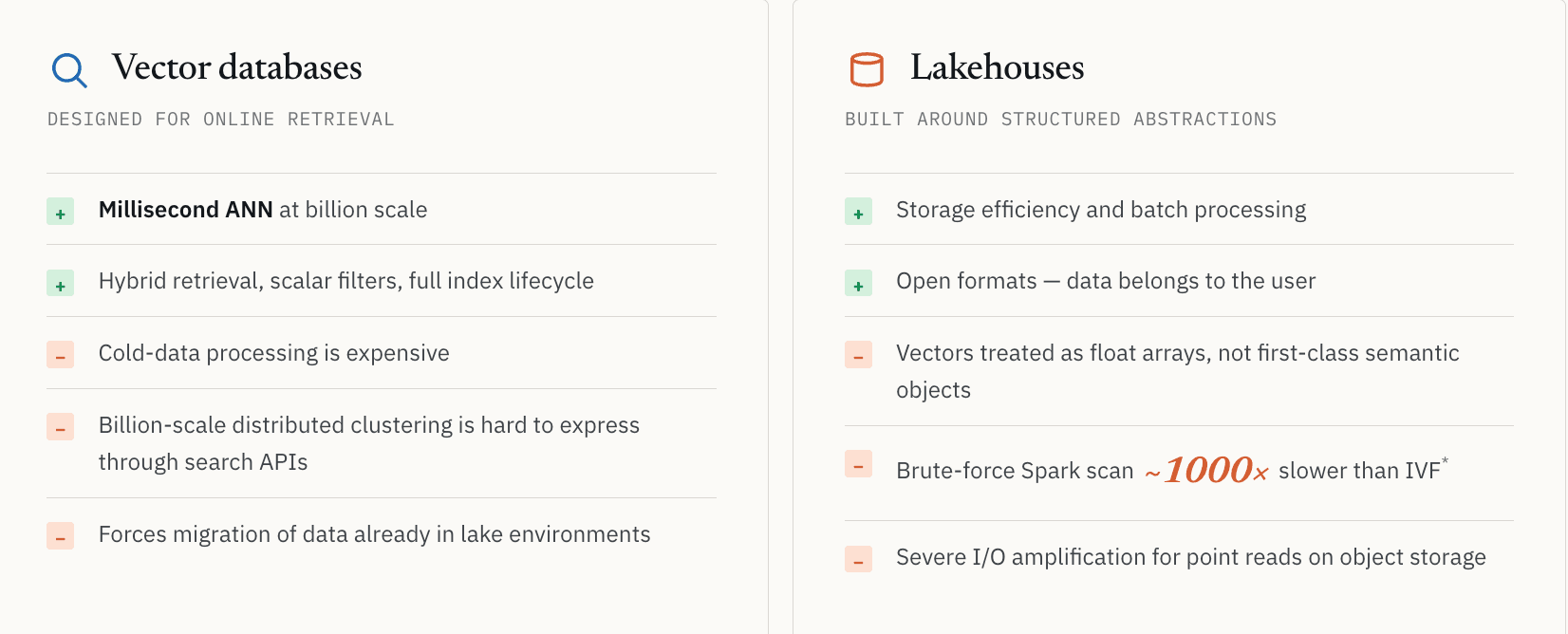
I database vettoriali sono stati progettati principalmente per il recupero online.
Prendiamo l'open-source Milvus come esempio. Risolve estremamente bene la ricerca vettoriale su larga scala. Ma quando i workload si spostano oltre il serving e verso la discovery su larga scala, emergono naturali confini architetturali.
L'elaborazione dei dati freddi diventa costosa. Il clustering distribuito su scala di miliardi è difficile da esprimere tramite API di ricerca online. Molti sistemi presuppongono che i dati debbano rimanere caricati nell'infrastruttura online per restare interrogabili. Le aziende che già archiviano enormi dataset non strutturati in ambienti lake affrontano costi di migrazione e frammentazione della governance quando viene chiesto loro di spostare tutto in un sistema di retrieval dedicato.
Questi non sono bug di implementazione. Sono conseguenze dell'ottimizzazione per il recupero online a bassa latenza.
I Lakehouse risolvono l'efficienza dello storage e l'elaborazione batch, ma sono stati progettati attorno ad astrazioni di dati strutturati
L'approccio opposto, partendo dal lato Lakehouse, introduce un diverso insieme di tradeoff.
I Lakehouse risolvono elegantemente l'efficienza dello storage e l'elaborazione batch. Ma sono stati progettati attorno ad astrazioni di dati strutturati. Nella maggior parte delle architetture lake, i vettori sono ancora trattati come lunghi array di float anziché come oggetti semantici di prima classe. Formati di file come Parquet non sono stati progettati attorno a indici ANN, indici invertiti o percorsi di recupero semantico a bassa latenza.
Lo abbiamo visto direttamente con un cliente farmaceutico che effettuava ricerche di similarità molecolare. Una scansione Spark brute-force sui dati del lake era circa 1000 volte più lenta rispetto al recupero vettoriale indicizzato usando una ricerca basata su IVF. Il numero esatto dipende dalla distribuzione dei dati, dai parametri dell’indice e dall’hardware, ma la lezione resta valida: senza l’indice giusto, molti workload semantici non sono economicamente praticabili.
Esiste anche un problema di storage più basilare. L’object storage può introdurre una grave amplificazione dell’I/O per workload orientati al recupero. La ricerca semantica spesso trova un numero ridotto di ID, ma l’applicazione ha comunque bisogno dei record completi dietro quegli ID. Con i formati colonnari tradizionali, recuperare pochi record di piccole dimensioni può richiedere la lettura di grandi blocchi di storage. Questo va bene per le scansioni. È poco adatto al serving a bassa latenza.
Nel tempo, la nostra conclusione è diventata difficile da evitare: il settore non dovrebbe dover scegliere tra database vettoriali e architetture lake. Ha bisogno di un’architettura in cui il recupero e la discovery su larga scala siano parti native dello stesso sistema operativo.
Cosa intendiamo per Vector Lakebase
Questa consapevolezza ci ha portati verso ciò che ora chiamiamo Vector Lakebase. L’idea centrale non è “un database vettoriale più un data lake.” Credo che questa formulazione manchi il punto architetturale più profondo.
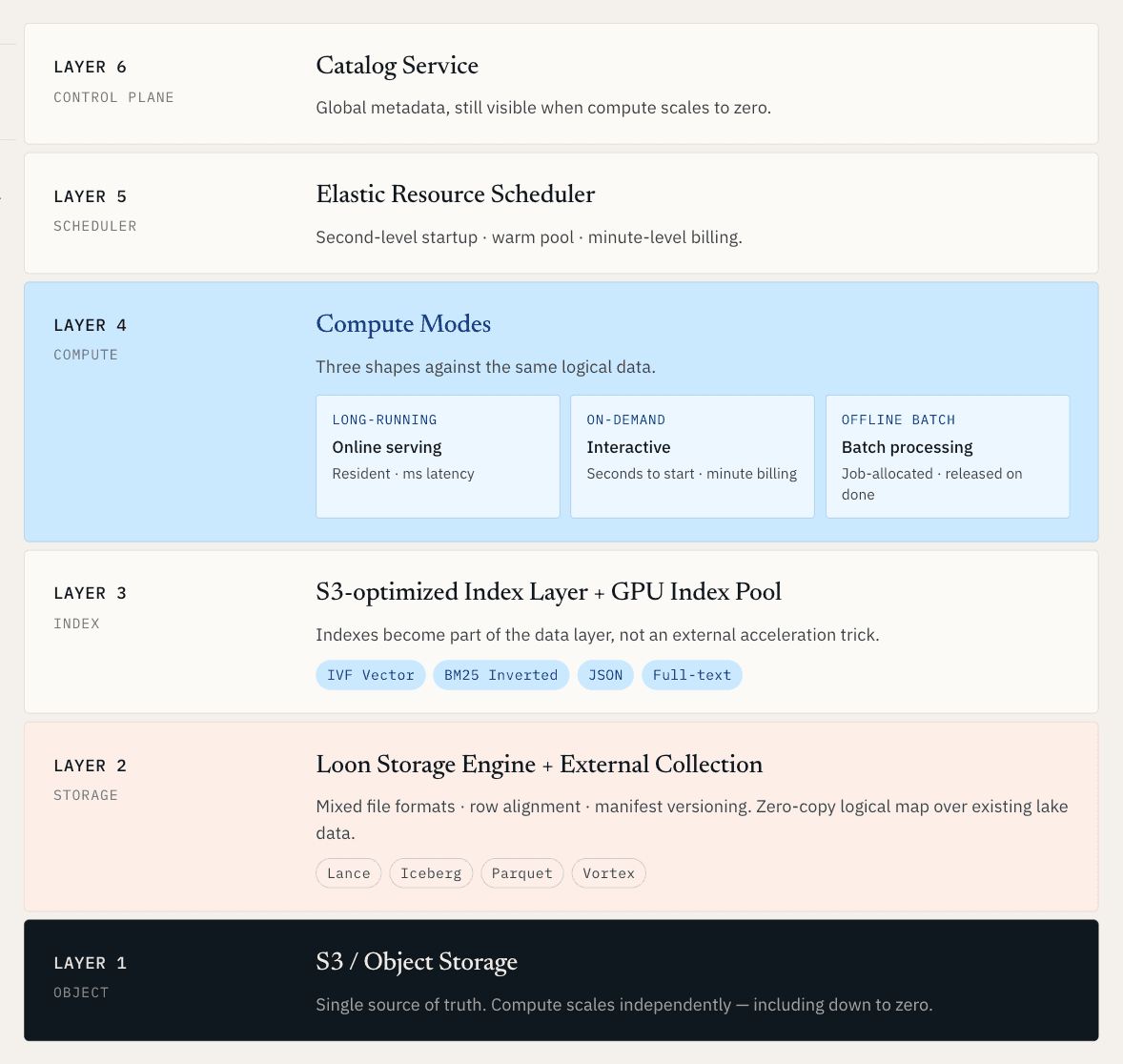
L’obiettivo è creare un livello operativo unificato per i dati non strutturati, in cui serving online, discovery offline e compute elastico operino tutti sulla stessa base logica dei dati.
Per i dati grezzi, questo significa che vettori, documenti, metadati, log e indici sono gestiti insieme su storage lake-native. Per i dati che già risiedono in Iceberg, Lance, Parquet o object storage, significa che il sistema può mappare e indicizzare quei dati senza imporre una migrazione completa.
Una volta partiti da questo requisito, l’architettura deve risolvere diversi problemi difficili contemporaneamente. Il compute deve scalare indipendentemente dallo storage. Gli indici devono diventare parte del livello dati, non un trucco di accelerazione esterno. Nuovi dati e nuovi indici devono essere pubblicati insieme come snapshot coerenti. E i dati lake esistenti devono diventare ricercabili senza creare un’altra copia.
Queste idee sembrano semplici. Farle funzionare preservando al contempo le prestazioni che le persone si aspettano da un database vettoriale è la parte difficile. È qui che le decisioni ingegneristiche di livello inferiore iniziano a contare.
Il costo della separazione tra storage e compute e come lo affrontiamo
La separazione storage-compute è necessaria per il ciclo CS/CD, ma non è gratuita.
Cold start lento
Se il compute può scalare fino a zero, la prima query in un workflow on-demand o offline può incontrare dati completamente freddi. Il nodo non ha un indice locale, nessuna cache calda e nessun dato residente. Tutto deve arrivare dall’object storage.
Per dataset piccoli, questo è gestibile. Per workload vettoriali di grandi dimensioni, diventa rapidamente inaccettabile. Consideriamo un miliardo di vettori a 768 dimensioni. Un indice HNSW convenzionale può pesare circa 340 GB. Scaricare quell’intero indice da S3 può richiedere più di quattro minuti. Nessuno vuole aspettare quattro minuti prima che una ricerca possa iniziare.
La nostra risposta è rendere il percorso a freddo molto più piccolo. Usando una quantizzazione a 1+3 bit in stile RaBitQ, possiamo comprimere quell’indice di circa 340 GB fino a circa 13 GB. La ricerca viene eseguita in due fasi. La prima fase usa una rappresentazione a 1 bit per il filtraggio grossolano, con circa l’85-90 percento di recall, riducendo al contempo la dimensione dei dati a circa un trentesimo dell’originale. La seconda fase usa la rappresentazione a 1+3 bit per rieseguire il ranking e perfezionare i risultati fino a circa il 95 percento di recall. Questo porta il cold start da minuti a circa 5-10 secondi.
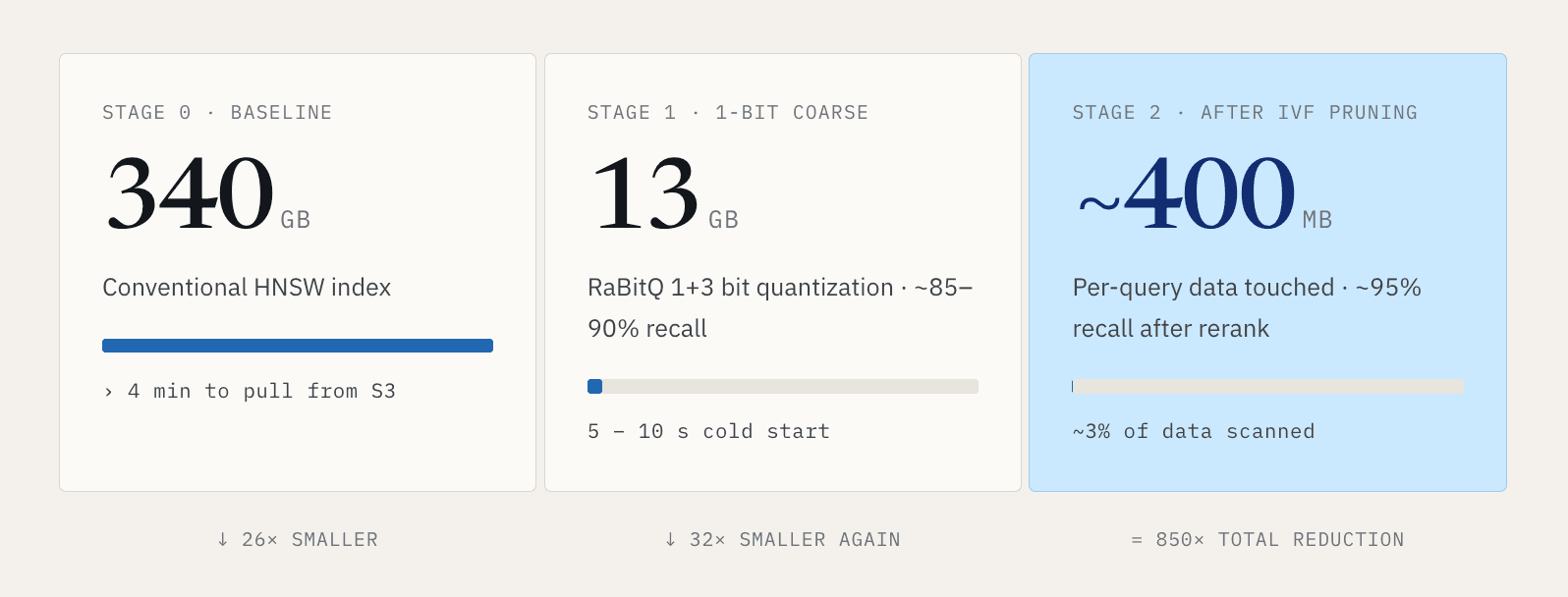
Utilizziamo poi il clustering IVF per ridurre la quantità di dati interessata da ogni query. In una configurazione rappresentativa, ogni query scansiona circa il 3 percento dei dati. Il percorso diventa: 340 GB di indice convenzionale, compressi a 13 GB, con una singola query che interessa circa 400 MB dopo il pruning.
Questa è la differenza tra la ricerca vettoriale elastica come idea e la ricerca vettoriale elastica come sistema utilizzabile.
Amplificazione I/O
Il cold start è solo un lato del problema. L’altro lato è l’accesso ai record.
La ricerca vettoriale restituisce ID. Ma le applicazioni hanno bisogno di record completi: frammenti di testo, metadati, puntatori ai documenti, permessi, timestamp, attributi delle immagini o altri campi. In un layout Parquet standard, una piccola lettura puntuale può costringere il sistema a scaricare un grande row group. Una query può aver bisogno solo di pochi kilobyte di dati utili ma finire per estrarre decine di megabyte dall’object storage. Ridurre i row group aiuta le letture puntuali, ma danneggia la compressione e l’efficienza delle scansioni.
Ecco perché abbiamo costruito Loon, il motore di storage ricostruito alla base di Zilliz Vector Lakebase.
Loon utilizza formati di file misti, allineamento delle righe e versioning basato su manifest. I campi scalari possono usare layout colonnari che rimangono efficienti per il filtering e le scansioni. I campi vettoriali e i dati con molte query puntuali possono usare layout più adatti al recupero a bassa latenza. I gruppi di colonne allineano gli ID di riga in modo che il sistema possa recuperare i campi di cui ha bisogno senza trascinare attraverso la rete grandi blocchi non correlati.
Sotto il cofano, Loon usa Vortex, un formato di file open-source sotto la Linux Foundation. Vortex supporta layout flessibili e codifiche annidate, incluse query puntuali senza decomprimere grandi blocchi irrilevanti.
In un test interno con 3 milioni di righe, vettori a 128 dimensioni, storage S3 e 256 reader concorrenti, le letture puntuali Parquet hanno scaricato circa 9,4 MB per lettura. Vortex ha scaricato circa 0,07 MB. Si tratta di una riduzione di 135 volte dei dati scaricati. Anche il throughput delle scansioni complete era più alto in quella configurazione.
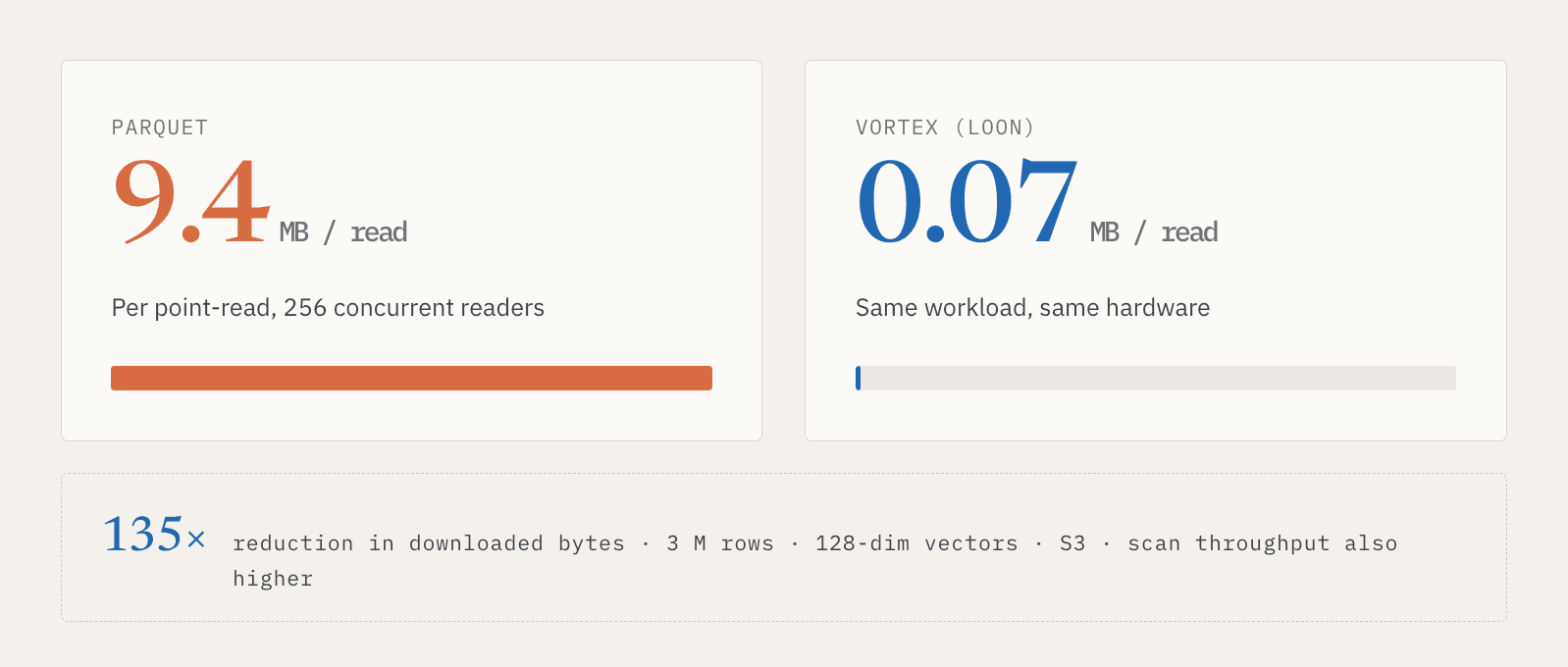
Il punto non è solo che un formato è più veloce per un benchmark. Il punto è che serving e discovery richiedono pattern di accesso diversi sugli stessi dati logici. I sistemi online hanno bisogno di letture puntuali rapide. I sistemi batch hanno bisogno di scansioni efficienti. Un Vector Lakebase deve supportare entrambi senza costringere gli utenti a mantenere due copie dei dati.
Vector Lakebase: un’unica base dati, più modalità di compute
Una volta che il layer dati è condiviso, il compute non può essere uguale per tutti.
I diversi workload di AI hanno forme molto diverse. Alcuni hanno bisogno di bassa latenza prevedibile tutto il giorno. Alcuni hanno bisogno di una sessione di ricerca interattiva per dieci minuti. Alcuni hanno bisogno di un grande job batch che viene eseguito durante la notte e poi scompare.
Ecco perché Zilliz Vector Lakebase supporta tre modalità di compute.
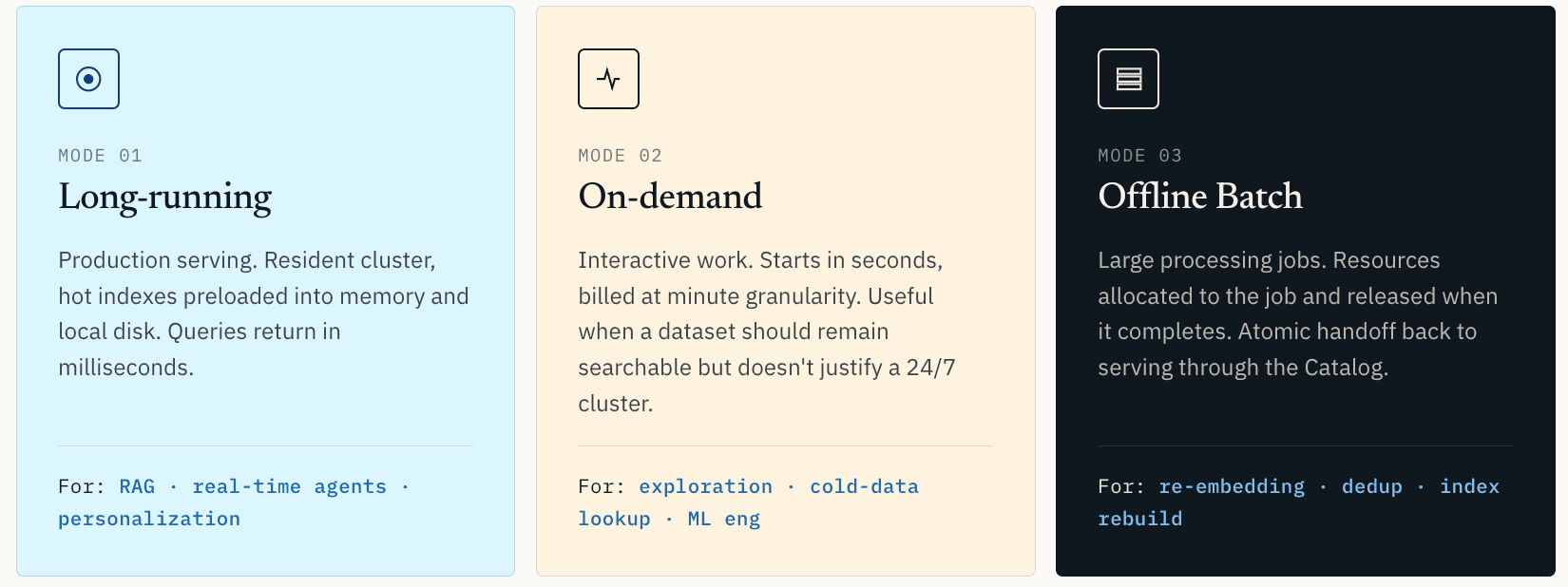
- Il compute long-running è per il serving in produzione. Il cluster rimane residente. Gli indici e i dati hot vengono precaricati in memoria e su disco locale. Le query rispondono in millisecondi. Questa è la modalità giusta per RAG in produzione, raccomandazioni in tempo reale, personalizzazione, agenti online e qualsiasi workload in cui la latenza faccia parte dell’esperienza utente.
- Il compute on-demand è per il lavoro interattivo. Si avvia in pochi secondi e viene fatturato con granularità al minuto. È utile per l’esplorazione di similarità, l’ispezione di anomalie, il recupero di cold data o i workflow di ML engineering in cui il dataset deve rimanere ricercabile ma non giustifica un cluster 24/7.
- Il compute Offline Batch è per grandi job di elaborazione: clustering vettoriale, deduplicazione dei dati di training, re-embedding completo, ricostruzione degli indici e scansioni della qualità dei dati. Le risorse vengono allocate al job e rilasciate quando il job è completato.
Il passaggio di consegne al serving avviene tramite il Catalog come nuovo snapshot. Il serving continua a leggere il vecchio snapshot finché i nuovi dati e indici non sono pronti. Poi la nuova versione diventa visibile in modo atomico. Quel passaggio atomico è importante. La discovery è utile solo se i miglioramenti possono rientrare in produzione senza esporre indici costruiti a metà o dati incoerenti.
 architecture.png
architecture.png
Un esempio di un cliente mostra perché la distinzione è importante. Un cliente nel settore della guida autonoma aveva un miliardo di vettori a 768 dimensioni, ma aveva bisogno solo di circa 20 minuti di tempo di query online al giorno. Eseguire il workload come cluster a lunga esecuzione costava circa $7.000 al mese. Spostarlo alla modalità on-demand ha ridotto il costo mensile a circa $500. Lo stesso cliente aveva un workflow di deduplicazione che in precedenza impiegava circa 70 ore per eseguire ricerche ANN una per una. Rielaborarlo come job batch offline ha ridotto il tempo di calcolo a circa 10 ore sulla stessa classe di risorse.

La lezione non è che una modalità di compute sia migliore di un’altra. La lezione è che i workload di dati per l’AI non hanno un’unica forma, e l’architettura non dovrebbe costringerli in una sola.
La pianificazione delle risorse diventa parte del Vector Lakebase
Le tre modalità di compute funzionano solo se la pianificazione delle risorse è elastica quanto il compute stesso.
Gli scheduler dei database tradizionali di solito presuppongono un pool fisso di macchine. Dati questi nodi, il sistema decide dove collocare i dati e come bilanciare i carichi. Quel modello funziona bene quando il workload è stabile. È poco adatto ai workload di AI che compaiono a raffiche: una sessione di ricerca on-demand, una breve ispezione di dati freddi, un job di deduplicazione notturno, poi ore di inattività.
In quel mondo, la domanda migliore non è solo dove dovrebbero essere eseguiti i dati. È se il compute debba essere in esecuzione o meno.
Ecco perché Vector Lakebase deve pianificare dati e risorse insieme. In pratica, questo significa mantenere un Warm Pool di nodi preparati, collegare rapidamente i dati quando arriva il lavoro, mantenere le risorse calde per poco tempo dopo la richiesta e rilasciarle quando non sono più utili.
Cambia anche l’economia. Non è la stessa cosa del pricing serverless per richiesta, e non è la stessa cosa della capacità mensile dedicata. Per molti workload di dati per l’AI, l’utilizzo a livello di minuto è l’unità più naturale: paghi per il compute mentre il ciclo è in esecuzione, poi lo lasci scomparire.
Dietro a questo c’è uno spostamento architetturale più ampio, da un control plane che gestisce un kernel per lo più statico a un kernel che comprende risorse, stato della cache, snapshot e costi. Questo merita un post a parte. Per questo articolo, il punto importante è più semplice: senza questo modello di risorse, Long-running, On-demand e Offline Batch sarebbero tre scelte di deployment separate, non tre parti dello stesso sistema di dati elastico.
External Collection: incontrare i dati dove già si trovano
C’è un’altra realtà per cui abbiamo dovuto progettare.
La maggior parte delle aziende dispone già di grandi quantità di dati non strutturati in ambienti lake: tabelle Lance, tabelle Iceberg, dataset Parquet e directory di object storage. Chiedere loro di spostare tutto in un nuovo sistema prima di poterlo usare non è realistico.
Ecco perché abbiamo creato External Collection all’interno di Zilliz Vector Lakebase. External Collection non è solo una mappatura zero-copy. Costruisce un livello di indicizzazione indipendente sopra dati esterni. I dati originali restano dove sono e rimangono governati dalla piattaforma esistente del cliente, mentre Zilliz costruisce e gestisce gli indici vettoriali, gli indici invertiti e gli indici JSON necessari per rendere quei dati ricercabili attraverso lo stesso percorso di retrieval dei dati nativi.
Il nostro principio interno è diventato semplice: Un dato. Un indice. Nessuno storage duplicato. Nessuna pipeline dual-write. Nessun percorso di discovery frammentato.
Questo significa che il ciclo CS/CD può coprire più dei dati già importati in un database vettoriale. Può includere gli asset di dati non strutturati che le aziende hanno già nei loro lake.
Cosa definisce la prima generazione di Vector Lakebase
Queste idee non sono solo architettura su carta. Le stiamo già distribuendo in Zilliz Vector Lakebase, e il processo di costruzione ha reso la nostra visione della categoria molto più concreta.
Un Vector Lakebase di prima generazione deve fare bene alcune cose contemporaneamente.

- Primo, separazione storage-compute con caching multi-livello. I dati risiedono nell'object storage, e il compute può scalare indipendentemente, anche fino a zero. Ma la separazione da sola non basta. La ricerca vettoriale online ha comunque bisogno di memoria, disco locale, nodi caldi ed esecuzione consapevole della cache per mantenere le query hot veloci a livello di ms.
- Secondo, gestione unificata per dati non strutturati multimodali. Il sistema dovrebbe gestire non solo i vettori, ma anche documenti sorgente, immagini, audio, video, embedding, metadati scalari, autorizzazioni e indici. Un sistema che archivia solo vettori è un servizio di indicizzazione, non una fondazione dati.
- Terzo, capacità native di database vettoriale. Ricerca ANN in millisecondi, gestione del ciclo di vita degli indici, ricerca ibrida, filtraggio scalare, recupero full-text, filtraggio JSON e molteplici metriche di similarità devono essere integrate. Collegare una Lakehouse a un database vettoriale esterno non elimina la frammentazione. Crea semplicemente un'altra pipeline.
- Quarto, molteplici modalità di compute. Serving online, interazione on-demand ed elaborazione batch offline devono operare sugli stessi dati logici. Il compute on-demand è particolarmente importante perché diventa il ponte tra il serving in produzione e l'elaborazione offline su larga scala.
- Quinto, formati aperti e nessuna migrazione forzata. Il livello di storage dovrebbe essere leggibile da engine esterni come Spark, Ray e Daft. Tabelle Iceberg esistenti, dataset Lance e file Parquet dovrebbero poter entrare nel sistema senza copie non necessarie. I dati appartengono all'utente, non all'engine.
- Sesto, le risorse dovrebbero seguire i dati. Il compute può scomparire quando non è necessario, mentre i metadati rimangono visibili e interrogabili. Una richiesta può riportare attive le risorse in pochi secondi. I tenant inattivi non dovrebbero pagare per compute dedicato che non stanno usando. Questo non è solo autoscaling; richiede che l'engine prenda decisioni sulle risorse insieme alle decisioni sui dati.
Queste sono le nostre convinzioni attuali, non l'ultima parola. Continueremo a rivederle man mano che il sistema maturerà. Ma una pressione sembra improbabile che cambi: i dati non strutturati continueranno a crescere, mentre i budget infrastrutturali non cresceranno allo stesso ritmo. Questo significa che i sistemi AI devono diventare più iterativi, più efficienti e più continuamente adattivi.
I database vettoriali non stanno scomparendo
Quindi, tornando alla domanda originale: questo significa che i database vettoriali stanno per sparire? Niente affatto.
Semmai, il recupero semantico diventa più importante in questa architettura. Ma il suo ruolo cambia.
I database vettoriali diventano l'engine di serving all'interno di un sistema di dati non strutturati più ampio, proprio come i database transazionali sono rimasti essenziali all'interno della più ampia era Lakehouse. I sistemi OLTP non sono stati sostituiti dalle Lakehouse. Sono diventati un livello all'interno di uno stack architetturale più ampio. Credo che i database vettoriali stiano attraversando ora la stessa transizione.
Il cambiamento più ampio che sta avvenendo sotto l'infrastruttura AI non riguarda semplicemente il recupero. Riguarda la costruzione di cicli operativi continui attorno ai dati non strutturati stessi. Il serving genera feedback. La scoperta migliora la qualità dei dati. Quei miglioramenti ritornano in produzione. Ogni giro del ciclo rende il sistema migliore.
Tutto il resto, inclusi formati di archiviazione, gerarchie di caching, sistemi di indicizzazione, modelli di calcolo elastico e pianificazione delle risorse, esiste per rendere quel volano economicamente sostenibile su larga scala.
Non sappiamo ancora esattamente cosa diventerà Vector Lakebase nei prossimi cinque anni. Quando abbiamo iniziato Milvus quasi un decennio fa, non avremmo nemmeno potuto prevedere dove avrebbero portato gli stessi database vettoriali.
Ma una cosa ora sembra chiara. I dati non strutturati continueranno a crescere. I modelli continueranno a cambiare. Gli agenti genereranno più tracce, feedback e stato. I team dovranno migliorare i propri dati più velocemente senza lasciare che i costi dell'infrastruttura crescano senza limiti.
I sistemi che avranno successo saranno quelli che faranno sembrare il serving continuo e la discovery continua parte della stessa macchina. Questa è la direzione verso cui stiamo costruendo.
Zilliz Vector Lakebase è disponibile in anteprima pubblica
Abbiamo lanciato l'anteprima pubblica di Zilliz Vector Lakebase — una grande evoluzione di Zilliz Cloud da database vettoriale gestito a piattaforma dati semantica unificata, che combina il serving vettoriale a bassa latenza con l'apertura, la scalabilità e l'economicità di un data lake.
Funzionalità principali di Zilliz Vector Lakebase:
- Serving a livelli ottimizzato per diversi compromessi prestazioni-costo in tempo reale
- Ricerca on-demand per carichi di lavoro su larga scala o esplorativi senza calcolo sempre attivo
- Ricerca su data lake esterni — indicizza e cerca direttamente sui dati del tuo lake esistente
- Ricerca full-spectrum su vettori, testo, JSON e dati geospaziali con retrieval ibrido e reranking
- Archiviazione unificata lake-native basata su Vortex, un formato aperto con letture casuali più veloci ed economiche rispetto a Lance o Parquet
Se il tuo stack attuale separa serving e discovery in sistemi distinti, potrebbe valere la pena dare un'occhiata a Vector Lakebase. Provalo su Zilliz Cloud — le nuove registrazioni con email di lavoro ricevono $100 di crediti gratuiti — oppure parla con noi del tuo caso d'uso.
Nota: I dati su prestazioni e costi in questo articolo provengono dai risultati open source di VectorDB Benchmark, da test interni e da scenari cliente anonimizzati. I risultati effettivi variano in base a scala dei dati, distribuzione, parametri dell'indice, forma del carico di lavoro e configurazione delle risorse.

Continua a leggere

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.