




L’interruzione di AWS è stata un campanello d’allarme per il disaster recovery cross-region dei database vettoriali
Le regioni cloud falliscono. Non è una questione di se — è una questione di quando e di quanto gravemente.
La scorsa settimana, due regioni AWS in Medio Oriente sono andate offline a causa di danni fisici all'infrastruttura dei data center. Due delle tre availability zone nella regione UAE di AWS (ME-CENTRAL-1) sono state messe fuori uso, e una struttura in Bahrain (ME-SOUTH-1) è stata danneggiata. Oltre 60 servizi AWS sono stati impattati, inclusi Lambda, EKS, VPC, S3 e CloudWatch. Careem, la più grande piattaforma di ride-hailing della regione, ha perso il servizio. Alaan, un importante provider di pagamenti, è andato offline. AWS ha consigliato ai clienti di spostare i workload verso altre regioni—ma non si è trattato di un incidente risolvibile con un riavvio e ripristino. Con la sostituzione dell'hardware e la riparazione della struttura, il recupero può richiedere settimane.
E il danno fisico è solo una modalità di guasto. Negli ultimi 12 mesi, una modifica di configurazione difettosa ha mandato giù la regione Central US di Azure per 14,5 ore. Un bug in Google Cloud ha messo fuori uso simultaneamente Cloud Run, GKE e Firebase per 8 ore. Un aggiornamento software difettoso di CrowdStrike — nemmeno un problema di un cloud provider — si è propagato attraverso l'infrastruttura ospitata su Azure, costando alle aziende Fortune 500 circa 5,4 miliardi di dollari.
Il report 2025 dell'Uptime Institute colloca il costo mediano di un'interruzione ad alto impatto a 2 milioni di dollari all'ora, circa il doppio rispetto a tre anni fa. Eppure il Data Protection Trends Report 2024 di Veeam ha rilevato che solo il 13% delle organizzazioni è effettivamente in grado di orchestrare il ripristino durante un vero disastro.
Questi numeri erano già allarmanti. Poi l'AI ha alzato la posta.
Quando l'AI va giù, i team non rallentano — si fermano
Cinque anni fa, un guasto cloud regionale danneggiava principalmente le app rivolte ai clienti. Doloroso, ma la maggior parte dei team poteva ancora funzionare internamente. Oggi, l'AI ha assorbito attività che attraversano interi dipartimenti—code review, documentazione, triage del supporto e persino analisi di routine. Con quasi il 60% dei dipendenti che usa l'AI nei flussi di lavoro quotidiani, le interruzioni non causano un rallentamento graduale. La produttività precipita.
Lo abbiamo già visto accadere — ChatGPT e Claude hanno entrambi subito interruzioni significative all'inizio del 2026, lasciando milioni di utenti e team enterprise senza gli strumenti di AI attorno ai quali avevano costruito i propri flussi di lavoro.
Ma ecco cosa la maggior parte dei team trascura. Le interruzioni dei modelli sono dirompenti, ma i modelli sono in gran parte stateless: i provider spesso possono reinstradare il traffico di inferenza verso regioni sane relativamente rapidamente. Il problema più difficile è il livello dati sottostante—i database, gli object store e gli indici vettoriali che forniscono memoria e contesto. Quel livello è stateful, vincolato alla regione e molto più difficile da ripristinare. Quando va giù, il tuo LLM può ancora generare testo—ma senza il contesto giusto, torna a un output generico e incline alle allucinazioni. L'AI non va semplicemente offline. Diventa inaffidabile.
Il database vettoriale è la memoria a lungo termine della tua AI — ed è probabilmente single-region
I database vettoriali sono diventati la spina dorsale dell'AI enterprise. Le pipeline RAG e gli agenti AI recuperano contesto da essi. I motori di raccomandazione li interrogano. La ricerca semantica viene eseguita su di essi. Quando questo livello non è disponibile, ogni applicazione costruita sopra di esso si rompe — non parzialmente, ma completamente.
E a differenza dei servizi stateless, il ripristino non è semplice:
- Le ricostruzioni degli indici sono lente. La ricerca vettoriale dipende da strutture di indice come i grafi HNSW, in cui il tempo di ricostruzione cresce in modo non lineare con la dimensione del dataset. Ricostruire un indice su oltre 100 milioni di vettori può richiedere più di 18 ore su compute standard.
- Le connection string sono ovunque. Ogni applicazione che si connetteva al vecchio cluster deve avere il proprio endpoint aggiornato — tra configurazioni, variabili d'ambiente, pipeline CI/CD, spesso gestite da team diversi.
- Deriva del modello di embedding. Se non riesci a individuare la versione esatta del modello di embedding che ha generato i tuoi vettori attuali, potresti dover ri-embeddare l'intero dataset.
Per un'interruzione del software, si aspetta un riavvio. Ma quando un data center viene danneggiato fisicamente, il ripristino richiede settimane. L'unica strategia praticabile è disporre già di una replica live, indicizzata e pronta per le query, servita da un'altra regione — con un reindirizzamento del traffico che non richiede alcuna modifica al codice.
Zilliz Cloud: il primo database vettoriale al mondo con disaster recovery cross-region nativo
Zilliz Cloud è il primo database vettoriale al mondo a offrire disaster recovery cross-region nativo — con failover automatizzato, replica in tempo reale e un endpoint globale che non richiede modifiche all'applicazione durante le transizioni di regione.
Forniamo due funzionalità complementari: Global Cluster per il failover in tempo reale e Cross-Region Backup per un disaster recovery conveniente.
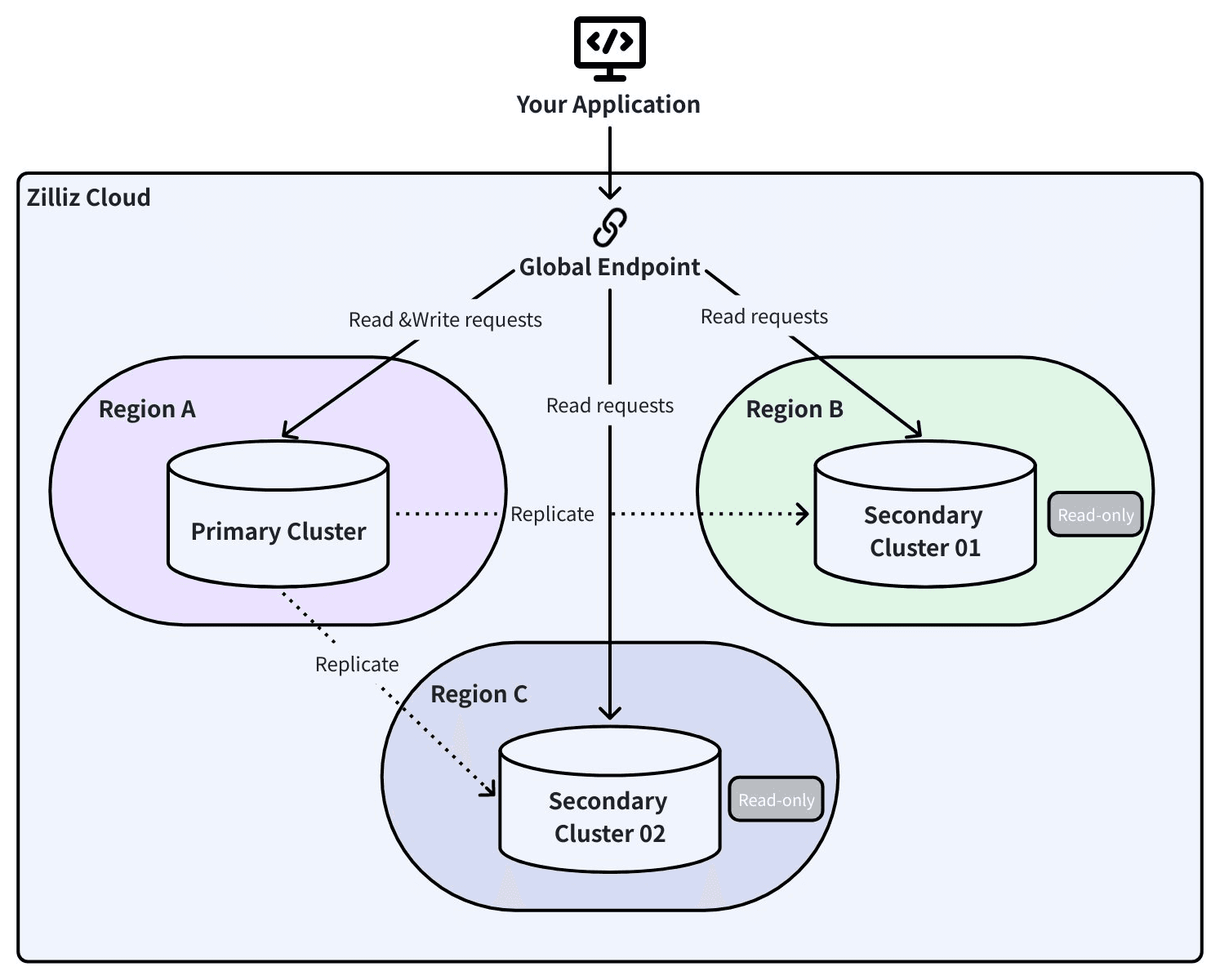
Global Cluster: replica live con failover automatico
Global Cluster utilizza Change Data Capture (CDC) per replicare continuamente i dati tra un cluster primario e uno secondario in una regione diversa. Non snapshot periodici — ogni inserimento, aggiornamento ed eliminazione si propaga in tempo reale.
- Switchover pianificato (manutenzione, migrazione, conformità): il sistema svuota i messaggi CDC in transito, conferma la piena sincronizzazione, quindi scambia i ruoli. L'RPO è zero. L'RTO è inferiore a 30 secondi.
- Failover automatico (guasto imprevisto della regione): il secondario si promuove automaticamente. L'RPO equivale al ritardo CDC al momento del guasto — in genere pochi secondi. L'RTO è inferiore a 60 secondi.
Una funzionalità unica: dopo un failover, il vecchio primario non scompare semplicemente. Va in un cestino con conservazione di 7 giorni, e un'API di streaming chiamata DumpMessages consente di recuperare eventuali scritture arrivate sul vecchio primario ma non ancora replicate. Invece di accettare la perdita di dati, ottieni una finestra per recuperarli.
Global Endpoint: una connessione, ogni regione
È qui che l'architettura dà i suoi frutti in uno scenario di disastro fisico.
La tua applicazione si connette a un singolo endpoint globale. Dietro di esso, i record DNS SRV tengono traccia di quale cluster è primario e quale è secondario. Quando si verifica un failover, l'SDK rileva il cambiamento di topologia e reindirizza automaticamente il traffico. Nessun aggiornamento della stringa di connessione. Nessun riavvio dell'applicazione. Nessuna modifica al codice.
Pensa a cosa significa durante un'interruzione regionale prolungata. Senza un endpoint globale, il ripristino richiede che qualcuno trovi una runbook, riconfiguri manualmente i client, aggiorni le stringhe di connessione e coordini i team — alle 3 del mattino, sotto pressione. Il tuo RTO non si misura in secondi; si misura nel tempo necessario per chiamare l'ingegnere giusto.
Con Global Endpoint, la tua pipeline RAG interroga la replica in un'altra regione entro 60 secondi, senza modificare una sola riga di codice.
Cross-Region Backup: resilienza senza il costo di una replica live
Non ogni workload giustifica l'esecuzione di un cluster secondario. Cross-Region Backup replica i dati di backup in una o più regioni di destinazione, ciascuna con la propria policy di conservazione. Quando si verifica un guasto a livello di regione, avvii un nuovo cluster da qualsiasi punto di backup nella regione di destinazione — nessun trasferimento di dati cross-region necessario durante la crisi, perché i dati sono già lì.
Il compromesso:
- Global Cluster → RPO in secondi, RTO inferiore a 60 secondi. Per workload che non possono tollerare alcun downtime.
- Cross-Region Backup → RPO e RTO in ore. Per workload in cui la sopravvivenza dei dati conta più del ripristino istantaneo.
Molti team iniziano con Cross-Region Backup per la garanzia critica — i tuoi dati sopravvivono a un guasto della regione — e passano a Global Cluster man mano che i loro workload di IA diventano mission-critical.
Come altri database vettoriali gestiscono il DR cross-region
La maggior parte dei database vettoriali offre alta disponibilità all’interno di una singola regione tramite set di repliche e ridondanza dei nodi. Questo gestisce i guasti dei nodi, non i guasti regionali. Zilliz Cloud è l’unico database vettoriale che offre failover cross-region automatizzato nativo con un cluster globale e un endpoint globale: transizioni tra regioni senza downtime e senza modifiche al codice.
| Funzionalità | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| Replica cross-region | ✅ Basata su CDC, in tempo reale | ❌ | ❌ | ❌ | ❌ |
| Failover non pianificato | ✅ RPO ≈ secondi, RTO<= 30s | ❌ | ❌ | ❌ | ❌ |
| Switchover pianificato | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| Recupero dei dati post-failover | ✅ Recupero automatico dei dati non sincronizzati. | ❌ | ❌ | ❌ | ❌ |
| Endpoint globale | ✅ Un endpoint globale, reindirizzamento automatico senza modifiche al codice | ❌ | ❌ | ❌ | ❌ |
| RPO/RTO in caso di guasto regionale | ✅ RPO ≈ secondi, RTO < 30s | ❌ | ❌ | ❌ | ❌ |
| Backup cross-region automatico | ✅ QUALSIASI regione con conservazione per regione | ❌ | ❌ | ❌ | ❌ |
Oltre il Disaster Recovery
I team utilizzano inoltre Global Cluster per scenari operativi che non hanno nulla a che fare con le interruzioni:
- Ottimizzazione della latenza: Aggiungi una regione secondaria più vicina ai tuoi utenti per tempi di risposta alle query inferiori a 100 ms.
- Migrazione regionale: Sposta i workload tra regioni senza downtime durante il consolidamento dell’infrastruttura.
- Conformità alla residenza dei dati: Mantieni i dati entro specifici confini geografici per soddisfare i requisiti normativi.
La stessa pipeline CDC che protegge dalle interruzioni ti offre anche una replica leggibile più vicina ai tuoi utenti: la capacità di DR come effetto collaterale dell’ottimizzazione delle prestazioni.
Per iniziare
Global Cluster e Cross-Region Backup sono disponibili su Zilliz Cloud per cluster dedicati.
- Se hai già un account Zilliz Cloud, semplicemente accedi e inizia subito a usare le nuove funzionalità—non sono necessari upgrade o migrazioni.
- Sei nuovo su Zilliz Cloud? Registrati gratis e ottieni \$100 in crediti per provare il database vettoriale gestito leader mondiale.
- Hai domande su uno qualsiasi degli aggiornamenti? Consulta la più recente documentazione o contatta Zilliz Support—siamo qui per aiutarti.
Crea senza limiti: uno sguardo più da vicino alle funzionalità enterprise-ready di Zilliz Cloud
Global Cluster è un elemento di una piattaforma più ampia progettata per l’AI su scala di produzione. Zilliz Cloud offre anche:
- Scalabilità elastica ed efficienza dei costi – Deployment con un clic, autoscaling serverless e prezzi pay-as-you-go.
- Ricerca AI avanzata – Ricerca vettoriale, full-text e ibrida (sparsa + densa) con filtraggio dei metadati, schema dinamico e multi-tenancy.
- Sicurezza di livello enterprise – SLA del 99,95%, certificazioni SOC 2 Type II e ISO 27001, conformità GDPR, predisposizione HIPAA, RBAC, BYOC e audit log. Consulta il nostro trust center per maggiori informazioni.
- Disponibilità globale – Deployment su AWS, GCP e Azure con latenza inferiore a 100 ms in tutto il mondo.
- Migrazione senza interruzioni – Strumenti integrati per migrare da Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate o Milvus on-prem.
- Query in linguaggio naturale – Supporto server MCP per query intuitive senza API complesse.
- E molto altro!

Continua a leggere

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.