




RAG multimodale a livello locale con CLIP e Llama3
Con il recente rilascio di GPT-4o e Gemini, il multimodale è stato un argomento molto caldo negli ultimi tempi. Un altro che è stato in cima alla classifica è Retrieval Augmented Generation (RAG) da un anno a questa parte, ma si è concentrato soprattutto sul testo. Questa esercitazione mostra come costruire un sistema RAG multimodale.
Utilizzando il RAG multimodale, non è necessario utilizzare solo il testo; è possibile utilizzare diversi tipi di dati, come immagini, audio, video e, naturalmente, testo. È anche possibile restituire diversi tipi di dati; solo perché si usa il testo come input per il sistema RAG, non significa che si debba restituire il testo come output. Lo dimostreremo nel corso di questa esercitazione.
Prerequisiti
Prima di iniziare a configurare i diversi componenti della nostra esercitazione, assicuratevi che il vostro sistema abbia i seguenti requisiti:
Docker e Docker-Compose-Assicurarsi che Docker e Docker-Compose siano installati sul sistema.
Milvus Standalone-Per i nostri scopi, utilizzeremo l'efficiente Milvus Standalone, che è facilmente gestibile tramite Docker Compose; esplorate la nostra documentazione per le indicazioni sull'installazione.
Ollama-Installare Ollama sul sistema. Questo ci permetterà di usare Llama3 sul nostro portatile. Visitate il loro sito web per la guida all'installazione più recente.
CLIP OpenAI
L'idea alla base del modello CLIP (Contrastive Language-Image Pretraining) è quella di comprendere la connessione tra un'immagine e un testo. Si tratta di un modello fondamentale di intelligenza artificiale addestrato su coppie testo-immagine. Impara quindi a creare un punto nello spazio vettoriale sia per il testo che per le immagini. In questo spazio, descrizioni di testo simili saranno vicine a immagini rilevanti e viceversa.
CLIP può essere utilizzato per diverse applicazioni, tra cui:
Recupero di immagini: Immaginate di cercare immagini utilizzando una descrizione testuale o di trovare la didascalia perfetta da abbinare a un'immagine.
Apprendimento multimodale**: la forza di CLIP nel collegare testo e immagini lo rende un elemento perfetto per sistemi come RAG multimodale, che trattano informazioni in formati diversi.
Ciò consente al nostro sistema RAG di comprendere e rispondere a richieste che possono riguardare sia il testo che le immagini.
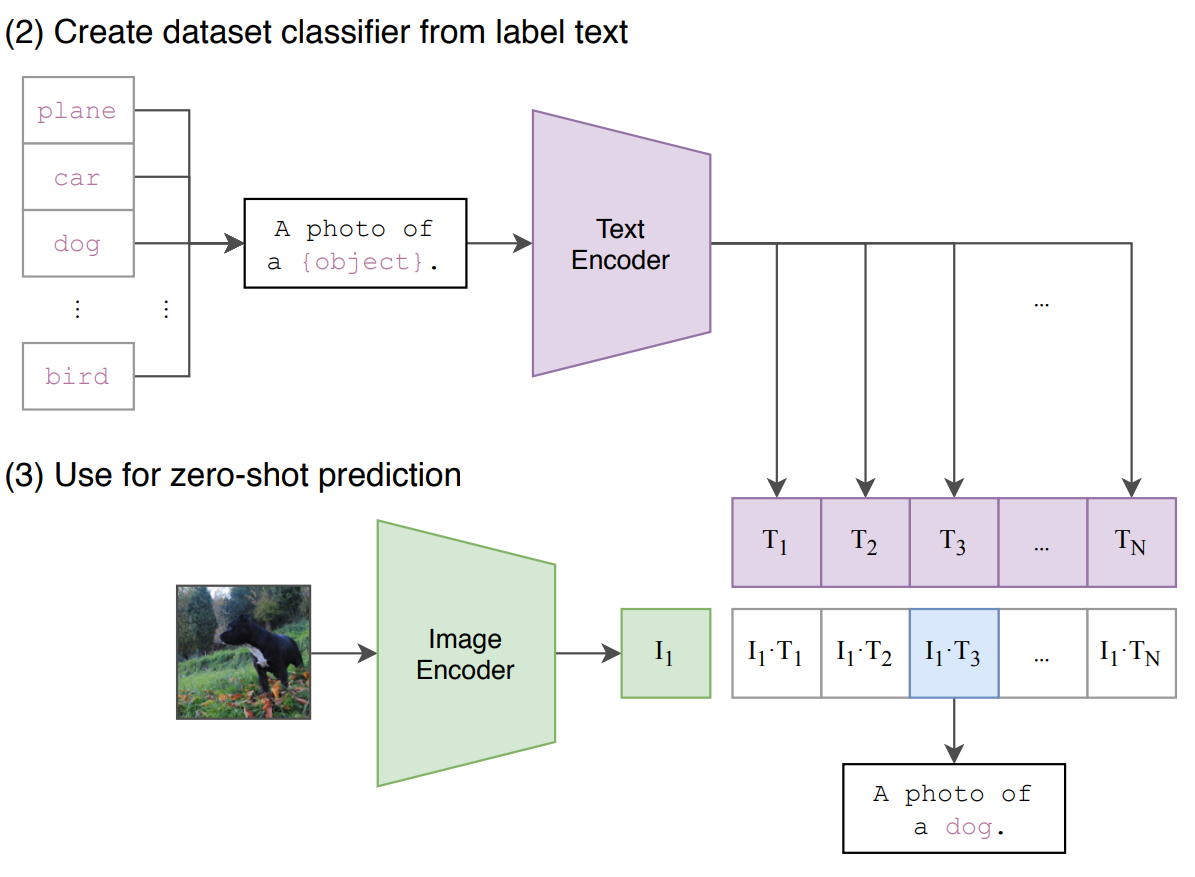 Fig1: Architettura di OpenAI CLIP
Fig1: Architettura di OpenAI CLIP
Incorporazioni multimodali
**In termini più semplici, le incorporazioni sono rappresentazioni compresse di dati. CLIP prende in input un'immagine o un testo e lo trasforma in un codice numerico che ne cattura le caratteristiche principali.
Il bello di CLIP è che funziona sia con il testo che con le immagini. È possibile fornire un'immagine e il programma genererà un incorporamento che cattura il contenuto visivo. Tuttavia, è anche possibile fornire un testo e CLIP genererà un incorporamento che riflette il significato del testo.
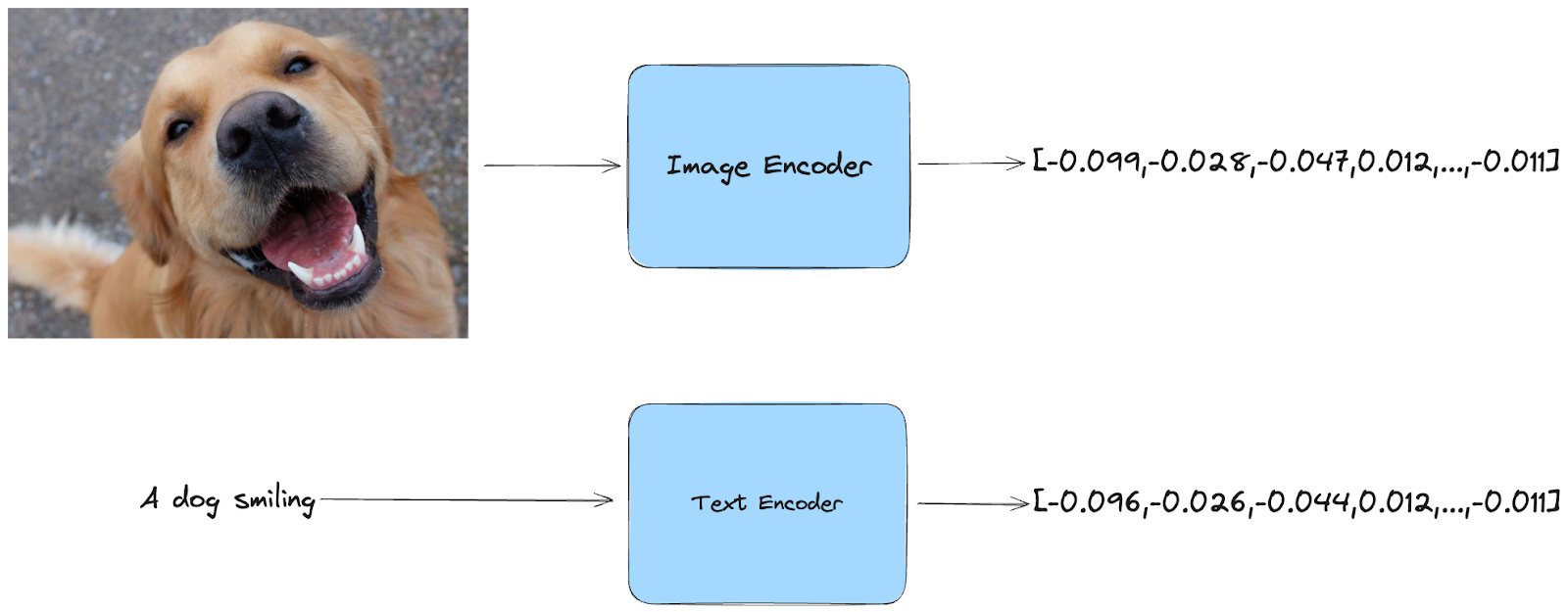 Incorporazioni multimodali
Incorporazioni multimodali
Se si immagina una proiezione nello spazio vettoriale, si avranno embeddings con significati simili vicini tra loro. Ad esempio, il testo "Un cane che sorride" e l'immagine di un cane che sembra sorridere sono vicini.
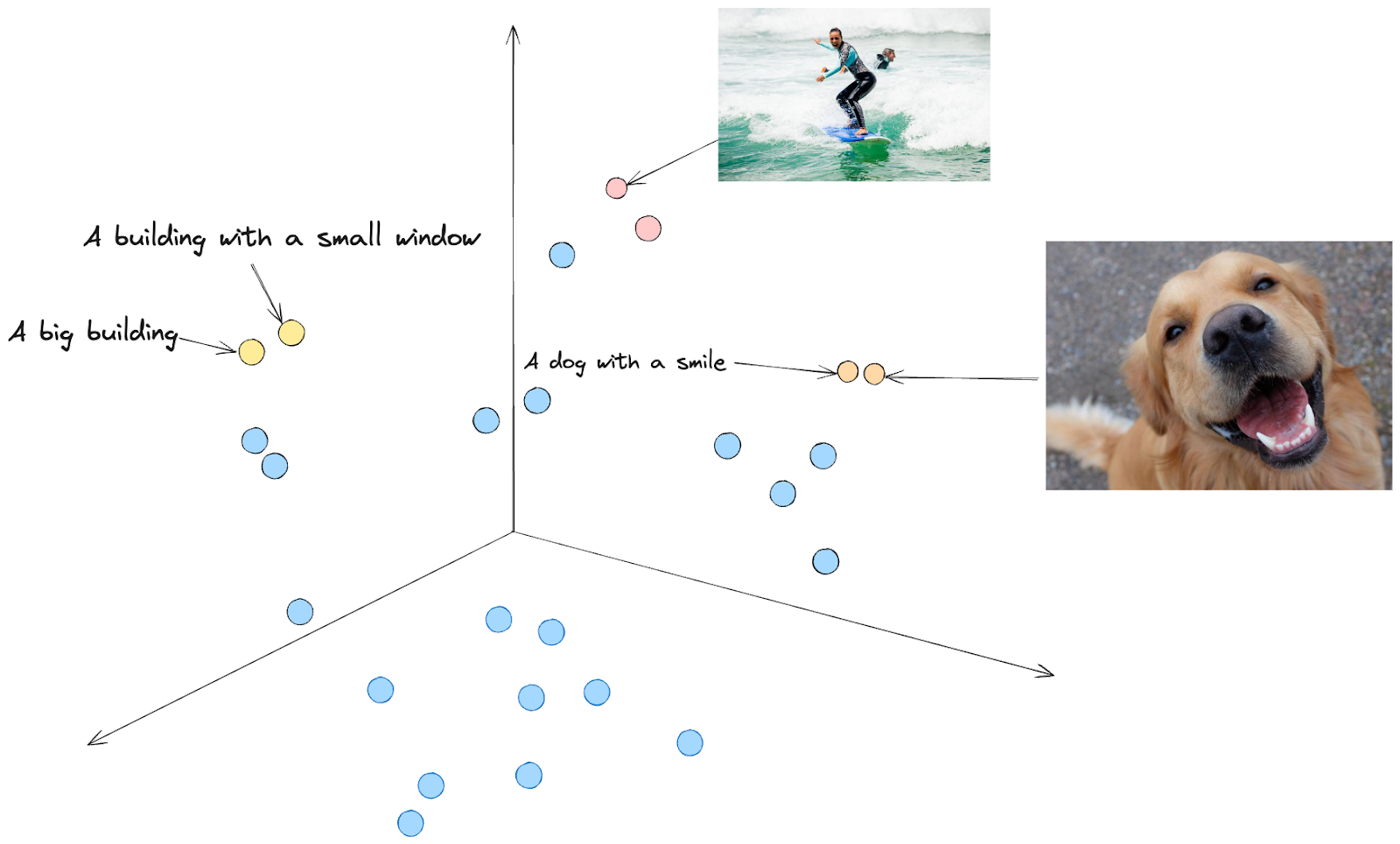 Fig2. Rappresentazione in uno spazio vettoriale
Fig2. Rappresentazione in uno spazio vettoriale
Costruire una RAG multimodale
Utilizzeremo i dati di Wikipedia, scaricheremo i dati di testo associati a ciò che vogliamo approfondire e faremo lo stesso con le immagini.
Genereremo Embeddings con il modello CLIP ViT-B/32 e useremo Llama3 come LLM.
Memorizziamo gli embeddings in Milvus, che è stato progettato per gestire embeddings su larga scala in modo da poter effettuare una ricerca rapida ed efficiente.
LlamaIndex è utilizzato come motore di interrogazione in combinazione con Milvus come archivio vettoriale.
L'intero codice è piuttosto lungo, in quanto occorre sfogliare Wikipedia, elaborare il testo e le immagini e quindi creare un'applicazione RAG. Tuttavia, è completamente disponibile su Github, quindi dovreste assolutamente dargli un'occhiata!
Una volta che il programma funziona, dovreste essere in grado di eseguire query simili alle seguenti:
# https://en.wikipedia.org/wiki/Helsinki
query2 = "Quali sono le attrazioni turistiche più popolari di Helsinki?"
# genera i risultati del recupero delle immagini
image_query(query2)
# generare i risultati del reperimento del testo
risultati_di_recupero_testo = text_query_engine.query(query2)
print("Risultati del recupero del testo: \´n" + str(risultati_testo_recupero))
Che dovrebbe restituire qualcosa di simile a
Tra le attrazioni turistiche più popolari di Helsinki vi sono Suomenlinna (Sveaborg), un'isola-fortezza con una ricca storia, e lo zoo di Korkeasaari, situato su una delle isole principali di Helsinki. Inoltre, la città possiede molte riserve naturali, tra cui Vanhankaupunginselkä, la più grande riserva naturale di Helsinki.

In questo modo si ottiene un'applicazione RAG multimodale, in grado di elaborare immagini o testo e di restituire immagini o testo.
Potete accedere al codice su Github, sentirvi liberi di fare domande sul nostro Discord e darci una stella su Github.

Continua a leggere

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Creating Collections in Zilliz Cloud Just Got Way Easier
We've enhanced the entire collection creation experience to bring advanced capabilities directly into the interface, making it faster and easier to build production-ready schemas without switching tools.

OpenAI o1: What Developers Need to Know
In this article, we will talk about the o1 series from a developer's perspective, exploring how these models can be implemented for sophisticated use cases.