




Chiamata di funzione con Ollama, Llama 3.2 e Milvus
Aggiornato il 25 settembre 2024 con Llama 3.2.
Chiamare funzioni con gli LLM significa dare alla propria IA il potere di connettersi con il mondo. Integrando il vostro LLM con strumenti esterni come le funzioni definite dall'utente o le API, potete costruire applicazioni che risolvono problemi reali.
In questo blog post, vedremo come integrare Llama 3.2 con strumenti esterni come Milvus e API per costruire applicazioni potenti e consapevoli del contesto.
Introduzione alla chiamata di funzione
Gli LLM come GPT-4, Mistral Nemo e Llama 3.2 sono ora in grado di rilevare quando devono chiamare una funzione e di produrre JSON con gli argomenti per chiamarla. Questo rende le applicazioni di intelligenza artificiale più versatili e potenti.
Le chiamate funzionali consentono agli sviluppatori di creare:
Soluzioni basate su LLM per l'estrazione e l'etichettatura dei dati (ad esempio, l'estrazione dei nomi delle persone da un articolo di Wikipedia).
applicazioni che possono aiutare a convertire il linguaggio naturale in chiamate API o in query valide per i database
motori di recupero della conoscenza conversazionale che interagiscono con una base di conoscenza
Gli strumenti
Ollama: Porta la potenza degli LLM sul vostro portatile, semplificando le operazioni locali.
Milvus: Il nostro database vettoriale di riferimento per l'archiviazione e il recupero efficiente dei dati.
Lama 3.2-3B: La versione aggiornata del modello 3.1, è multilingue e ha una lunghezza di contesto significativamente più lunga di 128K, e può sfruttare l'uso di strumenti.
Utilizzo di Llama 3.2 e Ollama
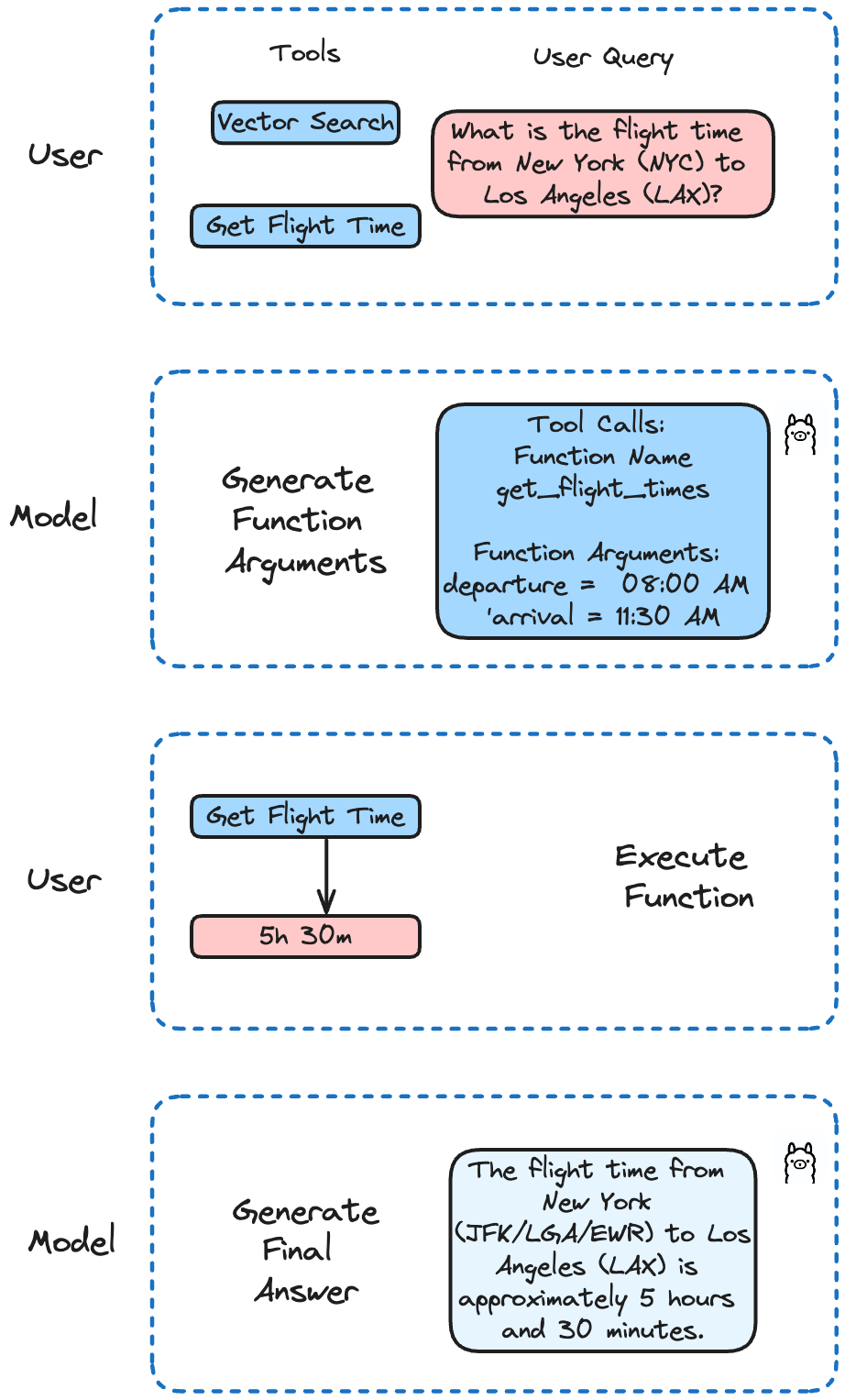
Llama 3.2 è stato perfezionato per quanto riguarda le chiamate di funzione. Supporta chiamate di funzioni singole, annidate e parallele, nonché chiamate di funzioni a più giri. Ciò significa che l'intelligenza artificiale può gestire compiti complessi che comportano più fasi o processi paralleli.
Nel nostro esempio, implementeremo diverse funzioni per simulare una chiamata API per ottenere gli orari dei voli ed eseguire ricerche in Milvus. Llama 3.2 deciderà quale funzione chiamare in base alla richiesta dell'utente.
Installare le dipendenze
Per prima cosa, prepariamo tutto. Scaricare Llama 3.2 usando Ollama:
ollama run llama3.2
Questo scaricherà il modello sul portatile, rendendolo pronto per l'uso con Ollama. Quindi, installate le dipendenze necessarie:
pip install ollama openai "pymilvus[modello]"
Stiamo installando Milvus Lite con l'estensione model, che consente di incorporare i dati utilizzando i modelli disponibili in Milvus.
Inserire i dati in Milvus
Ora inseriamo alcuni dati in Milvus. Questi sono i dati che Llama 3.2 deciderà di cercare in seguito, se li riterrà rilevanti!
Creare e inserire i dati
da pymilvus import MilvusClient, model
embedding_fn = model.DefaultEmbeddingFunction()
docs = [
"L'intelligenza artificiale è stata fondata come disciplina accademica nel 1956",
"Alan Turing è stato il primo a condurre una ricerca sostanziale sull'intelligenza artificiale",
"Nato a Maida Vale, Londra, Turing è cresciuto nel sud dell'Inghilterra",
]
vettori = embedding_fn.encode_documents(docs)
# Il vettore di output ha 768 dimensioni, che corrispondono all'insieme appena creato.
print("Dim:", embedding_fn.dim, vectors[0].shape) # Dim: 768 (768,)
# Ogni entità ha un id, una rappresentazione vettoriale, un testo grezzo e un'etichetta di soggetto.
dati = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "storia"}
per i in range(len(vectors))
]
print("I dati hanno", len(data), "entità, ciascuna con campi: ", data[0].keys())
print("Dimensioni del vettore:", len(dati[0]["vettore"]))
# Creare una collezione e inserire i dati
client = MilvusClient('./milvus_local.db')
client.create_collection(
collection_name="demo_collection",
dimension=768, # I vettori che useremo in questa dimostrazione hanno 768 dimensioni
)
client.insert(collection_name="demo_collection", data=data)
Si dovrebbero avere 3 elementi nella nuova collezione.
Definire le funzioni da utilizzare
In questo esempio, definiamo due funzioni. La prima simula una chiamata API per ottenere gli orari dei voli. La seconda esegue una ricerca in Milvus.
da pymilvus import model
importare json
importare ollama
embedding_fn = model.DefaultEmbeddingFunction()
# Simula una chiamata API per ottenere i tempi di volo
# In un'applicazione reale, questa operazione recupererebbe i dati da un database o da un'API in tempo reale.
def get_flight_times(departure: str, arrival: str) -> str:
voli = {
'NYC-LAX': {'partenza': '08:00 AM', 'arrivo': '11:30 AM', 'durata': '5h 30m'},
LAX-NYC': {'partenza': '02:00 PM', 'arrivo': '10:30 PM', 'durata': '5h 30m'},
'LHR-JFK': {'partenza': '10:00 AM', 'arrivo': '01:00 PM', 'durata': '8h 00m'},
'JFK-LHR': {'partenza': '09:00 PM', 'arrivo': '09:00 AM', 'durata': '7h 00m'},
'CDG-DXB': {'partenza': '11:00 AM', 'arrivo': '08:00 PM', 'durata': '6h 00m'},
'DXB-CDG': {'partenza': '03:00 AM', 'arrivo': '07:30 AM', 'durata': '7h 30m'},
}
key = f'{partenza}-{arrivo}'.upper()
return json.dumps(flights.get(key, {'error': 'Flight not found'}))
# Ricerca di dati relativi all'Intelligenza Artificiale in un database vettoriale
def search_data_in_vector_db(query: str) -> str:
query_vectors = embedding_fn.encode_queries([query])
res = client.search(
collection_name="demo_collection",
dati=query_vettori,
limit=2,
output_fields=["text", "subject"], # specifica i campi da restituire
)
print(res)
return json.dumps(res)
Dare le istruzioni al LLM per poter usare queste funzioni
Ora, diamo le istruzioni all'LLM in modo che possa usare le funzioni che abbiamo definito.
def run(model: str, question: str):
client = ollama.Client()
# Inizializza la conversazione con una domanda dell'utente
messaggi = [{"role": "user", "content": question}]
# Prima chiamata API: Invia la query e la descrizione della funzione al modello
response = client.chat(
modello=modello,
messaggi=messaggi,
strumenti=[
{
"type": "function",
"function": {
"name": "get_flight_times",
"description": "Ottieni gli orari dei voli tra due città",
"parameters": {
"type": "object",
"properties": {
"partenza": {
"tipo": "stringa",
"description": "La città di partenza (codice aeroporto)",
},
"arrivo": {
"tipo": "stringa",
"description": "La città di arrivo (codice aeroporto)",
},
},
"required": ["partenza", "arrivo"],
},
},
},
{
"tipo": "function",
"function": {
"nome": "search_data_in_vector_db",
"description": "Ricerca di dati sull'intelligenza artificiale in un database vettoriale",
"parametri": {
"tipo": "object",
"properties": {
"query": {
"type": "string",
"description": "La query di ricerca",
},
},
"required": ["query"],
},
},
},
],
)
# Aggiungere la risposta del modello alla cronologia della conversazione
messages.append(response["message"])
# Verificare se il modello ha deciso di usare la funzione fornita
if not response["message"].get("tool_calls"):
print("Il modello non ha usato la funzione. La sua risposta è stata:")
print(risposta["messaggio"]["contenuto"])
restituire
# Elaborare le chiamate di funzione effettuate dal modello
if response["message"].get("tool_calls"):
available_functions = {
"get_flight_times": get_flight_times,
"search_data_in_vector_db": search_data_in_vector_db,
}
per strumento in response["message"]["tool_calls"]:
function_to_call = available_functions[tool["function"]["name"]]
function_args = tool["function"]["arguments"]
function_response = function_to_call(**function_args)
# Aggiungere la risposta della funzione alla conversazione
messages.append(
{
"role": "tool",
"content": function_response,
}
)
# Seconda chiamata API: Ottenere la risposta finale dal modello
final_response = client.chat(model=modello, messages=messaggi)
print(final_response["message"]["content"])
Esempio di utilizzo
Verifichiamo se è possibile ottenere l'orario di un volo specifico:
domanda = "Qual è l'orario del volo da New York (NYC) a Los Angeles (LAX)?"
run('llama3.2', domanda)
Il risultato è:
Il tempo di volo da New York (JFK/LGA/EWR) a Los Angeles (LAX) è di circa 5 ore e 30 minuti. Tuttavia, si prega di notare che questo tempo può variare a seconda della compagnia aerea, dell'orario del volo e di eventuali scali o ritardi. È sempre meglio verificare con la propria compagnia aerea le informazioni più aggiornate e accurate sui voli.
Ora vediamo se Llama 3.2 è in grado di effettuare una ricerca vettoriale utilizzando Milvus.
domanda = "Quando è stata fondata l'intelligenza artificiale?".
run("llama3.2", domanda)
Che restituisce una ricerca Milvus:
dati: ["[{'id': 0, 'distanza': 0.5738513469696045, 'entità': {'text': 'L'intelligenza artificiale è stata fondata come disciplina accademica nel 1956.', 'subject': 'history'}}, {'id': 1, 'distanza': 0.4090226888656616, 'entità': {'text': 'Alan Turing fu la prima persona a condurre ricerche sostanziali nel campo dell'intelligenza artificiale', 'subject': 'history' }}]"].
L'intelligenza artificiale è stata fondata come disciplina accademica nel 1956.
Conclusione
Le chiamate di funzione con gli LLM aprono un mondo di possibilità. Integrando Llama 3.2 con strumenti esterni come Milvus e API, è possibile costruire applicazioni potenti e consapevoli del contesto, che rispondono a casi d'uso specifici e a problemi pratici.
Non esitate a dare un'occhiata a Milvus, al codice su Github e a condividere le vostre esperienze con la comunità unendovi al nostro Discord.

Continua a leggere

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.