




HKU PNL / instructor-base
 Milvus Integrated
Milvus Integrated
Compito: Incorporazione
Modalità: Testo
Metrica di Similarità: Coseno
Licenza: Apache 2.0
Dimensioni: 768
Token di Input Massimi: 512
Prezzo: Gratuito
Introduzione alla famiglia del Modello Istruttore
Il modello Instructor di NKU NLP è un modello di text embedding ottimizzato con istruzioni. Crea incorporazioni specifiche per le attività (per la classificazione, il recupero, il clustering, la valutazione del testo, ecc.) in vari domini (come la scienza e la finanza) semplicemente fornendo istruzioni per l'attività, senza bisogno di ulteriori messe a punto.
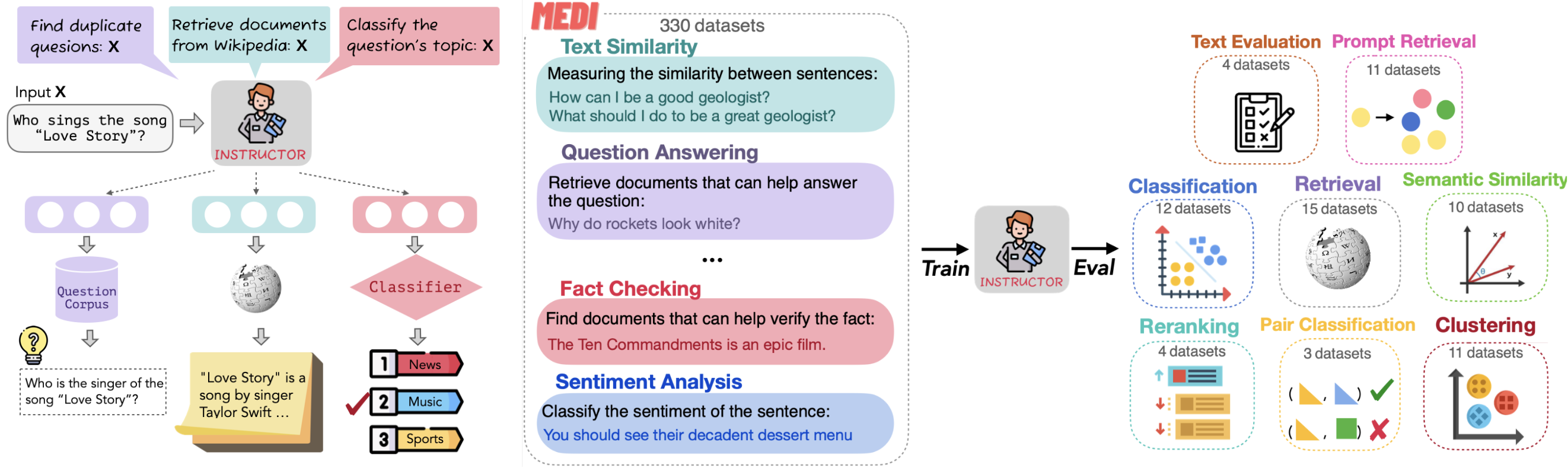 Figura Come funziona il Modello Istruttore
Figura Come funziona il Modello Istruttore
Figura: Funzionamento del modello istruttore (immagine di NKU NLP)
Il modello Istruttore è disponibile in tre varianti: [instructor-base] (istruttore-base), [instructor-xl] (https://zilliz.com/ai-models/instructor-xl) e [instructor-large] (https://zilliz.com/ai-models/instructor-large). Ogni versione offre diversi livelli di prestazioni e scalabilità per soddisfare le varie esigenze di incorporazione.
Introduzione a instructor-base
istruttore-base è la variante più piccola della famiglia di modelli Instructor, progettata per bilanciare efficienza e prestazioni. È ideale per le attività che richiedono incorporazioni di testo di alta qualità con un'impronta computazionale ridotta.
Confronto tra instructor-base, instructor-xl e instructor-large
| Feature | instructor-base | instructor-large | instructor-xl | |
|---|---|---|---|---|
| Dimensione dei parametri | 86 milioni | 335 milioni | 1,5 miliardi | |
| Dimensione dell'incorporamento | 768 | 768 | 768 | 768 |
| Punteggio MTEB medio | 55,5 Punteggio MTEB** | 55,9 | 58,4 | 58,8 |
Come creare le incorporazioni con instructor-base
Esistono due modi principali per generare embeddings vettoriali:
- PyMilvus: l'SDK Python per Milvus che integra perfettamente il modello
instructor-base. - Libreria per istruttori: la libreria Python
InstructorEmbedding.
Una volta create le incorporazioni vettoriali, queste possono essere memorizzate in Zilliz Cloud (un servizio di database vettoriale completamente gestito da Milvus) e utilizzate per la ricerca di similarità semantica. Ecco i quattro passaggi chiave:
- Iscriversi per un account Zilliz Cloud gratuito.
- Configurare un cluster serverless](https://docs.zilliz.com/docs/create-cluster#set-up-a-free-cluster) e ottenere Endpoint pubblico e chiave API.
- Creare una collezione di vettori e inserire gli embeddings vettoriali.
- Eseguire una ricerca semantica sugli embeddings memorizzati.
Creare embeddings tramite PyMilvus
da pymilvus.model.dense import InstructorEmbeddingFunction
da pymilvus import MilvusClient
ef = InstructorEmbeddingFunction(
"hkunlp/instructor-base",
query_instruction="Rappresenta la domanda di Wikipedia per recuperare i documenti di supporto:",
doc_instruction="Rappresenta il documento di Wikipedia per il recupero dei documenti:")
docs = [
"L'intelligenza artificiale è stata fondata come disciplina accademica nel 1956",
"Alan Turing è stato il primo a condurre una ricerca sostanziale sull'intelligenza artificiale",
"Nato a Maida Vale, Londra, Turing è cresciuto nel sud dell'Inghilterra".
]
# Generare le incorporazioni per i documenti
docs_embeddings = ef.encode_documents(docs)
query = ["Quando è stata fondata l'intelligenza artificiale",
"Dove è nato Alan Turing?"]
# Generare embeddings per le query
query_embeddings = ef.encode_queries(queries)
client = MilvusClient(
uri=ZILLIZ_PUBLIC_ENDPOINT,
token=ZILLIZ_API_KEY)
COLLEZIONE = "documenti"
if client.has_collection(collection_name=COLLECTION):
client.drop_collection(nome_raccolta=COLLEZIONE)
client.create_collection(
nome_collezione=COLLEZIONE,
dimensione=ef.dim,
auto_id=True)
per doc, embedding in zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
risultati = client.search(
nome_collezione=COLLEZIONE,
dati=query_embeddings,
consistency_level="Strong",
output_fields=["text"])
Generare le incorporazioni vettoriali tramite la libreria InstructorEmbedding
da InstructorEmbedding import INSTRUCTOR
da pymilvus importare MilvusClient
model = INSTRUCTOR('hkunlp/instructor-base')
docs = [["Rappresenta il documento di Wikipedia per il recupero: ", "L'intelligenza artificiale è stata fondata come disciplina accademica nel 1956."],
["Rappresenta il documento di Wikipedia per il recupero: ", "Alan Turing è stato il primo a condurre ricerche sostanziali nel campo dell'intelligenza artificiale."],
["Rappresentare il documento di Wikipedia per il recupero: ", "Nato a Maida Vale, Londra, Turing è cresciuto nel sud dell'Inghilterra"]].
# Generare embeddings per i documenti
docs_embeddings = model.encode(docs, normalize_embeddings=True)
query = [["Rappresenta la domanda di Wikipedia per recuperare i documenti di supporto: ", "Quando è stata fondata l'intelligenza artificiale"],
["Rappresenta la domanda di Wikipedia per il reperimento di documenti di supporto: ", "Dove è nato Alan Turing?"]]
# Generare embeddings per le query
query_embeddings = model.encode(queries, normalize_embeddings=True)
# Connettersi a Zilliz Cloud con l'endpoint pubblico e la chiave API
client = MilvusClient(
uri=ZILLIZ_PUBLIC_ENDPOINT,
token=ZILLIZ_API_KEY)
COLLEZIONE = "documenti"
if client.has_collection(collection_name=COLLECTION):
client.drop_collection(nome_raccolta=COLLEZIONE)
client.create_collection(
nome_collezione=COLLEZIONE,
dimensione=768,
auto_id=True)
per doc, embedding in zip(docs, docs_embeddings):
client.insert(COLLECTION, {"text": doc, "vector": embedding})
risultati = client.search(
nome_collezione=COLLEZIONE,
dati=query_embeddings,
consistency_level="Strong",
output_fields=["text"])
- Introduzione alla famiglia del Modello Istruttore
- Introduzione a instructor-base
- Come creare le incorporazioni con **instructor-base**
Contenuto
Flussi di lavoro AI senza interruzioni
Dalle embedding alla ricerca AI scalabile—Zilliz Cloud ti consente di memorizzare, indicizzare e recuperare embedding con velocità e efficienza senza pari.
Prova Zilliz Cloud gratuitamente

