




De l'extraction à la connaissance : Comprendre l'ETL

De l'extraction à la connaissance : Comprendre l'ETL
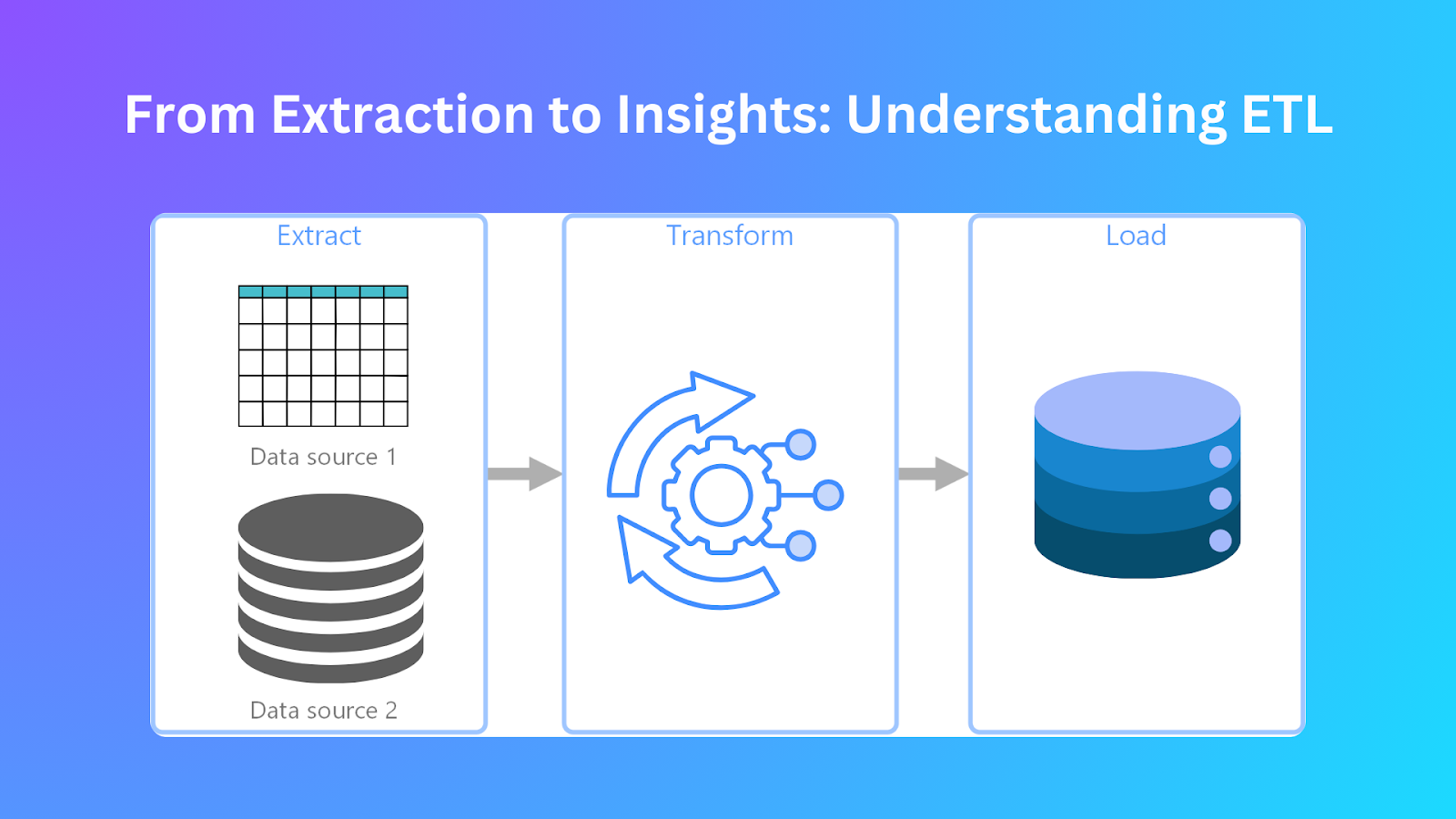 ETL Pipeline.png
ETL Pipeline.png
Comment les entreprises convertissent-elles d'énormes [ensembles de données] brutes (https://zilliz.com/learn/popular-datasets-for-natural-language-processing) en informations puissantes ? Quelles sont les étapes à suivre pour intégrer et affiner les données avant de les analyser ? La réponse réside dans l'extraction, la transformation et le chargement (ETL).
L'ETL est la clé de la gestion moderne des données. Il permet aux organisations de collecter, de traiter et de charger les données en vue de leur analyse. L'ETL extrait des informations de plusieurs ressources, les modifie pour éliminer les erreurs, puis les place dans une base de données centralisée. Ce processus permet d'affiner, de préciser et d'organiser les informations, ce qui facilite la prise de décision au sein de l'entreprise.
Les données sans ETL sont difficiles à analyser en raison de leur nature dispersée et déformée. Des données inefficaces peuvent entraîner des erreurs et avoir un impact sur différents aspects tels que les relations avec les clients ou les performances opérationnelles. L'ETL résout le problème de la mauvaise qualité des données en automatisant les flux de travail et en maintenant l'intégrité des données. Cela permet à l'entreprise de rationaliser les rapports, d'améliorer l'analyse et la prise de décision.
À l'heure où les entreprises axent tout sur les données, il est essentiel de comprendre l'ETL. Que vous travailliez sur des [bases de données] structurées (https://docs.zilliz.com/docs/database), des systèmes en nuage ou des analyses en temps réel, l'ETL garantit l'intégration et le traitement de données de qualité.
Cet article traite du fonctionnement de l'ETL, de son impact et de la manière dont une organisation peut l'utiliser pleinement. Nous découvrirons également les meilleurs outils que vous pouvez utiliser pour faciliter votre processus ETL.
Qu'est-ce que l'ETL (Extract, Transform and Load) ?
L'ETL est le processus central de gestion et d'intégration des données. Il commence par l'extraction des données de différentes sources avant de les transformer dans un format approprié pour les charger dans des destinations cibles telles que les entrepôts de données ou les lacs de données. Les organisations parviennent à consolider les données en réunissant des sources de données distinctes dans un référentiel unique afin de faciliter l'analyse.
L'ETL est l'épine dorsale du maintien de la cohérence, de la qualité et de l'accessibilité des données, quelles que soient les différences de systèmes ou de plateformes. Cette approche est utilisée dans de nombreux secteurs, notamment la finance, les soins de santé et le commerce électronique.
Les entreprises utilisent cette méthode pour organiser leurs données et supprimer les incohérences, ce qui améliore les capacités de prise de décision. Les outils ETL modernes peuvent traiter efficacement les données structurées et non structurées.
Un système de pipeline ETL bien conçu permet aux entreprises d'analyser les tendances et de découvrir des informations. Le flux de travail automatisé améliore l'efficacité opérationnelle grâce à l'automatisation du traitement des données. Les entreprises utilisent l'ETL pour créer une vue unifiée qui permet d'établir des rapports précis et des activités de planification stratégique.
Comment fonctionne l'ETL
Le traitement des données par ETL suit un processus en trois étapes qui garantit la précision et l'efficacité à chaque étape. Ces étapes sont les suivantes :
Extraction
Le pipeline ETL commence par l'extraction des données. Cette étape consiste à collecter des données à partir de différentes sources avant de les regrouper à des fins de traitement. Grâce au processus d'extraction, les organisations acquièrent des ensembles de données complets à partir de leurs différents systèmes, notamment les bases de données, les fichiers plats, le stockage en nuage et les API. Voici quelques-unes des étapes de la phase d'extraction des données :
Identification de la source des données : La première étape de l'extraction consiste à déterminer où résident les données. Les données peuvent provenir de bases de données relationnelles MySQL et PostgreSQL, de bases de données NoSQL MongoDB et Cassandra, d'[API] (https://zilliz.com/glossary/api) tierces, de fichiers CSV ou [JSON] (https://docs.zilliz.com/docs/data-import-json) et de plateformes de données en continu. Pour construire un pipeline ETL efficace, il faut identifier correctement les sources de données appropriées.
Récupération des données** : Les méthodes d'extraction des données dépendent des besoins de l'entreprise et des fonctionnalités disponibles du système. Les données peuvent être extraites de deux manières : soit de manière complète, soit de manière incrémentale. L'extraction complète recueille toutes les données des sources, tandis que l'extraction incrémentale ne recueille que les changements intervenus depuis la dernière extraction. L'extraction incrémentale est préférée car elle raccourcit la durée du traitement et réduit la pression sur les systèmes sources.
Les données extraites peuvent contenir des champs vides, des types de données incohérents et des formats structurels. Les organisations doivent effectuer des contrôles de prétraitement pour identifier et gérer les incohérences avant d'entamer la phase de transformation.
Transformation
Après l'extraction, les données doivent être transformées pour assurer leur compatibilité avec le schéma du système cible et appliquer les règles de gestion. Ce processus de transformation permet d'améliorer la qualité des données, d'obtenir des données cohérentes et d'améliorer la facilité d'utilisation. Voici quelques-unes des façons de transformer vos données :
Nettoyage des données : C'est l'une des procédures de transformation fondamentales. Elle nécessite la suppression des doublons, l'imputation des valeurs pour les données manquantes et la normalisation des conventions de dénomination. Cela permet de produire des rapports à la fois précis et exempts d'erreurs.
Intégration des données : Les données proviennent de sources multiples qui contiennent des structures de données distinctes. L'intégration des données permet de créer une vue unique et cohérente des données à partir de divers ensembles de données distincts. Le processus implique la mise en correspondance des différents noms de colonnes, la réconciliation des différences de fuseaux horaires et la garantie de l'intégrité référentielle.
Agrégation de données** : Elle permet de résumer les données en vue d'une analyse efficace. Les entreprises ont souvent besoin de rapports contenant les totaux des ventes régionales, les moyennes trimestrielles des dépenses des clients et les modèles de revenus mensuels. Le processus d'agrégation permet des requêtes plus rapides et simplifie l'interprétation des données.
Conversion des données** : De nombreux types de données doivent être convertis pour être compatibles avec le système requis. La normalisation des formats de données est cruciale, tandis que la normalisation des champs de texte et la conversion des unités pour les données numériques complètent le processus. Le processus de transformation des données garantit que toutes les données chargées correspondent exactement aux besoins analytiques.
Application des règles de gestion** : Les organisations créent généralement des règles de gestion pour les processus de transformation des données. Une institution financière utilise des seuils de transaction pour développer des catégories, et les entreprises de [commerce électronique] (https://zilliz.com/customers/ecommerce-saas) divisent leurs clients en segments sur la base de leur activité d'achat. Les règles définies génèrent de la valeur en organisant les données non traitées en catégories fonctionnelles.
Chargement
Les données transformées doivent être chargées dans un système cible, qui peut être un entrepôt de données, un lac de données ou une base de données analytique. Le processus de chargement établit le niveau auquel les données peuvent être interrogées et analysées efficacement.
Chargement dans le système cible** : Lors des procédures de chargement complet, le système cible reçoit toutes les données en une seule opération. Cette méthode est principalement utilisée lors de la première migration de données ou pour traiter des ensembles de données plus petits. Une autre méthode consiste à ne charger que les nouveaux enregistrements et les mises à jour à partir du système source. Cette méthode raccourcit la durée du traitement tout en rendant les opérations plus efficaces.
Indexation et partitionnement:** Les méthodes d'indexation des données et les techniques de partitionnement accélèrent les performances du système lors des recherches d'enregistrements. Les techniques de partitionnement divisent les collections de données en segments plus petits, ce qui améliore les performances des requêtes et rend les données plus faciles à gérer.
Les organisations mettent en place des stratégies de sauvegarde pour protéger leurs données contre la perte en cas de défaillance du système. Cette méthode permet de maintenir la protection des données et de garantir leur disponibilité à tout moment.
Comparaison : ETL vs. ELT
L'intégration des données repose sur l'ETL (Extract, Transform, Load) et l'ELT (Extract, Load, Transform) en tant que méthodes principales pour transférer les données de diverses sources vers des entrepôts de données ou des lacs de données. Ces deux méthodes ont en commun l'objectif d'un transfert de données efficace, mais elles fonctionnent différemment lors du traitement et de l'intégration dans les systèmes de données contemporains. Voici une comparaison entre ces deux méthodes :
| | | | | :------------------ : | :--------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------: | | Aspect | ETL | ELT | Aspect | ETL | ELT **ELT | Les données de l'analyse de la qualité de l'eau sont utilisées dans le cadre de l'analyse de la qualité de l'eau et de l'analyse de la qualité de l'eau. | La transformation a lieu avant le chargement dans le système cible. La transformation a lieu après le chargement dans le système cible. | Les données sont stockées dans une zone de transit temporaire pendant la transformation. Les données sont stockées dans le système cible et la transformation a lieu sur place. | Les données sont traitées en temps réel ou presque, et le traitement peut être effectué en parallèle. | Les données sont traitées en temps réel ou presque et le traitement peut être effectué en parallèle. | Il peut être plus coûteux en raison de la nécessité d'une zone de transit et d'un traitement par lots. Il peut être moins coûteux en raison de la capacité à traiter les données en temps réel et en parallèle. | Elle peut être moins coûteuse en raison de la capacité à traiter les données en temps réel et en parallèle. | Il convient au traitement par lots, à l'entreposage de données et à la veille stratégique. Il convient à l'analyse en temps réel, à l'intégration de données et au traitement des données volumineuses.
RTL vs ELT | Source
Avantages et défis
Si l'ETL permet d'extraire, de transformer et de charger des données, il présente également des avantages et des inconvénients. Examinons-les :
Avantages
Les processus ETL suivent le mouvement des données depuis les sources jusqu'aux destinations. Ils ont pour principales fonctions d'identifier les erreurs, de maintenir l'intégrité et de garantir l'exactitude des données.
Préservation des données historiques** : Le processus ETL capture des instantanés de données tout au long de leur parcours, ce qui permet aux entreprises de conserver les informations historiques nécessaires à l'analyse des tendances et à l'établissement de rapports. Les entreprises peuvent suivre les données tout en effectuant des comparaisons pour faciliter leur processus de prise de décision.
Transformation de données complexes** : Les outils ETL excellent dans l'exécution de transformations de données complexes, y compris les processus d'agrégation, les conversions de types de données et la mise en œuvre de la logique d'entreprise. Les capacités du système facilitent les opérations de nettoyage des données, produisant des informations structurées et normalisées avant que le système cible ne les reçoive.
Enrichissement des données:** Le processus d'enrichissement des données de l'ETL permet aux entreprises de combiner des informations provenant de diverses bases de données externes, améliorant ainsi la qualité et l'exhaustivité de l'ensemble des données. L'incorporation d'informations contextuelles par le biais de l'enrichissement augmente la perspicacité analytique en ajoutant de la valeur aux données à des fins de prise de décision.
Efficacité du traitement par lots** : Les flux de travail ETL atteignent une efficacité maximale grâce au traitement par lots, qui traite d'importants volumes de données pendant les périodes creuses programmées. Le processus minimise l'impact sur les performances du système pendant les heures normales de travail tout en gérant efficacement les grands ensembles de données.
Défis
Limites de l'intégration en temps réel** : Les processus ETL traditionnels intègrent les données par lots programmés, ce qui limite les besoins en données en temps réel. Les organisations qui ont besoin de capacités d'analyse et de prise de décision instantanées rencontrent des difficultés en raison des retards associés aux processus ETL traditionnels.
Opérations gourmandes en ressources** : les exigences en matière de calcul pour les charges de travail ETL deviennent particulièrement contraignantes lorsque les processus de transformation et de chargement des données ont lieu. L'utilisation élevée des ressources CPU et de la mémoire réduit la vitesse des opérations du système, ce qui affecte les niveaux de performance.
Complexité de la gestion des erreurs** : La gestion des erreurs devient difficile car les pipelines ETL doivent gérer de nombreuses sources de données et des règles de transformation complexes. Des outils de surveillance et des systèmes de débogage robustes sont nécessaires pour identifier les incohérences, traiter les données manquantes et gérer la qualité.
Contraintes d'évolutivité** : Le volume croissant de données pose des problèmes d'évolutivité qui obligent les processus ETL à investir dans de nouvelles infrastructures ou à adopter des architectures repensées. Lorsque l'optimisation des données est insuffisante, l'augmentation des volumes de données peut entraîner des retards de traitement et des limitations des performances du système.
Gestion des dépendances : Les différentes étapes des flux de travail ETL s'appuient les unes sur les autres, de sorte que toute défaillance au niveau d'une étape peut avoir un effet en cascade sur l'ensemble du pipeline. Pour éviter les perturbations opérationnelles, une gestion efficace des dépendances nécessite une planification minutieuse ainsi que des systèmes de surveillance et des plans de mécanismes de reprise en cas d'erreur.
Cas d'utilisation et outils
Le processus ETL est une exigence opérationnelle fondamentale pour de nombreux secteurs, car il permet une intégration et une analyse efficaces des données. Voici quelques-uns des cas d'utilisation et des outils :
Cas d'utilisation
Détail: Le processus ETL permet aux magasins de détail de rassembler les données du système de caisse, qu'ils normalisent par rapport aux enregistrements d'inventaire avant de les stocker dans une base de données unifiée. Le système permet de suivre les données de vente, de gérer les stocks et de mieux comprendre les clients.
Les institutions financières appliquent des méthodes ETL pour fusionner les données de transaction provenant de plusieurs systèmes avant de les transformer et de les charger dans des systèmes de stockage de données intégrés. Le processus de consolidation permet aux organisations de détecter efficacement les fraudes, de gérer les risques et de produire des rapports conformes.
Soins de santé** : Les organismes de santé appliquent des processus ETL pour unir les données des dossiers médicaux électroniques (DME), des bases de données cliniques et des systèmes administratifs. L'intégration du système permet une meilleure gestion des soins aux patients avec des améliorations de l'efficacité opérationnelle tout en soutenant des processus de prise de décision éclairés.
Outils ETL populaires
AWS Glue: Un service d'intégration de données sans serveur qui facilite la connexion à plus de 70 sources de données diverses. Il offre un catalogue de données centralisé, un environnement sans serveur et des scripts personnalisables.
[Apache NiFi] (https://nifi.apache.org/) : Il s'agit d'un système open-source qui permet un traitement automatisé des flux de données grâce à sa fonctionnalité ETL. Le système offre un accès web facile à utiliser, des capacités de traitement instantanées et des options de personnalisation étendues qui profitent aux opérations d'acheminement de données complexes.
[Matillion] (https://www.matillion.com/) : Un outil ETL natif qui fonctionne de manière transparente sur les principales plateformes de données basées sur le cloud. Il offre des fonctionnalités telles que l'IA générative, des connecteurs prédéfinis et des flux de travail collaboratifs.
Les outils et leurs applications démontrent à quel point les méthodes ETL sont essentielles pour convertir les données brutes en informations pratiques dans de nombreux domaines d'activité.
FAQ
- Quel est l'objectif principal de l'ETL ?
L'ETL a pour fonction de fusionner des données provenant de différentes sources dans un référentiel unique et unifié. Le processus de traitement des données comprend trois étapes : les données sont extraites des sources, puis transformées en fonction des besoins opérationnels avant d'être chargées dans un système analytique.
- En quoi l'ETL diffère-t-il de l'ELT ?
Le processus ETL commence par l'extraction des données des systèmes sources avant de les transformer en une zone de transit pour les charger dans le système cible. Les données sont ensuite chargées dans le système cible et les transformations sont effectuées directement sur ce système.
- Quels sont les défis les plus courants liés à la mise en œuvre des processus ETL ?
La mise en œuvre des procédures ETL se heurte à de nombreux obstacles, car elle nécessite une gestion efficace des données d'origines diverses, un contrôle de la qualité et un traitement efficace de volumes de données considérables. Ces défis engendrent des problèmes de performance qui nécessitent une planification minutieuse des ressources pour être résolus efficacement.
- Les processus ETL peuvent-ils être automatisés ?
Les outils ETL offrent des capacités d'automatisation grâce à des fonctions de planification et de gestion des flux de travail permettant d'exécuter les processus de transfert de données. L'automatisation permet des opérations efficaces grâce à un traitement automatique des données qui réduit l'implication humaine tout en maintenant une qualité de données cohérente afin de conserver des ensembles de données à jour pour l'analyse.
- Pourquoi la transformation des données est-elle importante dans l'ETL ?
La transformation des données dans le cadre des opérations ETL est essentielle pour nettoyer, normaliser et formater les données obtenues à partir de différentes sources. Le processus de transformation des données garantit que le système cible reçoit des données précises et cohérentes pour l'analyse et le reporting, ce qui permet de prendre des décisions fiables.
Ressources connexes
- Qu'est-ce que l'ETL (Extract, Transform and Load) ?
- Comment fonctionne l'ETL
- Comparaison : ETL vs. ELT
- Avantages et défis
- Cas d'utilisation et outils
- FAQ
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement