




Comment Tokopedia a obtenu une expérience de recherche 10x plus intelligente grâce à Milvus
10x plus intelligent
expérience de recherche
Améliorée
expérience utilisateur
Améliorée
évolutivité et fiabilité
Our search system has been much more intelligent, stable, and reliable using Milvus.
Rahul Yadav
A propos de Tokopedia
[Tokopedia] (https://www.tokopedia.com/) est la plus grande plateforme de commerce électronique d'Indonésie, avec 90 millions d'utilisateurs mensuels actifs et un impressionnant réseau de 8,6 millions de marchands. Avec une portée s'étendant à 98% des régions administratives indonésiennes, Tokopedia est devenue la destination privilégiée du pays pour les achats en ligne.
Tokopedia reconnaît que la valeur de son vaste catalogue de produits réside dans le fait que les acheteurs peuvent découvrir sans effort des produits adaptés à leurs préférences. Dans le cadre de son engagement inébranlable à améliorer la pertinence des résultats de recherche, elle a introduit une [recherche par similarité] (https://zilliz.com/learn/vector-similarity-search) sur Tokopedia.
Lorsque l'utilisateur navigue sur la page des résultats de recherche sur votre appareil mobile, il remarquera un bouton discret "...". En cliquant sur ce bouton, l'utilisateur peut accéder à un menu qui lui offre la possibilité d'explorer les produits qui correspondent le plus à celui qu'il est en train de regarder.
Défis de la recherche par mot-clé
Dans le passé, Tokopedia Search utilisait [Elasticsearch] (https://zilliz.com/blog/elasticsearch-cloud-vs-zilliz) comme moteur principal pour la recherche et le classement des produits. Chaque demande de recherche envoyait une requête à Elasticsearch, qui classait les produits en fonction du mot-clé de recherche de l'utilisateur. Elasticsearch stocke les mots-clés sous forme de séquences de valeurs numériques, représentant des codes ASCII ou UTF pour des lettres individuelles. Il construit un index inversé pour l'identification rapide des documents contenant les mots de la requête de l'utilisateur et détermine ensuite les meilleures correspondances à l'aide d'une série d'algorithmes de notation.
Toutefois, ces algorithmes de notation ne tiennent généralement pas compte de la sémantique des mots-clés recherchés. Ils se concentrent plutôt sur des facteurs tels que la fréquence d'apparition des mots dans les documents, leur proximité et d'autres informations statistiques. Bien que les humains puissent comprendre le sens de la représentation ASCII des mots, les ordinateurs ont besoin d'un algorithme fiable pour comparer la sémantique des mots codés en ASCII.
Représentation vectorielle
L'une des solutions trouvées par l'équipe de Tokopedia a été de créer une nouvelle façon de représenter les mots-clés, qui montre les lettres d'un mot et donne des informations sur sa signification. Par exemple, ils pourraient coder les mots couramment utilisés avec le mot-clé de recherche pour fournir un contexte probable. À partir de là, ils peuvent supposer que des contextes similaires indiquent des concepts similaires et les comparer à l'aide de techniques mathématiques. Il est même possible de coder des phrases entières en fonction de leur sens.
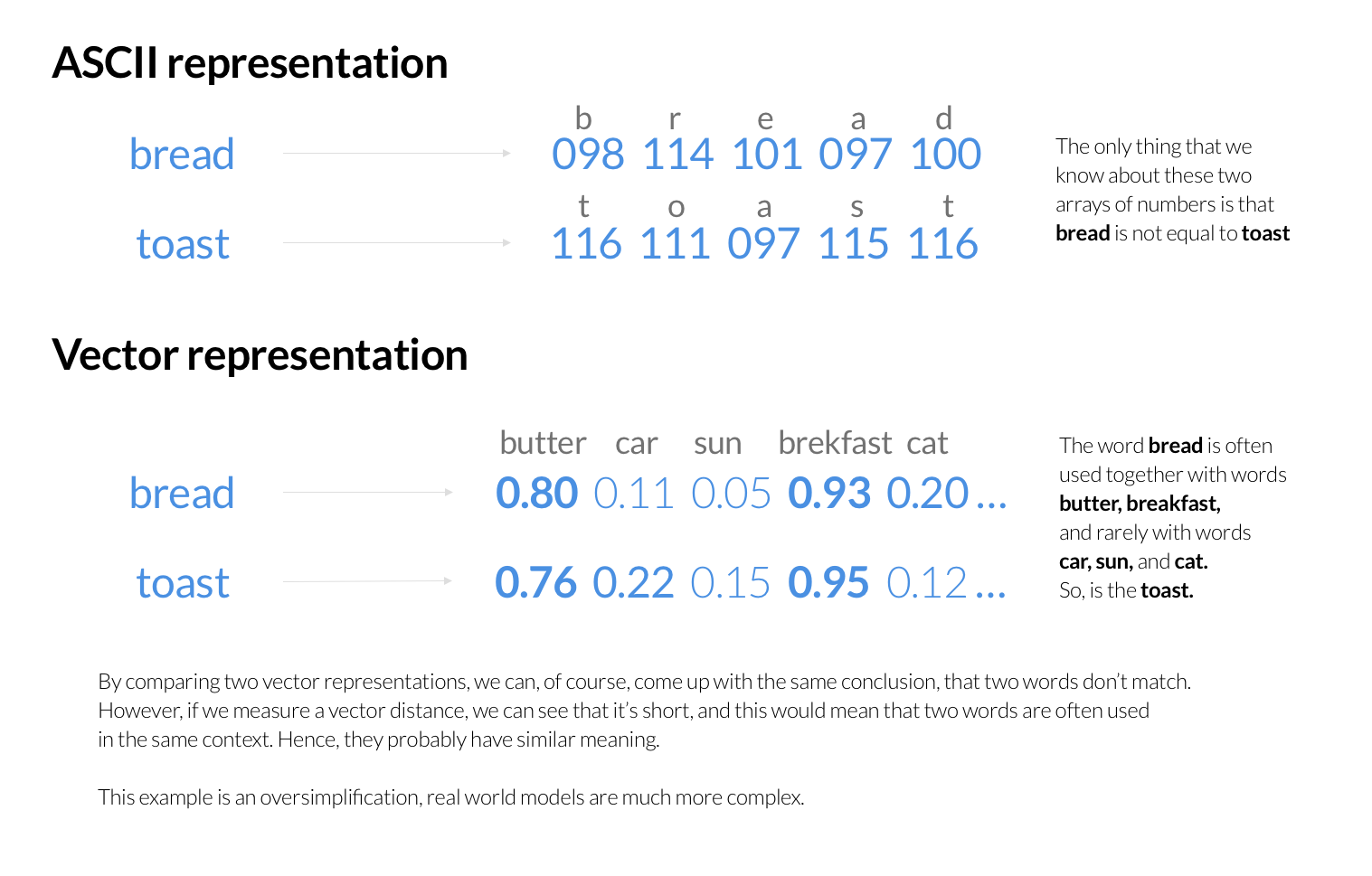
Sélection de Milvus comme moteur de recherche de similarité vectorielle
Maintenant que Tokopedia possède des vecteurs de caractéristiques, le défi restant consiste à récupérer efficacement les vecteurs du vaste ensemble de données qui correspondent étroitement au vecteur cible. En explorant les moteurs de recherche vectorielle, nous avons effectué des évaluations de validation de concept (POC) sur plusieurs piles de recherche vectorielle disponibles sur GitHub, y compris FAISS, Vearch, et Milvus.
Notre préférence va à Milvus sur la base des résultats de nos tests de charge. Par rapport à Milvus, FAISS fonctionne davantage comme une bibliothèque sous-jacente et est donc moins convivial. Lorsque nous avons approfondi Milvus, nous l'avons adopté pour les raisons suivantes :
- Milvus s'est avéré remarquablement convivial. Ils ont constaté qu'il suffisait d'extraire son image Docker et d'ajuster les paramètres en fonction de vos cas d'utilisation spécifiques.
- Milvus offre une plus large gamme d'index pris en charge**. En plus de FAISS, HSNW, DISK_ANN et ScaNN, il y a 11 index parmi lesquels choisir.
- Milvus fournit une documentation complète pour aider les utilisateurs dans leur mise en œuvre**.
En résumé, Milvus est convivial, avec une documentation claire et un support communautaire fiable pour tout problème qui pourrait survenir.
Milvus en production
Après avoir mis en œuvre Milvus en tant que moteur de recherche à vecteur de fonctionnalités, ils l'ont utilisé pour leur service Ads afin de faire correspondre des mots-clés à faible taux de remplissage avec des mots-clés à taux de remplissage élevé. Ils ont configuré et exécuté un nœud autonome dans un environnement de développement (DEV), qui a fonctionné sans problème et a permis d'obtenir un taux de clics (CTR) et un taux de conversion (CVR) 10 fois plus élevés.
Cependant, un problème potentiel s'est posé. Si un nœud autonome tombait en panne, l'ensemble du service deviendrait inaccessible. L'équipe de Tokopedia est donc passée à une implémentation HA de Milvus.
Milvus propose deux outils : Mishards, un middleware de cluster sharding, et Milvus-Helm pour une configuration simplifiée. Tokopedia utilise des playbooks Ansible pour la configuration de l'infrastructure, ce qui l'a incité à créer un playbook pour orchestrer l'infrastructure. Le diagramme ci-dessous illustre le fonctionnement de Mishards.
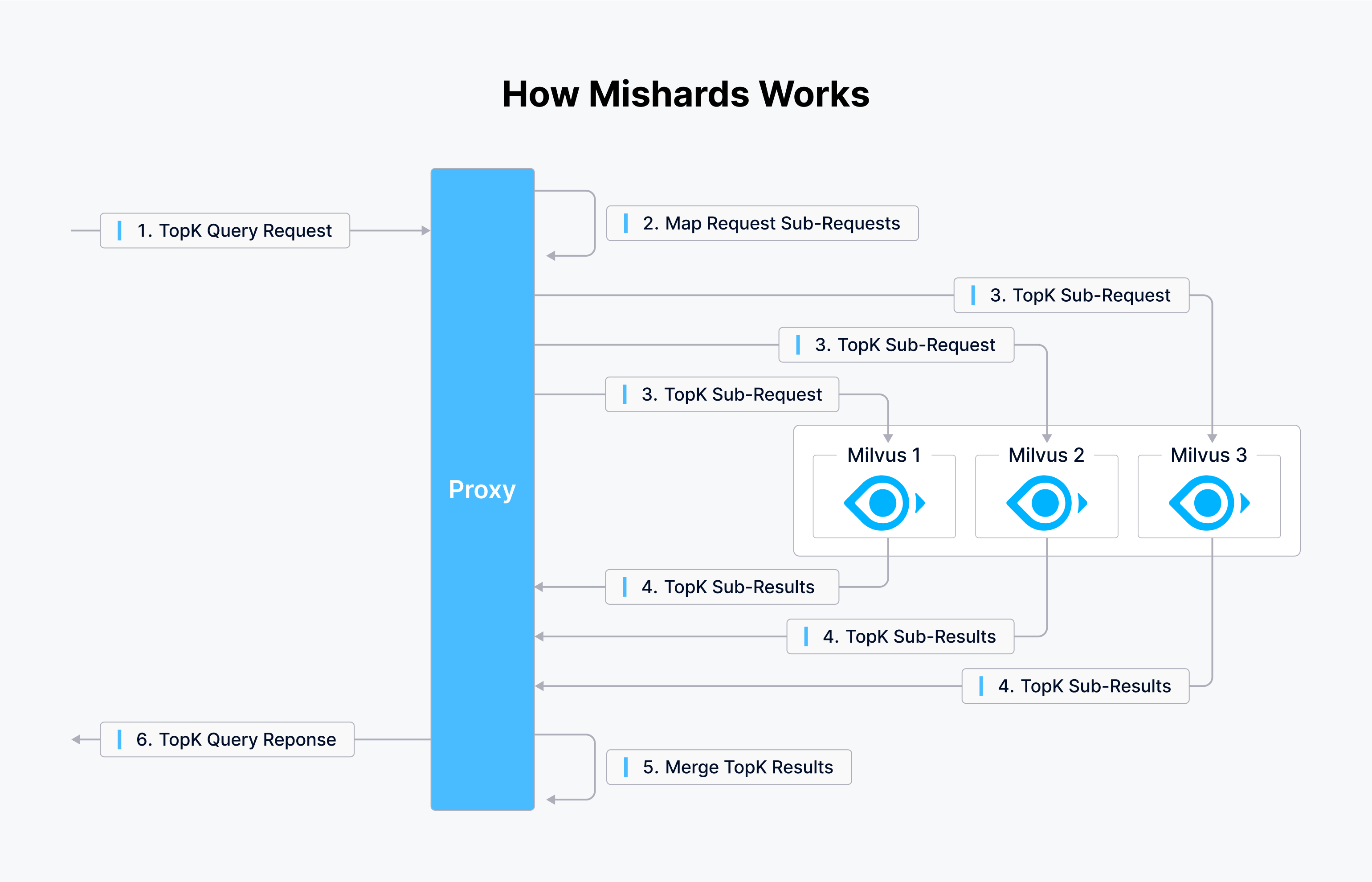
Mishards facilite le flux transparent des demandes d'amont en aval, en divisant les demandes d'amont en sous-modules, en recueillant les résultats des sous-services et en renvoyant ensuite ces résultats à la source d'amont.
L'architecture de la solution de cluster basée sur Mishards est présentée ci-dessous.
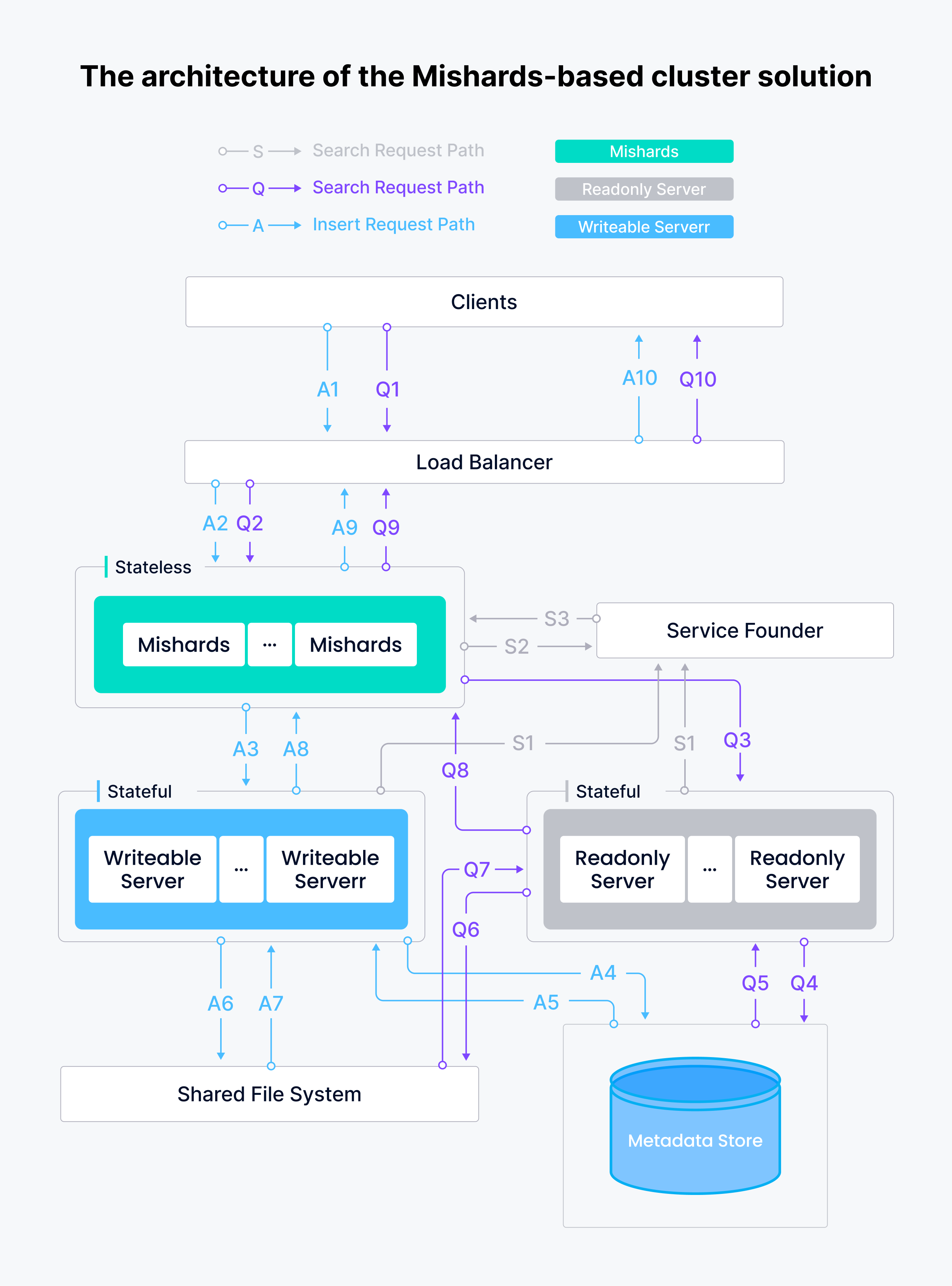
Le système de service de recherche sémantique Tokopedia comprend un nœud en écriture, deux nœuds en lecture seule et une instance de middleware Mishards, tous déployés dans GCP à l'aide de Milvus Ansible. Le système a été considérablement plus intelligent, stable et fiable.
Comment l'indexation vectorielle accélère-t-elle la recherche de similarités ?
L'interrogation efficace de grands ensembles de données vectorielles dans les moteurs de recherche de similarité nécessite une indexation appropriée. Ce processus organise les données et accélère le processus de recherche, ce qui le rend essentiel pour traiter des ensembles de données comportant des millions, des milliards, voire des trillions de vecteurs. Une fois que vous avez indexé un ensemble massif de données vectorielles, vous pouvez orienter les requêtes vers les grappes ou sous-ensembles de données les plus susceptibles de contenir des vecteurs similaires à la requête d'entrée. Cependant, cette approche peut sacrifier la précision pour obtenir des requêtes plus rapides sur des données vectorielles volumineuses.
Pour mieux comprendre, imaginez l'indexation comme un classement alphabétique des mots dans un dictionnaire. Lorsque vous recherchez un mot clé, vous pouvez rapidement naviguer vers une section contenant uniquement les mots dont la lettre initiale est la même, ce qui accélère considérablement la recherche de la définition du mot saisi.
Résumé
La quête de Tokopedia pour une fonctionnalité de recherche supérieure l'a conduite à Milvus, qui change la donne en matière de recherche sémantique. Avec Milvus, ils ont exploité la puissance de la représentation vectorielle et construit un système de recherche 10 fois plus intelligent qui a considérablement amélioré l'expérience de l'utilisateur. Leur service de recherche est également hautement disponible, ce qui garantit des opérations sans faille. Ce voyage avec Milvus a transformé la recherche de Tokopedia, promettant un avenir de résultats de recherche personnalisés et significatifs. Avec Milvus, ils révolutionnent le commerce électronique en Indonésie et au-delà.
*Cet article a été rédigé par Rahul Yadav, ingénieur logiciel chez Tokopedia. Il est édité et reposté ici avec sa permission. *
- A propos de Tokopedia
- Défis de la recherche par mot-clé
- Représentation vectorielle
- Sélection de Milvus comme moteur de recherche de similarité vectorielle
- Milvus en production
- Comment l'indexation vectorielle accélère-t-elle la recherche de similarités ?
- Résumé
Contenu
Cas d'usage
Secteur d'activité
Commerce électronique