




Comment TAL Education Group développe l’apprentissage alimenté par l’IA avec Milvus

Recherche sémantique en millisecondes
Récupération instantanée parmi des milliards de vecteurs, remplaçant la correspondance approximative lente
Précision de notation accrue
Compréhension sémantique plus précise des réponses ouvertes et multimodales des étudiants
Qualité de recommandation renforcée
La recherche vectorielle à rappel élevé fait émerger du contenu pertinent que la recherche par mots-clés manque
Accélérations de bout en bout
Des pipelines de notation, de récupération et de recommandation plus rapides, avec une latence globale réduite
À propos de TAL Education Group
TAL Education Group (NYSE: TAL) est l’une des principales entreprises de technologie éducative en Asie, au service de millions d’élèves et de familles. Fondée en 2003 et cotée à la Bourse de New York en 2010, TAL est passée de son activité de soutien scolaire Xueersi à un vaste portefeuille de produits d’apprentissage numérique—including Xueersi.com, Xueersi Smart Devices, MathGPT, and other technology-driven education brands—tous conçus pour accompagner les élèves à la maison et dans des environnements de classe numérique.
À mesure que TAL s’est davantage développée dans l’apprentissage piloté par l’IA—couvrant le tutorat personnalisé, la correction automatisée, la recommandation de contenu et la recherche de connaissances multimodale—l’entreprise avait besoin d’une nouvelle infrastructure de données capable de prendre en charge ces charges de travail intensives en calcul à grande échelle. En choisissant Milvus comme fondation de sa plateforme de recherche vectorielle, TAL a obtenu les performances, l’évolutivité et la flexibilité nécessaires pour permettre une correction plus rapide, des recommandations plus précises et une recherche sémantique plus intelligente dans l’ensemble de ses produits. Milvus joue désormais un rôle clé dans le soutien de la mission plus large de TAL : offrir des expériences d’apprentissage de haute qualité, propulsées par la technologie, accessibles, efficaces et performantes pour chaque élève.
Défis auxquels sont confrontés les systèmes d’apprentissage de TAL propulsés par l’IA
TAL déploie l’IA dans plusieurs scénarios pédagogiques clés—correction automatisée, recommandations de ressources d’apprentissage et recherche documentaire basée sur les vecteurs. Mais à mesure que ces services ont pris de l’ampleur, l’entreprise a rapidement atteint les limites des systèmes de données traditionnels. L’éducation en ligne moderne génère d’énormes volumes de contenu complexe et multimodal, tandis que la correction propulsée par l’IA exige à la fois un débit élevé et une compréhension approfondie des réponses des élèves. Ces pressions ont fait apparaître des problèmes structurels que les infrastructures héritées ne pouvaient tout simplement pas résoudre.
1. Croissance explosive des données multimodales
TAL traite chaque jour des centaines de milliers de nouvelles questions et réponses dans différentes matières, niveaux scolaires et formats, notamment des images, des diagrammes et des formules manuscrites. Cet afflux constant de données pousse les bases de données traditionnelles au-delà de leur capacité à indexer et récupérer les données efficacement. À mesure que les plateformes d’apprentissage numérique de TAL se développent, le backend doit évoluer de manière fluide pour répondre à des besoins de stockage croissants, à une recherche vectorielle à haut débit et à des pics soudains de trafic pendant les examens et les périodes d’apprentissage de pointe, le tout sans compromettre les performances ni la disponibilité.
2. Inefficacités opérationnelles dans le pipeline de correction
La correction humaine ne peut pas suivre le rythme de l’apprentissage en ligne moderne. Un seul test peut prendre 15 à 20 minutes à un enseignant pour être évalué, et les questions subjectives donnent souvent lieu à des notes incohérentes selon les correcteurs. À l’échelle de TAL, cela entraîne des goulots d’étranglement dans la correction et consomme un temps précieux des enseignants qui pourrait être réorienté vers un enseignement personnalisé.
De plus, TAL possède une vaste bibliothèque d’explications, de solutions et de supports d’apprentissage—mais ces ressources sont dispersées entre différents systèmes. Sans recherche intelligente, des ressources de grande qualité restent sous-utilisées, créant des écarts entre la création de contenu et les besoins réels des apprenants.
3. Exigences élevées de précision pour le feedback propulsé par l’IA
La correction par l’IA doit faire plus que faire correspondre des mots-clés—elle doit comprendre le sens. Les systèmes de TAL doivent identifier l’équivalence sémantique, interpréter des formulations variées et évaluer les élèves de manière juste et cohérente. Toutes les explications générées doivent être exactes, pédagogiquement solides et adaptées à l’âge. Pour cela, TAL a besoin d’un graphe de connaissances robuste qui relie chaque question aux concepts appropriés et cartographie leurs relations. Les systèmes traditionnels ne sont pas conçus pour prendre en charge ce niveau de raisonnement sémantique à grande échelle.
Alimenter les systèmes de correction et d’apprentissage par l’IA de TAL avec Milvus
À mesure que TAL étendait ses services de notation et d’apprentissage pilotés par l’IA, l’entreprise avait besoin d’une infrastructure vectorielle capable de prendre en charge des charges de travail massives d’embeddings avec une grande précision et une réactivité en temps réel. Après avoir évalué plusieurs solutions, TAL a choisi Milvus comme moteur central de sa plateforme de données vectorielles.
Au-dessus de Milvus, TAL a construit une architecture modulaire qui garantit une haute qualité des données, une intégration fluide avec les applications et une amélioration continue du système.
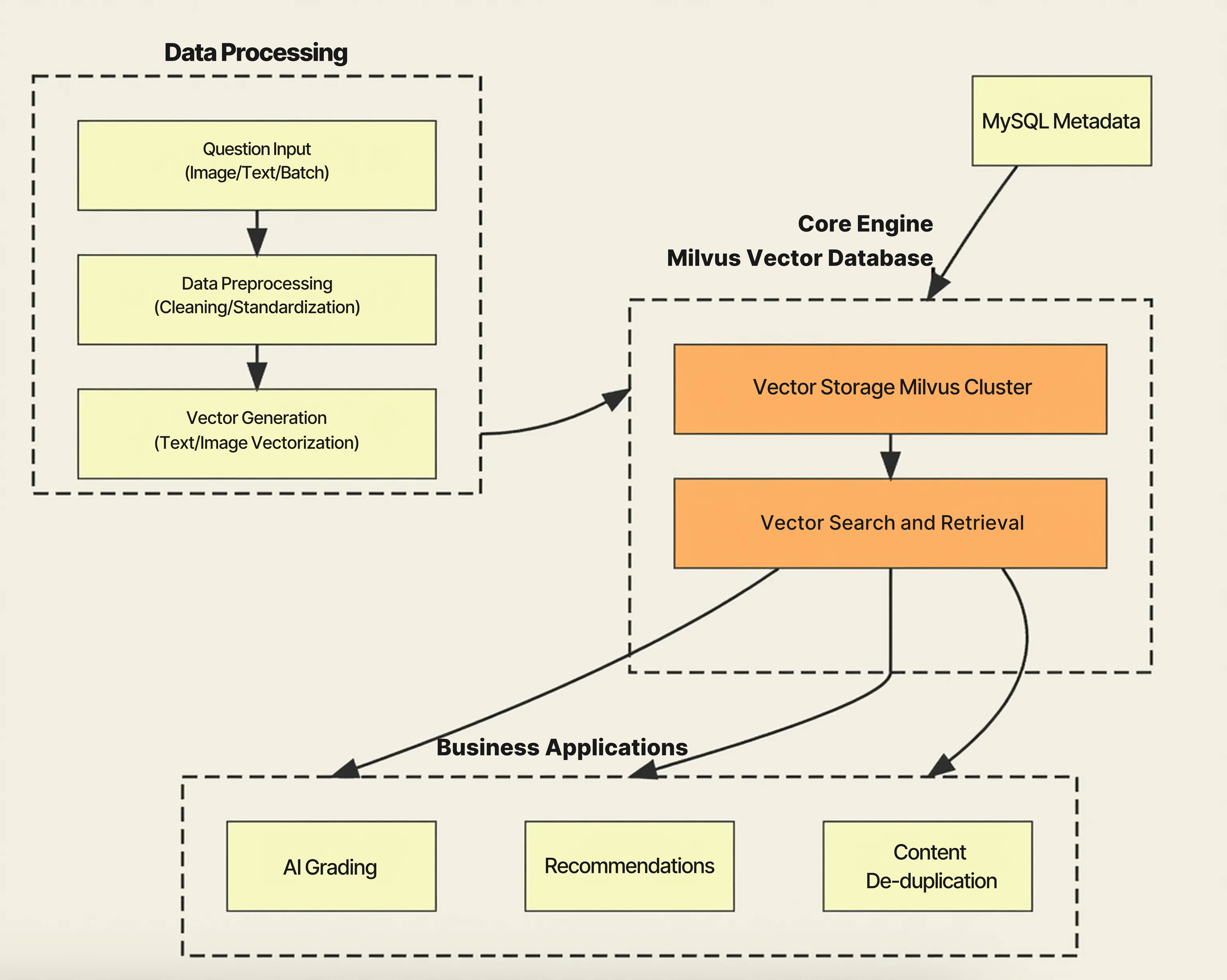
Pipeline de traitement des données : des données propres, cohérentes et prêtes pour les vecteurs
Le pipeline de traitement des données de TAL constitue la base de l’ensemble du système. Les questions, réponses et supports d’apprentissage sont ingérés depuis plusieurs sources, notamment des API, des importations par lots et l’extraction OCR à partir d’images ou d’écriture manuscrite. Une fois ingéré, tout le contenu passe par la normalisation, l’extraction de caractéristiques et des contrôles qualité avant d’être transformé en embeddings vectoriels. Ce pipeline garantit que tout ce qui est stocké dans Milvus est propre, cohérent et optimisé pour une récupération sémantique de haute qualité.
Base de données vectorielle Milvus : récupération haute performance à l’échelle du milliard
Au cœur de l’architecture de TAL se trouve la base de données vectorielle Milvus, qui offre un stockage vectoriel à l’échelle du milliard et une recherche sémantique haute performance. L’architecture distribuée de Milvus et l’indexation Approximate Nearest Neighbor (ANN) permettent à TAL de servir des requêtes de similarité en quelques millisecondes, même sur des centaines de millions à des milliards d’embeddings. La stratégie multi-index de Milvus aide TAL à équilibrer vitesse et précision, tandis que MySQL stocke les métadonnées structurées telles que le versionnement et les correspondances d’index. Cela maintient les données vectorielles et les données relationnelles étroitement synchronisées.
Aujourd’hui, ce déploiement Milvus gère plus de 1 milliard de vecteurs dans plus de 20 collections, avec un seul cluster traitant des millions de requêtes de récupération par jour.
Services applicatifs : transformer la récupération vectorielle en impact éducatif
La couche des services applicatifs transforme les capacités de Milvus en un véritable impact éducatif.
Notation par l’IA : Utilise la similarité sémantique pour évaluer les réponses des élèves et générer des explications.
Recommandations : Trouve des questions similaires adaptées au niveau d’apprentissage et à la progression d’un élève.
Déduplication de contenu : Détecte les contenus répétitifs ou redondants afin de maintenir la qualité de la banque de questions.
Chaque service dépend de la capacité de Milvus à fournir une récupération rapide et précise à grande échelle, garantissant que les élèves et les enseignants reçoivent des résultats rapides, personnalisés et cohérents.
Cadre d’évaluation de la qualité : une boucle fermée pour l’amélioration continue
Pour maintenir la fiabilité à grande échelle, TAL a construit un cadre d’évaluation continue de la qualité à travers le système. Chaque résultat de notation généré par l’IA reçoit un score de confiance basé sur la similarité sémantique, les performances historiques et les retours des enseignants. Ces signaux alimentent une boucle de rétroaction structurée qui identifie les anomalies, ajuste la logique de notation, met à jour les paramètres du modèle et améliore la qualité de récupération au fil du temps.
Ce mécanisme en boucle fermée garantit que le système devient plus précis à mesure que l’utilisation augmente, au lieu de se dégrader sous des charges de travail plus importantes.
Des gains de performance réels et de nouvelles possibilités grâce à Milvus
Après avoir déployé Milvus dans ses environnements de cloud hybride, TAL a rapidement constaté des améliorations majeures des performances du système et de la qualité des expériences d’apprentissage alimentées par l’IA.
Récupération en quelques millisecondes à l’échelle du milliard
Milvus gère désormais des milliards de vecteurs avec une recherche sémantique en quelques millisecondes, remplaçant les méthodes lentes de correspondance approximative qui freinaient auparavant la notation par l’IA, les recommandations et la récupération de contenu. Avec Milvus en place, les résultats reviennent plus rapidement, la précision augmente, et les enseignants comme les élèves obtiennent des réponses plus cohérentes dans l’ensemble.
Précision accrue et plus grande stabilité
La recherche par similarité vectorielle de Milvus offre à TAL une compréhension bien plus approfondie des réponses des élèves. Par rapport à ses systèmes précédents, Milvus fournit :
Des résultats de récupération plus précis, en particulier pour les questions ouvertes et multimodales
Un rappel de meilleure qualité, faisant émerger du contenu pertinent que la recherche par mots-clés ne peut pas trouver
Des performances stables à l’échelle du milliard, même pendant les périodes de pointe des examens
Un traitement de bout en bout plus rapide, réduisant la latence pour la notation et les recommandations
Ces avancées améliorent non seulement l’efficacité du système, mais aussi la qualité pédagogique, permettant à l’IA de mieux comprendre l’intention des élèves et de répondre avec une plus grande pertinence pédagogique.
Débloquer de nouvelles capacités d’IA dans tout l’écosystème
Au-delà de l’accélération des processus existants, Milvus a permis une vague de nouvelles fonctionnalités sur les plateformes d’apprentissage de TAL :
Notation par IA : Une correspondance sémantique plus précise améliore la cohérence de la notation et la qualité des explications.
Plateforme IM interne : Une récupération de documents plus rapide et plus pertinente améliore la collaboration et la réutilisation des contenus.
Questions-réponses sur base de connaissances : Un rappel précis au niveau des segments fournit des réponses que la recherche par mots-clés ne pourrait jamais faire émerger.
Faire progresser l’équité et l’efficacité éducatives
Les améliorations de Milvus se traduisent par des gains concrets en classe. Une notation par IA plus rapide et plus fiable réduit la charge de travail des enseignants et crée une notation plus cohérente pour de grands groupes d’élèves. Une meilleure récupération sémantique rend les ressources d’apprentissage de haute qualité plus faciles à trouver et à réutiliser. Ensemble, ces améliorations aident TAL à offrir un accompagnement plus personnalisé et équitable à chaque élève.
Une efficacité opérationnelle et une observabilité renforcées
Pour les équipes d’ingénierie, Milvus simplifie également les opérations quotidiennes. La console web Attu, l’outil de gestion officiel de Milvus, rend l’inspection des vecteurs et la gestion des collections plus intuitives, réduisant la charge opérationnelle. Dans le même temps, les intégrations avec Prometheus + Alertmanager offrent une visibilité approfondie sur la latence, l’état des nœuds, l’utilisation du stockage et les schémas d’erreurs. Cette observabilité aide TAL à maintenir des services stables et prévisibles, même lors des pics de trafic et des grands cycles d’examens.
Et ensuite : grandir avec Milvus et la communauté
Avec Milvus solidement déployé au sein de plusieurs équipes, TAL se projette désormais vers la manière dont la recherche vectorielle peut soutenir encore davantage ses initiatives d’IA. L’exploitation de Milvus à l’échelle du milliard a donné aux ingénieurs de TAL une vision claire de ce qui fonctionne bien et des améliorations qui pourraient avoir un impact encore plus important.
TAL prévoit de rester actif au sein de la communauté Milvus, en partageant des enseignements réels issus de la production, en donnant son avis sur les nouvelles fonctionnalités et en travaillant étroitement avec les contributeurs pour façonner la prochaine vague de capacités des bases de données vectorielles. Des améliorations telles qu’une migration des données inter-clusters plus simple et l’optimisation continue des performances permettraient à TAL d’introduire encore plus facilement Milvus dans davantage de produits.
Pour maintenir le bon fonctionnement des services critiques, TAL exploite également Zilliz Cloud, le service Milvus entièrement géré, parallèlement à son déploiement open-source de Milvus. Cette configuration dual-active apporte à l’équipe une fiabilité supplémentaire lors des mises à niveau ou des périodes de fort trafic, et garantit aux élèves comme aux enseignants une expérience d’apprentissage toujours stable.
Alors que TAL continue de créer des outils d’IA plus intelligents et évolutifs pour l’éducation, Milvus restera un élément clé de sa stack technologique, aidant l’entreprise à fournir des solutions d’apprentissage plus rapides, plus intelligentes et plus fiables à des millions de familles.
Note : Cette étude de cas a été rédigée par Zhiming Huang et Muzi Lee, senior data scientists chez TAL Education Group, et est traduite, éditée et republiée ici avec autorisation.
- À propos de TAL Education Group
- Défis auxquels sont confrontés les systèmes d’apprentissage de TAL propulsés par l’IA
- Alimenter les systèmes de correction et d’apprentissage par l’IA de TAL avec Milvus
- Des gains de performance réels et de nouvelles possibilités grâce à Milvus
- Et ensuite : grandir avec Milvus et la communauté
Contenu
Cas d'usage
Secteur d'activité
Éducation