




Comment une plateforme GPU et IA leader mondiale utilise Milvus pour faire évoluer l’exploration de données multimodales pour son système de conduite autonome

-30% Coût
Empreinte mémoire et stockage réduite grâce aux clés primaires basées sur disque et à une disposition optimisée des segments dans Milvus 2.5.
Échelle 10×
Marge de manœuvre éprouvée pour évoluer d’un ordre de grandeur supplémentaire sans refonte ni surprises de coûts.y sans changements architecturaux ni coûts imprévus.
Fiabilité d’entreprise
Production continue à très grande échelle sans incident majeur.
Recherche hybride
Recherche vectorielle unifiée et filtrage des métadonnées pour prendre en charge les requêtes complexes.
From a system stability perspective, it's really quite good. Over the year-plus that we've been using it—from version 2.4.3 to now 2.5.8—I honestly haven't encountered many issues. The system can just run there for months, with new data being written every day and users searching every day, without any problems. I don't need to worry about it.
Team Lead
À propos de l’entreprise
Le client est un leader mondial de l’informatique accélérée et de l’intelligence artificielle, avec des décennies d’expérience dans la création de GPU et de plateformes logicielles utilisées dans les jeux vidéo, la robotique, les centres de données et les applications automobiles. L’une de ses initiatives phares est une plateforme de bout en bout pour l’aide avancée à la conduite et la conduite autonome. Cette plateforme prend en charge l’ensemble du cycle de vie du développement de la conduite autonome — de la collecte de données à grande échelle et de l’entraînement de modèles d’IA à l’inférence embarquée et à la prise de décision en temps réel.
Derrière cette plateforme se trouve l’organisation Autonomous Vehicle (AV) Data Engineering de l’entreprise, responsable de l’infrastructure de données qui alimente sa technologie de conduite autonome. Chaque heure de conduite réelle produit des téraoctets de données de capteurs multimodales, notamment des flux de caméras synchronisés, des nuages de points LiDAR, des mesures radar, des données de localisation de haute précision et des métadonnées détaillées sur l’état du véhicule. La mission de l’équipe est de rendre cet ensemble de données massif et en croissance constante consultable, découvrable et exploitable opérationnellement par des centaines d’ingénieurs qui doivent faire émerger des scénarios de longue traîne, identifier des cas limites rares et valider le comportement des modèles dans des conditions réelles.
Pour répondre à ces exigences, l’équipe a construit un système d’exploration de données multimodales capable de rechercher parmi des dizaines de milliards de points de données de capteurs indexés collectés auprès de flottes de test. Le système convertit les données brutes des capteurs en embeddings vectoriels afin que les ingénieurs puissent exécuter des requêtes profondes et sensibles au contexte — par exemple : « véhicules s’insérant depuis la droite sous une forte pluie », « piétons traversant au crépuscule à des intersections non marquées » ou « ronds-points à deux voies avec visibilité obstruée ».
Le système fonctionnait initialement sur FAISS, mais à mesure que le volume de données et les exigences opérationnelles augmentaient, l’équipe a migré vers Milvus afin d’atteindre une plus grande évolutivité, de réduire l’effort de maintenance et de renforcer la fiabilité en production. Milvus a offert une voie claire pour prendre en charge un ordre de grandeur de données supplémentaire, réduire la charge opérationnelle et améliorer l’efficacité du clustering, de l’indexation et du stockage à mesure que la flotte de conduite autonome continuait de s’étendre.
Le défi : FAISS ne pouvait pas évoluer
Le goulot d’étranglement de la gestion des données
La conception initiale de ce système d’exploration de données était volontairement simple. Chaque session de conduite autonome — généralement un trajet d’une heure — était traitée en images, transformée en embeddings vectoriels grâce aux modèles propriétaires de l’entreprise, puis regroupée dans des fichiers d’index FAISS, généralement un par jour.
Si cette structure fonctionnait bien au départ, elle ne passait pas à l’échelle. À mesure que l’ensemble de données explosait, le nombre de fichiers d’index augmentait lui aussi — jusqu’à atteindre finalement des centaines de milliers. Chacun représentait une petite poche d’information isolée. Effectuer des recherches parmi eux introduisait une complexité importante : les index quotidiens contenaient souvent des données qui se chevauchaient, nécessitant une logique complexe pour filtrer et fusionner les métadonnées. En pratique, cela signifiait que si la recherche au sein d’une seule journée fonctionnait correctement, la plupart des utilisateurs voulaient interroger des conditions plus larges — comme des scénarios de conduite spécifiques s’étendant sur plusieurs jours ou régions. Ces recherches devaient accéder simultanément à de nombreux fichiers d’index distincts, ce qui était coûteux en calcul. Les ingénieurs devaient souvent réduire manuellement leur périmètre, en devinant quels fichiers pouvaient contenir les données pertinentes avant de lancer une requête. Ces suppositions rendaient le processus de recherche lent et peu fiable.
Le manque de flexibilité
FAISS n’est pas une base de données — c’est une bibliothèque. Elle convient pour trouver les plus proches voisins d’un vecteur donné, mais les systèmes de recherche de niveau production exigent bien plus qu’une simple correspondance de similarité rapide.
En pratique, les ingénieurs ne voulaient pas rechercher dans l’ensemble du corpus en une seule fois. Ils avaient besoin d’un filtrage contextuel—pour trouver, par exemple, « des images de caméra frontale capturées sous une pluie légère sur des routes urbaines », ou « des trajets de nuit sur les autoroutes de Californie ». Atteindre ce niveau de précision nécessitait de combiner la recherche vectorielle avec des filtres de métadonnées tels que le type de caméra, l’heure, le lieu, la météo et la version du modèle. Mais FAISS ne fournissait pas ces capacités prêtes à l’emploi. Pour combler cette lacune, l’équipe a dû construire une pile complexe de logique personnalisée : des bases de données de métadonnées séparées, des planificateurs de requêtes sur mesure pour décider quels indices FAISS analyser, et un post-filtrage manuel des résultats après la récupération.
Au fil du temps, ces personnalisations ont créé un problème majeur de mise à l’échelle. Différents angles de caméra, plusieurs modèles d’embedding et des pipelines de prétraitement versionnés exigeaient tous des stratégies de gestion distinctes. Il n’existait aucun concept intégré de collections, de partitions ou de regroupement logique des données—seulement des fichiers d’index. Chaque couche d’organisation, du versionnage des données au filtrage des requêtes, devait être écrite et maintenue dans du code personnalisé. Le système fonctionnait—mais au prix de la flexibilité, de la maintenabilité et de la scalabilité à long terme.
Le problème de scalabilité
Le système était déjà mis à rude épreuve par des milliards de vecteurs, et les véhicules de test de l’entreprise généraient de nouvelles données chaque jour. Pendant ce temps, les équipes de recherche introduisaient de nouveaux modèles d’embedding, chacun nécessitant une réindexation à grande échelle des données historiques. Ce n’était qu’une question de temps avant que les charges de travail soient multipliées par dix, mais la configuration FAISS basée sur des fichiers n’avait aucun moyen pratique de passer à cette échelle.
Pire encore, chaque nouveau jeu de données signifiait davantage de fichiers d’index et davantage de mises à jour manuelles du stockage des métadonnées. Il n’y avait pas de partitionnement automatique, pas d’équilibrage de charge intégré, et aucun moyen d’ajouter de la capacité à la demande. L’architecture était devenue obsolète —statique, exigeante en main-d’œuvre et résistante à la croissance.
Les coûts d’ingénierie cachés
Au-delà des coûts cloud, le plus grand défi était la surcharge d’ingénierie cachée liée à la maintenance de FAISS. Les ingénieurs devaient gérer des systèmes de métadonnées complexes, concevoir une logique personnalisée pour distribuer les données, et mettre à jour manuellement des millions de fichiers d’index. Au fil du temps, cette surcharge a ralenti l’innovation : les performances de recherche se sont dégradées, les cycles de développement se sont allongés, et les nouvelles idées ne dépassaient jamais le stade du tableau blanc. À mesure que les volumes de données continuaient de croître, le système devenait de plus en plus rigide et fragile. Il était clair qu’essayer de mettre à niveau la configuration héritée n’était plus viable.
La solution : repenser l’architecture pour la scalabilité avec Milvus
Pour surmonter ces défis, l’équipe AV Data avait besoin d’un système capable de gérer des dizaines de milliards de vecteurs dès aujourd’hui, avec une trajectoire claire vers une croissance de 10× et au-delà. Il devait offrir un filtrage robuste, une simplicité opérationnelle et—avant tout—une fiabilité en production avec une maintenance minimale.
Le processus d’évaluation
Au lieu de mener une comparaison large entre toutes les bases de données vectorielles émergentes, l’équipe s’est concentrée sur la populaire Milvus Vector Database, en exécutant une preuve de concept avec 400 à 500 millions de vecteurs—une taille suffisante pour révéler les goulets d’étranglement du monde réel. Pendant les tests, les ingénieurs ont reproduit l’intégralité de leur flux de travail de données : indexation de jeux de données avec différents types d’index pour comparer les compromis, mesure du temps d’indexation pour estimer les mises à jour quotidiennes par lots, et benchmarking de la latence avec des combinaisons de filtres et des modèles de requêtes réalistes. Ils ont délibérément poussé Milvus à ses limites, en exécutant des recherches complexes à conditions multiples et en augmentant les volumes de données pour tester la stabilité.
Pourquoi Milvus ?
Les résultats de la preuve de concept ont fait de Milvus le choix évident pour l’équipe AV Data.
Performances de requête acceptables : Milvus a systématiquement fourni des latences de requête de l’ordre de la seconde, même pour les recherches les plus complexes et fortement filtrées—largement dans les exigences des charges de travail internes de data mining.
Filtrage natif et flexibilité des requêtes : Les ingénieurs pouvaient désormais combiner la recherche par similarité vectorielle avec des filtres de métadonnées dans une seule requête — des capacités qui nécessitaient auparavant beaucoup de code personnalisé dans FAISS.
Structure de données organisée : Les embeddings vectoriels issus de différents modèles étaient stockés dans des collections distinctes, chacune partitionnée selon des attributs tels que la date de capture ou la région. Milvus gérait automatiquement la distribution des données entre les segments, supprimant la charge de la gestion manuelle des fichiers.
Scalabilité transparente : À mesure que les données augmentaient, l’équipe ajoutait davantage de nœuds pour accroître la capacité. L’architecture distribuée de Milvus évoluait de manière linéaire sans nécessiter de refonte du système.
Communauté open source active : Pendant les tests, les ingénieurs AV Data ont reçu un support rapide et concret de la part de l’équipe Milvus et des contributeurs de la communauté, renforçant fortement leur confiance en Milvus en tant qu’écosystème fiable et prêt pour la production.
Mise en œuvre de la nouvelle architecture avec Milvus
À la base, l’architecture de ce système d’exploration de données multimodales est simple, mais son exécution à très grande échelle exige une ingénierie minutieuse et précise. Les données vidéo brutes issues des trajets de véhicules autonomes — des heures de séquences continues provenant de plusieurs caméras — alimentent un pipeline de traitement qui extrait des images individuelles ou de courts clips, généralement de quelques secondes.
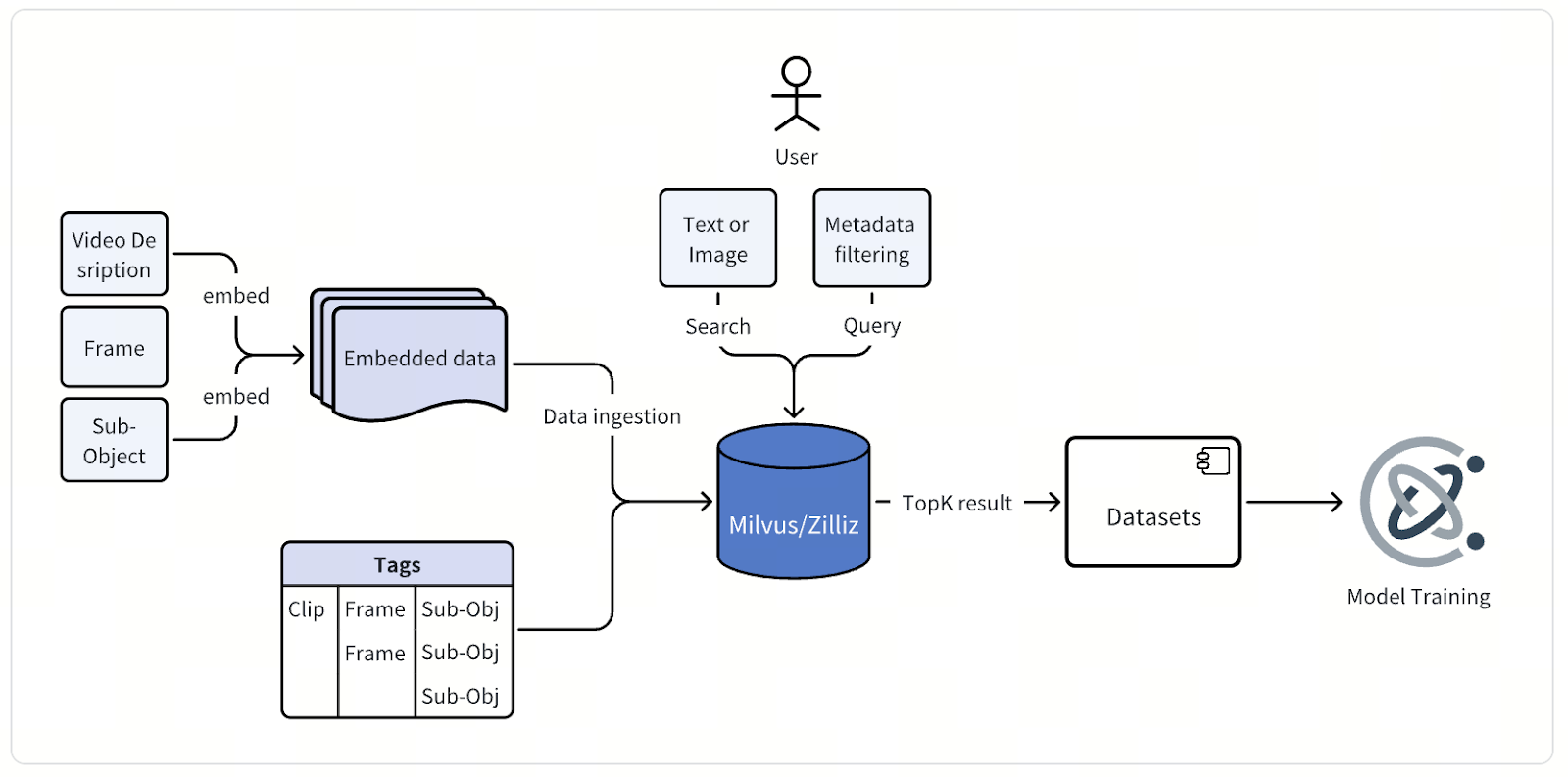
Chaque image ou clip passe ensuite par les modèles d’embedding propriétaires de l’entreprise, spécialement conçus pour la conduite autonome. Pour les données image, l’équipe utilise des modèles dérivés de l’architecture CLIP, personnalisés et affinés pour capturer la sémantique propre à la route. Pour les données vidéo, elle s’appuie sur ses propres modèles maison, une famille de modèles de fondation pour les applications d’IA physique. Ensemble, ces modèles convertissent les données visuelles en embeddings vectoriels à haute dimension qui encodent une riche signification contextuelle.
Une fois générés, ces embeddings vectoriels — ainsi que des métadonnées détaillées — sont stockés et indexés dans la base de données vectorielle Milvus. Chaque point de données comporte des attributs décrivant, entre autres, la session de conduite, la position de la caméra, l’horodatage, l’état du véhicule, l’emplacement et les conditions météorologiques. Ces métadonnées sont également indexées afin de permettre des recherches filtrées rapides et précises dans d’immenses jeux de données.
Grâce à une interface de requête unifiée, les ingénieurs peuvent rechercher les données de plusieurs façons. Ils peuvent saisir une description textuelle, téléverser une image ou une vidéo de référence, ou combiner la recherche vectorielle avec des filtres de métadonnées pour identifier exactement ce dont ils ont besoin. Une seule requête pourrait, par exemple, demander des « intersections urbaines de nuit avec des piétons traversant », et Milvus renvoie les images ou clips les plus pertinents pour examen, analyse et amélioration du modèle.
Les avantages : efficacité des coûts, stabilité et échelle
Après plus d’un an de fonctionnement continu, Milvus s’est révélé non seulement solide sur le plan technique, mais aussi transformateur sur le plan opérationnel. Les résultats suivants montrent comment son architecture et son écosystème se sont traduits par une efficacité concrète à grande échelle.
Des opérations plus simples, moins de casse-tête et un développement plus rapide
La migration de centaines de milliers de fichiers FAISS vers Milvus a supprimé toute une couche de surcharge opérationnelle. Il n’y a plus de gestion manuelle des fichiers d’index, plus de scripts ad hoc, ni de logique de requête personnalisée. La distribution des données, la gestion des segments et le routage des requêtes se font désormais automatiquement. Les mises à niveau sont simples, la supervision est unifiée et les métriques racontent une histoire claire. Résultat : moins de temps consacré à la maintenance des systèmes et plus de temps à exploiter les données pour en tirer des insights.
Une charge d’ingénierie réduite, plus 30 % de réduction supplémentaire des coûts après la mise à niveau vers Milvus 2.5
Le déploiement de Milvus a immédiatement réduit les coûts d’infrastructure et d’ingénierie. L’abandon du système basé sur des fichiers de FAISS a éliminé la gestion manuelle des fichiers et le suivi complexe des métadonnées, permettant d’économiser un temps de développement et des efforts opérationnels considérables. La mise à niveau de Milvus 2.4 vers Milvus 2.5 a ensuite apporté une réduction supplémentaire de 30 % des coûts d’infrastructure, grâce à un mappage mémoire plus intelligent, au stockage des clés primaires sur disque et à une gestion plus efficace des segments.
Ensemble, ces améliorations permettent à l’équipe AV Data d’exécuter les mêmes charges de travail sur des instances AWS plus petites — ou d’indexer bien plus de données — sans augmenter les dépenses ni la charge de maintenance. Encouragée par ces résultats, l’équipe prévoit de tester Milvus 2.6, qui introduit de nouveaux types d’index comme RaBitQ et d’autres optimisations qui devraient encore améliorer les performances et l’efficacité des coûts. Pour les importantes charges de travail par lots hors ligne, la vitesse de construction des index reste un défi central. Grâce aux contributions de l’équipe NVIDIA cuVS, Milvus prend désormais en charge la construction d’index accélérée par GPU avec un service basé sur CPU (GPU-build, CPU-serve). Cette approche accélère considérablement la construction des index tout en maintenant l’efficacité des coûts — et devrait encore renforcer l’avantage prix-performance de Milvus dans les charges de travail liées à la conduite autonome.
Évolutivité intégrée, éprouvée en pratique
La plateforme indexe désormais des dizaines de milliards de vecteurs et ingère de nouvelles données quotidiennement sans friction. La modélisation interne confirme qu’elle peut encore évoluer d’un facteur 10 sans refonte ni mauvaises surprises en matière de coûts, transformant ce qui était autrefois une contrainte de capacité en avantage stratégique à long terme. Grâce à cette marge de manœuvre, l’équipe peut passer de l’indexation de deux années de données de conduite récentes à la couverture de l’ensemble des archives historiques, permettant la recherche dans chaque session de conduite jamais enregistrée. Elle peut également exécuter plusieurs modèles d’embedding en parallèle afin d’optimiser la récupération pour différents types de requêtes, et même conserver les données indéfiniment au lieu de les supprimer avec le temps. Ici, l’évolutivité ne signifie pas seulement gérer davantage de données, mais permettre un apprentissage continu et des progrès plus rapides vers une conduite autonome plus sûre.
Fiabilité d’entreprise à très grande échelle
En plus d’un an de production ininterrompue, Milvus a géré discrètement des dizaines de milliards de vecteurs avec ingestion et requêtage quotidiens, sans un seul incident majeur. Le système fonctionne de manière stable en arrière-plan, avec une supervision minimale. Pas de pannes le week-end, pas de correctifs d’urgence — seulement des performances constantes et prévisibles. Ce type de fiabilité à cette échelle se traduit par moins de risques opérationnels, moins de gestion de crises et davantage de concentration sur la création de valeur plutôt que sur la gestion de l’infrastructure.
Recherche plus riche, workflows plus intelligents
Milvus combine la recherche vectorielle avec le filtrage par métadonnées, offrant aux ingénieurs de l’entreprise de nouvelles façons d’analyser des données de conduite complexes. Ils peuvent, par exemple, trouver toutes les images de zones de construction capturées par des caméras frontales à la lumière du jour, ou filtrer par heure et par lieu afin de comparer le comportement des modèles entre les mises à jour et les régions. Différentes collections contiennent des embeddings provenant de différents modèles, permettant aux équipes de tester de nouvelles architectures sans affecter la production. Ces capacités accélèrent l’expérimentation et révèlent des insights qui nécessitaient auparavant une ingénierie personnalisée considérable.
Une communauté forte qui démultiplie l’impact
Au-delà de la technologie, la communauté open source Milvus a joué un rôle majeur dans le succès de l’entreprise. Pendant les phases de test et de déploiement, les ingénieurs ont bénéficié d’un support rapide directement de la part des contributeurs et mainteneurs de Milvus. Cette réactivité a réduit les temps d’arrêt, accéléré le débogage et permis de maintenir les progrès sur la bonne voie. Au fil du temps, la communauté active a continué d’apporter de la valeur en aidant à valider de nouvelles idées, à fluidifier les mises à niveau et à partager les meilleures pratiques. Pour ce client, Milvus n’est pas seulement un logiciel fiable — c’est un écosystème collaboratif qui renforce la plateforme et offre une efficacité à long terme.
Enseignements tirés de la production
Choisir le bon index : équilibrer échelle, coût et précision
Choisir un index est l’une des décisions pratiques les plus importantes lors de la création d’un système de recherche vectorielle. Milvus prend en charge de nombreux types d’index, chacun avec ses propres compromis en matière de vitesse, d’utilisation de la mémoire et de précision. Pour l’équipe AV Data, l’objectif était de trouver un équilibre entre l’échelle des données, le coût de l’infrastructure et la précision de la recherche — pas simplement de choisir l’option la plus rapide.
Après avoir testé plusieurs configurations, ils ont sélectionné IVF_FLAT, qui regroupe les vecteurs en clusters et effectue une recherche exacte au sein de ceux qui sont pertinents. Ce n’est pas l’option la plus rapide ni la plus compacte, mais pour des dizaines de milliards de vecteurs et des besoins de latence modérés, elle a fourni le bon équilibre entre performance et précision tout en restant efficace.
L’équipe a constaté qu’une fois qu’un index correspond bien à la charge de travail, il est rarement nécessaire de passer à quelque chose de plus récent. En pratique, un index bien adapté permet d’économiser plus de temps et de ressources que la recherche de petits gains de performance. Pour les systèmes à grande échelle, des performances stables et prévisibles sont ce qui garantit la fluidité des opérations.
Mappage mémoire : échanger de la latence contre des coûts réduits à grande échelle
L’un des choix techniques les plus efficaces de l’équipe a été d’utiliser le mappage mémoire (Mmap) pour maîtriser les coûts d’infrastructure. Dans les configurations traditionnelles, conserver toutes les données vectorielles en RAM nécessiterait des instances massives et coûteuses. Avec le mappage mémoire dans Milvus, la plupart des données restent sur disque tandis que le système d’exploitation conserve automatiquement en mémoire les portions fréquemment consultées. Cette conception introduit une certaine latence — les lectures disque sont plus lentes que la RAM — mais elle maintient des performances prévisibles et une utilisation efficace des ressources. Pour la charge de travail de l’entreprise, ce compromis était parfaitement logique. Leurs utilisateurs sont des ingénieurs exécutant des requêtes analytiques, et non des utilisateurs finaux attendant des réponses instantanées, et la concurrence reste faible.
Opérations de suppression : quand de petites hypothèses échouent à grande échelle
L’un des plus grands enseignements de l’équipe est venu de quelque chose qui semblait simple : la suppression de données. Dans l’architecture append-only de Milvus, les vecteurs supprimés ne sont pas retirés immédiatement — ils sont marqués pour suppression et nettoyés plus tard via une compaction en arrière-plan. Lors des tests, la suppression de millions de vecteurs a déclenché de manière inattendue la réindexation de milliards d’entre eux, car les filtres de Bloom produisaient des faux positifs sur des milliers de segments. Ce qui semblait être un nettoyage de routine a fini par surcharger les nœuds de données et bloquer les tâches.
La solution est venue d’une meilleure compréhension de la manière dont Milvus gère les données et de l’ajustement de leur flux de travail — réglage des filtres de Bloom, utilisation de clés de partition pour cibler précisément les suppressions, et passage à un chargement en masse en insertion seule. Conclusion : à grande échelle, même des opérations simples peuvent se comporter différemment, et comprendre les mécanismes internes du système est essentiel pour maintenir des performances prévisibles.
Perspectives
L’équipe se prépare à adopter Milvus 2.6 peu après sa sortie, convaincue que les nouveaux types d’index et les optimisations architecturales apporteront un nouveau bond en matière d’efficacité. Les premières discussions avec l’équipe d’ingénierie de Milvus indiquent des réductions de coûts continues et une meilleure utilisation des ressources, que l’entreprise prévoit de valider au moyen de benchmarks à pleine échelle.
À plus long terme, l’équipe entrevoit des opportunités prometteuses pour étendre les fonctionnalités et passer à l’échelle. Des fonctionnalités telles que la recherche hybride, qui combine les requêtes textuelles et vectorielles, pourraient ouvrir de nouvelles façons d’explorer les données multimodales, tandis que des filtres améliorés de type base de données simplifieront les workflows complexes. La prochaine version Milvus 3.0 est également prometteuse pour les architectures à plusieurs niveaux, permettant à l’entreprise de conserver un accès rapide aux données récentes tout en stockant efficacement l’intégralité de ses archives historiques. Ensemble, ces avancées offriront à l’entreprise une plateforme de données qui évolue sans effort, prend en charge des capacités de recherche plus approfondies et se développe plus efficacement.
En outre, l’introduction et la maturation des constructions d’index accélérées par GPU et alimentées par NVIDIA cuVS, avec service basé sur CPU (GPU-build, CPU-serve) dans Milvus devraient apporter une amélioration décisive des performances d’indexation hors ligne. En tirant parti des GPU NVIDIA et des bibliothèques cuVS hautement optimisées, Milvus peut construire des index vectoriels à grande échelle beaucoup plus rapidement que les pipelines reposant uniquement sur CPU, tout en continuant à servir les requêtes de manière rentable sur CPU. Cela réduit considérablement le délai entre les données et les requêtes, permet des cycles d’actualisation des index plus fréquents et amplifie encore l’avantage prix-performance de Milvus pour la conduite autonome et d’autres workloads multimodaux à grande échelle où l’itération rapide et les données récentes sont essentielles.
Conclusion
L’équipe AV Data du client a construit une puissante plateforme de data mining qui accélère le développement de la conduite autonome en rendant d’immenses volumes de données multimodales consultables et exploitables. La migration de FAISS vers Milvus a résolu des défis critiques en matière de scalabilité, de flexibilité et de complexité opérationnelle, tout en générant des économies mesurables et une stabilité remarquable en production.
Après plus d’un an de fonctionnement continu et des dizaines de milliards de vecteurs indexés, la plateforme a prouvé que Milvus peut servir de fondation de niveau production pour la recherche vectorielle à grande échelle et spécifique à un domaine. Le système ingère de nouvelles données quotidiennement, soutient les ingénieurs dans les programmes de conduite autonome de l’entreprise et offre une voie claire pour passer à une échelle 10× supérieure sans réarchitecture.
Pour les organisations qui construisent des systèmes de recherche vectorielle avec des volumes de données massifs, l’efficacité des coûts compte, et la stabilité l’emporte sur une latence inférieure à la milliseconde. L’expérience de l’entreprise est instructive. Milvus démontre qu’une base de données vectorielle open-source peut non seulement répondre aux exigences de la production, mais aussi continuer à s’améliorer au fil du temps, en fournissant une épine dorsale fiable, scalable et prête pour l’avenir pour l’infrastructure IA du monde réel.
- À propos de l’entreprise
- Le défi : FAISS ne pouvait pas évoluer
- La solution : repenser l’architecture pour la scalabilité avec Milvus
- Les avantages : efficacité des coûts, stabilité et échelle
- Enseignements tirés de la production
- Perspectives
- Conclusion
Contenu
Secteur d'activité
Automobile
Technologie utilisée