




Optimiser l'IA conversationnelle chez FARFETCH

15x
temps d'indexation plus rapide
5x
temps d'interrogation plus rapide
Augmentation de la conversion
grâce à des recommandations de produits plus pertinentes
Plusieurs types de métriques
pour soutenir différents cas d'utilisation
Milvus consistently outperformed Weaviate, emphasizing the indexing time for scenario S9, closely resembling the FARFETCH product catalog's dimensions.
PEDRO MOREIRA COSTA
A propos de FARFETCH
FARFETCH, leader de la vente de mode en ligne, repousse les limites du shopping numérique avec sa dernière innovation, iFetch. Ce système d'IA conversationnel est conçu pour apporter au monde numérique le service personnalisé et haut de gamme que l'on trouve généralement dans les magasins physiques de luxe. Dans le cadre de cette initiative, FARFETCH Chat R&D développe un système de recommandation conversationnel spécialisé. Ce chatbot, intégré à iFetch, permet aux utilisateurs d'interagir avec le catalogue de produits FARFETCH par le biais du langage naturel et d'images. Par exemple, un utilisateur peut télécharger la photo d'une veste qu'il aime, et le chatbot lui répondra en lui proposant une sélection de vestes similaires. En combinant de manière transparente des technologies d'IA avancées et en mettant l'accent sur l'expérience utilisateur, FARFETCH vise à redéfinir ce que les clients peuvent attendre des achats en ligne.
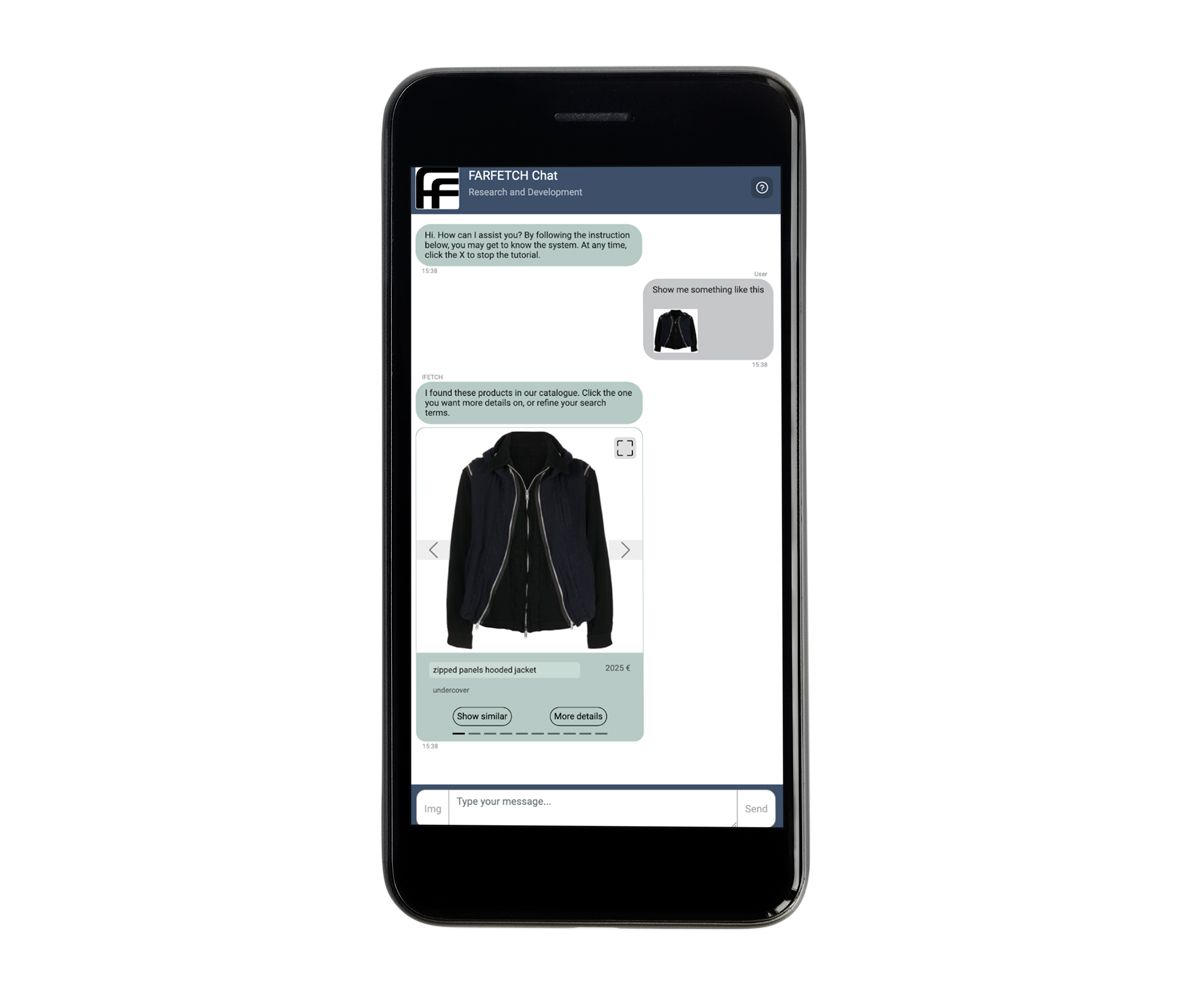 Le chatbot FARFETCH montre une vitrine similaire
Le chatbot FARFETCH montre une vitrine similaire
L'entreprise s'est toutefois heurtée à un problème de taille : avec leurs métadonnées limitées, les catalogues de produits traditionnels peinaient à rendre compte des relations complexes et des attributs nuancés de leur vaste gamme de produits. Pour résoudre ce problème, ils ont eu recours à des algorithmes d'apprentissage automatique pour développer des "embeddings" de produits, c'est-à-dire des points de données à haute dimension qui servent de langage robuste à leur système d'intelligence artificielle. Cela permet au chatbot de comprendre et de recommander des produits avec une précision sans précédent. Cependant, le stockage et la récupération de ces embeddings en temps réel ont constitué un autre obstacle, nécessitant une solution de stockage spécialisée capable de traiter efficacement des données de haute dimension.
L'importance des bases de données vectorielles
Les bases de données vectorielles, également connues sous le nom de moteurs de similarité vectorielle (VSE), sont des bases de données spécialisées conçues pour traiter des données complexes en haute dimension appelées "embeddings vectoriels". Ces bases de données utilisent des algorithmes ANN (Approximated Nearest Neighbors), qui sont indispensables pour une recherche rapide et précise des données. Cette caractéristique est particulièrement vitale pour iFetch, qui exige des interactions en temps réel avec les clients afin de leur fournir des recommandations de produits instantanées et de répondre à leurs questions. Le choix d'une base de données vectorielle n'est pas une simple question technique ; il s'agit d'une décision stratégique qui a un impact direct sur les performances, la robustesse et l'efficacité d'iFetch. L'entreprise a mené une étude comparative complète pour s'assurer qu'elle avait choisi la base de données vectorielles la plus appropriée. Cette étude a consisté à évaluer diverses bases de données, notamment Vespa, Milvus, Qdrant, Weaviate, Vald et Pinecone, sur la base de divers critères tels que la vitesse d'indexation, la vitesse d'interrogation et l'évolutivité. L'analyse comparative comprenait également des tests de stress pour évaluer les performances de chaque ESV en cas de charge maximale, ainsi que des scénarios de basculement et de récupération pour évaluer la résilience.
Représentation holistique de l'architecture du système iFetch avec Vector Similarity Searc](https://assets.zilliz.com/Holistic_representation_of_the_i_Fetch_system_architecture_with_Vector_Similarity_Search_10948cc2e7.png)
Critères de référence et sélection
Le processus de benchmarking mené par l'équipe de Farfetch a été exhaustif et méthodique, couvrant un large éventail de facteurs cruciaux pour le succès à long terme d'iFetch. Ces facteurs comprenaient la diversité des types d'index, des types de métriques, des capacités de service de modèles et de l'adoption par la communauté. Ils ont également pris en compte la qualité de la documentation et la disponibilité de l'assistance, ces facteurs ayant un impact sur la facilité de mise en œuvre et la maintenance continue.
| Les utilisateurs ont également pris en compte la qualité de la documentation et la disponibilité de l'assistance, car ces facteurs ont une incidence sur la facilité de mise en œuvre et la maintenance continue.
| --------- | ---------- | --------- | -------- | -------- | ---- | ------------ |
| Modèle de cohérence - N/A - Cohérence forte - Cohérence éventuelle - Cohérence éventuelle - N/A - Cohérence éventuelle - Modèle de cohérence - N/A - Cohérence éventuelle - Modèle de cohérence - N/A - Modèle de cohérence - Modèle de cohérence - N/A - Cohérence forte - Modèle de cohérence - N/A - Cohérence éventuelle
| Prise en charge de GraphQL - N/A - N/A - Oui - N/A - N/A - N/A - N/A - N/A - N/A - N/A
| Sharding | Non (à venir
date inconnue) | Oui | Oui | Oui | Oui | N/A | N/A | N/D
| Pagination - N/A - Non (prévue dans la version 2.2
en 2022.3) - Oui - Oui - N/A - N/A - Non
|Types de mesures|Produit intérieur
Similitude de cosinus
Euclidienne (L2)|L2
Produit intérieur
Hamming
Jaccard
Tanimoto
Superstructure
Substructure|Cosinus|Euclidienne
Angulaire
Produit intérieur
Géo degrés
Hamming|L1
L2
Angle
Hamming
Cosinus
Angle normalisé
Cosinus normalisé
Jaccard|Euclidienne
Cosinus
Produit intérieur|
Taille max. du vecteur| N/A | N/A | 32
768 | N/A | Max.MaxInt64 | N/A | Taille max. de l'index| N/A | 32
768 | N/A | Max.MaxInt64 | N/A
|Taille max. de l'index| N/A | N/A | Illimité | N/A | N/A | N/A | N/A
|Type d'index| HNSW | ANNOY
HNSW
IVF_PQ
IVF_SQ8
IVF_FLAT
FLAT
IVF_SQ8_H
RNSG | NHSW | HNSW
BM25 | N/A |Propriétaire|
text2vec-contextionary
Le propre vecteur de langage de Weaviate ; le module vecteur Weighted Mean of Word Embeddings (WMOWE) qui fonctionne avec des modèles populaires tels que fastText et GloVe. Le plus récent text2vec - contextionary est entraîné en utilisant fastText sur des données Wiki et CommonCrawl.
text2vec- transformers
Les modèles Transfomer diffèrent du Contextionary car ils vous permettent d'ajouter un module NLP pré-entraîné spécifique à votre cas d'utilisation. Cela signifie que des modèles tels que BERT, DilstBERT, RoBERTa, DilstilROBERTa, etc. peuvent être utilisés avec Weaviate.
Après une analyse rigoureuse, deux TPE - Milvus et Weaviate - ont été sélectionnés pour une analyse comparative approfondie. Ces plates-formes correspondaient étroitement à leurs exigences strictes en matière de robustesse, d'efficacité et d'évolutivité. Les feuilles de route des plateformes ont également influencé la sélection finale, car l'entreprise avait besoin d'une solution qui continuerait à évoluer et à s'adapter à ses besoins croissants.
Configuration expérimentale
L'équipe a utilisé une configuration matérielle et logicielle standardisée afin de garantir une évaluation équitable et complète.
- Matériel : Intel Xeon E5-2690 v4 CPU, 112 GB RAM, 1024 GB HDD
- Logiciel : Linux 16.04-LTS, Anaconda 4.8.3 avec Python 3.8.12
- Ensemble de données : L'équipe de Farfetch a utilisé un ensemble de données publiques provenant de startups-list.com, comprenant 40 474 enregistrements. L'ensemble de données comprenait des encastrements précalculés pour les descriptions d'entreprises.
Scénarios et algorithme d'indexation
Les chercheurs ont conçu plusieurs scénarios de test pour évaluer les performances de ces TPE dans différentes conditions. Ces scénarios faisaient varier le nombre d'enregistrements et le nombre d'encodages par entité. Ils ont utilisé l'algorithme Hierarchical Navigable Small World (HNSW) pour l'indexation, connu pour son efficacité dans les espaces de données à haute dimension.
La liste finale des scénarios est présentée ci-dessous.
| Scénario : nombre d'entités, nombre de codages par entité, nombre de codages par entité, nombre de codages par entité, nombre de codages par entité, nombre de codages par entité, etc. | ---------------- | ------------------ | ------------------------------ | Scénario #1 (S1) | 1.000 | 1 | Scénario #2 (S2) | 10.000 | 1 | | Scénario #2 (S2) | 10.000 | 1 | Scénario #3 (S3) | 40.474 | 1 | Scénario #4 (S3) | 10.000 | 1 Scénario #4 (S4) | 1.000 | 2 | Scénario #5 (S4) | 1.000 | 2 | Scénario 5 (S5) - 10.000 - 2 | Scénario #6 (S6) | 40.474 | 2 | Scénario #7 (S7) - 1.000 - 5 Scénario #7 (S7) | 1.000 | 5 | Scénario #8 (S8) | 10.000 | 5 | Scénario #9 (S8) | 1.000 | 5 | Scénario #9 (S9) | 40.474 | 5 |
Analyse des performances
Indexation
Weaviate : Permet la déclaration explicite des paramètres d'indexation lors de la création d'un schéma de classe. Cependant, il restreint la dénomination des classes, notamment en interdisant les nombres et les caractères spéciaux.
Milvus : Offre un plus large éventail d'algorithmes d'indexation et de types de métriques. Il permet également de définir la taille des fichiers d'index, ce qui peut optimiser les opérations par lots.
Résultat : Milvus a pris l'avantage en ce qui concerne les temps d'indexation moyens dans tous les scénarios. Il était notamment plus rapide dans le scénario le plus gourmand en ressources, S9.
Milvus 1.1.1 Temps d'indexation moyen pour les scénarios S1 à S9](https://assets.zilliz.com/Milvus_Average_Indexing_Time_f319bf820f.png) Temps d'indexation moyen de Weaviate pour les scénarios S1 à S9](https://assets.zilliz.com/Weaviate_Average_Indexing_Time_7e5d22ae83.png)
Interrogation
Weaviate : Son client Python supporte la recherche vectorielle mais seulement pour un seul vecteur à la fois.
Milvus : Offre une méthode de recherche plus flexible qui peut gérer une liste de vecteurs, facilitant les requêtes multi-vectorielles.
Résultat : Milvus a affiché des temps de recherche moyens plus courts dans tous les scénarios, même s'il a eu besoin d'une phase d'échauffement pour atteindre des performances optimales.
Milvus 1.1.1 Temps moyen d'interrogation pour les scénarios S1 à S9] (https://assets.zilliz.com/Milvus_Average_Querying_Time_3917a37469.png)
!Weaviate Temps de recherche moyen pour les scénarios S1 à S9](https://assets.zilliz.com/Weaviate_Average_Querying_Time_a51475e7d5.png)
L'équipe de Farfetch a estimé que Milvus et Weaviate étaient prometteurs, mais qu'ils étaient encore en évolution. Des fonctionnalités telles que la mise à l'échelle horizontale, le sharding et la prise en charge des GPU sont sur la feuille de route. Pour FARFETCH, qui vise à gérer un catalogue de produits allant de 300k à 5 millions de produits, la TPE idéale devrait offrir :
- Des résultats précis et de haute qualité
- Des capacités d'indexation efficaces
- Une exécution rapide des requêtes
- Des fonctions d'évolutivité telles que l'équilibrage de la charge et la réplication des données.
Leurs expériences ont révélé que Milvus était systématiquement plus performant que Weaviate en termes de temps d'indexation et d'interrogation. Toutefois, il convient de noter que les deux plateformes présentent certaines limites, telles que l'absence de prise en charge de codages multiples. Leurs travaux futurs consisteront à suivre de près le développement de ces plateformes et à les réévaluer éventuellement au fur et à mesure qu'elles introduisent de nouvelles fonctionnalités.
Cette étude de cas est une version condensée d'une analyse comparative approfondie des bases de données vectorielles publiée à l'origine par PEDRO MOREIRA COSTA de Farfetch. Pour une analyse plus détaillée, veuillez vous référer aux articles de blog originaux : [PUISSANCE DE L'IA AVEC LES BASES DE DONNÉES VECTORELLES : UNE ÉVALUATION - PARTIE I] (https://www.farfetchtechblog.com/en/blog/post/powering-ai-with-vector-databases-a-benchmark-part-i/) et [PUISSANCE DE L'IA AVEC LES BASES DE DONNÉES VECTORELLES : UNE ÉVALUATION - PARTIE II] (https://www.farfetchtechblog.com/en/blog/post/powering-ai-with-vector-databases-a-benchmark-part-ii/).
- A propos de FARFETCH
- L'importance des bases de données vectorielles
- Critères de référence et sélection
- Configuration expérimentale
- Scénarios et algorithme d'indexation
- Analyse des performances
Contenu
Cas d'usage
Secteur d'activité
Commerce électronique